所有集群启动的命令
所有集群启动的命令
- 查询所有节点
- 启动Hadoop集群(Yarn模式)
- 关闭Hadoop集群
- Spark(local模式)
- 启动Spark集群
-
- standalone模式(不用了)
- 关闭standalone模式
- HA下的standalone模式
- 关闭HA-standalone模式
- Yarn模式(重点)
- 关闭Spark集群
- 启动flink集群
- 关闭flink集群
- 启动Zookeeper集群
- 关闭Zookeeper集群
- 启动Kafka集群
- 停止Kafka集群
⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计6391字,阅读大概需要3分钟
更多学习内容, 欢迎关注【文末】我的个人微信公众号:不懂开发的程序猿
个人网站:https://jerry-jy.co/
查询所有节点
jpsall
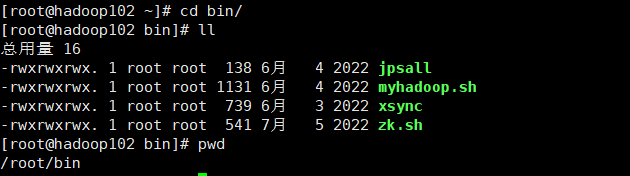
所有的一键启动命令在
/root/bin
启动Hadoop集群(Yarn模式)
一键启动爆错了
myhadoop.sh start
myhadoop.sh stop
分别启动Hadoop
hadoop102启动HDFS
[root@hadoop102 hadoop-3.3.3]# sbin/start-dfs.sh
在hadoop102启动历史服务器
[root@hadoop102 hadoop-3.3.3]# mapred --daemon start historyserver
在配置了ResourceManager的节点 hadoop103启动YARN
[root@hadoop103 hadoop-3.3.3]# sbin/start-yarn.sh
查询节点启动情况
[root@hadoop102 hadoop-3.3.3]# jpsall
=============== hadoop102 ===============
11720 Jps
10619 NameNode
11645 JobHistoryServer
10862 DataNode
11327 NodeManager
=============== hadoop103 ===============
7491 Jps
6995 NodeManager
6837 ResourceManager
6602 DataNode
=============== hadoop104 ===============
