【C++】类和对象 - 上
目录
- 1. 面向过程和面向对象初步认识
- 2. 类的引入
- 3. 类的定义
- 4. 类的访问限定符及封装
-
- 4.1 访问限定符
- 4.2 封装
- 5. 类的作用域
- 6. 类的实例化
- 7. 类对象模型
-
- 7.1 如何计算类的大小
- 7.2 类对象的存储方式猜测
- 7.3 结构体内存对齐规则
- 8. this指针
-
- 8.1 引出
- 8.2 this指针的特性
- 总结
1. 面向过程和面向对象初步认识
C语言是面向过程的,关注的是过程,分析出求解问题的步骤,通过函数调用逐步解决问题。
比如说洗衣服,一般分为以下几个步骤:
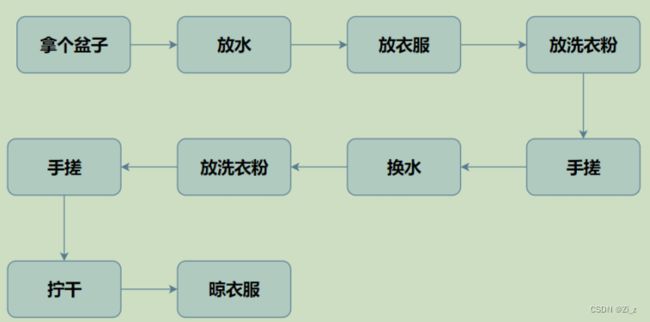
以上的每一个步骤都是需要人来做的,也就是说人是要对每个步骤应该做的事情都要清楚,在语言层面对应依次设计和实现函数来解决遇到的每个问题,这就是面向过程的大体思想。
C++是基于面向对象的,关注的是对象,将一件事情拆分成不同的对象,靠对象之间的交互完成。
同样是洗衣服,用面向对象的思路则是要把解决的问题分为几个对象:人、衣服、洗衣机,洗衣粉。
洗衣服的过程则为:人把衣服放进洗衣机–>倒入洗衣粉–>启动洗衣机–>最后洗衣机洗完会把衣服甩干。
这里的整个过程主要是这几个对象之间互相交互完成的,而有些步骤,人是不需要知道的,比如洗衣机是如何洗衣服以及如何甩干的,这是面向对象的思想。
2. 类的引入
C语言结构体中只能定义变量,在C++中,结构体内不仅可以定义变量,也可以定义函数。因为C++把结构体升级成了类:
//C语言只能这么玩
struct stu
{
//成员变量
char name[20];
int age;
//...
};
//C++
struct stu
{
//成员函数
char* getName() {
return name;
}
int getAge() {
return age;
}
//...
//成员变量
char name[20];
int age;
//...
};
同样定义一个结构体对象也多了一种方式:
int main()
{
//C语言只能像下面这样定义结构体变量
struct stu s1;
//C++不仅可以支持C语言的写法
//下面这种写法也是支持的
stu s2;
//stu是类名,直接定义变量
return 0;
}
C++在语法层面上是完全兼容C的,虽然上面的类型是结构体但是编译器已经把它识别成了类,所以C++更喜欢用关键字class来代替struct。
在C++中,用类或者结构定义的变量一般都称之为对象。
3. 类的定义
class className
{
// 类体:由成员函数和成员变量组成
}; // 一定要注意后面的分号
class为定义类的关键字,ClassName为类的名字,{}中为类的主体,注意类定义结束时后面分号不能省略。
与定义结构体的语法是一样的。
类体中内容称为类的成员:类中的变量称为类的属性或成员变量; 类中的函数称为类的方法或者成员函数。
类的两种定义方式:
- 声明和定义全部放在类体中,需注意:成员函数如果在类中定义,编译器可能会将其当成内联函数处理。
- 类声明放在.h文件中,成员函数定义放在.cpp文件中,注意:如果定义与声明分离,那么在定义处成员函数名前需要加
类名::,否则编译器无法识别是成员函数还是普通全局函数,如下:
class stu
{
char* getName();
int getAge();
char name[20];
int age;
//...
