clickHouse相关知识详解
clickHouse相关知识详解
- clickHouse介绍
-
- 大数据技术背景
- 什么是clickHouse
-
- clickHouse核心特性
- clickHouse适用场景
- clickHouse不适用的场景
- 使用clickHouse的大厂
- clickHouse安装与部署
- 数据类型
- DDL:数据定义语言
clickHouse介绍
大数据技术背景
2006年开源项目Hadoop的出现,标志着大数据技术普及的开始,大数据技术真正开始走向大众。Hadoop最初指代的是分布式文件系统HDFS和MapReduce计算框架,但是它一路高歌猛进,在此基础上快速发展成为一个庞大的生态(包括 Yarn,Hive,HBase,Spark等等)。虽然Hadoop生态化的属性带来了许多便利,例如分布式文件系统HDFS可以直接作为其他组件的底层存储(Hive,HBase),生态内部的组件可以补重复造轮子,只需要相互借力,组合就能形成新的方案。但是生态化的另一面也会造成臃肿和复杂,同时随着现代化终端系统对数据的时效性和高并发的要求越来越高,Hadoop在这些情况下显得有点力不从心。
这时候一匹黑马横空出世——clickHouse。天下武功唯快不破,谈起ClickHouse,应该很多人都会很陌生。一来它是一个新生事物,听过的使用过的人非常少。二来可能没有hadoop生态那么完善和健壮,所以稳定性和功能还有所欠缺。但这些都不影响其迅速获得的良好的口碑和开挂的性能,作为特定领域的数据库,极其看好ClickHouse。下面展示了开源OLAP引擎测评报告,从中我们可以看出clickHouse的极高性能。
-
1.单表查询性能对比:
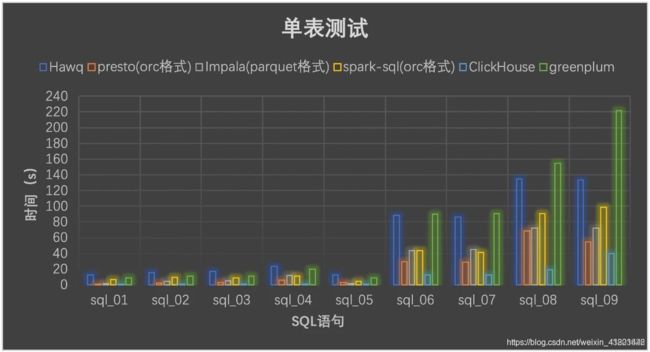
-
2.多表关联查询性能对比:
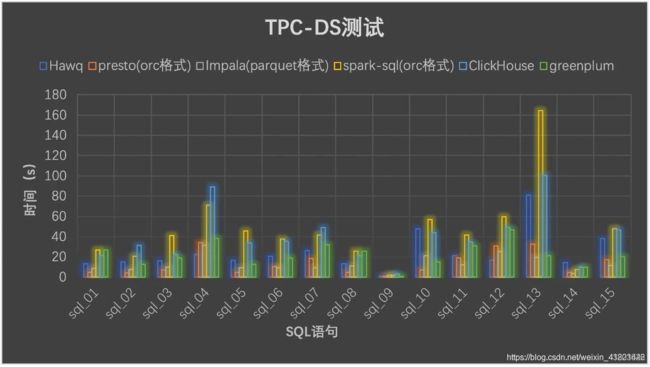
从上面图表对比可以看出,clickHouse在性能方面都表现不俗的能力,尤其在单表查询中
什么是clickHouse
ClickHouse是一个开源列式数据库,由俄罗斯排名第一的搜索引擎公司Yandex开发,主要用于线上分析处理(OLAP)。该系统允许分析实时更新的数据,以高性能著称。clickhouse官网地址:https://clickhouse.tech
-
ClickHouse是一个数据库管理系统DBMS
-
它是列式的
-
它为联机处理分析而生
什么是DBMS呢?就是说它是一个成体系的东西,对于数据的读写、存储、查询、修改、复制、事务、效率等等方方面面都有自己的架构方法论,换句话来说,它是庞大的,完善的。说到DBMS,联想到MYSQL就对了。但是,但是,相对于hadoop的笨重,ClickHouse可以说是一个小清新了。
什么是column-oriented呢?column-oriented是相对于row-oriented来讲的。典型的行式数据库,比如mysql。相对于行式数据库,列式数据库是一列数据存储为一个小单元,需要用多少列就读取多少列的数据,那么减少了IO的数据量,自然提升了效率。
什么是OLAP呢?联机分析处理是相对于联机事务处理而言的。联机事务处理面向的是数据修订、状态改变,比如业务数据的查询、订正、变更、写入等等。联机分析处理面向的是数据分析/挖掘,需要提供多维度、灵活的、高效的检索和查阅服务,一个比较典型的应用是BI平台。
ClickHouse是俄罗斯的百度——yandex公司开发的。yandex公司在处理自己公司日常数据业务中,开发了一套数据管理系统,随后进行了开源分享。因为脱胎于实践,来源于业务+技术沉淀,因此在使用过程中会有非常多暖心的、别的数据库不具备的特点(后面会一步步介绍)。另外,搞数据效率是永恒的命题,数学和计算机这两个东西缺一不可,恰恰俄罗斯就是盛产数学家的地方,而且之前看过一个由github统计的数据显示,俄罗斯的程序员在算法方面的活跃度排名世界第一,我们有理由相信ClickHouse前途光明。
clickHouse核心特性
-
1.完整的DBMS功能
DDL(数据定义语言): 可以动态地创建、修改或删除数据库、表和视图,而无需重启服务
DML(数据操作语言):可以动态查询、插入、删除和修改数据
权限控制:可以按照用户粒度设置数据库或者表的操作权限,满足生产环境的安全要求。