6546 Jps
6038 DataNode
6122 SecondaryNameNode
6286 NodeManager
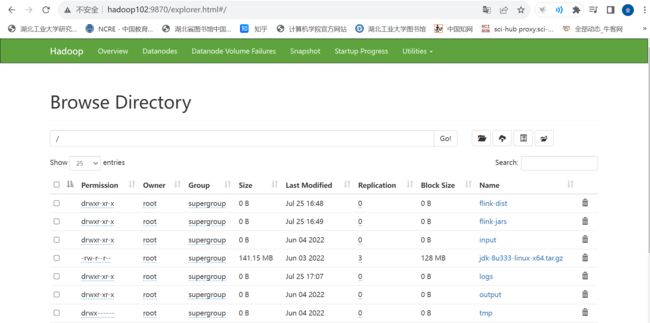
(4)Web端查看HDFS的NameNode
-
(a)浏览器中输入:http://hadoop102:9870
-
(b)查看HDFS上存储的数据信息
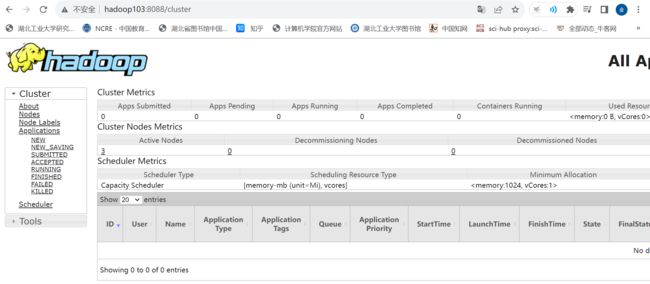
(5)Web端查看YARN的ResourceManager
-
(a)浏览器中输入:http://hadoop103:8088
-
(b)查看YARN上运行的Job信息
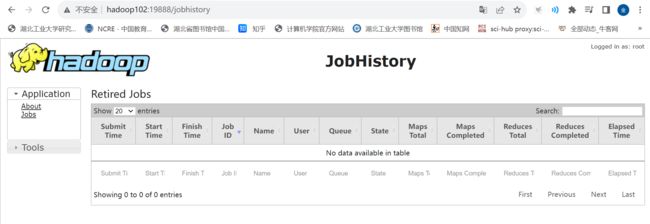
6)查看JobHistory
http://hadoop102:19888/jobhistory
关闭Hadoop集群
hadoop102关闭HDFS,历史服务器
[root@hadoop102 hadoop-3.3.3]# sbin/stop-dfs.sh
[root@hadoop102 hadoop-3.3.3]# mapred --daemon stop historyserver
hadoop103关闭YARN
[root@hadoop103 hadoop-3.3.3]# sbin/stop-yarn.sh
Spark(local模式)
启动Spark前先启动Hadoop集群,不然后面无法RDD计算
启动Spark
[root@hadoop102 spark-3.0.0-bin-hadoop3.2]# pwd
/opt/module/spark-3.0.0-bin-hadoop3.2
[root@hadoop102 spark-3.0.0-bin-hadoop3.2]# bin/spark-shell
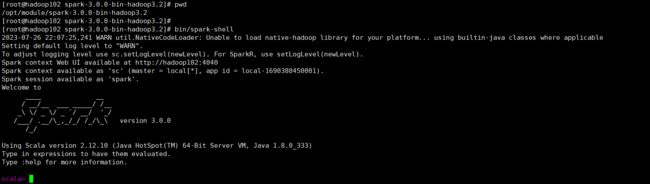
证明环境没问题
scala> sc.textFile("data/word.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
res0: Array[(String, Int)] = Array((Hello,3), (Scala,2), (Spark,1))
![]()
这里的“data/word.txt”文件在
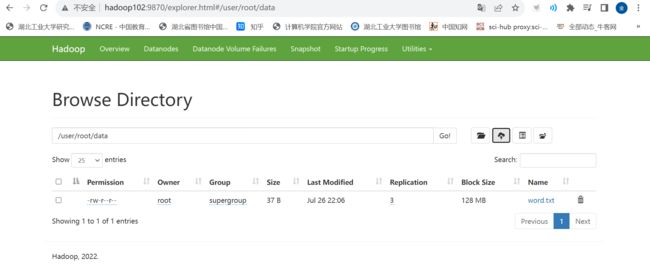
提交计算作业
