『pyspark』三:RDD数据处理
1、使用Pyspark
1.1 Linking with Spark
from pyspark import SparkContext, SparkConf
1.2 Initializing Spark
conf = SparkConf().setAppName(appName).setMaster(master)
sc = SparkContext(conf=conf)
2、RDD
2.1 读取数据
2.1.1 parallelize
rdd = sc.parallelize([('Amber', 22), ('Alfred', 23), ('Skye', 4), ('Albert', 12)])
rdd.collect()
# [('Amber', 22), ('Alfred', 23), ('Skye', 4), ('Albert', 12)]
2.1.2 External Datasets
distFile = sc.textFile("./test.txt")
distFile.collect()
# ["'1001','男,25,教师'", "'1002','女,27,医生'", "'1003','男,32,程序员'"]
2.1.3 RDD/DataFrame互相转化
(1)RDD转换为DataFrame
from pyspark.sql.types import *
schema = StructType([StructField('id', StringType()), StructField('sex', StringType()),
StructField('age', StringType()), StructField('position', StringType())])
df0 = sqlContext.createDataFrame(rdd)
df0.show()
+----+---+---+------+
| _1| _2| _3| _4|
+----+---+---+------+
|1001| 男| 25| 教师|
|1002| 女| 27| 医生|
|1003| 男| 32|程序员|
+----+---+---+------+
df1 = sqlContext.createDataFrame(rdd, schema)
df1.show()
+----+---+---+--------+
| id|sex|age|position|
+----+---+---+--------+
|1001| 男| 25| 教师|
|1002| 女| 27| 医生|
|1003| 男| 32| 程序员|
+----+---+---+--------+
(2)DataFrame转换为RDD
rdd = df1.rdd
rdd.collect()
# [Row(id='1001', sex='男', age='25', position='教师'),
# Row(id='1002', sex='女', age='27', position='医生'),
# Row(id='1003', sex='男', age='32', position='程序员')]
rdd.map(lambda x: [x[i] for i in range(4)]).collect()
# [['1001', '男', '25', '教师'],
# ['1002', '女', '27', '医生'],
# ['1003', '男', '32', '程序员']]
2.2 RDD操作
2.2.1 Basic
rdd = distFile.map(lambda x:x.replace("'", "")).map(lambda x: x.split(","))
rdd.collect()
# [['1001', '男', '25', '教师'],
# ['1002', '女', '27', '医生'],
# ['1003', '男', '32', '程序员']]
2.2.2 Passing Functions to Spark
def myFunc(s):
x = s.replace("'", "")
return x.split(",")
rdd = distFile.map(myFunc)
rdd.collect()
# [['1001', '男', '25', '教师'],
# ['1002', '女', '27', '医生'],
# ['1003', '男', '32', '程序员']]
2.2.3 Working with Key-Value Pairs
大部分spark操作在RDD上都是work的,但是有少量特征操作只能作用于key-value pairs RDD,最常见的是分布式shuffle操作,例如:按key对元素进行分组( grouping)或聚合(aggregating)。
这些操作在包含内置Python元组(如(1,2))的rdd上工作,例如:
lines = sc.textFile("data.txt")
pairs = lines.map(lambda s: (s, 1))
counts = pairs.reduceByKey(lambda a, b: a + b)
pairs.collect()
# [('a', 1), ('b', 1), ('c', 1), ('a', 1), ('c', 1), ('b', 1), ('a', 1)]
counts.collect()
# [('b', 2), ('a', 3), ('c', 2)]
Spark支持两个类型(算子)操作:Transformation和Action。
2.2.4 transformation
主要做的是就是将一个已有的RDD生成另外一个RDD。Transformation具有lazy特性(延迟加载)。Transformation算子的代码不会真正被执行。只有当我们的程序里面遇到一个action算子的时候,代码才会真正的被执行。这种设计让Spark更加有效率地运行。
(1)map
x = sc.parallelize([1,2,3])
y = x.map(lambda x: (x, x**2))
# 从远程集群拉取数据到本地,经网络传输.如果数据量较大时,尽量不要用collect函数,可能导致Driver端内存溢出。
print(x.collect())
# [1, 2, 3]
print(y.collect())
