【Linux线程同步】生产者消费者模型
文章目录
- 1 :peach:线程互斥中可能还会存在的问题:peach:
- 2 :peach:线程同步:peach:
-
- 2.1 :apple:同步概念与竞态条件:apple:
- 2.2 :apple:条件变量函数:apple:
-
- :lemon:初始化:lemon:
- :lemon:销毁:lemon:
- :lemon:等待条件满足:lemon:
- :lemon:唤醒等待:lemon:
- :lemon:条件变量使用规范:lemon:
- 3 :peach:生产者消费者模型 :peach:
-
- 3.1 :apple:基本概念:apple:
- 3.2 :apple:生产者消费者模型优点:apple:
- 3.3 :apple:基于阻塞队列的生产者消费者模型代码:apple:
1 线程互斥中可能还会存在的问题
从上篇文章线程互斥时重点讲解抢票系统中我们知道:当多个线程并发抢票时我们只控制了不会有多个线程抢到了同一张票,但是并没有控制多个线程间谁来抢票的问题。也就是可能会出现下面这种情况:只有一个线程在抢票,其他线程并没有抢票,这样并没有违反线程互斥的规则,但是这样会导致其他线程出现饥饿问题,那么这样做肯定是不够高效的,我们应该采取怎样的措施来解决问题呢?
我们可以简单的修改一下前面我们写的代码,为了使效果更加显著,我们将票的个数减少一些:
int g_tictet=10;
pthread_mutex_t mtu=PTHREAD_ADAPTIVE_MUTEX_INITIALIZER_NP;
pthread_cond_t cond=PTHREAD_COND_INITIALIZER;
void* Run(void* args)
