运维自动化前三阶段
运维自动化前三阶段
-
纯手工阶段:手工操作重复地进行软件部署和运维;
-
脚本阶段:通过编写脚本、方便地进行软件部署和运维;
-
工具阶段:借助第三方工具高效、方便地进行软件部署和运维。
这几个阶段是随着运维知识、经验、教训不断积累而不断演进的。而且,第2个阶段和第3个阶段可以说是齐头并进,Linux下的第三方工具虽说已经不少了,但是Linux下的脚本编写对运维工作的促进作用是绝对不可以忽视的。 在DevOps出现之前,运维工作者在工作中还是以这两种方式为主。
Linux下好用的开源工具
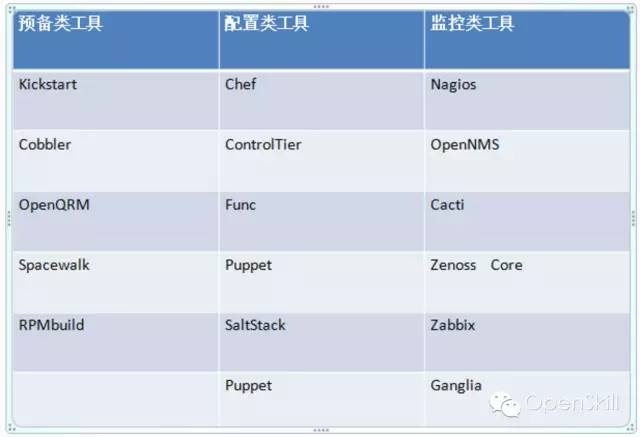
1、预备类工具:
Kickstart
kickstart安装是redhat开创的按照你设计好的方式全自动安装系统的方式。安装方式可以分为光盘、硬盘、和网络。
Cobbler
Cobbler是一个快速网络安装linux的服务,而且在经过调整也可以支持网络安装windows。该工具使用python开发,小巧轻便(才15k行代码),使用简单的命令即可完成PXE网络安装环境的配置,同时还可以管理DHCP,DNS,以及yum包镜像。
OpenQRM
openQRM提供开放的插件管理架构,你可用很轻松的将现有的数据中心应用程序集成到其中,比如Nagios和VMware。openQRM的自动化数据中心操作不但可用帮助你提高可用性,同时还可以降低您企业级数据中心的管理费用。针对数据中心管理的开源平台,针对设备的部署、监控等多个方面通过可插拔式架构实现自动化的目的,尤其面向云计算/基于虚拟化的业务。
Spacewalk
Spacewalk可管理Fedora、红帽、CentOS、SUSE与Debian Linux服务器。当你的数据中心拥有多台Linux服务器时,手动管理将不再是一个好的选择。Spacewalk就可以管理补丁、登录、更新。
在自动化运维和大数据云计算时代实现预设自动化安装服务器环境、应用环境等不仅可以提高运维效率,而且还能大大减少运维的工作任务及出错概率。尤其是对于在服务器数量按几百台、几千台增加的公司而言,单单是装系统,如果不通过自动化来完成,其工作量和周期不可想象。
2、配置管理类工具:
前浪:
Chef
Chef是一个系统集成框架,可以用Ruby等代码完成服务器的管理配置并编写自己的库。
ControlTier
ControlTier是一个完全开放源码系统的自动化服务管理活动的多个服务器和多个应用层(代码,数据,配置和内容) 。共同使用的ControlTier包括部署应用程序,控制它们的状态,并运行按需行政工作在多个服务器上。ControlTier是跨平台和工程同样的物理服务器,虚拟机,或云计算基础设施。
Func
Func是由红帽子公司以Fedora统一网络控制器Func,目的是为了解决这一系列统一管理监控问题而设计开发的系统管理基础框架,它是一个能有效的简化我们众多服务器系统管理工作的工具,其具备容易学习,容易使用,更容易扩展;功能强大而且配置简单等优点。
Puppet
puppet是一个开源的软件自动化配置和部署工具,它使用简单且功能强大,正得到了越来越多地关注,现在很多大型IT公司均在使用puppet对集群中的软件进行管理和部署。
后浪:
SaltStack
Salt一种全新的基础设施管理方式,部署轻松,在几分钟内可运行起来,扩展性好,很容易管理上万台服务器,速度够快,服务器之间秒级通讯。
Ansible
Ansible是新出现的运维工具是基于Python研发的糅合了众多老牌运维工具的优点实现了批量操作系统配置、批量程序的部署、批量运行命令等功能。
在进行大规模部署时,手工配置服务器环境是不现实的,这时必须借助于自动化部署工具。
3、监控类工具
Nagios
Nagios是一款免费的开源IT基础设施监控系统,其功能强大,灵活性强,能有效监控 Windows 、Linux、VMware 和 Unix 主机状态,交换机、路由器等网络设置等。一旦主机或服务状态出现异常时,会发出邮件或短信报警第一时间通知 IT 运营人员,在状态恢复后发出正常的邮件或短信通知。
OpenNMS
OpenNMS是一个网络管理应用平台,可以自动识别网络服务,事件管理与警报,性能测量等任务。
Cacti
Cacti是一套基于PHP、MySQL、SNMP及RRDTool开发的网络流量监测图形分析工具。它通过snmpget来获取数据,使用 RRDtool绘画图形,它的界面非常漂亮,能让你根本无需明白rrdtool的参数能轻易的绘出漂亮的图形。而且你完全可以不需要了解RRDtool复杂的参数。它提供了非常强大的数据和用户管理功能,可以指定每一个用户能查看树状结 构、host以及任何一张图,还可以与LDAP结合进行用户验证,同时也能自己增加模板,让你添加自己的snmp_query和script!功能非常强大完善,界面友好。
Zenoss Core
一个基于Zope应用服务器的应用/服务器/网络管理平台,提供了Web管理界面,可监控可用性、配置、性能和各种事件。
Zabbix
zabbix是一个基于WEB界面的提供分布式系统监视以及网络监视功能的企业级的开源解决方案。用于监控网络上的服务器/服务以及其他网络设备状态的网络管理系统,后台基于C,前台由PHP编写,可与多种数据库搭配使用。提供各种实时报警机制。
Ganglia
Ganglia是一个针对高性能分布式系统(例如,集群、网格、云计算等)所设计的可扩展监控系统。该系统基于一个分层的体系结构,并能够支持2000个节点的集群。它允许用户能够远程监控系统的实时或历史统计数据,包括:CPU负载均衡、网络利用率等。Ganglia依赖于一个基于组播的监听/发布协议来监控集群的状态。Ganglia系统的实现综合了多种技术,包括:XML(数据描述)、XDR(紧凑便携式数据传输)、RRDtool(数据存储和可视化)等。
数据监控和业务监控非常关键,及时发现问题,及时解决问题,监控系统主要包括:服务应用监控、主机监控、网络设备监控、网络连通性监控、网络访问质量监控、分布式系统监控、报警预设、监控图形化与历史数据等。
自动化对运维的意义
自动化就是运维为了减少重复枯燥的工作而建立的流程方法,而除此之外,自动化还能够带来减少人为错误、及时报警与故障恢复、提高业务可用性等好处。
运维工作自动化确实包含上述2个方面,归纳总结来其实就是:把零碎的工作集中化,把复杂的工作简单有序化,把流程规范化,最大化地解放生产力,也就是解放运维人员。
自动化的技能/意识对于运维工作至关重要。运维工作不是简单的使用工具,这里面还有很多技巧和意识。具体的技巧/意识包括:
-
如何驾驭这些琳琅满目的工具为己所用;
-
如何根据不同的应用环境来选用不同的工具;
-
如何根据应用来组合使用工具等等等等。
一定要记住一点:工具只是利用帮助人进行运维的,这中间还需要人的干预和决策,工具不能完全代替全部运维工作。还需要结合实际业务逻辑和业务场景,就像架构一样,并不是淘宝、百度等大公司的架构,一定适合任何公司和业务。
自动化运维范畴
-
安装自动化
-
部署自动化
-
监控自动化
-
发布自动化
-
升级自动化
-
安全管控自动化
-
优化自动化
-
数据备份自动化
前阶段在自动化管理和安全方面的技术实现,比如说HP和IBM出品的一些ITIL和ITSM产品等,比如HP Openview,IBM Tivoli等等。这些工具都有Linux的版本,与其他同类工具相比的优势应该在于他们的商业应用成熟度,都是老品牌。 现阶段有自动化的一些工具git、svn、Jenkins、docker等等,一些开源的软件!
工具选择
针对不同规模的架构,一个小规模的网站,到百万量级、千万量级的网站,我们选择的工具就有不同。
在选择上对于百万量级、千万量级的网站,我们应该考虑选择成熟的工具、性能高的工具、熟悉的工具。而对于小规模的网站,我们应该考虑选择一些开源的、免费的工具。
这个原则就是以应用为导向,百万量级、千万量级的网站牵涉的面广、要求高,不成熟的工具往往很难说服领导和公司使用,所以主要是在成熟度方面。
自动化运维规划
自动化的实现不是单纯学习几个工具就能够做好的,甚至于规划不好的情况,自动化不仅没有节省人力,反而带来了更多的问题。
所以运维人员在考虑自动化流程的过程中应该考虑如下几点原则:
-
根据应用选择工具;
-
对于关键应用,选择成熟度高的工具;
-
不能过分依赖一种工具,需要进行对比和分析;
-
对工具的特性做到精通;
-
是人驾驭工具,人要监督工具,而不是工具来驾驭人;
-
善于利用脚本实现定制化场景。
自动化经验积累
从专业性上分:
从工作方向上分:
-
经常逛逛一些不错的IT媒体网站和看看这方面的文章,可以多多涉猎和学习;
-
针对公司业务场景,选择一些自动化工具,登陆到官网学习和熟悉工作原理;
-
经常参加一些线下自动化运维的活动和媒体活动,多和一些自动化方面的大拿和资深人士交流。
运维的工作非常多且杂,几乎填满了我们的日常工作且看似无序,但如果抬头向上看,我们所做的一切其实就很有意义了!

运维的意义就是从无序的零碎工作中,做到有章可循,“不积跬步无以至千里”。运维投入的是时间和精力,打造出一套适合当下场景的运维体系建设,才是运维的投资回报率(ROI)。为了更好的帮助我们更好的了解运维体系建设,我们可从以下几个维度来了解下:从运维框架上分:
-
IaaS,主要分布基础设施;
-
PaaS,主要通过平台的维度对基础设施进行管控;
-
SaaS,主要通过精细化的服务,解决不断增长的痛点需求;
-
开发人员、测试人员、安全人员的工作主要分布在南北向上,涉及运维框架中某几个场景;
-
运维人员的工作在东西向和南北向都有,涉及运维框架中大部分场景;
-
基础运维:多方位的基础设施管理,如软件定义网络(SDN)、软件定义数据中心(SDDC)、软件定义存储(SDS)等
-
应用运维:从运维自动化入手,结合流程规范,对操作系统、应用管控、安全合规、系统监控等全面纳管;
-
业务运维:需要熟悉业务流程,从运营数据、日志数据、多方位监控数据等方面对业务事件快速响应;
-
基础运维:多方位的基础设施管理,如软件定义网络(SDN)、软件定义数据中心(SDDC)、软件定义存储(SDS)等
-
应用运维:从运维自动化入手,结合流程规范,对操作系统、应用管控、安全合规、系统监控等全面纳管;
-
业务运维:需要熟悉业务流程,从运营数据、日志数据、多方位监控数据等方面对业务事件快速响应