数据备份与恢复:提供了数据备份导出和导入恢复机制,满足生活环境的要求
分布式管理:提供集群模式,能够自动管理多个数据库节点。 -
2.列式存储与数据压缩
列式存储和数据压缩,对于一个高性能数据库来说是必不可少的特性。一个非常流行的观点,要想数据查询变得更快,最简单有效的方法是减少数据扫描范围和数据传输时的大小。而列式存储和数据压缩就可以帮助实现上述两点。列式存储和数据压缩通常是伴生的,因为一般来说列式存储是数据压缩的前提。 -
3.向量化执行
向量化执行,可以简单看作一项消除程序中循环的优化。其实就是并行执行,而非串行执行。为了实现向量化执行,需要利用CPU和SIMD指令。SIMD的全程是Single Instruction Multiple data,即用单条指令操作多条数据,现代计算机系统概念中,它是通过数据并行以提高性能的一种实现方式(其他的还有指令级并行和线程级并行),它的原理和在CPU寄存器层面实现数据的并行操作。 -
4.关系模型与sql查询
clickHouse与传统数据库一样,使用关系模型描述数据,并且完成使用SQL作为查询语句,同时clickHouse是区分大小写的 -
5.多样化的表引擎
最初的架构是基于MySQL实现的,所以在clickHouse设计中,能看到一些MySQL的影子,表引擎的设计就是其中之一。clickHouse共拥有合并树、内存、文件、和其他6大类20多种表引擎。其中每一种引擎都有各自的特点,适用于不同的实际业务场景。 -
6.多线程与分布式
-
7.多主架构
-
8.在线查询
-
9.数据分片与分布式查询
clickHouse适用场景
可以说clickHouse具备了人们对一款高性能的OLAP数据库的美好向往,所以它基本上能够胜任各种数据分析类的场景,并随着数据体量的增大,它的优势也会越来越明显。,非常适用于商业智能领域(也就是我们所说的BI领域),除此之外,它也能够被广泛应用于广告流量、Web、App流量、电信、金融、电子商务、物联网等众多领域。
clickHouse不适用的场景
- 不支持事务
- 不擅长根据组件按行粒度进行查询(虽然支持),所以不应该不clickHouse当做Key-Value数据库使用
- 不擅长按行删除数据(虽然支持)
使用clickHouse的大厂
国内有字节跳动、阿里、腾讯、新浪等一线大厂。
clickHouse安装与部署
安装部署教程详情请参考:https://www.sxy91.com/posts/clickhouse/
数据类型
作为一款分析型数据库,clickHouse提供了许多种数据类型,它们可以划分为基础数据类型、复合数据类型和特殊类型。
- 1.基础类型
基础类型只用数值、字符串和时间三种类型,没有Boolean类型,但可以使用整形的0或1替代
1)Int
clickHouse直接使用Int8、Int16、Int33、Int64,其末尾的数字整合表明了占用字节大小,8位=1字节
2)Float
clickHouse直接使用Float32和Float64代表单精度浮点数以及双精度浮点数
建议尽可能以整数形式存储数据。例如,将固定精度的数字转换为整数值,如时间用毫秒为单位表示,因为浮点型进行计算时可能引起四舍五入的误差。select 1-0.9 ┌───────minus(1, 0.9)─┐ │ 0.09999999999999998 │ └─────────────────────┘
3)Decimal
如果要求更高精度的计算,则需要使用定点数,clickHouse提供了Decimal32、Decimal64和Decimal128三种精度的定点数。可以通过两种形式声明定点:简写方式有Decimal32(S)、Decimal64(S)、Decimal128(S)三种,原生方式是Decimal(P, S),其中:
P代表精度,决定总位数(整数部分+小数部分),取值范围是1~38;S代表规模,决定小数位数,取值范围0到p
-
2.字符串类型
字符串类型可以细分为String、FixedString和UUID三类
1)String
字符串由String定义,长度不限。因此在使用String的时候无需声明大小。它完全和传统数据库的varchar、text、clob和blob等字符一样
2)FixString