};
char* stu::getName() {
return name;
}
int stu::getAge() {
return age;
}
若类中定义的成员函数过多,尽量使用第二种方法,这样有利于提高代码的可读和可维护性。
成员变量命名规则建议:
class Date
{
public:
void Init(int year)
{
// 这里的year到底是成员变量,还是函数形参?
year = year;
}
private:
int year;
};
为了避免上述不必要的争议,建议把成员变量的名称都加上一些前后缀来区分,比如:
class Date
{
public:
void Init(int year)
{
_year = year;
}
private:
//前缀加上一个下划线
int _year;
//或则
int Year;
};
其他方式也可以的,主要目的是为了区分。
4. 类的访问限定符及封装
4.1 访问限定符
把struct改为class后,下面代码编译后会报错:
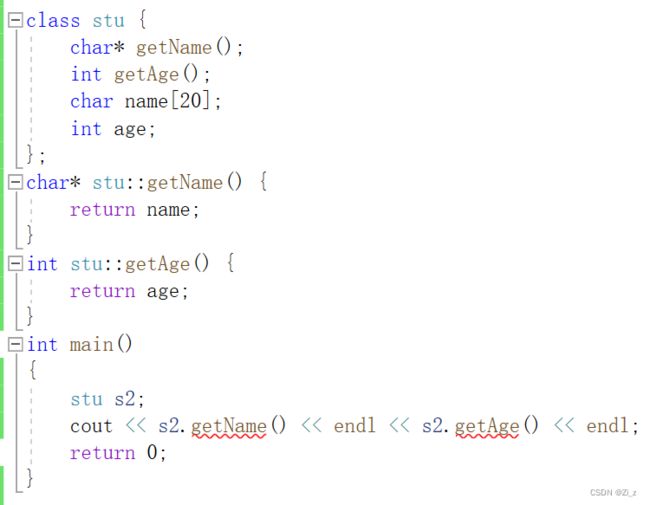

原因是C++在类中新增了三个访问限定符,分别是:
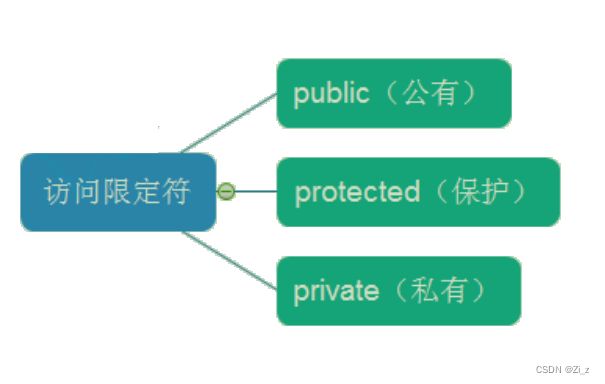
说明如下:
public修饰的成员在类外可以直接被访问protected和private修饰的成员在类外不能直接被访问(它俩有些区别,但此处protected和private的作用是类似的)- 访问权限作用域从该访问限定符出现的位置开始直到下一个访问限定符出现时为止
- 如果后面没有访问限定符,作用域就到 } 即类结束。
- class的默认访问权限为private,struct为public(因为struct要兼容C)
从最后一条可以得知报错的原因是:class定义的类,类中的成员变量和成员函数的默认访问权限是private,即外部无法直接访问类中的任何成员,而struct可以是因为它的默认访问权限是public。
注意:访问限定符只在编译时有用,当数据映射到内存后,没有任何访问限定符上的区别
为了使得该段代码能够正常通过编译,一种做法是在前面加上public访问限定符:
class stu {
public:
char* getName();
int getAge();
char name[20];
int age;
};
这样便可顺利通过编译,但是出于安全性考虑,大部分情况是类中的成员变量不想让外部直接被访问到,但是又需要使用这些变量,因此为了满足这种情况,只需要把成员函数公有即可,成员变量进行私有保护:
class stu {
public:
char* getName();
int getAge();
private:
char name[20];
int age;
};
这种做法很好的保护了成员变量被非法访问,若要访问,必须通过对外提供的接口来安全访问这些私有成员。
你要访问使用我,可以,但是你必须要按照我给你提供的方法来操作
问题:C++中struct和class的区别是什么?