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
启动Spark集群
standalone模式(不用了)
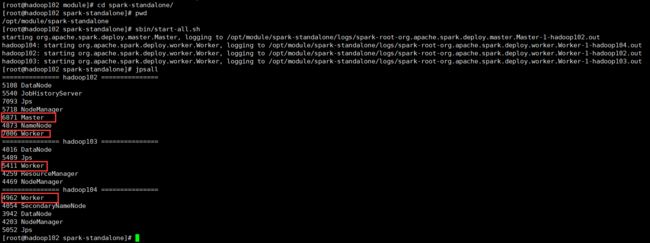
[root@hadoop102 spark-standalone]# sbin/start-all.sh
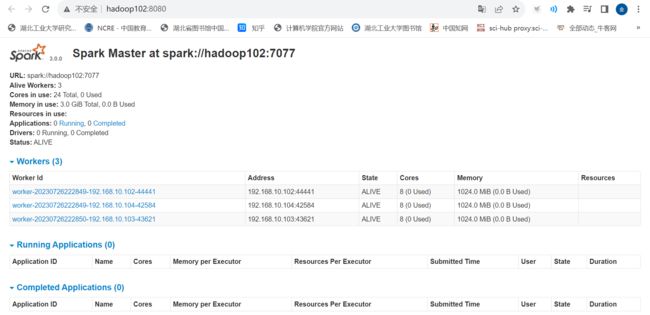
查看 Master 资源监控 Web UI 界面: http://hadoop102:8080
启动历史服务器
[root@hadoop102 spark-standalone]# sbin/start-history-server.sh
查看历史服务:http://hadoop102:18080

提交计算作业
[root@hadoop102 spark-standalone]# bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
关闭standalone模式
[root@hadoop102 spark-standalone]# sbin/stop-all.sh
[root@hadoop102 spark-standalone]# sbin/stop-history-server.sh
HA下的standalone模式
由于一台master会出现单点故障,为了配置高可用(HA),进行了spark-env.sh修改,需要用到Zookeeper,
因此先启动Zookeeper
cd /opt/module/zookeeper-3.5.7
[root@hadoop103 zookeeper-3.5.7]# zk.sh start
接着在hadoop102上启动master1,作为主节点
[root@hadoop102 spark-standalone]# sbin/start-all.sh
[root@hadoop102 spark-standalone]# sbin/start-history-server.sh
查看 Master 资源监控 Web UI 界面: http://hadoop102:8989
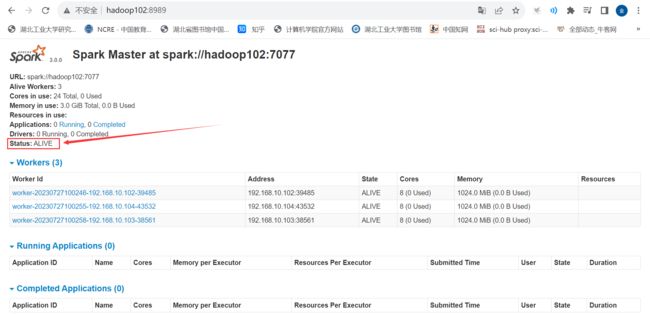
接着在hadoop103上启动master2,作为备用节点
[root@hadoop103 spark-standalone]# sbin/start-master.sh
查看 备用Master 资源监控 Web UI 界面: http://hadoop103:8989