# [(1, 1), (2, 4), (3, 9)]
(2)flatmap
x = sc.parallelize([1,2,3])
y1 = x.flatMap(lambda x : [(x, 100*x)])
y2 = x.flatMap(lambda x : (x, 100*x, x**2))
print(x.collect())
# [1, 2, 3]
print(y1.collect())
# [(1, 100), (2, 200), (3, 300)]
print(y2.collect())
# [1, 100, 1, 2, 200, 4, 3, 300, 9]
(3)mapPartitions
map是对rdd中的每一个元素进行操作,而mapPartitions(foreachPartition)则是对rdd中的每个分区的迭代器进行操作。
如果在map过程中需要频繁创建额外的对象(例如将rdd中的数据通过jdbc写入数据库,map需要为每个元素创建一个链接,而mapPartition为每个partition创建一个链接),则mapPartitions效率比map高的多。
如果是普通的map,比如一个partition中有1万条数据,那么你的function要执行和计算1万次。
使用MapPartitions操作之后,一个task仅仅会执行一次function,function一次接收所有的partition数据,只要执行一次就可以了,性能比较高。
x = sc.parallelize([1,2,3], 2) # 2 表示分区的个数
def f(iterator):yield sum(iterator)
y = x.mapPartitions(f)
print(x.collect())
# [1, 2, 3]
print(y.collect())
# [1, 5]
# 将RDD中每一个分区中类型为T的元素转换成Array[T],这样每一个分区就只有一个数组元素。
print(x.glom().collect())
# [[1], [2, 3]]
print(y.glom().collect())
# [[1], [5]]
如果是普通的map操作,一次function的执行就处理一条数据,那么如果内存不够用的情况下, 比如处理了1千条数据,这个时候内存不够了,那么就可以将已经处理完的1千条数据从内存里面垃圾回收掉,或者用其他方法,腾出空间来。
所以说普通的map操作通常不会导致内存的OOM异常。
但是MapPartitions操作,对于大量数据来说,比如一个partition有100万条数据,一次传入一个function以后,那么可能一下内存就不够了,但是又没有办法去腾出内存空间来,可能就OOM,内存溢出。
(4)mapPartitionsWithIndex
mapPartitionsWithIndex相比于mapPartitions多了一个index索引,每次调用时就会把分区的“编号”穿进去。
x = sc.parallelize([1,2,3], 2)
def f(partitionIndex, iterator): yield(partitionIndex, sum(iterator))
y = x.mapPartitionsWithIndex(f)
print(x.glom().collect())
# [[1], [2, 3]]
print(y.glom().collect())
# [[(0, 1)], [(1, 5)]]
(6)filter
x = sc.parallelize([1,2,3])
y = x.filter(lambda x: x % 2 == 1) # 选择奇数
print(x.collect())
# [1, 2, 3]
print(y.collect())
# [1, 3]
(6)getNumPartitions
x = sc.parallelize([1,2,3], 2) # 2 表示分区的个数
y = x.getNumPartitions()
print(x.glom().collect())
# [[1], [2, 3]]
print(y)
# 2
(7)sample
x = sc.parallelize(range(7))
ylist = [x.sample(withReplacement=False, fraction=0.7) for i in range(5)]
print('x = ' + str(x.collect()))
for cnt,y in zip(range(len(ylist)), ylist):
print('sample:' + str(cnt) + ' y = ' + str(y.collect()))
# x = [0, 1, 2, 3, 4, 5, 6]
# sample:0 y = [0, 1, 2, 3, 4]
# sample:1 y = [0, 1, 2, 4, 5]
# sample:2 y = [1, 2, 3, 4, 5]
# sample:3 y = [0, 1, 2, 4, 5]
# sample:4 y = [0, 2, 6]
(8)union
x = sc.parallelize(['A', 'B', 'C'])
y = sc.parallelize(['d', 'A', 'T'])
z = x.union(y)
print(x.collect())
print(y.collect())
print(z.collect())
# ['A', 'B', 'C']
# ['d', 'A', 'T']
# ['A', 'B', 'C', 'd', 'A', 'T']
(9)intersection
x = sc.parallelize(['A','A','B'])
y = sc.parallelize(['A','C','D'])
z = x.intersection(y)
print(x.collect())
print(y.collect())
print(z.collect())
# ['A', 'A', 'B']
# ['A', 'C', 'D']
# ['A']
(9)subtract
x = sc.parallelize(['A','A','B','G'])
y = sc.parallelize(['A','C','D'])
z = x.subtract(y) # 返回在x中出现,但未在y中出现的元素
print(x.collect())
