Kettle学习笔记
Kettle学习笔记
文章目录
- 1.kettle概述
-
- 1.1 Kettle简介
- 1.2 Kettle核心概念
- 2.Kettle下载和安装
-
- 2.1 Kettle下载
- 2.2 Kettle安装
- 3.输入
-
- 3.1 CSV文件输入
- 3.2 文本文件输入
- 3.3 Excel输入
- 3.4 get_data_from_xml
- 3.5 json_input
- 3.6 生成纪录
- 3.7 MySQL表输入
- 3.8 Oracle表输入
- 4.输出
-
- 4.1 Excel输出
- 4.2 文本文件输出
- 4.3 SQL文件输出
- 4.4 MySQL表输出
- 4.5 更新
- 4.6 MySQL-MySQL插入/更新
- 4.7 删除
- 4.8 MySQL-Oracle插入/更新
- 4.9 Oracle-Oracle插入/更新
- 4.10 Oracle-MySQL插入/更新
- 5.转换
-
- 5.1 concatfields
- 5.2 值映射
- 5.3 增加常量
- 5.4 增加序列
- 5.5 字段选择
- 5.6 计算器
- 5.7 字符串剪切、替换、操作
- 5.8 去除重复记录、排序记录
- 5.9 唯一行(哈希值)
- 5.10 拆分字段
- 5.11 列拆分为多行
- 5.12 列转行
- 5.13 行转列
- 5.14 行扁平化
- 5.15 替换NULL值
- 5.16 写日志
- 6.流程
-
- 6.1 switch/case
- 6.2 过滤记录(if/esle)
- 6.3 空操作
- 6.4 中止
- 7.查询
-
- 7.1 HttpClient
- 7.2 数据库查询
- 7.3 数据库连接
- 7.4 流查询
- 8.连接
-
- 8.1 合并记录
- 8.2 记录关联(笛卡尔积)
- 8.3 记录集关联
- 9.统计和映射
-
- 9.1 分组
- 9.2 映射
- 10.脚本
-
- 10.1 javascript代码
- 10.2 java代码
- 10.3 执行SQL脚本
- 11.作业
-
- 11.1 作业
- 11.2 全局参数
- 11.3 常量传递
- 11.4 转换命名参数
- 11.5 设置变量、获取变量
- 11.6 作业中设置变量
- 11.7 发邮件
- 11.8 作业定时任务
1.kettle概述
1.1 Kettle简介
ETL 数据抽取,转换,加载
Extract-transform-load 数据抽取 数据 装载的过程,对于企业或者行业应用来说,
我们经常沪遇到各种数据的处理,转换,迁移,所以了解并掌握一种ETL工具的使用,
必不可少,这里我们要学习的ETL工具就是Kettle.
kettle是一款国外开源的ETL工具,纯Java编写,可以在Windows,linux,unix
上运行,绿色无需安装,数据抽取高效稳定。
Kettle是个工具集,它允许你管理来自不同数据库的数据,通过提供一个图形化的
用户环境来描述你想做什么,而不是你想怎么做。
kettle中有两种脚本文件,transformation和job,
transformation完成针对数据的基础转换,一个对数据进行转换,
job则完成整个工作流的控制 —一个对工作流进行控制
kettle(现在已经更名为PDI,Pentaho Data Integration-Pentaho 数据集成)
步骤度量:
kettle可以使用图形化的方式定义复杂的ETL程序和工作流
kettle里的图就是转换和作业
使IT领域更贴近于商务领域
转换–处理抽取,转换,加载各种对数据行的操作
读取文件 – 过滤数据行 – 数据清洗 – 加载到数据库
在kettle里,数据的单位是行
跳 —数据通道
行集:1000行 数据行缓存
数据类型:
string:字符类型数据
Number:双精度浮点数
integer:带符号长整型(64位)
bigNumber:任意精度数据
Date:带毫秒秒精度的日期时间值
Boolean:取值为true和false的布尔值
Binary:二进制字段可以包含图像,声音,视频的二进制数据
元数据
名称:行里的字段名是唯一的
数据类型:字段的数据类型
格式:
长度:
精度:
并行
跳的这种基于行集缓存的规则允许每个步骤都是由一个独立的线程运行,
这样并发程度最高。这一规则也允许数据以最小消耗内存的数据流的方式来处理。
在数据仓库里,我们经常要处理大量数据,所以这种并发低消耗内存的方式也是
ETL工具的核心需求。
对于kettle的转换,不可能定义一个执行顺序,因为所有步骤都以并发方式执行:
当转换启动后,所有步骤都同时启动,从它们的输入跳中读取数据,并把处理过的数据
写到输入跳,直到输入跳里不再有数据,就中止步骤的运行。当所有的步骤都中止了,
整个转换就中止了。
1.2 Kettle核心概念
Spoon:通过图形化接口,用于编辑作业和转换的桌面应用。
Kettle的执行分为2个层级:
作业:Job
转换:Transformation
2.Kettle下载和安装
2.1 Kettle下载
Kettle可以在http://kettle.pentaho.org/网站下载



http://sourceforge.net/projects/pentaho/files/Data%20Integration/7.1/pdi-ce-7.1.0.0-12.zip/download

2.2 Kettle安装
下载kettle压缩包,因kettle为绿色软件,解压缩到任意本地路径即可。然后打开Spoon.bat,如图所示:

因为,运行spoon在不同的平台上运行spoon所支持的脚本:
Spoon.bat:在Windows平台上运行spoon;
Spoon.sh:在Linux、AppleOSX、Solaris平台上运行Spoon。


驱动jar包 放到data-integration\lib目录下
想要kettle连接到MySQL数据库,就要放入MySQL的驱动程序
MySQ驱动下载:
https://dev.mysql.com/downloads/connector/j/
解压后jar包 放到data-integration\lib目录下
Oracle驱动:

3.输入
3.1 CSV文件输入
1.新建一个转换,点击核心对象–>输入–CSV文件输入:

2.CSV文件输入组件配置:
cvs文件:

CSV组件配置界面:

3.运行结果:

3.2 文本文件输入
1.新建一个转换,点击核心对象–>输入–文本文件输入:

2.文本文件组件配置:
文本文件.txt

文本文件组件界面配置:

获取字段:

3.运行结果:

3.3 Excel输入
1.新建Excel输入

2输入设置

选择对应的Sheet:

获取字段:

3输出设置:

4结果

3.4 get_data_from_xml
get_data_from_xml:
xpath:xml路径语言,它是一种用来确定xml文档中某部分位置的语言
xpath基于xml的树状结构,提供在数据结构树中寻找节点的能力。
选取节点xpath使用路径表达式在xml文档中选取节点。节点是通过沿着路径或者step来选取的。
语法:
/ 从根节点寻找
// 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置
. 选择当前节点
@ 选取属性
bookstore 选取bookstore元素的所有子节点
/bookstore 选取根元素bookstore
bookstore/book 选取bookstore的子元素的所有book元素
//book 选取所有book子元素,而不管他们在文档中的位置
bookstore//book 选择属于bookstore元素的子元素的所有book元素,而不管他们在文档中的位置
//@lang 选取名为lang的所有属性
需求说明: 当从其他如WebService接口获取到的xml格式的数据时,需要将xml格式数据存入数据库表中,故借助Get data from xml组件进行转换
需求分析: 故该案例中可以简单使用Get data from xml组件进行转换与Excel输出组件进行测试即可
要求: 从xml文件中提取testDescription、rowID、v1、v2数据保存到excel中
数据源:data.xml,内容如下

期望的结果:

设计转换:

转换配置:
Step1:Get data from xml 配置
双击组件,写上步骤名称

切换到“内容”菜单,配置读取路径,如下:

切换到“字段”菜单,配置希望读取到的字段,如下所示:

Excel输出组件配置
- 双击打开,设置步骤名称,如Excel-Output
- 选择输出文件所在路径,可以设置其他的内容,具体如下:

获取字段,得到目标字段如下:

运行转换:
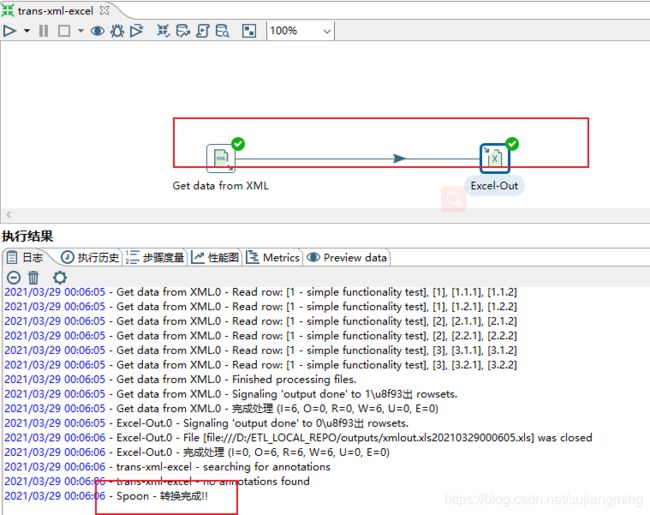
结果如下:
3.5 json_input
json
jsonpath:类似于xpath在xml文档中的定位,jsonPath表达式通常用来路径检搜或者位置json的。
点记法: $.store.book[0].title 常用点记法
括号记法:$['store']['book'][0]['title']
1.car_factory.js数据:
{
“RECORDS”: [
{
“factory_id”: “10”,
“factory_name”: “一汽奔腾”,
“name_index”: “Y”,
“picture_path”: null
},
{
“factory_id”: “107”,
“factory_name”: “劳斯莱斯”,
“name_index”: “L”,
“picture_path”: null
},
{
“factory_id”: “108”,
“factory_name”: “阿斯顿马丁”,
“name_index”: “A”,
“picture_path”: null
},
{
“factory_id”: “11”,
“factory_name”: “一汽马自达”,
“name_index”: “Y”,
“picture_path”: null
}
]
}
2.选择json文件:

配置字段项:

可以选择预览:
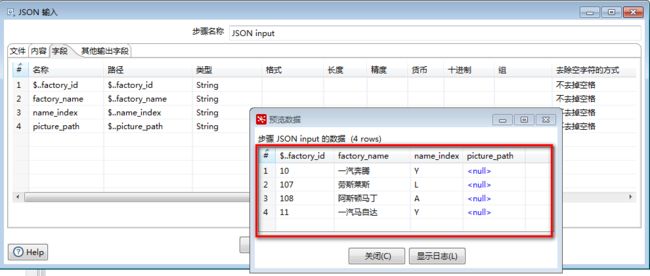
运行结果:

3.6 生成纪录
生成纪录:数据仓库中绝大部分的数据都是业务系统生成的动态数据,但是其中一部分维度数据不是动态的,
比如:日期维度
静态维度数据可以提前生成。
1.配置:
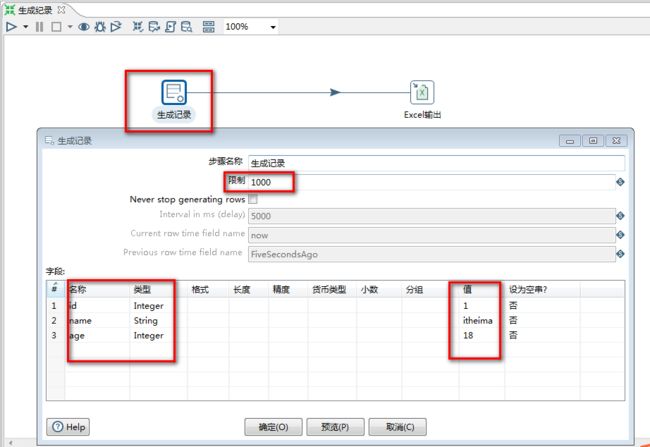
2.运行结果:

3.7 MySQL表输入
1.配置:

数据库连接配置:

选择到表,获取SQL查询语句:

运行结果:

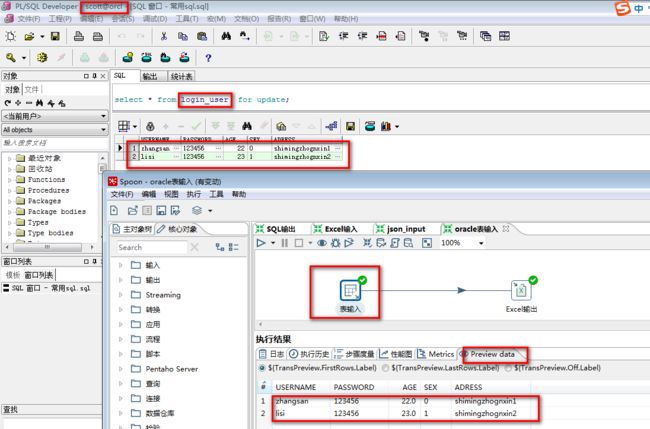
3.8 Oracle表输入
1.oracle数据库连接配置

2.连接测试

3.oracle数据库连接成功:

4.设为共享:

5.选择到表,获取SQL查询语句:

6.oracle表输入

7.结果:
4.输出
4.1 Excel输出
Excel输出:
Excel输出 ---- 输出.xls 文件
Microsoft Excel输出 ---- 输出.xlsx文件
任务:
从MySQL数据库的mysql库的user表读取数据插入到excel的.xls和.xlsx文件中
1.配置:
文件选择界面:
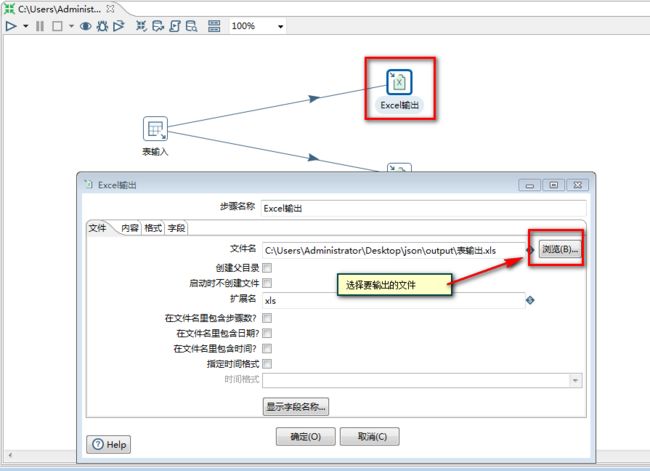
获取字段界面:

2.运行结果:


4.2 文本文件输出
文本文件输出:
任务:从mysql数据库的mysql库的user表读取数据插入到.text和.cvs的文件中
1.配置:
文件界面设置:

字段界面设置:

2.运行结果:


4.3 SQL文件输出
sql输出:
获取mysql库的user表的结构和数据的sql文件
SQL文件输出可以导出数据库表的结构和数据:

SQL文件输出:

输出的是建表的语句:

4.4 MySQL表输出
表输出:是对第一次全量同步数据时使用的。相当于“插入”操作
对数据不做校验,数据入库效率高,可能会有重复数据入库,适用于数据初始化操作,数据量大的情况。

1.选择"表输出"控件

2.表输出设置

3.运行结果:

数据库结果:

4.5 更新
更新:
把数据库已经存在的记录与数据流里面的记录进行对比,
如果不同就进行更新;
注意:如果记录不存在,则会出现错误!
任务:从Excel中读取数据,并把数据更新到test数据库的user中
只有更新功能,当数据由更新时,执行"更新"操作,没有插入功能
1.选择“更新”控件

2.更新设置

3.运行结果:
更新前:

更新后:

4.6 MySQL-MySQL插入/更新
插入更新
把数据库已经存在的记录与数据流里面的记录进行比较,
如果不同就进行更新,
如果不存在,则会插入数据
有“插入”和"更新"功能。
当数据有新增时,执行“插入”操作;
当数据有更新时,执行“更新”操作
先做数据校验,如有重复则更新,没有则插入。
1.选择“插入/更新”控件

2.插入/更新设置

3.运行结果
执行前:

执行后:
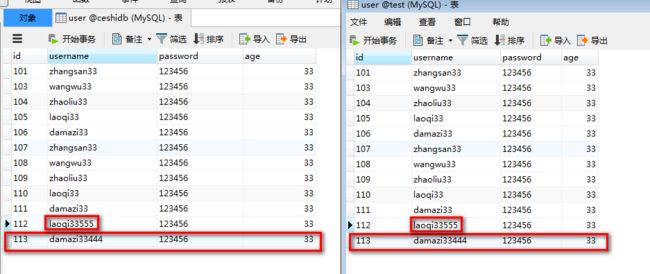
id为113的记录插入了test库的user表中,同时更新id=112的username=laoqi33555
4.7 删除
删除:
删除数据库表中指定条件的数据。
从mysql数据库user表中删除指定id为1的数据
1.选择"删除"控件

2.“删除”设置



3.运行结果:
执行前:

删除后:

id为101的记录被删除。
4.8 MySQL-Oracle插入/更新
1.选择"插入/更新"控件
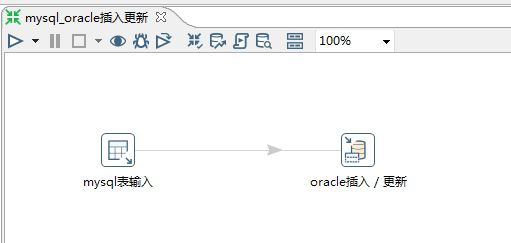
2.mysql输入设置

3.oracle输出设置

3.运行结果:
执行前:

执行后:

4.9 Oracle-Oracle插入/更新
1.选择“插入/更新”控件

2.oracle输入设置

3.oracle输出设置

4.运行结果:
运行前:

运行后:

4.10 Oracle-MySQL插入/更新
1.选择“更新”控件

2.oracle输入设置

3.mysql输出设置

4.运行结果:
执行前:

执行后:

5.转换
转换:清洗 转换 工作量是ETL的2/3
5.1 concatfields
多个字段连接起来形成一个新的字段,concatField:字段连接
从user表中获取usernaeme和password,并把他们连接起来,输入到Excel中
1.选择“concatfields”控件
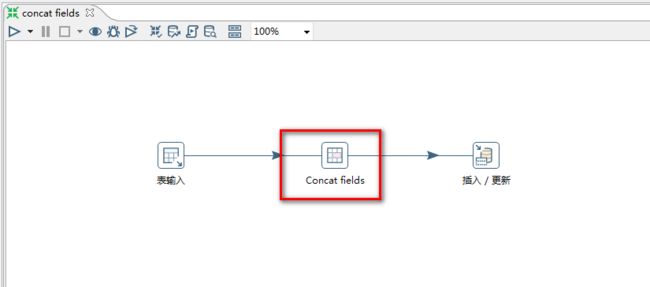
2.concatfields设置:

3.运行结果:

5.2 值映射
值映射就是把字段的一个值映射成其他的值。
系统1: 1 男 2 女
系统2: f 男 m 女
数据仓库统一为: female 男 male 女
任务:从Excel中读取数据,并把gender里面的f和m转换为female和male,写入到Excel
1.选择“值映射”控件
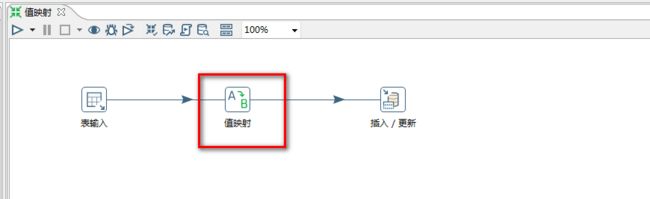
2.值映射设置:

3.运行结果:
执行前:

执行后:

5.3 增加常量
增加常量:就是在本身的数据流里面添加一列数据,该列数据都是相同的值。
任务:从User中读取数据,增加一个新列language值为en,把数据保存到user中。
1.选择“增加常量”控件:

2.增加常量设置:

3.运行结果:
执行前:

执行后:

5.4 增加序列
增加序列:是给数据流添加一个序列字段。
任务:从Excel读取数据,并添加序列,把数据保存到User中
1.选择“增加序列”控件:

2.增加序列设置:

3.运行结果:
执行前:
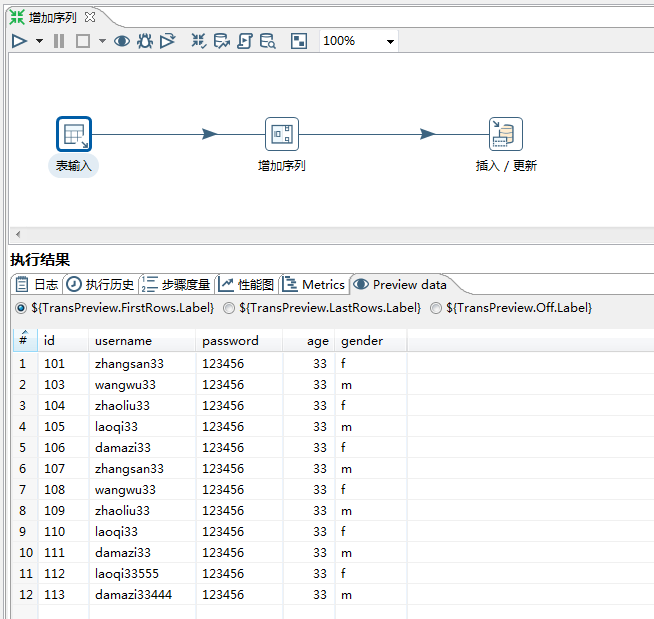
执行后:

5.5 字段选择
字段选择:是从数据流中选择字段、改变名称、修改数据类型。
任务:从user中读取数据,移除language和country,并把phone列名改为telphone,
id列明改为key,把gender列名改为sex
1.选择“字段选择”控件

2.字段选择设置:
修改字段名:

移除字段age:

3.运行结果:
执行前:

执行后:

5.6 计算器
计算器:是一个函数集合用来创建新的字段,还可以设置字段是否移除(临时字段)。
任务:从user中读取数据,生成name(username,password),quarter,week_of_day,account列,
把数据 存在到User表中。
1.选择"计算器"控件

2.计算器设置:

选择计算类型:

3.运行结果:
执行前:

执行后:

5.7 字符串剪切、替换、操作
字符串剪切:是指定输入流字段裁剪的位置剪切出新的字段
字符串替换:是指定搜索内容和替换内容,如果输入流字段匹配上搜索内容就进行替换生成新字段
字符串操作:去除字符串两端的空格和大小写切换,并生成新的字段
场景:从user中读取数据,
获取username的首位,生成xian字段, —剪切
把gender中的f替换成男,m替换成女,生成新的gender_desc字段 --替换
去掉useername中的空格,字符串变成大写,生成username_upper字段
1.选择“剪切字符串”,“字符串替换”,“字符串操作”控件

2.“剪切字符串”设置

3.“字符串替换”设置

4.“字符串操作”设置
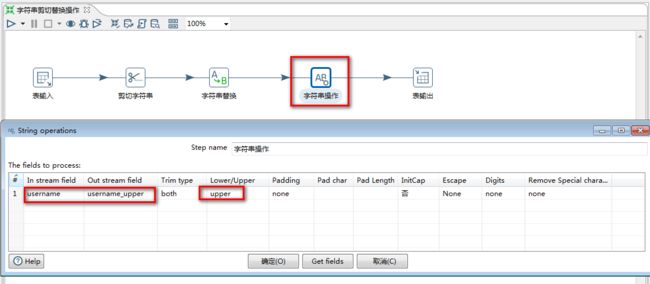
5.运行结果:
执行前:

执行后:

5.8 去除重复记录、排序记录
排序记录:是按照指定字段的升序或者降序对数据流排序 —排序
去除重复记录:去除数据流里面相同的数据行 ----去除重复
必须先去数据流进行排序
任务:从user中读取数据,去除重复的数据,并保持到user中
1.选择“排序记录”,“去除重复记录”控件

2.“排序记录”设置

3.“去除重复记录”设置

4.运行结果:
执行前:

排序后:

去除重复记录后:

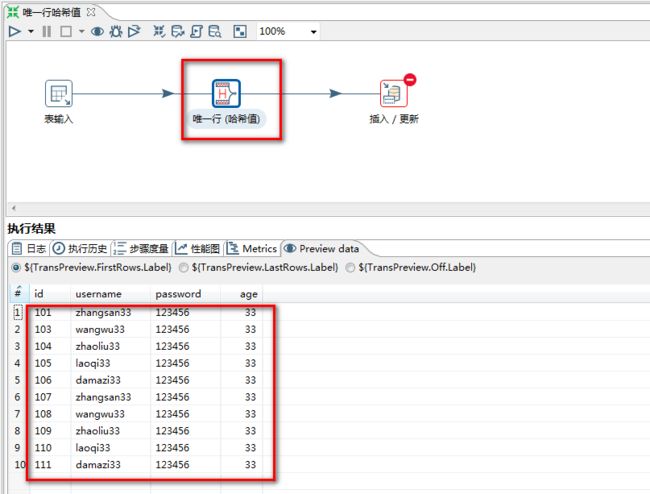
5.9 唯一行(哈希值)
唯一行(哈希值):删除数据流中重复的行
注意:唯一行(哈希值)和(排序记录+去除重复行)效果一样的,但实现的原理不同!
唯一行(哈希值)的效率更高
任务:从user中读取数据,去除重复的数据,并保存到user中
1.选择“唯一行(哈希值)”控件