答:C++需要兼容C语言,所以C++中struct可以当成结构体使用。另外C++中struct还可以用来定义类。和class定义类是一样的,区别是struct定义的类默认访问权限是public,class定义的类默认访问权限是private。
注意:在继承和模板参数列表位置,struct和class也有区别,后序会介绍
4.2 封装
封装是面向对象的三大特性之一,另外两个分别为:继承和多态。
另外两个后续会介绍
封装不仅在语言中很常见在现实生活中也是如此,那么什么是封装?
封装:将数据和操作数据的方法进行有机结合,隐藏对象的属性或者一些方法的实现细节,仅对外公开接口来和对象进行交互。
举个现实中例子:
计算机的组成以及底层的工作原理十分复杂,但是对于使用者而言压根不太需要关心,只需要知道怎么开机、怎么使用鼠标键盘等来操作计算机就够了。
因此厂商在出厂时,在外部套上壳子,把内部的组成和实现细节全部隐藏起来,对外仅仅暴露出电源以及部分io接口,能让用户和计算机交互即可。
不仅方便了用户,也对计算机本体进行了很好的保护
这是现实层面,在语言层面C++的封装是怎么体现的呢?
它是通过类将数据以及操作数据的方法进行有机结合,通过访问权限来隐藏对象内部实现细节,控制哪些方法可以在类外部直接被使用。
因此封装的本质是一种管理,能让用户更方便的使用类。
5. 类的作用域
类定义了一个新的作用域,类的所有成员都在类的作用域中。在类体外定义成员时,需要使用 :: 作用域操作符指明成员属于哪个类域。
在成员函数内部使用一个变量或者函数时,会先在该函数的局部域中查找,若找不到再去类域中去找,还找不到则会去全局域中去找,找不到就报错,有命名空间也不会去命名空间中去找。
同样可以指定去命名空间域中去找,找不到就报错
6. 类的实例化
用类类型创建对象的过程,称为类的实例化或者叫做对象的定义:
class stu {
public:
char* getName();
int getAge();
private:
char name[20];
int age;
};
int main()
{
//对象的实例化
stu s1;
stu s2;
return 0;
}
类类型和结构体类型是一样的,本质只是定义一个新的类型,类型是不占用内存空间的,只有用该类型实例化出一个对象(变量)才会在内存中开辟空间来存储类中声明的那些成员。
就好比建筑图纸,图纸只有一份,并不占地方,只有通过图纸建造出很多实体建筑才会占用地方
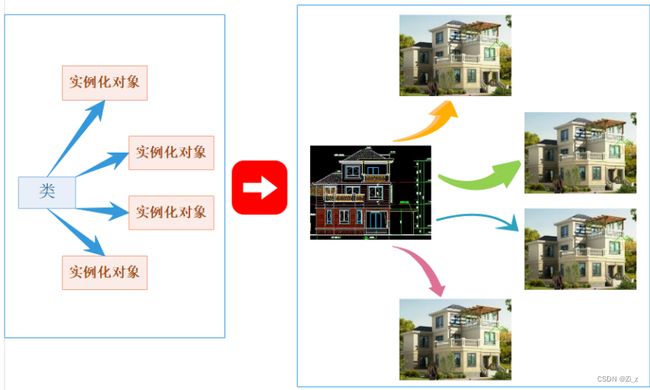
7. 类对象模型
7.1 如何计算类的大小
先说结论:计算一个类的大小与计算一个结构体类型的大小规则是完全一致的。
class stu {
public:
char* getName();
int getAge();
private:
char name[20];
int age;
};
int main()
{
cout << sizeof(stu) << endl;
return 0;
}
这里的运行结果为24,字符数组占20个字节,整形占了4个字节,非常奇怪的是类中的成员函数并没有占用空间,这是为什么?