print(y.collect())
print(z.collect())
# ['A', 'A', 'B', 'G']
# ['A', 'C', 'D']
# ['B', 'G']
(10)distinct
去掉重复数据
x = sc.parallelize(['A', 'B', 'C', 'A', 'A'])
y = x.distinct()
print(x.collect())
print(y.collect())
# ['A', 'B', 'C', 'A', 'A']
# ['C', 'A', 'B']
(10)glom
将RDD中每一个分区中类型为T的元素转换成Array[T],这样每一个分区就只有一个数组元素。
x = sc.parallelize(['C', 'B', 'A'], 2)
y = x.glom()
print(x.collect())
print(y.collect())
# ['C', 'B', 'A']
# [['C'], ['B', 'A']]
(11)sortByKey
函数能够完成对(key,value)格式的数据进行排序,它是根据key进行排序。
x = sc.parallelize([('B',1),('A',2),('C',3)])
y = x.sortByKey()
print(x.collect())
print(y.collect())
# [('B', 1), ('A', 2), ('C', 3)]
# [('A', 2), ('B', 1), ('C', 3)]
(11)sortBy
根据value进行排序。
x = sc.parallelize([('B',4),('A',2),('C',3)])
y = x.sortBy(lambda x : x[1], False) # False 降序排列
print(x.collect())
print(y.collect())
# [('B', 4), ('A', 2), ('C', 3)]
# [('B', 4), ('C', 3), ('A', 2)]
x = sc.parallelize(['Cat','Apple','Bat'])
def keyGen(val): return val[0] # 按照首字母排序
y = x.sortBy(keyGen)
print(y.collect())
# ['Apple', 'Bat', 'Cat']
(14)groupBy
groupBy算子接收一个函数,这个函数返回的值作为key,然后通过这个key来对里面的元素进行分组。
x = sc.parallelize([1,2,3])
y = x.groupBy(lambda x: 'A' if (x % 2 == 1) else 'B')
print(x.collect())
print([(j[0],[i for i in j[1]]) for j in y.collect()])
# [1, 2, 3]
# [('A', [1, 3]), ('B', [2])]
(14)groupByKey
该函数用于将RDD[K,V]中每个K对应的V值,合并到一个集合Iterable[V]中,
参数numPartitions用于指定分区数;
参数partitioner用于指定分区函数;
x = sc.parallelize([('B',1),('B',2),('A',3),('A',4),('A',5)])
print(sorted(x.groupByKey().mapValues(len).collect()))
print(sorted(x.groupByKey().mapValues(list).collect()))
# [('A', 3), ('B', 2)]
# [('A', [3, 4, 5]), ('B', [1, 2])]
(12)reduceByKey
用于对每个key对应的多个value进行merge操作,最重要的是它能够在本地先进行merge操作,并且merge操作可以通过函数自定义。
x = sc.parallelize([('B',1),('B',2),('A',3),('A',4),('A',5)])
y = x.reduceByKey(lambda x, y : x + y)
print(x.collect())
print(y.collect())
# [('B', 1), ('B', 2), ('A', 3), ('A', 4), ('A', 5)]
# [('B', 3), ('A', 12)]
(12)reduceByKeyLocally
该函数将RDD[K,V]中每个K对应的V值根据映射函数来运算,运算结果映射到一个Map[K,V]中,而不是RDD[K,V]。
x = sc.parallelize([('B',1),('B',2),('A',3),('A',4),('A',5)])
y = x.reduceByKeyLocally(lambda x, y : x + y)
print(x.collect())
print(y)
# [('B', 1), ('B', 2), ('A', 3), ('A', 4), ('A', 5)]
# {'B': 3, 'A': 12}
注意: reduceByKey与reduceByKeyLocally的返回值不同,一个是RDD, 一个是 map。
(13)aggregateByKey
rdd.aggregateByKey(zerovalue, seqFunc, combFunc) 其中第一个函数是初始值; seqFunc代表combine的聚合逻辑,每一个mapTask的结果的聚合成为combine; combFunc reduce端大聚合的逻辑
aggregateByKey函数对PairRDD中相同Key的值进行聚合操作,在聚合过程中同样使用了一个中立的初始值。
和aggregate函数类似,aggregateByKey返回值的类型不需要和RDD中value的类型一致。因为aggregateByKey是对相同Key中的值进行聚合操作,所以aggregateByKey函数最终返回的类型还是Pair RDD,对应的结果是Key和聚合好的值;
aggregate函数直接是返回非RDD的结果,这点需要注意。
x = sc.parallelize([('B',1),('B',2),('A',3),('A',4),('A',5)])
zeroValue = []