2.“唯一行(哈希值)”设置

3.运行结果:
执行前:

执行后:
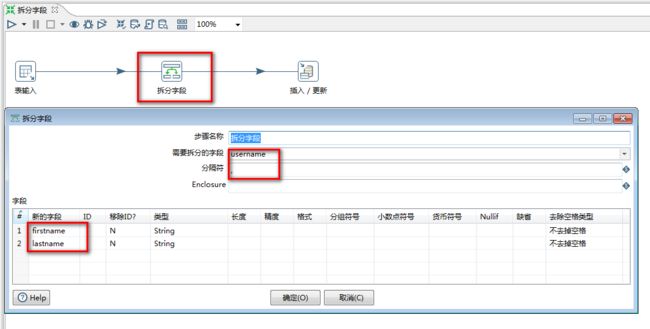
5.10 拆分字段
拆分字段:是把字段按照分隔符拆分成两个或多个字段
注意:拆分后,原字段就不存在于数据流中!
任务:从user中读取数据,把username拆分为firstname和lastname,并保存数据到user中
1.选择“拆分字段”控件

2.“拆分字段”设置
3.运行结果:
执行前:

执行后:

5.11 列拆分为多行
列拆分为多行就是把指定分隔符的字段进行拆分为多行。----1行数据 拆分为多行 ----行转列
任务:从user表中读取数据,把hobby列拆分为多行,并保存到user中
1.选择“列拆分为多行”控件

2.“列拆分为多行”设置:

3.运行结果:
5.12 列转行
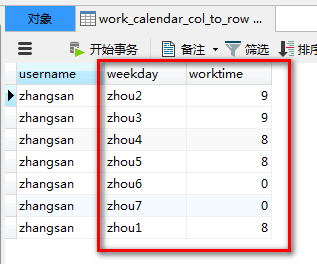
列转行:就是如果数据一列有相同的值,按照指定的字段,把多行数据转换为一行数据 —列转行
去除一些原来的列名,把一列数据变为字段
注意:列转行之前数据流必须进行排序!
任务:从user中读取数据,按照姓名进行分组,把星期、工作小时变成列转行,
保存到user中。
1.选择“列转行”控件

2.“排序记录”设置

3.“列转行”设置

3.运行结果:
执行前:

执行后:
5.13 行转列
行转列:就是把数据字段的字段名转换为一列,把数据行变为数据列 ----行转列
任务:从user中读取数据,把星期工作小时行转为星期列和工作小时列,把数据保存到user中
1.选择“行转列”控件

2.“行转列”设置:

3.运行效果:
执行前:

执行后:

5.14 行扁平化
行扁平化:就是把同一组的多行数据合并为一行。
注意:只有数据流的同类数据数据行记录一直的情况下才可使用! —记录行数一样才可以用
数据流必须进行排序,否则结果会不正确!
任务:从user中读取数据,把数据进行扁平化处理,存在user中
1.选择“行扁平化”控件:

2.“行扁平化”设置:

3.运行结果:
5.15 替换NULL值
替换null值:把null转换为其他的值
null值不好进行数据分析
任务:从user中读取数据,age列的空值使用28来替换,并保存到user中
1.选择“替换null值”控件

2.“替换null值”设置:

3.运行结果:
执行前:

执行后:

5.16 写日志
写日志:主要是在调试的时候用,把日志信息打印到日志窗口中。
任务:从user中读取数据,向日志输出窗口打印出所有的数据信息
1.选择“写日志”控件
2.“写日志”设置:

3.运行结果:

6.流程
流程:主要控制数据流程和数据流向
6.1 switch/case
switch/case:让数据流从一路到多路
任务:从user中读取数据,按sex进行数据分类,把女性,男性,保密分别保存不同的
在user中
1 表示男性
0 表示女性
2 表示保密
1.选择“switch/case”控件:

2.“switch/case”设置:

3.运行结果:
执行前:
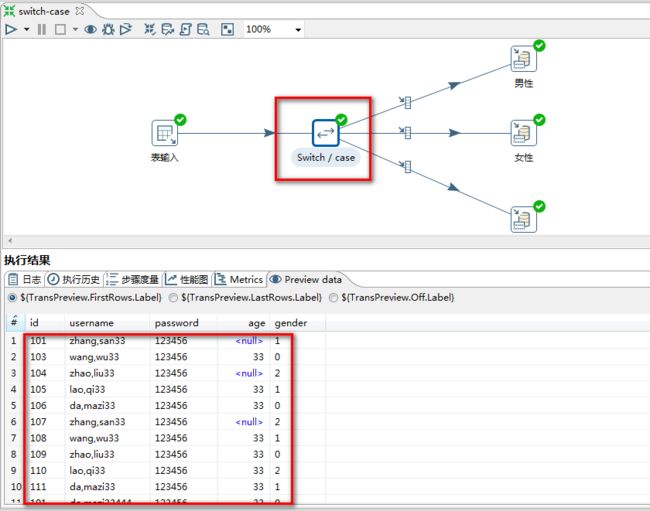
执行后:
男性:

女性:
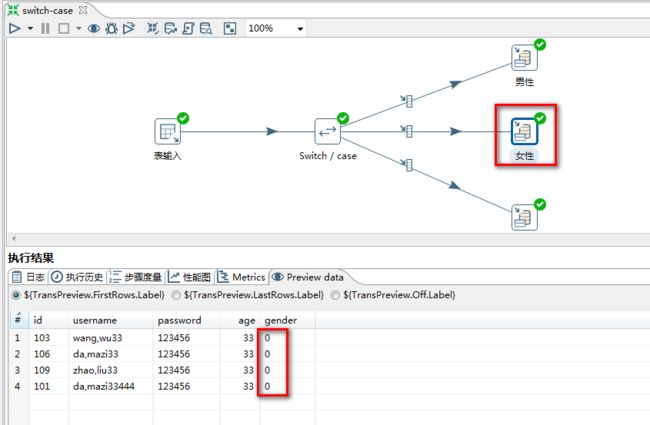
保密:

6.2 过滤记录(if/esle)
过滤记录(if/else):让数据流从一路到两路,相当于if…else…
任务:从user中读取数据,分离出sex为1的数据,保存到不同的user中
1.选择“过滤记录”控件:

2.“过滤记录”设置:

3.运行结果:
执行前:

执行后:
男性分支:
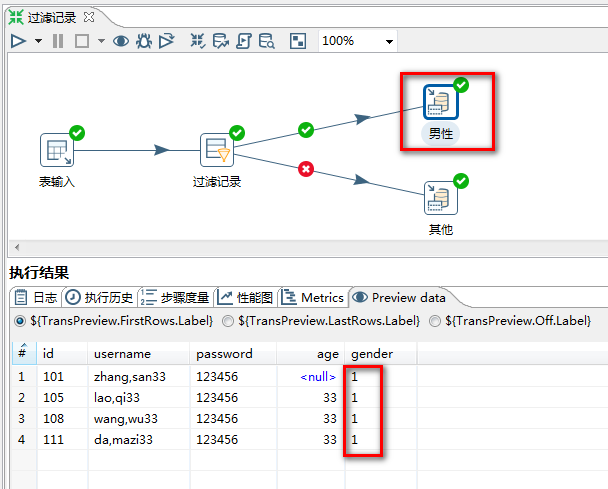
其他分支:

6.3 空操作
空操作:一般作为数据流的终点
(在kettle的sample中经常使用,但是在实际开发中很少使用)
1.选择“空操作”控件:

2.“空操作”设置
“过滤记录”设置:

"空操作"设置:

3.运行结果:

6.4 中止
中止:中止是数据流的终点,如果有数据到这来,将会报错。
用来校验数据的时候使用。
任务:从user中读取数据,过滤gender中不为空的数据,
不为空的数据保存在user_man中,
如果出现为空的数据就停止转换。
1.选择"中止"控件:

2.“过滤记录”设置:

3.“中止”设置:

4.运行结果:

7.查询
查询:是用来查询数据源里的数据并合并到主数据流中 —获取数据
7.1 HttpClient
HTTP client:是使用get的方式提交请求,获取返回的页面内容
自定义常量数据:
任务:从网络上获取xml,解析出productID,productName,supplierID,
categoryId,保存到user中
地址:http://services.odata.org/V3/Northwind/Northwind.svc/Products/
1.选择“HttpClient”控件

2.HttpClient设置:
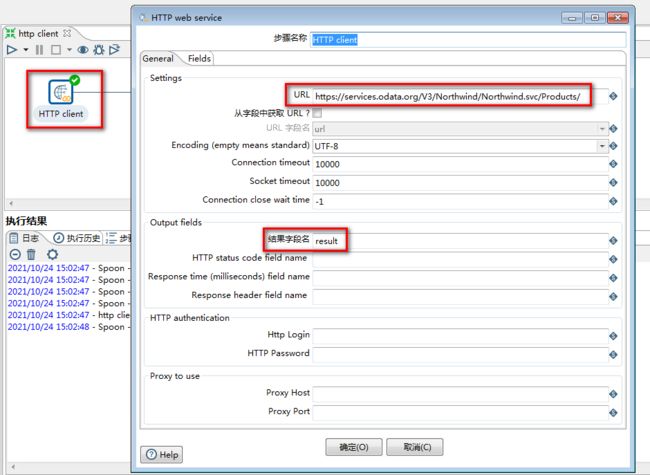
3.Get data from XML设置:
文件设置:

内容设置:

字段设置:

4.运行结果:

7.2 数据库查询
数据库查询:就是数据库里面的左连接 ----同一个库
左连接就是两张表执行左关联查询,把左边的表数据全部查询出来。
任务:从user表中读取数据,根据gender从user_gender表中获取name保存到user中
1.选择“数据库查询”控件

2.“数据库查询”设置:

3.运行结果:

7.3 数据库连接
数据库连接:可以执行两个数据库的查询,和单参数的表输入
任务:从user中读取数据,连接到另外一个数据的dender,把数据保存到user中 ----不同的库
1.选择“数据库连接”控件:

2.“数据库连接”设置:

3.运行结果:
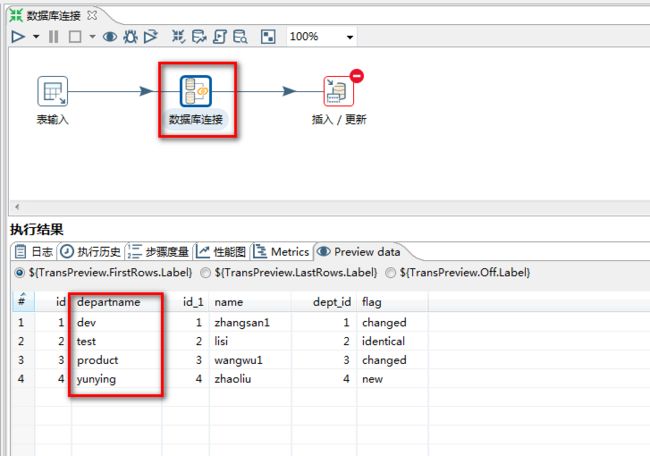
7.4 流查询
流查询:在查询前把数据都加载到内存中,并且只能进行等值查询
任务:从user中读取department和employee的数据,根据dept_id来查询dept_name,
—针对Excel数据把数据保存到user中。
1.选择“流查询”控件:

2."流查询"设置:
employees设置:

departments设置:

“流查询”设置:

3.运行结果:



8.连接
连接: 结果集通过关键字进行连接
8.1 合并记录
合并记录:是用于将两个不同来源的数据合并,这两个来源的数据分别为旧数据和新数据,
该步骤将旧数据和新数据按照指定的关键字匹配、比较、合并。
标志字段:设置标志字段的名称,标志字段用于保存比较的结果,比较结果有下列几种:
identical: --旧数据和新数据一样
changed: --数据发生了变化
new: --新数据中有而旧数据中没有的记录
deleted: --旧数据中有而新数据中没有的记录
关键字段:用于定位量数据源中同一条数据
比较字段:对于两个数据源中的同一条记录,指定需要比较的字段
合并后的数据将包括旧数据来源和新数据来源里的所有数据,对于变化的数据,
使用新数据代替旧数据,同时在结果里用一个标示字段,来指定新旧数据的比较结果。
任务:从user中读取新数据和旧数据,合并记录,标记处new,delete,changed,identical,把数据保存到user中
1.选择“合并记录”控件