先举个简单的例子:一个小区有多户人家,每家的房子一定都是独立的,都有各自的卧室、客厅和厨房等等,但是若要建一个游泳池或者健身房有没有必要给每一家都建一个呢?是可以的,但是没必要,因为这类建筑对于每户人家的作用是一致的,会造成大量的空间浪费,所以比较好的方法是把它们独立出来在一个公共的区域去建,这样所有人都可以用,很大程度的减少了空间的浪费。
有了这个例子对于上面的问题就比较好理解了,其实类比到类,是一样的。
多户人家可以当作多个实例化出来的对象,每个对象中的成员变量可以当作对应的卧室、客厅和厨房,成员函数则当作健身房,其中成员变量必须是存储在不同的空间中,而因为每个对象中的成员函数的作用是相同的,要是每个对象都存储的话会造成空间浪费,因此在存储的时候可以把它们独立出来放在一块公共的代码段,不同的对象都可以找到然后调用它。
7.2 类对象的存储方式猜测
关于类对象的存储模型有以下三种:
-
对象中包含类的各个成员
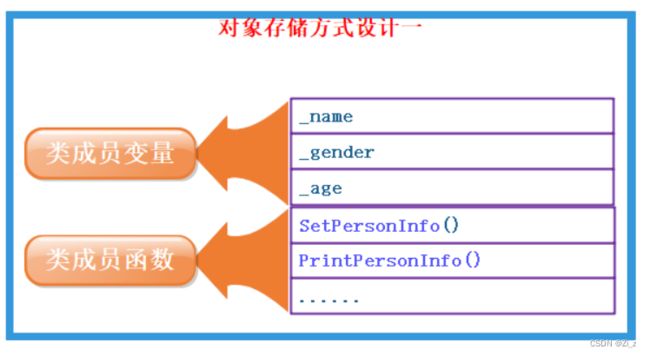
这种做法是有缺陷的,每个对象中成员变量是不同的,但是调用同一份函数,如果按照此种方式存储,当一个类创建多个对象时,每个对象中都会保存一份代码,相同代码保存多次,浪费空间。 -
代码只保存一份,在对象中保存存放函数的地址
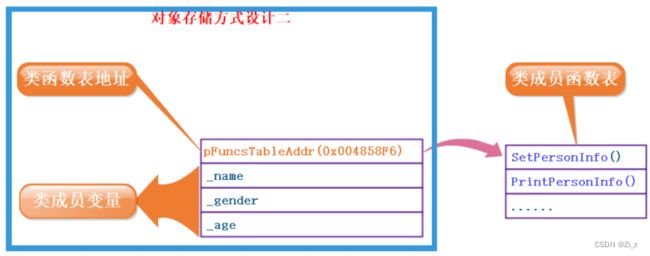
很大程度的解决了第一种空间浪费的问题,但没有完全解决。 -
只保存成员变量,成员函数存放在公共的代码段
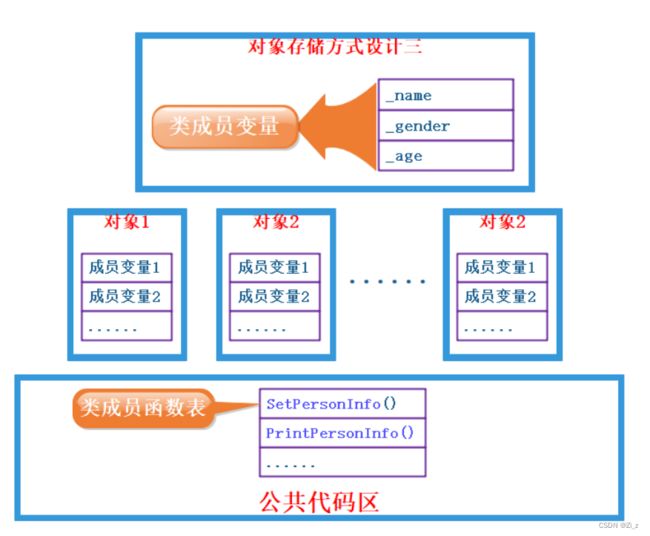
这种是最优的一种实现方法,有了上面提到的例子,可以发现的是类对象的存储模型就是采用的第三种方法,完美解决了空间的浪费。
注意:没有成员变量的类或者空类的大小只有一个字节,作为占位符不存储有效数据,告诉编译器对象存在。
7.3 结构体内存对齐规则
最开始提到过,计算类的大小与计算结构体类型大小的规则是一样的,都要遵循结构体内存对齐原则,具体的在这篇文章中详细地介绍了,这里不再赘述。
8. this指针
8.1 引出
先定义一个日期类:
class Date{
public:
void Init(int year, int month, int day) {
_year = year;
_month = month;
_day = day;
}
void Print(){
cout << _year << "-" << _month << "-" << _day << endl;
}
private:
int _year; // 年
int _month;// 月
int _day; // 日
};
int main()
{
Date d1, d2;
d1.Init(2022,1,11);