mergeVal = (lambda aggregated, el : aggregated + [(el, el**2)])
mergeComb = (lambda agg1, agg2 : agg1 + agg2)
y = x.aggregateByKey(zeroValue, mergeVal, mergeComb)
print(x.collect())
print(y.collect())
# [('B', 1), ('B', 2), ('A', 3), ('A', 4), ('A', 5)]
# [('B', [(1, 1), (2, 4)]), ('A', [(3, 9), (4, 16), (5, 25)])]
(16)partitionBy
partitionBy根据partitioner函数生成新的ShuffleRDD,将原RDD重新分区。
repartition默认采用HashPartitioner分区,自己设计合理的分区方法(比如数量比较大的key 加个随机数,随机分到更多的分区, 这样处理数据倾斜更彻底一些)
x = sc.parallelize([(0, 1), (1, 2), (1, 3), (0, 2), (3, 5), (5, 6)], 2)
y1 = x.partitionBy(numPartitions=6, partitionFunc=lambda x : x)
print(x.glom().collect())
print(y1.glom().collect())
# [[(0, 1), (1, 2), (1, 3)], [(0, 2), (3, 5), (5, 6)]]
# [[(0, 1), (0, 2)], [(1, 2), (1, 3)], [], [(3, 5)], [], [(5, 6)]]
(16)combineByKey
combineByKey()是最为常用的基于键进行聚合的函数。大多数基于键聚合的函数都是用它实现的。和aggregate()一样,combineByKey()可以让用户返回与输入数据的类型不同的返回值。
# 合并
x = sc.parallelize([('B',1),('B',2),('A',3),('A',4),('A',5)])
createCombiner = (lambda el : [(el, el ** 2)])
mergeVal = (lambda aggregated, el : aggregated + [(el, el ** 2)])
mergeComb = (lambda agg1, agg2 : agg1 + agg2)
y = x.combineByKey(createCombiner, mergeVal, mergeComb)
print(x.collect())
print(y.collect())
# [('B', 1), ('B', 2), ('A', 3), ('A', 4), ('A', 5)]
# [('B', [(1, 1), (2, 4)]), ('A', [(3, 9), (4, 16), (5, 25)])]
(15)join
内连接,两个表具有相同的 key 时进行连接。
x = sc.parallelize([('C',4),('B',3),('A',2),('A',1)])
y = sc.parallelize([('A',8),('B',7),('A',6),('D',5)])
z = x.join(y)
print(x.collect())
print(y.collect())
print(z.collect())
# [('C', 4), ('B', 3), ('A', 2), ('A', 1)]
# [('A', 8), ('B', 7), ('A', 6), ('D', 5)]
# [('B', (3, 7)), ('A', (2, 8)), ('A', (2, 6)), ('A', (1, 8)), ('A', (1, 6))]
(16)leftOuterJoin
左连接
x = sc.parallelize([('C',4),('B',3),('A',2),('A',1)])
y = sc.parallelize([('A',8),('B',7),('A',6),('D',5)])
z = x.leftOuterJoin(y)
print(x.collect())
print(y.collect())
print(z.collect())
# [('C', 4), ('B', 3), ('A', 2), ('A', 1)]
# [('A', 8), ('B', 7), ('A', 6), ('D', 5)]
# [('B', (3, 7)), ('A', (2, 8)), ('A', (2, 6)), ('A', (1, 8)), ('A', (1, 6)), ('C', (4, None))]
(16)rightOuterJoin
右连接
x = sc.parallelize([('C',4),('B',3),('A',2),('A',1)])
y = sc.parallelize([('A',8),('B',7),('A',6),('D',5)])
z = x.rightOuterJoin(y)
print(x.collect())
print(y.collect())
print(z.collect())
# [('C', 4), ('B', 3), ('A', 2), ('A', 1)]
# [('A', 8), ('B', 7), ('A', 6), ('D', 5)]
# [('B', (3, 7)), ('A', (2, 8)), ('A', (2, 6)), ('A', (1, 8)), ('A', (1, 6)), ('D', (None, 5))]
(16)fullOuterJoin
全连接
x = sc.parallelize([('C',4),('B',3),('A',2),('A',1)])
y = sc.parallelize([('A',8),('B',7),('A',6),('D',5)])
z = x.fullOuterJoin(y)
print(x.collect())
print(y.collect())
print(z.collect())