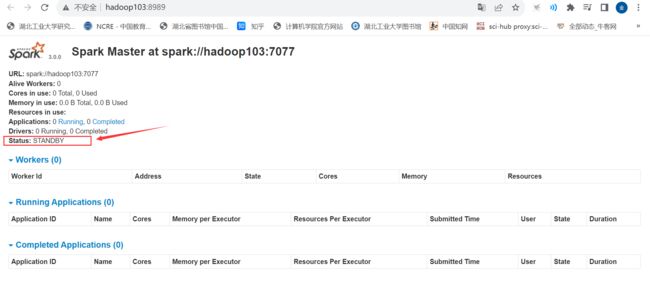
提交计算作业
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077,hadoop103:7077 \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
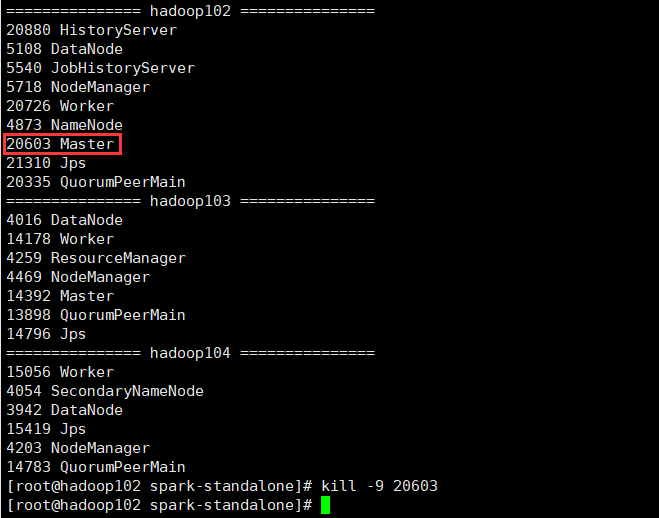
模拟其中 主master 宕机了
先查询进程,再kill -9 杀掉
[root@hadoop102 spark-standalone]# jpsall
[root@hadoop102 spark-standalone]# kill -9 20603
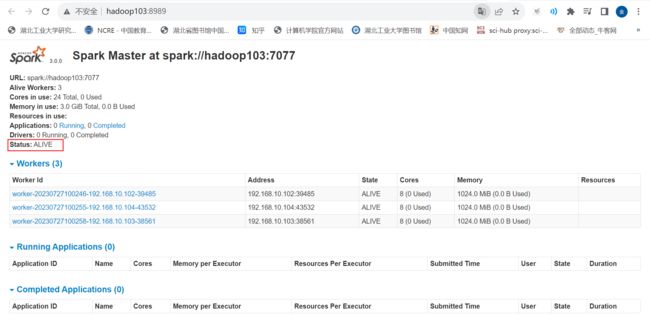
接着去WebUI查看 备用Master 资源监控,发现变成了主master,这就是zookeeper发现了原来的主mater宕机,备用master上位
关闭HA-standalone模式
先关闭集群,再关闭zookeeper
[root@hadoop102 spark-standalone]# sbin/stop-all.sh
[root@hadoop102 spark-standalone]# sbin/stop-history-server.sh
[root@hadoop103 spark-standalone]# sbin/stop-master.sh
[root@hadoop103 zookeeper-3.5.7]# zk.sh stop
Yarn模式(重点)
首先需要启动Hadoop的 HDFS 以及 YARN 集群
再提交作业,测试性能
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
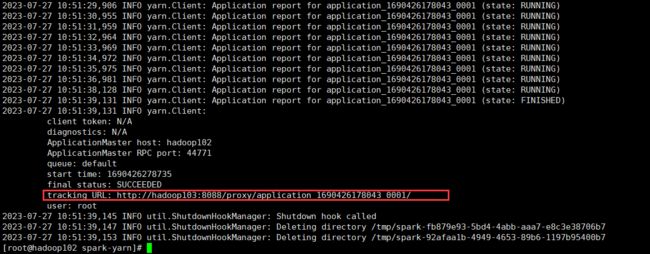
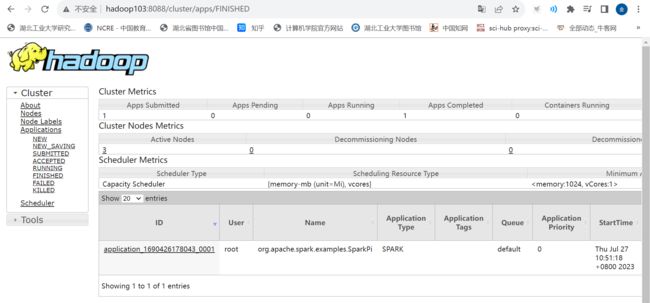
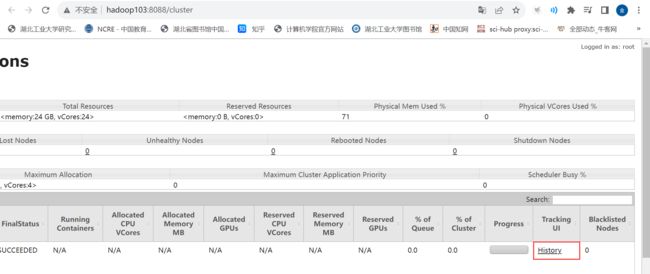
查看 http://hadoop103:8088 页面,点击 History,查看历史页面
启动历史服务器
[root@hadoop102 spark-yarn]# sbin/start-history-server.sh
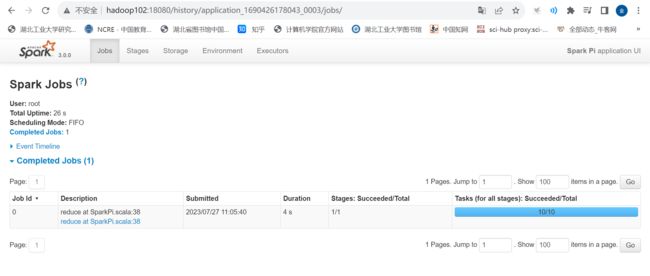
再次重新提交作业