{
string name=static_cast<const char*>(args);
while(true)
{
pthread_mutex_lock(&mtu);
pthread_cond_wait(&cond,&mtu);
if(g_tictet<=0)
{
pthread_mutex_unlock(&mtu);
break;
}
else
{
cout<<"I am "<<name<<",is running tickets"<<g_tictet<<endl;
g_tictet--;
}
pthread_mutex_unlock(&mtu);
usleep(2000);
}
return nullptr;
}
int main()
{
pthread_t ptids[5];
for(int i=0;i<5;++i)
{
char* name=new char[26];
snprintf(name,26,"pthread%d",i+1);
pthread_create(ptids+i,nullptr,Run,name);
}
while(true)
{
pthread_cond_signal(&cond);
sleep(1);
}
for(int i=0;i<5;++i)
{
pthread_join(ptids[i],nullptr);
}
return 0;
}
当我们运行时:
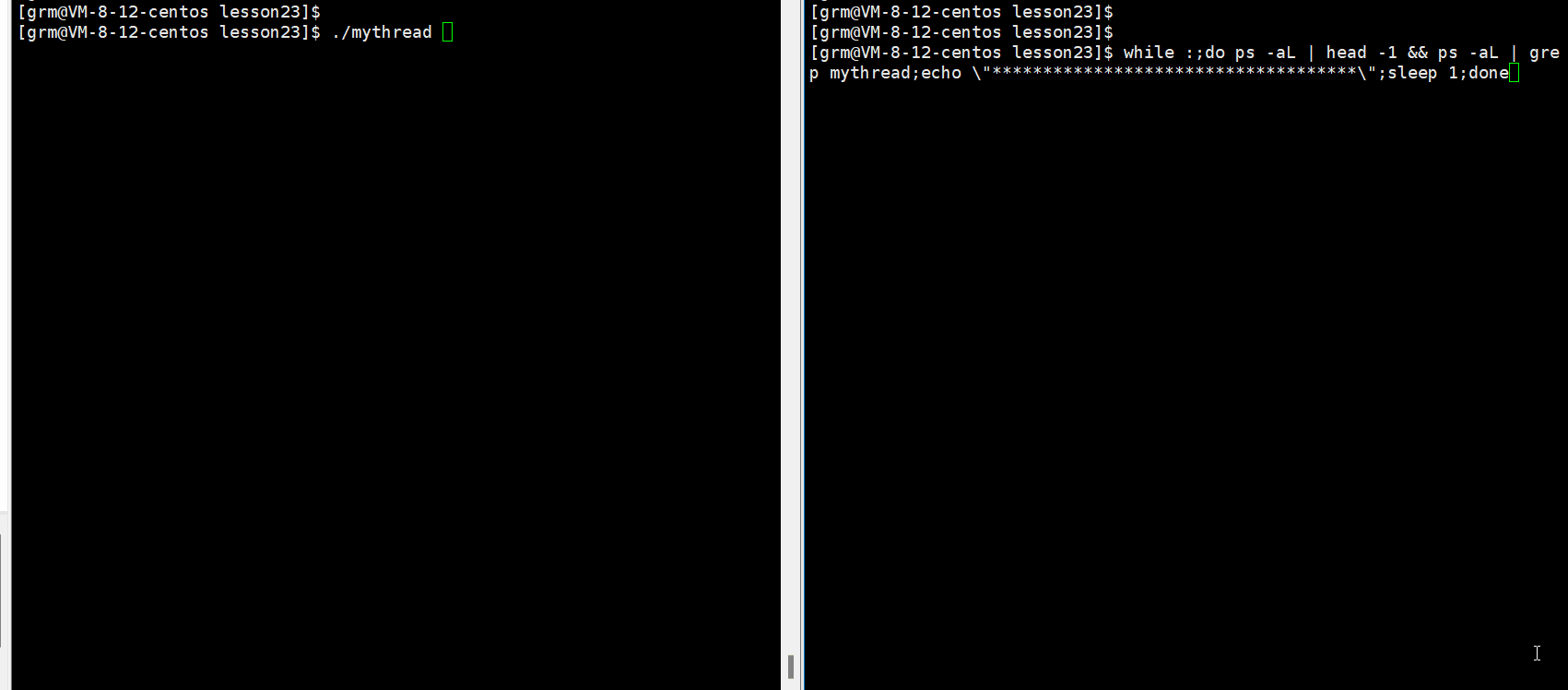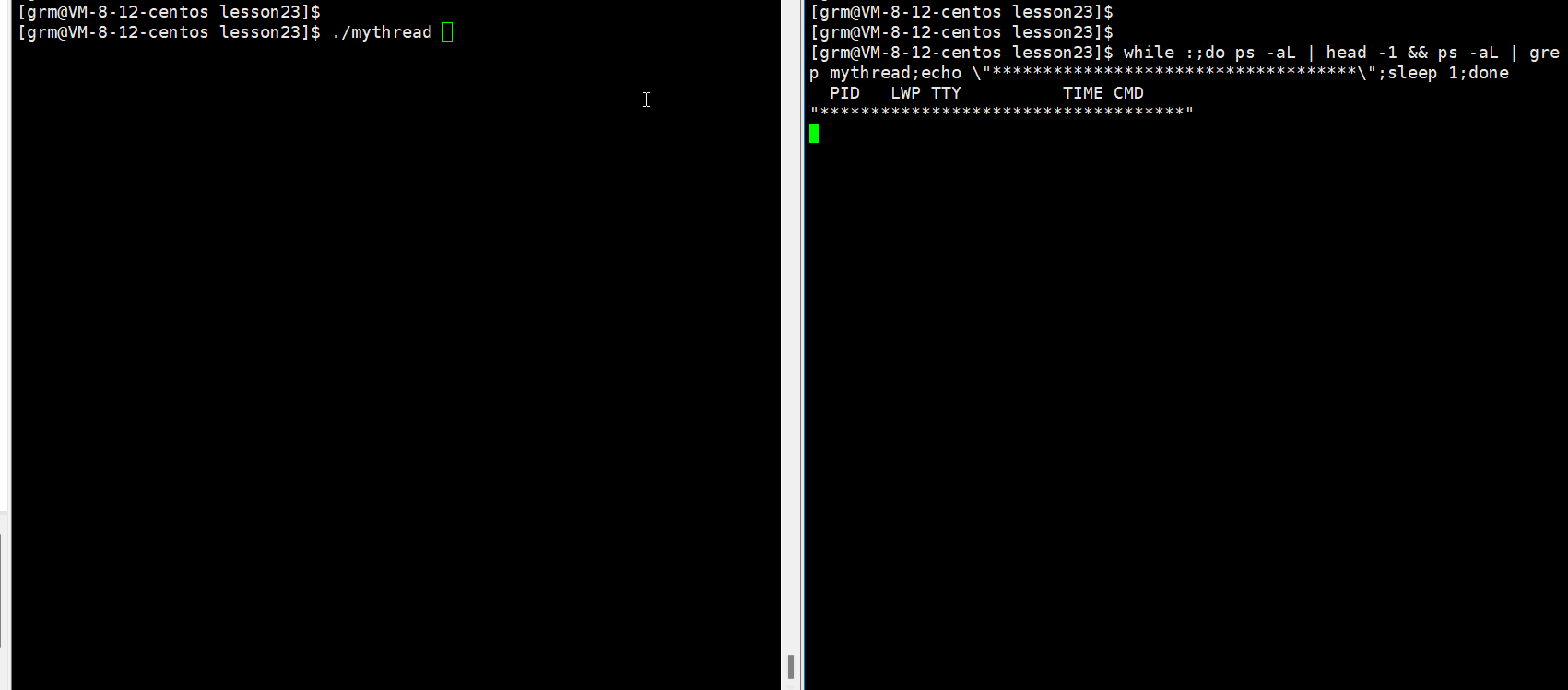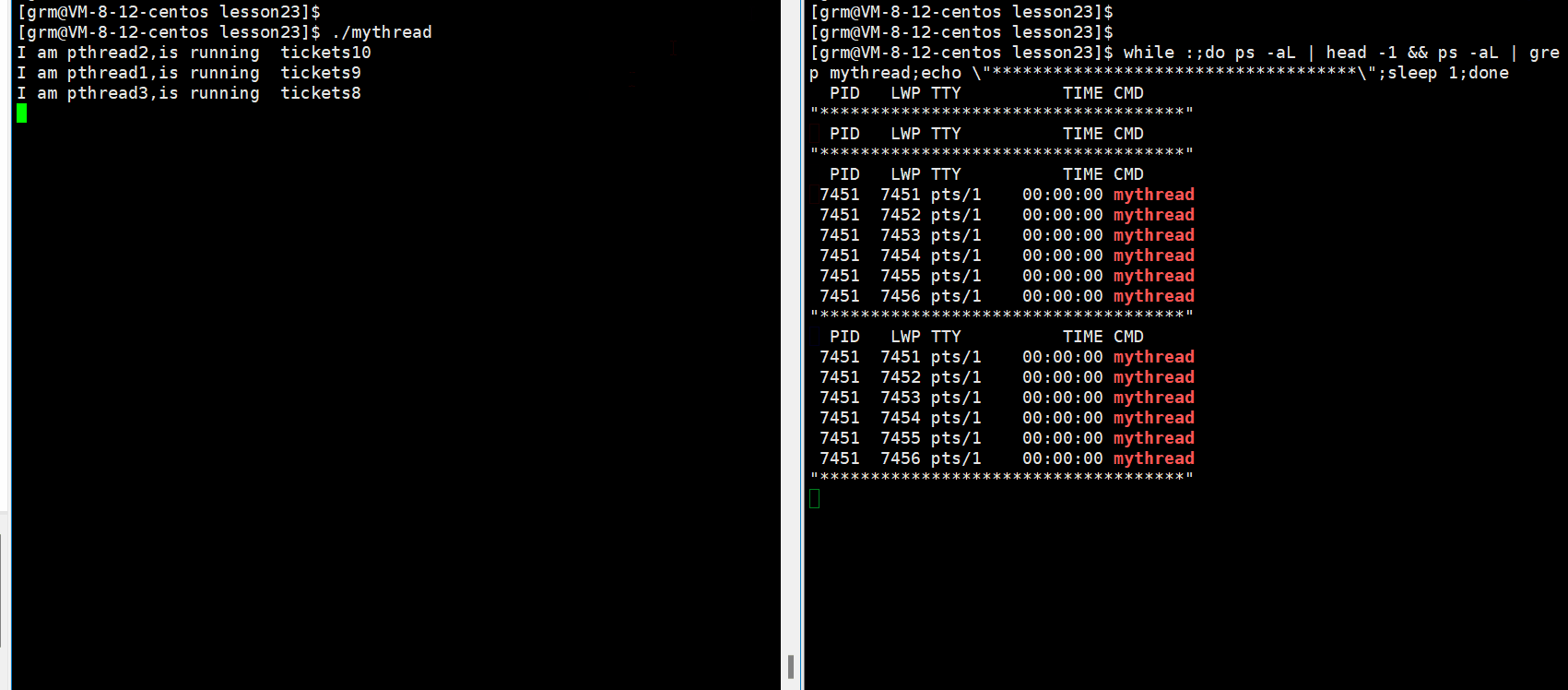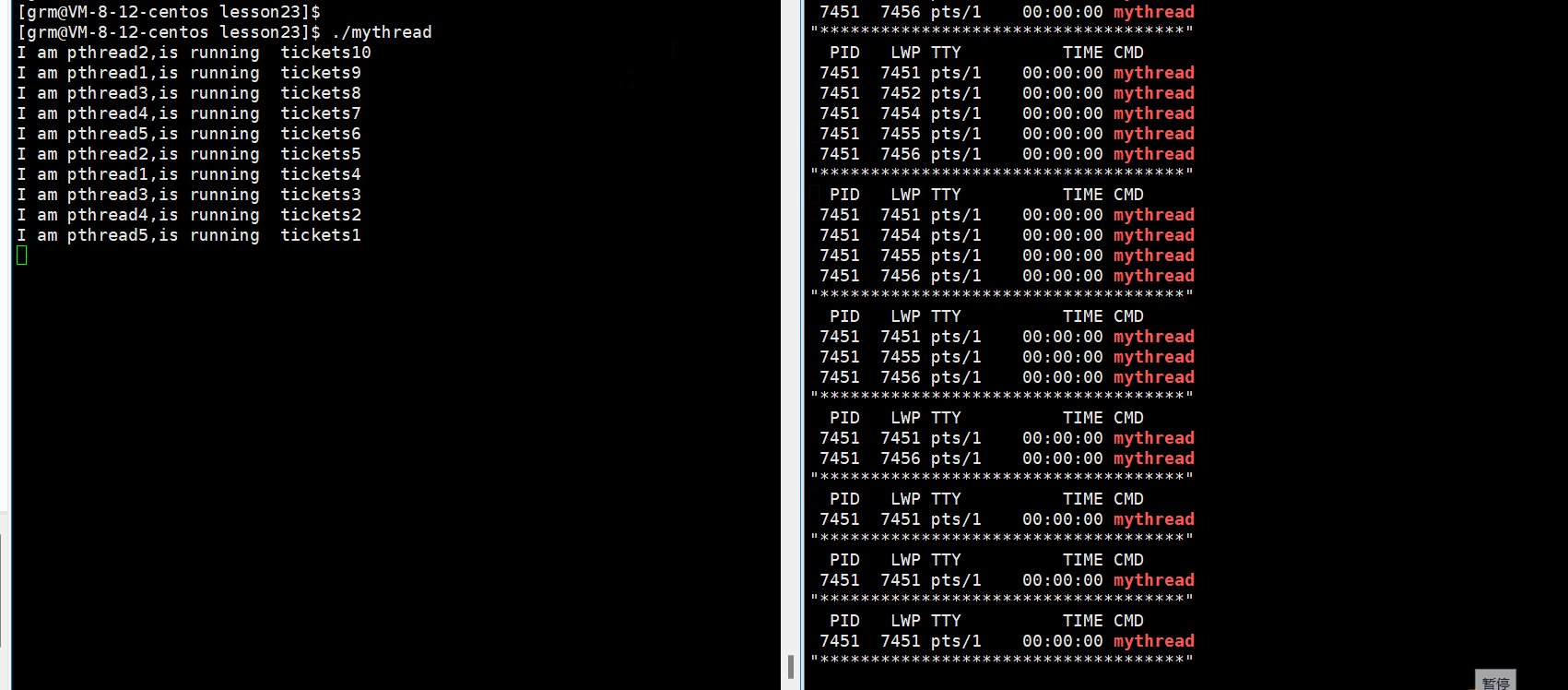 从上面的图中我们发现各线程抢票是有一定的顺序的,也就是使用了条件变量后个线程间的运行变得有序了起来。