# [('C', 4), ('B', 3), ('A', 2), ('A', 1)]
# [('A', 8), ('B', 7), ('A', 6), ('D', 5)]
# [('B', (3, 7)), ('A', (2, 8)), ('A', (2, 6)), ('A', (1, 8)), ('A', (1, 6)), ('C', (4, None)), ('D', (None, 5))]
(16)cogroup
将多个RDD中同一个Key对应的Value组合到一起。
x = sc.parallelize([('C',4),('B',(3,3)),('A',2),('A',(1,1))])
y = sc.parallelize([('A',8),('B',7),('A',6),('D',(5,5))])
z = x.cogroup(y)
print(x.collect())
print(y.collect())
for key,val in list(z.collect()):
print(key, [list(i) for i in val])
# [('C', 4), ('B', (3, 3)), ('A', 2), ('A', (1, 1))]
# [('A', 8), ('B', 7), ('A', 6), ('D', (5, 5))]
# B [[(3, 3)], [7]]
# A [[2, (1, 1)], [8, 6]]
# C [[4], []]
# D [[], [(5, 5)]]
(17)cartesian
返回两个RDD的笛卡尔集.如果两个RDD中某一个RDD的结果集为空集时,这个结果集也是一个空集。
x = sc.parallelize(['A', 'B'])
y = sc.parallelize(['C', 'D'])
z = x.cartesian(y)
print(x.collect())
print(y.collect())
print(z.collect())
# ['A', 'B']
# ['C', 'D']
# [('A', 'C'), ('A', 'D'), ('B', 'C'), ('B', 'D')]
(18)pipe
将由管道元素创建的RDD返回到分叉的外部进程。
sc.parallelize(['1', '2', '', '3']).pipe('cat').collect()
# ['1', '2', '', '3']
x = sc.parallelize(['A', 'Ba', 'C', 'AD'])
y = x.pipe('grep -i "A"') # 忽略字符大小写的差别。
print(x.collect())
print(y.collect())
# ['A', 'Ba', 'C', 'AD']
# ['A', 'Ba', 'AD']
x = sc.parallelize(['A', 'Ba', 'Cb', 'AD', 'ac'])
y = x.pipe('grep -i "b"') # 忽略字符大小写的差别。
print(x.collect())
print(y.collect())
# ['A', 'Ba', 'Cb', 'AD', 'ac']
# ['Ba', 'Cb']
(19)coalesce
def coalesce(numPartitions:Int,shuffle:Boolean=false):RDD[T]
该函数用于将RDD进行重分区,使用HashPartitioner。
第一个参数为重分区的数目,第二个为是否进行shuffle,默认为false。
当spark程序中,存在过多的小任务的时候,可以通过 RDD.coalesce方法,收缩合并分区,减少分区的个数,减小任务调度成本。
# shuffle=False,新的分区数小于原来的分区数,分区
x = sc.parallelize([1,2,3,4,5],2)
y = x.coalesce(numPartitions=1, shuffle=False)
print(x.glom().collect())
print(y.glom().collect())
# [[1, 2], [3, 4, 5]]
# [[1, 2, 3, 4, 5]]
# shuffle=False,新的分区数大于原来的分区数,不分区
x = sc.parallelize([1,2,3,4,5],2)
y = x.coalesce(numPartitions=3, shuffle=False)
print(x.glom().collect())
print(y.glom().collect())
# [[1, 2], [3, 4, 5]]
# [[1, 2], [3, 4, 5]]
# shuffle=True,新的分区数小于原来的分区数,分区
x = sc.parallelize([1,2,3,4,5],2)
y = x.coalesce(numPartitions=1, shuffle=True)
print(x.glom().collect())
print(y.glom().collect())
# [[1, 2], [3, 4, 5]]
# [[1, 2, 3, 4, 5]]
# shuffle=True,新的分区数大于原来的分区数,分区
x = sc.parallelize([1,2,3,4,5],2)
y = x.coalesce(numPartitions=3, shuffle=True)
print(x.glom().collect())
print(y.glom().collect())
# [[1, 2], [3, 4, 5]]
# [[], [1, 2, 3, 4, 5], []]
如果shuff为false时,如果传入的参数大于现有的分区数目,RDD的分区数不变,也就是说不经过shuffle,是无法将RDDde分区数变多的。
我们常认为coalesce不产生shuffle会比repartition 产生shuffle效率高,而实际情况往往要根据具体问题具体分析,coalesce效率不一定高,有时还有大坑,大家要慎用。
coalesce 与 repartition 他们两个都是RDD的分区进行重新划分,repartition只是coalesce接口中shuffle为true的实现(假设源RDD有N个分区,需要重新划分成M个分区)
-
如果N
-
如果N>M并且N和M相差不多,(假如N是1000,M是100)那么就可以将N个分区中的若干个分区合并成一个新的分区,最终合并为M个分区,这时可以将shuff设置为false(coalesce实现),如果M>N时,coalesce是无效的,不进行shuffle过程,父RDD和子RDD之间是窄依赖关系,无法使文件数(partiton)变多。