2.“合并记录”设置:

3.运行结果:
执行前:


执行后:

8.2 记录关联(笛卡尔积)
记录关联(笛卡尔积输出):就是对两个数据流进行笛卡尔积操作。
任务:从user中读取两位和三位数,完成两位和三位数的组合(笛卡尔积),把结果存入user中。
1.选择”记录关联(笛卡尔积)“控件

2.“记录关联(笛卡尔积)”设置

3.运行结果:
执行前:


执行后:

8.3 记录集关联
记录集关联:就像数据库的左连接left join,右连接 right join,内连接 inner join,外连接 out join
注意:在进行记录集连接之前,应该要对记录集进行排序。
任务:从employee表和department表中读取数据,进行左连接,右连接,外连接,把数据保存到
dept_employ表中
1.选择“记录集关联”控件:

2.“记录集关联”设置:

3.运行结果:
执行前:


执行后:

9.统计和映射
统计: 数据的采样和统计功能
9.1 分组
分组:分组是按照某一个或某几个进行分组,同时可以将其余字段按照某种规则进行合并。
注意:分组之前数据应该进行排序!
任务:从user中读取数据,按照group进行分组统计,把结果保存到user中
1.选择“分组”控件

2.“分组”设置:

3.运行结果:
运行前:

运行后:

9.2 映射
映射:类似于 方法里面 调子方法 代码可以重用
1.选择“映射(子转换)”控件:

2.“映射(子转换)”设置:
3.运行结果:
10.脚本
脚本: 就是直接通过程序代码完成一些复杂的操作
10.1 javascript代码
JavaScrip代码:就是使用Javascript语言通过代码编程来完成对数据流的操作 —了解
js中有很多内置函数,可以在编写js代码时查看。
1.选择“JavaScript代码”控件:
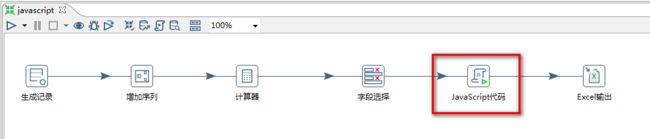
2."JavaScript代码"设置:

3.运行结果:
生成纪录:
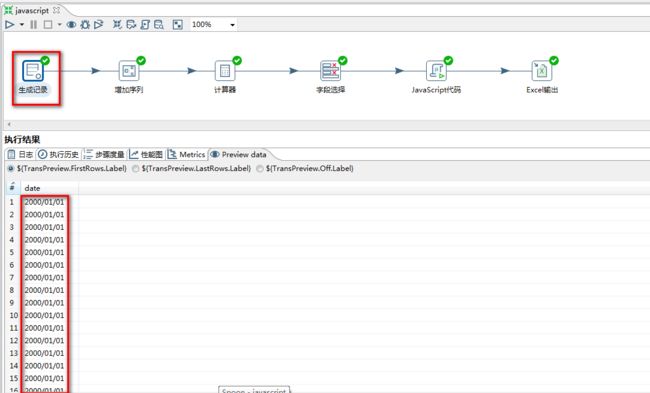
增加序列:

计算器:

字段选择:

JavaScript代码

10.2 java代码
Java代码:就是使用Java语言通过代码编程来完成对数据流的操作
内置了很多函数可以直接使用
任务:从user中读取数据,生成newcode字段,如果code列为null,就使用name列来替换,
否则就在code列的后面加上123,结果保存在user中。
1.选择“Java代码”控件:

2.“Java代码”编写:

Java代码:
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException {
if (first) {
first = false;
}
Object[] r = getRow();
if (r == null) {
setOutputDone();
return false;
}
r = createOutputRow(r, data.outputRowMeta.size());
String hobby = get(Fields.Info, "hobby").getString(r);
if(username==null||"".equals(username)){
String name = get(Fields.Info, "username").getString(r);
hobby = name;
}else{
hobby = hobby+"123";
}
get(Fields.Out, "newhobby").setValue(r, hobby);
putRow(data.outputRowMeta, r);
return true;
}
3.运行结果:
(略)
10.3 执行SQL脚本
SQL脚本:可以执行一个update语句,用来更新某个表中的数据。 ----更新数据库的数据
任务:从t_user表中获取所有数据,把age的值改为33
1.选择“执行SQL脚本”控件:

2."执行SQL脚本"设置:

3.运行结果:

11.作业
11.1 作业
作业:
大多数ETL项目都需要完成各种各样的维护工作。
例如:如何传送文件,验证数据库表是否存在,等待。而这些操作都是按照一定顺序完成的。
因此转换以并行方式执行,就需要一个可以串行执行的作业来处理这些操作。
一个作业包含一个或多个作业项,这些作业项以某种顺序来执行。作业执行顺序由作业项
之间的跳和每个作业项的执行结果来决定的。
作业项是作业的基本构成部分。如同转换步骤,作业项也可以使用图标的方式图形化展示。
但是,如果你再仔细观察,还是会发现作业项有一些地方不同于步骤:
在作业项之间可以传递一个结果对象。这个结果对象里面包含了数据行,它们本身以数据流
的方式来传递的。而是等待一个作业项执行完了,再传递给下一个作业项。
因为作业顺序执行作业项,所以必须定义一个起点。有一个叫"开始"的作业项定义了这个点。
一个作业只能定一个开始作业项。
作业跳是作业项之间的连接线,它定义了作业的执行路径。作业里每个作业项的不同运行结果
决定了做作业的不同执行路径。
(1)无条件执行:不论上一个作业项执行成功还是失败,下一个作业项都会执行。这是一种蓝色的连接线,
上面有个锁的图标。
(2)当运行结果为真时执行:当上一个作业项的执行结果为真时,执行下一个作业项。通常在需要无错误执行的情
况下使用。
这是一种绿色的连接线,上面有一个对钩号的图标。
(3)当运行结果为假时执行:当上一个作业项的执行结果为假或者没有成功执行时,执行下一个作业项。
这是一种红色的连接线,上面有一个红色的停止图标。
在图标上单击就可以对跳进行设置。
任务:从user表中读取数据,保存到use中,在从user2中读取数据,保存到user2中,如果产生错误就发送邮件,
并且停止作业,如果成功发送成功邮件。
1.选择“作业”控件:

2.“转换”1设置

3.“转换”2设置:

4.运行结果:


11.2 全局参数
参数:对于ETL参数传递是一个很重要的环节,因为参数的传递会涉及到业务数据是如何抽取的。
参数分为两种:全局参数和局部参数。
全局参数:全局参数定义是通过当前用户下.kettle文件夹中的kettle.properties文件来定义。
定义方式是采用 键=值 对方式来定,如:start_date=20130101
注意:在配置全局变量时需要重启kettle才会生效。
局部参数:是通过set variables 与 get variables 方式来设置
注:在set variables时在当前转换当中是不能马上使用,需要在作业中的下一个步骤中使用。
参数的使用:一种是${变量名} —一般使用这种
一种是%%变量名%%
注:在sql中使用变量时,需要把"是否替换变量"勾选上,否则无法使变量生效。
任务:从.kettle/kettle.properties文件中读取startrow和pagesize参数,从t_order表中
获取数据,使用参数传递。
1.“全局参数”设置:

2.运行结果:

11.3 常量传递
常量传递:先定义常量传递,在表输入的SQL语句里使用?来替换
默认的替换顺序就是常量定义的顺序
任务:自定义常量数据id1 = 3,id2=10,从t_user表中获取数据,满足条件id>id1和id 后续不要执行任何操作 1.选择“自定义常量数据”控件: 2."自定义常量数据"设置: 3.使用设置: 4.运行结果: 转换命名参数:就是在转换内部定义的变量,作用范围是在转换内部。 在转换的空白处右键,选择转换设置就可以看见。 任务:设置转换命名参数id1 = 3,id2=10,从t_user表中获取数据,满足条件id>id1和id 后续不要执行任何操作 常量 取值 是用 ? 1.在转换空白处右键,选择“转换设置”控件 2.命名参数使用: 3.运行结果: 设置变量-获取变量: 在转换里面有一个作业分类,里面有设置变量和获取变量的步骤 注意:"获取变量"时,在当前转换当中是不能马上使用,需要在作业中的下一步骤中使用! 如果作业中的多个转换都要用到这个变量,则在作业中设置变量; 如果只在某一个转换中用到这个变量,那就在转换中设置变量。 任务:在一个转换里面设置变量id1和id2,在另外一个转换里面获取变量id1和id2, 从t_user表中获取数据,满足条件id 1.选择“设置变量、获取变量” 2.转换_设置变量 添加 设置变量 3.“设置变量”设置: 4.设置“转换_获取变量名”的子转换 5.在“转换_获取变量”子转换中 添加“获取变量”: 6.在“转换_获取变量”子转换中的“获取变量”设置: 7.在“转换_获取变量”子转换中的“表输入”设置: 8.运行结果: 在作业里面设置变量id1和id2,在转换以两种不同的方式进行变量转换, 1.先获取变量,在进行步骤替换 2.直接变量替换 都是从t_user表中获取数据,满足id>id1和id 1.先定义一个作业 2.“设置变量”配置 3.定义转换1的子转换:作业中设置变量_转换1 4.定义转换2的子转换:作业中设置变量_转换2 5.转换1中“获取变量”配置 6.转换1中的“表输入”配置 7.转换2中“表输入”配置: 运行结果: 发送邮件:发送邮件就是在执行成功、失败,其他某种情景给相关人员发送邮件。 任务:发送一封邮件 1.选择“发邮件”控件: 2."发送邮件"设置: 3.运行结果: start按钮 按秒重复循环,按每天的某个时间点 1.新建“作业”,选择“Start”控件 选择类型: 3.默认为:不需要定时 只执行一次 4.类型:天 设置 每天的20:20执行 5.类型:时间间隔 每隔1分30秒执行一次 6.类型:周 设置 每周一 18:15执行 7.类型:月 设置 每月1号 18:15执行



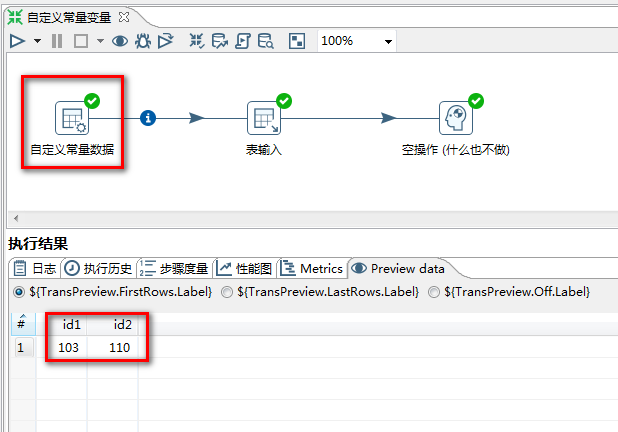

11.4 转换命名参数
变量 取值 是用 ${}


11.5 设置变量、获取变量



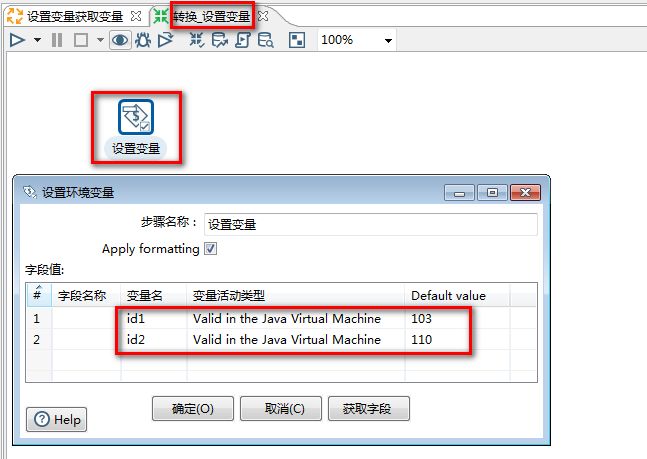






11.6 作业中设置变量









11.7 发邮件
注意:只有企业邮箱才可以,个人邮箱不行!
并且需要在邮件设置中开通客户端授权码!




11.8 作业定时任务
 2.“Start”控件设置:
2.“Start”控件设置:




