mysql(一) 使用注意事项及优化
初学mysql的时候、写了一份 "什么是CRUD? CRUD的操作" 的文章(18年的)
我开心看到有朋友经常在下面讨论一些问题、 但是以现在(今天 23年)回头看觉得 那些只是入门需要知道和掌握的、也刚好最近不是很忙 所以我准备整理下 mysql 使用注意事项及优化
写完也会慢慢完善、后面还会整理一些 索引、执行计划、底层的知识、我们一起学习、一起进步、欢迎指导修正。
基础的mysql写法、语句我就不再赘述了、需要看的上移 "什么是CRUD? CRUD的操作"
目录
1、Mysql大小写问题 (关键字 BINARY )
2、MySQL自身的缓存问题
3、合理使用exist & in
4、索引失效的情景 (常见的情景)
情景1:隐式转换导致索引失效
情景2:查询条件包含or且字段列不含索引
情景3:对索引的列进行数值运算,索引失效
情景5:当查询条件为大于等于、in等范围查询时,根据查询结果占全表数据比例的不同,优化器有可能会放弃索引,进行全表扫描
情景6:特殊的语句 <> ,not in、not exists、is not null 不走索引(辅助索引)
情景7:用or连接的两个含null索引字段,不走索引
情景8:联合索引不满足最左匹配原则
情景9:使用了select * 导致索引失效
情景10:索引列参使用了函数 导致索引失效
情景11:两列数据做比较,即便两列都创建了索引,索引也会失效
情景12:关键字(order by)和函数使用会导致索引失效
5、mysql数据量大的操作
6、索引不要超过6个、且不要在经常更新的字段上建立索引。
7、删除冗余和无效的索引
8、选取最适用的字段属性、尽量把字段设置为NOT NULL
由简到难:
1、Mysql大小写问题 (关键字 BINARY )
MySQL数据库是不区分大小写
创建表 t_test_user_info
CREATE TABLE `t_test_user_info` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`name` varchar(50) NOT NULL DEFAULT '',
`age` varchar(5) NOT NULL DEFAULT '',
`create_by` varchar(50) NOT NULL DEFAULT '',
`create_time` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COMMENT='模拟测试表';插入两条数据(name 字段 都是大小的区别)
INSERT INTO `t_test_user_info`
( `name`, `age`, `create_by`, `create_time`)
VALUES
('yzh', '13', 'admin', NOW()),
('Yzh', '15', 'admin', NOW()),
('yzH', '17', 'admin', NOW()),
('YZH', '19', 'admin', NOW());写查询语句 select name from t_test_user_info where name="yzh";
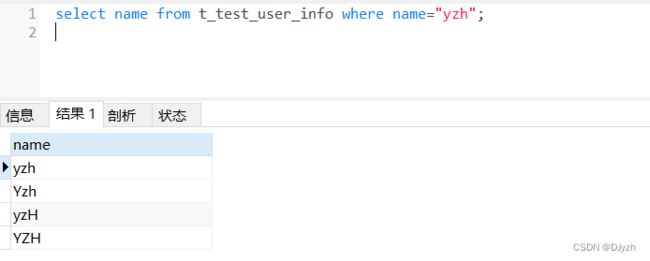
结果是所有的数据都查询出来了、那怎么解决呢
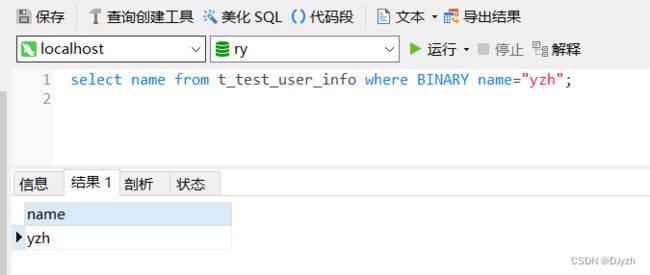
写查询语句加关键字 BINARY
select name from t_test_user_info where BINARY name="yzh";
2、MySQL自身的缓存问题
2.1 MySQL的自身的缓存是严格基于 sql 语句的(MySQL自身缓存是严格区分sql语句的大小写的)
select === SELECT 关键字 查询是一样的、但是MySQL自身缓存是严格区分大小写、导致不能缓存命中。
select name from t_test_user_info where id=1;
SELECT name FROM t_test_user_info WHERE id=1;2.2 MySQL的sql语句里面出现不确定信息(例如使用 now() 函数)自身缓存将无法被使用、查询的结构不会被缓存起来
select name, NOW() as newTime from t_test_user_info where id=1;3、合理使用exist & in
in 是把外表和内表作hash连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。如果查询的两个表大小相当,那么用in和exists差别不大。
如果子查询表大的用exists,子查询表小的用in
4、索引失效的情景 (常见的情景)
前提 主键 id
辅助索引(非聚簇索引) age age_index
没有索引 name
ALTER TABLE `t_test_user_info` ADD INDEX age_index (`age`)情景1:隐式转换导致索引失效
`age` varchar(5)
在查询时,where条件是字符串,要带引号 (结果命中索引、扫描2行)
select age from t_test_user_info where age="13";![]()
像上面这条语句又涉及到、索引覆盖和回表 在这里不详细说了、后面写索引的时候再聊。
情景2:查询条件包含or且字段列不含索引
select name,age from t_test_user_info where age="13" or name="yzh";
-- 执行计划
EXPLAIN select name,age from t_test_user_info where age="13" or name="yzh";执行计划结果

age or name == 辅助索引+or+无索引、会走索引列,但无索引的列会进行全表扫描
-- 执行计划
EXPLAIN select name,age from t_test_user_info where id="2" or age="13";
-- 执行计划
EXPLAIN select name,age from t_test_user_info where age="13" or id="2";

辅助索引 +or+ 主键索引
主键索引 +or+ 辅助索引
结果显示可能命中索引,实际没有命中的 key==null (索引) type是ALL全表扫描
情景3:对索引的列进行数值运算,索引失效
select name,age from t_test_user_info where age * 1 = 13;
-- 执行计划
EXPLAIN select name,age from t_test_user_info where age * 1 = 13;![]()
情景4:like且%为前缀的非覆盖索引
%在前面,不走索引、type 是ALL 全表扫描
select name,age from t_test_user_info where age like "%3";
-- 执行计划
EXPLAIN select name,age from t_test_user_info where age like "%3";![]()
%不在在前面,走索引、type 是 rang 根据索引范围扫描,返回匹配值域的行 rows 扫描1行
select name,age from t_test_user_info where age like "23%";
-- 执行计划
EXPLAIN select name,age from t_test_user_info where age like "23%";![]()
情景5:当查询条件为大于等于、in等范围查询时,根据查询结果占全表数据比例的不同,优化器有可能会放弃索引,进行全表扫描
还有在实际的特殊情况 :比如查询的结果集数据超出大部分会导致全部表扫描(优化器认为没有必要走索引)
比如超出25%大部分都1开头的年龄 使用 "1%" (实际遇到这个也可以用limit 来分解结果集 )
-- 执行计划
EXPLAIN select name,age from t_test_user_info where age like "1%";
用limit 来分解结果集 支持走索引
-- 执行计划
EXPLAIN select name,age from t_test_user_info where age like "1%" limit 2;
情景6:特殊的语句 <> ,not in、not exists、is not null 不走索引(辅助索引)
情景7:用or连接的两个含null索引字段,不走索引
情景8:联合索引不满足最左匹配原则
情景9:使用了select * 导致索引失效
情景10:索引列参使用了函数 导致索引失效
情景11:两列数据做比较,即便两列都创建了索引,索引也会失效
情景12:关键字(order by)和函数使用会导致索引失效
5、mysql数据量大的操作
若插入数据过多,考虑批量插入、避免同时修改或删除过多数据分批操作
6、索引不要超过6个、且不要在经常更新的字段上建立索引。
索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。
7、删除冗余和无效的索引
如果表中存在索引:
KEY `name_age` (`name`, `age`);
KEY `age` (`age`);上面第二个索引属于冗余索引,需要删除掉。
8、选取最适用的字段属性、尽量把字段设置为NOT NULL
MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快。因此,在创建表的时候,我们可以将表中字段的宽度设得尽可能小,同时应该尽量把字段设置为NOT NULL,这样在将来执行查询的时候,数据库不用去比较NULL值。