总之如果shuffle为false时,如果传入的参数大于现有的分区数目,RDD的分区数不变,也就是说不经过shuffle,是无法将RDD的分区数变多的 -
如果N>M并且两者相差悬殊,这时你要看executor数与要生成的partition关系,如果executor数 <= 要生成partition数,coalesce效率高,反之如果用coalesce会导致(executor数-要生成partiton数)个excutor空跑从而降低效率。如果在M为1的时候,为了使coalesce之前的操作有更好的并行度,可以将shuffle设置为true。
(20)repartition
def repartition(numPartitions: Int): RDD[T]
该函数其实就是coalesce函数第二个参数为true的实现。
x = sc.parallelize([1,2,3,4,5],2)
y = x.repartition(numPartitions=3)
print(x.glom().collect())
print(y.glom().collect())
# [[1, 2], [3, 4, 5]]
# [[], [1, 2, 3, 4, 5], []]
(20)zip
def zip[U](other: RDD[U])(implicit arg0: ClassTag[U]): RDD[(T, U)]
zip函数用于将两个RDD组合成Key/Value形式的RDD,这里默认两个RDD的partition数量以及元素数量都相同,否则会抛出异常。
x = sc.parallelize(['B','A','A'])
y = sc.parallelize(range(0,3))
z = x.zip(y)
print(x.collect())
print(y.collect())
print(z.collect())
# ['B', 'A', 'A']
# [0, 1, 2]
# [('B', 0), ('A', 1), ('A', 2)]
2.2.5 action
触发代码的运行,我们一段spark代码里面至少需要有一个action操作。
(1)reduce
reduce先在各分区中做操作,随后进行整合。
reduce返回值类型和参加计算类型一样。
map的主要作用就是替换,reduce的主要作用就是计算。
x = sc.parallelize([1,2,3])
y = x.reduce(lambda obj, accumulated: obj + accumulated) # 求和
print(x.collect())
print(y)
# [1, 2, 3]
# 6
(2)collect
数据量比较大的时候,尽量不要使用collect函数,因为这可能导致Driver端内存溢出问题。
x = sc.parallelize([1,2,3])
y = x.collect()
print(x) # distributed
print(y) # not distributed
# ParallelCollectionRDD[110] at parallelize at PythonRDD.scala:540
# [1, 2, 3]
collect操作的特点是从远程集群是拉取数据到本地,经过网络传输,如果数据量大的话,会给网络造成很大的压力,和foreach的区别是,foreach是在远程集群上遍历rdd中的元素,如果是在本地的话,差别不大。建议使用foreach,不要用collect。
(3)max/min/sum/count/mean/variance/stdev/sampleStdev/sampleVariance
x = sc.parallelize([2,3,4])
y1 = x.max()
y2 = x.min()
y3 = x.sum()
y4 = x.count()
y5 = x.mean()
print(y1,y2,y3,y4,y5)
# 4 2 9 3 3.0
(4)first
返回RDD中的第一个元素,不排序
x = sc.parallelize([1, 3, 1, 2, 3])
y = x.first()
print(x.collect())
print(y)
# [1, 3, 1, 2, 3]
# 1
(5)take
take用于获取RDD中从0到num-1下标的元素,不排序。
x = sc.parallelize([1, 3, 1, 2, 3])
y = x.take(num=3)
print(x.collect())
print(y)
# [1, 3, 1, 2, 3]
# [1, 3, 1]
(6)foreach
foreach用于遍历RDD,将函数f应用于每一个元素。
但要注意,如果对RDD执行foreach,只会在Executor端有效,而并不是Driver端。
x = sc.parallelize([1,2,3])
def f(x): print(x)
x.foreach(f)
# 打印到CLI,不是Jupyter Notebook
(7)countByKey
countByKey用于统计RDD[K,V]中每个K的数量。返回一个map,map的 key 是RDD的K,value是K出现的次数。
x = sc.parallelize([('B',1),('B',2),('A',3),('A',4),('A',5)])
y = x.countByKey()
print(x.collect())
print(y)
# [('B', 1), ('B', 2), ('A', 3), ('A', 4), ('A', 5)]
# defaultdict(, {'B': 2, 'A': 3})
(8)countByValue
统计一个RDD中各个value的出现次数。返回一个map,map的key是元素的值,value是出现的次数。
x = sc.parallelize([1, 3, 1, 2, 3])
y = x.countByValue()
print(x.collect())
print(y)
# [1, 3, 1, 2, 3]
# defaultdict(, {1: 2, 3: 2, 2: 1})
常用的 68 个函数
2.3 WordCount