d2.Init(2022, 1, 12);
d1.Print();
d2.Print();
return 0;
}
输出结果:

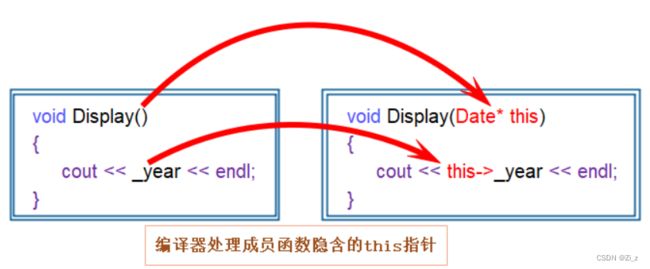
在主函数中定义了两个对象,分别调用Print函数输出了不同的日期,而两个对象都是调的同一个函数,上面说过不同的对象它们的成员函数所在的区域则是相同的,函数体中也没有不同对象的区分,那么函数是如何识别是哪个对象调用了我呢?
C++中通过引入this指针解决该问题,即:C++编译器给每个“非静态的成员函数“增加了一个隐藏的指针参数,让该指针指向当前对象,在函数体中所有“成员变量”的操作,都是通过该指针去访问。只不过所有的操作对用户是透明的,即用户不需要来传递,编译器自动完成。
因此上面的代码在被编译器处理后变成下面这样子:
//所有的非静态成员函数都会被处理,不一一写了
//处理前:
void Print(){
cout << _year << "-" << _month << "-" << _day << endl;
}
d1.Print();
d2.Print();
//处理后:
void Print(Date* const this) {
cout << this->_year << "-" << this->_month << "-" << this->_day << endl;
}
d1.Print(&d1);
d2.Print(&d2);
需要注意的是,this指针传参是编译器的工作,用户不需要显式地传,也不能,否则会报错,但是却可以在函数体里显式地使用this指针,因为有些场景会使用它。
8.2 this指针的特性
this指针的类型:类类型* const,即成员函数中,不能给this指针赋值。- 只能在“成员函数”的内部使用。
- this指针本质上是“成员函数”的形参,当对象调用成员函数时,将对象地址作为实参传递给this形参。所以对象中不存储this指针。
- this指针是“成员函数”第一个隐含的指针形参,一般情况由编译器通过ecx寄存器自动传递,不需要用户传递。
两个题:
- this指针存在哪里?
this指针虽然是编译器隐式传递的参数,但本质也是一个形式参数,是参数就会在函数调用时被依次压入到栈中,函数调用结束形参也随之被销毁了。 - this指针可以为空吗?
可以,但如果为空,则不可以在函数体中解引用访问对应的成员变量,因为对空指针解引用会报错。
总结
C++中的类是从C语言里的结构体进化而来,并且引入了面向对象的思想,即封装,使得成员变量和成员方法可以一起放在类中,使其之间的联系更加紧密,同时增加了类的访问限定符,不仅使得访问类中的成员更加规范化,而且也屏蔽了底层的部分实现细节,提高了代码的保密性。