FixString类型与传统数据库的char类型有些相似,对于一些字符长度的场合,可以使用固定长度的字符串。定长字符串可以用FixString(N)声明,其中N表示字符长度。但与char不同的是,FixString使用null字节填充末尾字符。而char通常使用空格填充。
3)UUID
UUID是一种常见的主键类型,在clickHouse中直接把它作为数据类型。UUID共有32位,它的格式为8-4-4-4-12,如果一个UUID类型的字段在写入数据时没有赋值,则会依照格式使用0填充 -
3.时间类型
时间类型分为DateTime、DateTime64和Date三类。clickHouse目前没有时间戳类型。时间类型最高的精度是秒,即若需要处理毫秒、微秒等大于秒分辨率的时间,则只能借助UInt类型实现。
DateTime类型包含时、分、秒信息,精确到秒,支持使用字符串形式写入
DateTime64可以记录亚秒,在DateTime之上增加精度的设置
Date类型不包含具体的时间信息,只精确到天,同样支持字符串形式写入 -
复合类型
clickHouse提供了数组、元组、枚举和嵌套四种数据类型
1)Array
有两种定义形式
以最小存储代价为原则,即使用最小可表达的数据类型
可以使用array函数来创建数组:array(T)也可以使用方括号直接创建:
[]示例代码:
SELECT array(1, 2) AS x, toTypeName(x) SELECT [1, 2] AS x, toTypeName(x) ┌─x─────┬─toTypeName(array(1, 2))─┐ │ [1,2] │ Array(UInt8) │ └───────┴─────────────────────────┘ 1 rows in set. Elapsed: 0.002 sec. :) SELECT [1, 2] AS x, toTypeName(x) SELECT [1, 2] AS x, toTypeName(x) ┌─x─────┬─toTypeName([1, 2])─┐ │ [1,2] │ Array(UInt8) │ └───────┴────────────────────┘ 1 rows in set. Elapsed: 0.002 sec.在同一个数组中可以包含多种数据类型,例如数组[1, 2.0]是可行的,但各类型之间是必须兼容,数组[1, ‘2’]则会报错
2)Tuple
元组类型由1~n个元素组成,每个元素之间允许设置不同的数据类型,且彼此之间不要求兼容。元组同样支持类型推断,其推断依据仍然以最小存储代价为原则
Tuple(T1, T2, …):元组,其中每个元素都有单独的类型。
创建元组的示例:
:) SELECT tuple(1,'a') AS x, toTypeName(x)
SELECT
(1, 'a') AS x,
toTypeName(x)
┌─x───────┬─toTypeName(tuple(1, 'a'))─┐
│ (1,'a') │ Tuple(UInt8, String) │
└─────────┴───────────────────────────┘
1 rows in set. Elapsed: 0.021 sec.
3)Enum
包括Enum8和Enum16两种枚举类型,
Key和Value是不允许重复的,要保证唯一性。其次,Key和Value的值都不能为Null,但Key允许是空字符串。
Enum 保存 ‘string’= integer 的对应关系。
Enum8 用 ‘String’= Int8 对描述。
Enum16 用 ‘String’= Int16 对描述。
用法演示:
创建一个带有一个枚举 Enum8(‘hello’ = 1, ‘world’ = 2) 类型的列:
CREATE TABLE t_enum
(
x Enum8('hello' = 1, 'world' = 2)
)
ENGINE = TinyLog
这个 x 列只能存储类型定义中列出的值:‘hello’或’world’。如果尝试保存任何其他值,ClickHouse 抛出异常
INSERT INTO t_enum VALUES ('hello'), ('world'), ('hello')
INSERT INTO t_enum VALUES
Ok.