2.3.1 实例
# 读取文件,生成RDD
file = sc.textFile('./hello.txt')
# RDD转化,单词计数
wordCount = file.flatMap(lambda x: x.split()).map(lambda x: (x, 1)).reduceByKey(lambda x, y: x + y)
wordCount.collect()
# [('jump', 4), ('i', 2), ('you', 2)]
# 按照单词出现的次数 降序排序
sortedRDD = wordCount.sortBy(lambda x: x[1], True)
sortedRDD.collect()
# [('i', 2), ('you', 2), ('jump', 4)]
# 保存最终结果
sortedRDD.saveAsTextFile('./wordCount.txt')
默认保存为两个文件:
![]()
分别存储如下:
# part-00000
('i', 2)
('you', 2)
# part-00001
('jump', 4)
2.3.2 WordCount执行过程图
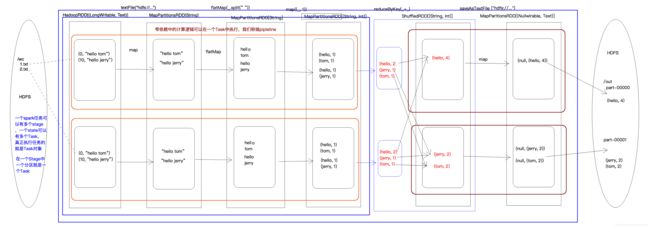
2.4 RDD的宽依赖和窄依赖
2.4.1 RDD依赖关系的本质内幕
由于RDD是粗粒度的操作数据集,每个Transformation操作都会生成一个新的RDD,所以RDD之间就会形成类似流水线的前后依赖关系;RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。如图所示显示了RDD之间的依赖关系。

从图中可知:
-
窄依赖:是指每个父RDD的一个Partition最多被子RDD的一个Partition所使用,例如map、filter、union等操作都会产生窄依赖;(独生子女)
-
宽依赖:是指一个父RDD的Partition会被多个子RDD的Partition所使用,例如groupByKey、reduceByKey、sortByKey等操作都会产生宽依赖;(超生)
需要特别说明的是对join操作有两种情况:
(1)图中左半部分join:如果两个RDD在进行join操作时,一个RDD的partition仅仅和另一个RDD中已知个数的Partition进行join,那么这种类型的join操作就是窄依赖,例如图1中左半部分的join操作(join with inputs co-partitioned);
(2)图中右半部分join:其它情况的join操作就是宽依赖,例如图1中右半部分的join操作(join with inputs not co-partitioned),由于是需要父RDD的所有partition进行join的转换,这就涉及到了shuffle,因此这种类型的join操作也是宽依赖。
总结:
在这里我们是从父RDD的partition被使用的个数来定义窄依赖和宽依赖,因此可以用一句话概括下:如果父RDD的一个Partition被子RDD的一个Partition所使用就是窄依赖,否则的话就是宽依赖。因为是确定的partition数量的依赖关系,所以RDD之间的依赖关系就是窄依赖;由此我们可以得出一个推论:即窄依赖不仅包含一对一的窄依赖,还包含一对固定个数的窄依赖。
一对固定个数的窄依赖的理解:即子RDD的partition对父RDD依赖的Partition的数量不会随着RDD数据规模的改变而改变;换句话说,无论是有100T的数据量还是1P的数据量,在窄依赖中,子RDD所依赖的父RDD的partition的个数是确定的,而宽依赖是shuffle级别的,数据量越大,那么子RDD所依赖的父RDD的个数就越多,从而子RDD所依赖的父RDD的partition的个数也会变得越来越多。
2.4.2 依赖关系下的数据流视图
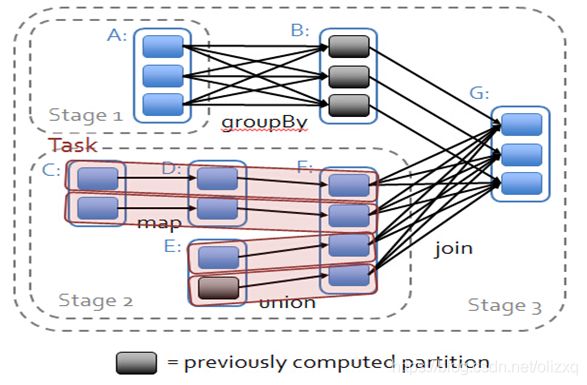
在spark中,会根据RDD之间的依赖关系将DAG图(有向无环图)划分为不同的阶段,对于窄依赖,由于partition依赖关系的确定性,partition的转换处理就可以在同一个线程里完成,窄依赖就被spark划分到同一个stage中,而对于宽依赖,只能等父RDD shuffle处理完成后,下一个stage才能开始接下来的计算。
因此spark划分stage的整体思路是:从后往前推,遇到宽依赖就断开,划分为一个stage;遇到窄依赖就将这个RDD加入该stage中。因此在图2中RDD C,RDD D,RDD E,RDDF被构建在一个stage中,RDD A被构建在一个单独的Stage中,而RDD B和RDD G又被构建在同一个stage中。
在spark中,Task的类型分为2种:ShuffleMapTask和ResultTask;
简单来说,DAG的最后一个阶段会为每个结果的partition生成一个ResultTask,即每个Stage里面的Task的数量是由该Stage中最后一个RDD的Partition的数量所决定的!而其余所有阶段都会生成ShuffleMapTask;之所以称之为ShuffleMapTask是因为它需要将自己的计算结果通过shuffle到下一个stage中;也就是说上图中的stage1和stage2相当于mapreduce中的Mapper,而ResultTask所代表的stage3就相当于mapreduce中的reducer。
在之前动手操作了一个wordcount程序,因此可知,Hadoop中MapReduce操作中的Mapper和Reducer在spark中的基本等量算子是map和reduceByKey;不过区别在于:Hadoop中的MapReduce天生就是排序的;而reduceByKey只是根据Key进行reduce,但spark除了这两个算子还有其他的算子;因此从这个意义上来说,Spark比Hadoop的计算算子更为丰富。
3、共享变量
在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本。这些变量会被复制到每台机器上,并且这些变量在远程机器上的所有更新都不会传递回驱动程序。通常跨任务的读写变量是低效的,但是,Spark还是为两种常见的使用模式提供了两种有限的共享变量:广播变量(broadcast variable)和累加器(accumulator)。
3.1 广播变量
3.1.1 为什么要将变量定义成广播变量?