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode client \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
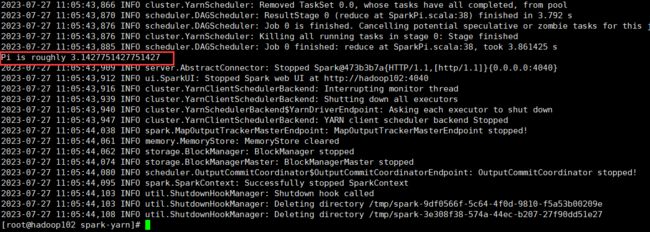
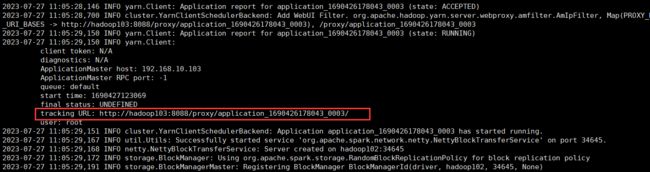
Web 页面查看日志:http://hadoop103:8088
关闭Spark集群
启动flink集群
[root@hadoop102 flink-1.17.1]# bin/start-cluster.sh
关闭flink集群
[root@hadoop102 flink-1.17.1]# bin/stop-cluster.sh
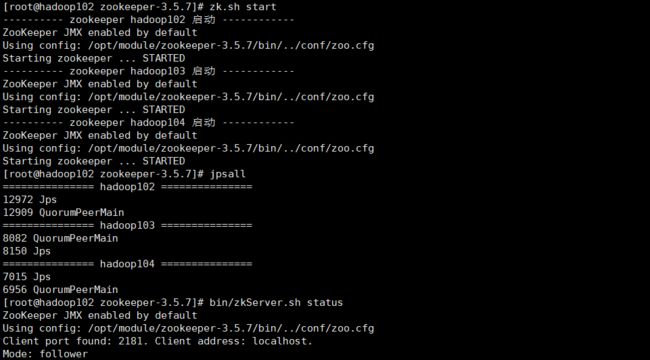
启动Zookeeper集群
cd /opt/module/zookeeper-3.5.7
zk.sh start
jpsall
# 查询哪一个zookeeper是leader,一般是hadoop103
bin/zkServer.sh status
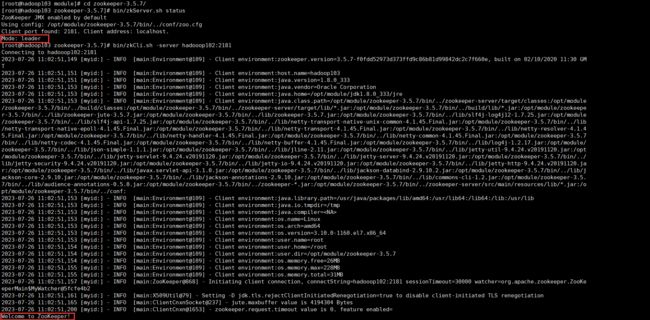
# 在leader上运行这个
bin/zkCli.sh -server hadooop102:2181
关闭Zookeeper集群
zk.sh stop
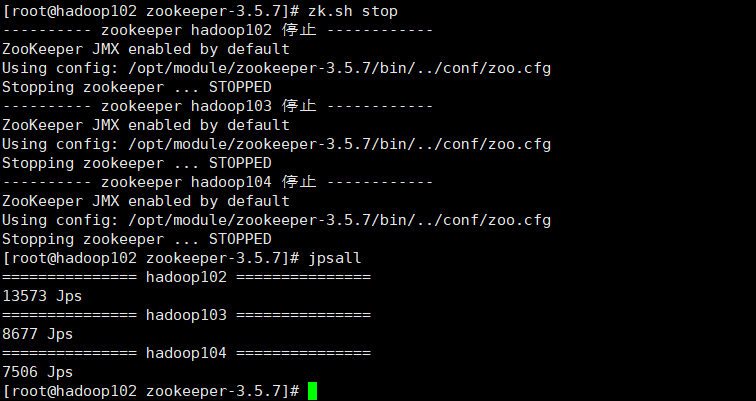
启动Kafka集群
一定要先启动zk再启动kafka,关闭的时候先关闭kafka,再关闭zk。
一键启动
kafka.sh start
或
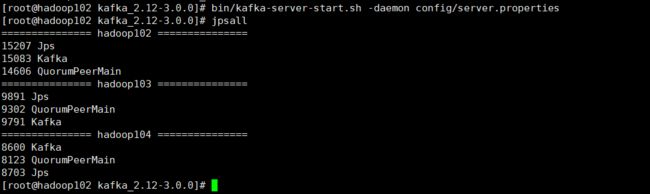
分别在Hadoop102,103,104上操作如下命令:
[root@hadoop102 kafka_2.12-3.0.0]# bin/kafka-server-start.sh -daemon config/server.properties
查看节点启动情况
jpsall
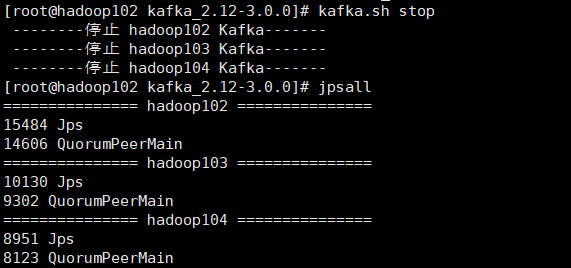
停止Kafka集群
一键停止
kafka.sh stop
或
分别在Hadoop102,103,104上操作如下命令:
[root@hadoop102 kafka_2.12-3.0.0]# bin/kafka-server-stop.sh
–end–