大家现在可以先看看怎么使用的,至于条件变量的接口我们接下来会慢慢介绍的.(但是实际上同步的应用场景并不在此,这里只是简单的让大家理解一下同步)
从上面的图中我们发现各线程抢票是有一定的顺序的,也就是使用了条件变量后个线程间的运行变得有序了起来。大家现在可以先看看怎么使用的,至于条件变量的接口我们接下来会慢慢介绍的.(但是实际上同步的应用场景并不在此,这里只是简单的让大家理解一下同步)
2 线程同步
2.1 同步概念与竞态条件
当一个线程互斥地访问某个变量时,它可能发现在其它线程改变状态之前,它什么也做不了。例如一个线程访问队列时,发现队列为空,它只能等待,直到其它线程将一个节点添加到队列中。这种情况就需要用到条件变量。上面我们想要让抢票线程按照一定的规律去抢票,也要用到条件变量。
- 同步:在保证数据安全的前提下,让线程能够按照某种特定的顺序访问临界资源,从而有效避免饥饿问题,叫做同步。
- 竞态条件:因为时序问题,而导致程序异常,我们称之为竞态条件。
2.2 条件变量函数
初始化
int pthread_cond_init(pthread_cond_t *restrict cond,const pthread_condattr_t *restrict
attr);
参数:
cond:要初始化的条件变量
attr:NULL
销毁
int pthread_cond_destroy(pthread_cond_t *cond)
等待条件满足
int pthread_cond_wait(pthread_cond_t *restrict cond,pthread_mutex_t *restrict mutex);
参数:
cond:要在这个条件变量上等待
mutex:互斥量
这里大家或许有了疑问,为什么这里会需要互斥量呀?不知道大家注意到了没,我们使用条件变量是在临界区的(因为在我们进行条件判断时必须保证线程的安全,条件不会无缘无故的突然变得满足了,必然会牵扯到共享数据的变化。所以一定要用互斥锁来保护。没有互斥锁就无法安全的获取和修改共享数据。),也就是在加锁的地方进行的;所以当我们在该条件下进行等待时是要先将锁给解了,否则不就造成了死锁问题了吗;然后在进行等待,等到别人成功唤醒后当条件不满足时再去重新申请该锁,然后才能退出。
其中解锁和等待必须是一个原子操作,否则如果已经有其他线程获取到互斥量,摒弃条件满足,发送了信号,那么 pthread_cond_wait 将错过这个信号,可能会导致线程永远阻塞在pthread_cond_wait。
唤醒等待
int pthread_cond_broadcast(pthread_cond_t *cond);
int pthread_cond_signal(pthread_cond_t *cond);
其中第1个是唤醒全部在该条件下等待的线程,第2个是唤醒条件变量底层维护队列中队头的线程(也就是最早等待的线程)
有了之前对于互斥锁接口的使用,条件变量的接口我相信使用起来也是得心应手的,大家熟悉了接口后可以再次回到刚开始写的代码中,看起来就会很容易了。
条件变量使用规范
- 等待条件代码:
pthread_mutex_lock(&mutex);
while (条件为假)
pthread_cond_wait(cond, mutex);
修改条件
pthread_mutex_unlock(&mutex);
大家注意到了进行条件判断用的是while而不是if,为什么呢?
这里我们先留着,在实例化生产者消费者模型代码时会给出解释。
- 给条件发送信号代码:
pthread_mutex_lock(&mutex);
设置条件为真
pthread_cond_signal(cond);
pthread_mutex_unlock(&mutex);
3 生产者消费者模型
3.1 基本概念
相信这个模型大家在上OS课程时多少也会了解过,不了解也没关系,我们下面先给出一张生产者与消费者关系的图片:
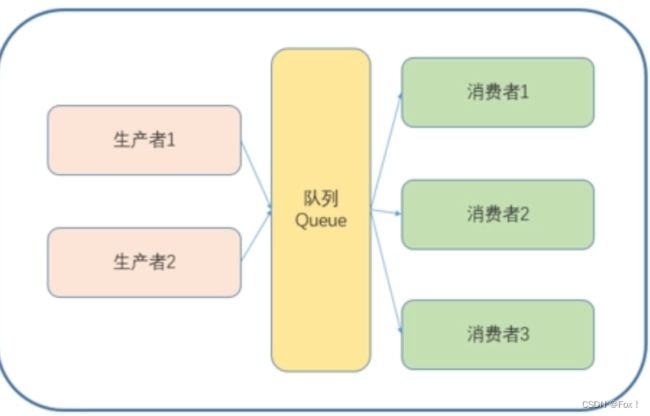 生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费者解耦的。
生产者消费者模式就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。这个阻塞队列就是用来给生产者和消费者解耦的。
生产者消费者模型中有三种关系,两种角色,一个交易场所。
3种关系:
- 生产者与生产者 互斥(竞争)
- 消费者与消费者 互斥(竞争)
- 生产者与消费者 互斥与同步(竞争与合作)
2种角色:
- 生产者和消费者
1种交易场所:
- 队列
3.2 生产者消费者模型优点
- 解耦
- 支持并发,效率高
- 支持忙闲不均
在基于阻塞队列的生产者消费者模型中,我们知道生产者与生产者,生产者与消费者,消费者与消费者都是不能同时访问阻塞队列的,也就是我在生产的时候你不能消费,我在生产的时候你不能生产,我在消费时你不能消费。那么也就注定了在生产数据与消费数据时要使用同一把锁来加锁。那么也就是多线程在访问阻塞队列是一定是串行访问的,那么高效性究竟体现在哪里呢?
这个问题我相信大家刚接触阻塞队列的生产者消费者模型时都会感到疑惑,为什么呢?
其实生产者消费者高效的原因是因为在push数据前数据的准备工作以及pop数据后数据的消费工作是可以并发进行的,并不是将数据放入阻塞队列以及从阻塞队列取出数据的时候。(这个时候只能串行访问)
3.3 基于阻塞队列的生产者消费者模型代码
在写代码之前我们先来思考下,我们创建一个阻塞队列的类里面应该有哪些成员?
首先需要一个queue,还需要一把锁,除此之外肯定还需要条件变量,我们需要两个条件变量来表示生产者与消费者应该等待的情况,不妨取名为full(满了说明是生产者需要等待),以及empte(空的说明是消费者需要等待),同时为了方便,我们可以再加一个记录容量大小的变量。
blockQueue.hpp:
#pragma once
#include cpTest.cc:
#include 由于我们消费者sleep1s后在消费数据的,所以我们可以观察到一定是生产者先直接生产满了,然后消费者再去消费:
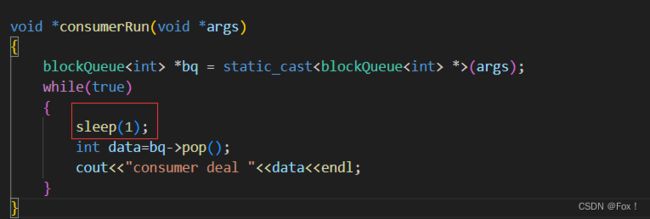
当我们运行时:
 同理,大家也可以去试试生产者先sleep.
同理,大家也可以去试试生产者先sleep.
在来回答之前遗留的问题,为什么进行等待时的条件要用while而不是if:
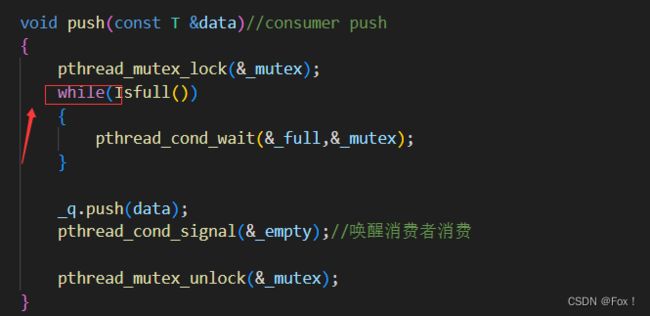
如果生产者是被误唤醒的,那么此时阻塞队列已经达到了最大容量,再push就会出错。所以为了安全起见我们最好还是使用while,保持良好习惯。
但是现在问题又来了,上面的代码能够处理多生产者消费者的场景吗?
我们想想,由于我们使用的是同一把锁,所以就算是多生产者多消费者一样能够处理,我们可以验证验证:
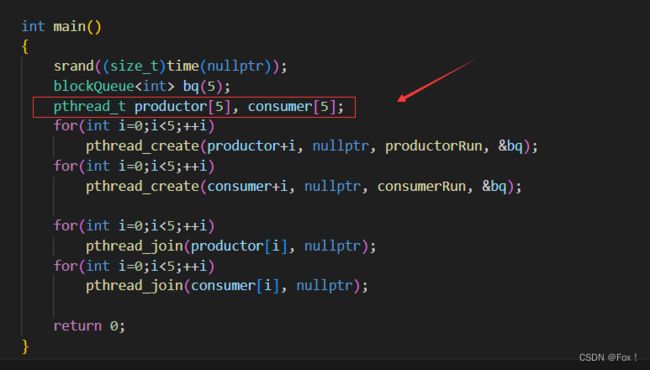 当我们运行时;
当我们运行时;
 有人或许会说,你这不是打印混乱了吗,别忘了我们处理任务和派发任务是可以多线程共同进行的,所以打印混乱是正常的。处理任务和分配任务多线程并发执行效率就很高效。
有人或许会说,你这不是打印混乱了吗,别忘了我们处理任务和派发任务是可以多线程共同进行的,所以打印混乱是正常的。处理任务和分配任务多线程并发执行效率就很高效。