如果我们要在分布式计算里面分发大对象,例如:字典,集合,黑白名单等,这个都会由Driver端进行分发,一般来讲,如果这个变量不是广播变量,那么每个task就会分发一份,这在task数目十分多的情况下Driver的带宽会成为系统的瓶颈,而且会大量消耗task服务器上的资源,如果将这个变量声明为广播变量,那么知识每个executor拥有一份,这个executor启动的task会共享这个变量,节省了通信的成本和服务器的资源。
3.1.2 广播变量图解
错误的,不使用广播变量

正确的,使用广播变量的情况
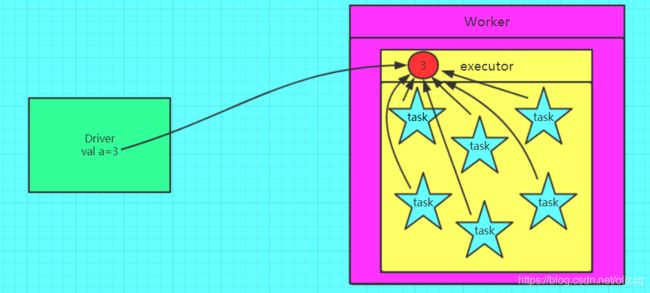
3.1.3 如何定义一个广播变量?
a = 3
brd_a = sc.broadcast(a)
brd_a
# 3.1.4 如何还原一个广播变量?
b = brd_a.value
b
# 3
3.1.5 定义广播变量需要的注意点?
变量一旦被定义为一个广播变量,那么这个变量只能读,不能修改
3.1.6 注意事项
1、能不能将一个RDD使用广播变量广播出去?
不能,因为RDD是不存储数据的。可以将RDD的结果广播出去。
2、 广播变量只能在Driver端定义,不能在Executor端定义。
3、 在Driver端可以修改广播变量的值,在Executor端无法修改广播变量的值。
4、如果executor端用到了Driver的变量,如果不使用广播变量在Executor有多少task就有多少Driver端的变量副本。
5、如果Executor端用到了Driver的变量,如果使用广播变量在每个Executor中只有一份Driver端的变量副本。
3.2 累加器
3.2.1 为什么要将一个变量定义为一个累加器?
在spark应用程序中,我们经常会有这样的需求,如异常监控,调试,记录符合某特性的数据的数目,这种需求都需要用到计数器,如果一个变量不被声明为一个累加器,那么它将在被改变时不会再driver端进行全局汇总,即在分布式运行时每个task运行的只是原始变量的一个副本,并不能改变原始变量的值,但是当这个变量被声明为累加器后,该变量就会有分布式计数的功能。
3.2.2 图解累加器
错误的图解

正确的图解

3.2.3 如何定义一个累加器?
a = sc.accumulator(0)
a
# Accumulator3.2.4 如何还原一个累加器?
b = a.value
b
# 0
3.2.5 注意事项
1、 累加器在Driver端定义赋初始值,累加器只能在Driver端读取最后的值,在Excutor端更新。
2、累加器不是一个调优的操作,因为如果不这样做,结果是错的
参考:
[1] RDD Programming Guide
[2] 常用的 68 个函数
[3] Spark学习之路 (三)Spark之RDD
[4] Spark学习之路 (四)Spark的广播变量和累加器