3 rows in set. Elapsed: 0.002 sec.
insert into t_enum values('a')
INSERT INTO t_enum VALUES
Exception on client:
Code: 49. DB::Exception: Unknown element 'a' for type Enum8('hello' = 1, 'world' = 2)
从表中查询数据时,ClickHouse 从 Enum 中输出字符串值。
SELECT * FROM t_enum
┌─x─────┐
│ hello │
│ world │
│ hello │
└───────┘
如果需要看到对应行的数值,则必须将 Enum 值转换为整数类型
SELECT CAST(x, 'Int8') FROM t_enum
┌─CAST(x, 'Int8')─┐
│ 1 │
│ 2 │
│ 1 │
└─────────────────┘
4)Nested
一种嵌套表结构。一张数据表,可以定义任意多个嵌套类型字段,但每个字段的嵌套层级只支持一级,即嵌套表内不能继续使用嵌套类型。嵌套类型本质是一种多维数组的结构。嵌套表中的每个字段都是一个数组,并且行与行之间数组的长度无须对齐。在访问嵌套类型的数据时需要使用点符号。
- 特殊类型
1.Nullable
准确来说,Nullable并不能算一个独立的类型。它更像是一种辅助的修饰符,需要与基础数据类型搭配使用,示例:Nullable(String) ,但不能用于数组和元组这些复合类型,其次,应该慎用Nullable类型,包含Nullable的数据表,不然会是查询和写入性能变得很慢。因为在正常情况下,每个列字段的数据都会存储在对应的[Column].bin文件中,如果每一个列字段被Nullable类型修饰后,会额外生成一个[Column].null.bin文件专门保存它的Null值。这意味着在读取和写入数据时,需要一倍额外文件操作。
2.Domain
域名类型分为IPv4和IPv6两类,本质上他们是对整形和字符串的进一步封装。
与String类型的区别:
1)出于便捷性的考量,例如IPv4支持格式检查,格式错误的IP数据时无法被写入的
CREATE TABLE IP4_TEST(
url String,
ip IPv4
) ENGINE = Memory
INSERT INTO IP4_TEST VALUES ('www.baidu.com', '192.0.0')
code: 441. DB::Exception: Invalid IPv4 value
2)出于性能的考量,IPv4使用UInt32存储,相比String更加紧凑,占用的空间比较小,查询性能更快。IPv6类型是基于FixString(16)封装的
DDL:数据定义语言
- 1.创建数据库
默认的引擎, 默认操作本地或者是指定集群的数据
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster] [ENGINE = engine(...)]
数据库目前一共支持5种引擎:
1)Ordinary:默认引擎,在绝大多数情况新建库都会使用默认引擎,使用时无需声明
2)Dictionary:字典引擎,此类数据库会为所有数据字典创建它们的数据表
3)Memory:内存引擎,用于存放临时数据,此类数据库的数据表只会停留在内存中,不会涉及任何磁盘操作,当服务重启后数据会被清除
4)Lazy:日志引擎,此类数据库下只能使用Log系列的表引擎
5)MySQL:MySQLyinq,此类数据库会自动拉取远端MySQL中的数据,并为它们创建MySQL表引擎的数据表。
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]
ENGINE = MySQL('host:port', ['database' | database], 'user', 'password')
样例:
CREATE TABLE isc_adw.workflow
(
`id` Int64,
`name` String,
`create_time` Nullable(DateTime),
`update_time` Nullable(DateTime),
`is_delete` Int8,
`status` Int8,
`cron` Nullable(String),
`run_status` Int8,
`priority` Int32,
`start_time` Nullable(DateTime),
`end_time` Nullable(DateTime),
`page_config` Nullable(String),
`trigger_type` Nullable(Int32)
)
ENGINE = MySQL('10.30.30.11:23306',
'isc_adw',
'workflow',
'root',
'123456')
- 2.创建表
-目前clickHouse提供了三种最基本的建表方法:
1)常规定义法:
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] [db.]name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = engine
示例:
CREATE TABLE TEST_TABLE (
id Int32,
url String,
eventTime DateTime
) ENGINE = Mermory
2)复制其他表结构
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] [db.]name AS [db2.]name2 [ENGINE = engine]
示例:
CREATE TABLE IF NOT EXISTS default.TEST_TABLE_1 AS default.TEST_TABLE ENGINE = TinyLog
3)通过SELECT子句建立相应的表结构
CREATE [TEMPORARY] TABLE [IF NOT EXISTS] [db.]name ENGINE = engine AS SELECT ...
示例:
CREATE TABLE IF NOT EXISTS default.TEST_TABLE_1 ENGINE = TinyLog AS SELECT * FROM default.TEST_TABLE
clickHouse和大多数数据库一样,使用DESC查询可以返回数据表定义的结构,示例:
DESC default.TEST_TABLE
如果想要删除一张表,则可以使用DROP语句:
DROP TABLE default.TEST_TABLE
- 3.表数据插入
INSERT INTO主要用于向表中添加数据,基本格式如下:
INSERT INTO [db.]table [(c1, c2, c3)] VALUES (v11, v12, v13), (v21, v22, v23)
实例:
insert into t1 values(1,'zhangsan'),(2,'lisi'),(3,'wangwu')
还可以使用select来写入数据:
INSERT INTO [db.]table [(c1, c2, c3)] SELECT ...
实例:
insert into t2 select * from t3
- 4.临时表
ClickHouse支持具有以下特征的临时表:
1)会话结束时,包括连接断开,临时表都会消失。
2)临时表仅使用内存引擎。
3)无法为临时表指定数据库。它是在数据库外部创建的。
4)无法在所有群集服务器上通过分布式DDL查询创建临时表(通过使用ON CLUSTER):该表仅存在于当前会话中。
5)如果一个临时表与另一个表具有相同的名称,并且查询指定表名而不指定DB,则将使用该临时表。
6)对于分布式查询处理,查询中使用的临时表将传递到远程服务器。
CREATE TEMPORARY TABLE [IF NOT EXISTS] table_name(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...)
- 5.分区表
- 6.视图view
普通视图:不会存储数据,只保存了一个query,一般用作子查询,当base表删除后不可用
CREATE VIEW view_name AS SELECT * FROM default.TEST_TABLE
物化视图支持表引擎,数据的保存形式由表的引擎决定。
创建语法:
CREATE [MATERIALIZED] VIEW [IF NOT EXISTS] [db.]table_name [TO[db.]name]
[ENGINE = engine] [POPULATE] AS SELECT ...
创建物化视图的限制:
1.必须指定物化视图的engine 用于数据存储
2.TO [db].[table]语法的时候,不得使用POPULATE。
3.查询语句(select)可以包含下面的子句: DISTINCT, GROUP BY, ORDER BY, LIMIT…
4.雾化视图的alter操作有些限制,操作起来不大方便。
5.若物化视图的定义使用了TO [db.]name 子语句,则可以将目标表的视图 卸载 DETACH 在装载 ATTACH
物化视图的数据更新:
1.物化视图创建好之后,若源表被写入新数据则物化视图也会同步更新
2.POPULATE 关键字决定了物化视图的更新策略:
若有POPULATE 则在创建视图的过程会将源表已经存在的数据一并导入,类似于 create table … as
若无POPULATE 则物化视图在创建之后没有数据,只会在创建只有同步之后写入源表的数据.
clickhouse 官方并不推荐使用populated,因为在创建物化视图的过程中同时写入的数据不能被插入物化视图。
3.物化视图不支持同步删除,若源表的数据不存在(删除了)则物化视图的数据仍然保留
4.物化视图是野种特殊的数据表,可以用show tables 查看
:) SHOW TABLES
┌─name ───────── ─ ─┐
│ .inner.view_test │
│ .inner.view_test1 │
└─────── ──┘
发现物化视图也在其中,它们是使用了.inner 特殊前缀的数据表
- 7.数据表的基本操作:
添加、删除、修改列
ALTER TABLE [db].table [ON CLUSTER cluster] ADD|DROP|MODIFY COLUMN ...
rename 支持*MergeTree和Distributed
rename table db.table1 to db.table2 [ON CLUSTER cluster]
truncate table db.table;不支持Distributed引擎
示例:
ALTER TABLE isc_test.edge_data ADD COLUMN column5 Nullable(Int32), MODIFY COLUMN column2 String, rename column column1 to col1