MongoDB学习(三)MongoDB 体系架构
1.MongoDB的体系结构
文档(document)、集合(collection)、数据库(database)的层次结构如下图:
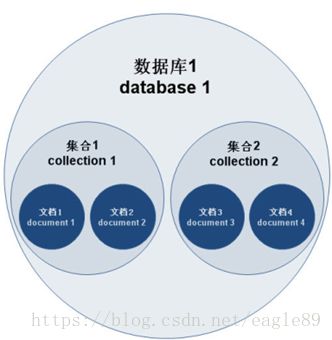
数据库中的对应关系,及存储形式的说明
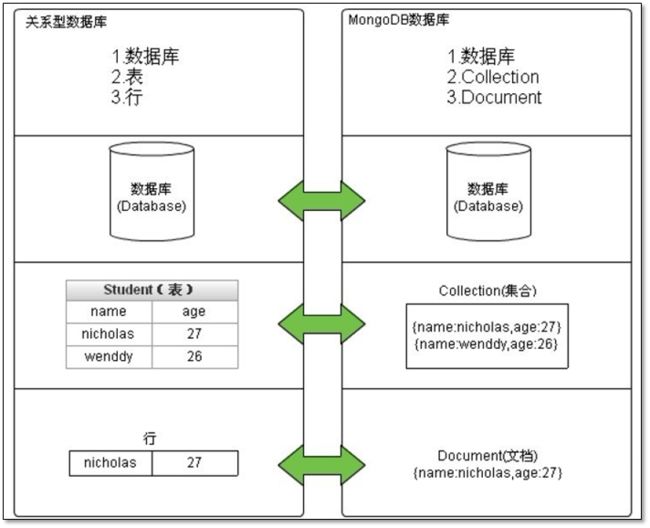
MongoDB与SQL的结构对比详解
SQL Terms/Concepts |
MongoDB Terms/Concepts |
database |
database |
table |
collection |
row |
document or BSON document |
column |
field |
index |
index |
table joins |
embedded documents and linking |
primary key Specify any unique column or column combination as primary key. |
primary key In MongoDB, the primary key is automatically set to the _id field. |
aggregation (e.g. group by) |
aggregation pipeline See the SQL to Aggregation Mapping Chart. |
1.1MongoDB的体系结构详细说明
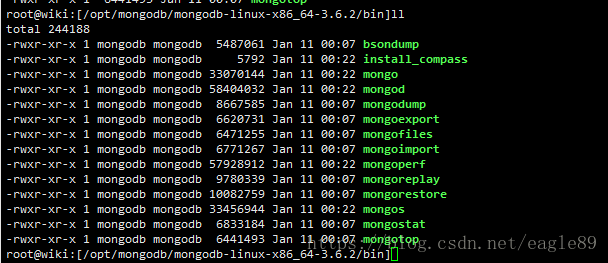
- 数据库服务(mongod)
- 分片集群部署中,数据和查询的路由服务(mongos)
- shell客户端(mongo)
- 导入导出工具(mongoimport / mongoexport)
- 备份恢复工具(mongodump / mongorestore)
- 拉取并重放oplog的工具(mongooplog)
- 监控工具(mongostat、mongotop、mongosniff)
- GridFS的命令行操作工具(mongofiles)
- 性能测试工具(mongoperf,暂时只能测I/O)
- 查看bson文件的工具(bsondump)
其中最主要的程序当然是mongod(数据库服务),mongod在不同的部署方案中(单机部署,副本集部署,分片集群部署),通过不同的配置,可以扮演多种不同的角色:
- 在单机部署中扮演 数据库服务器(提供所有读写功能)
- 在副本集部署中,通过配置,可以部署为 primary节点(主服务器,负责写数据,也可以提供查询)、secondary节点(从服务器,它从主节点复制数据,也可以提供查询)、以及arbiter节点(仲裁节点,不保存数据,主要用于参与选举投票)
- 在分片集群中,除了在每个分片中扮演上述角色外,还扮演着配置服务器的角色(存储有分片集群的所有元数据信息,mongos的数据路由分发等都要依赖于它)
在一台服务器上,可以启动多个mongod服务。但在实际生产部署中,通常还是建议一台服务器部署一个mongod实例,这样不仅减少资源竞争,而且服务器故障也不会同时影响到多个服务。
2.MongoDB的数据逻辑结构
- 一个mongod实例中允许创建多个数据库。
- 一个数据库中允许创建多个集合(集合相当于关系型数据库的表)。
- 一个集合则是由若干个文档构成(文档相当于关系型数据库的行,是MongoDB中数据的基本单元)。
2.1详细说明数据库\集合\文档
2.1.1数据库
一个数据库中可以创建多个集合,原则上我们通常把逻辑相近的集合都放在一个数据库中,当然出于性能或者数据量的关系,也可能进行拆分。
在MongoDB中有几个内建的数据库:
1) admin
admin库主要存 放有数据库帐号相关信息。
2)local
local数据库永远不会被复制到从节点,可以用来 存储限于本地单台服务器的任意集合
副本集的配置信息、oplog就存储在local库中。
注意:重要的数据不要存储在local库,因为没有冗余副本,如果这个节点故障,存储在local库的数据就无法正常使用了。
3)config
config数据库 用于分片集群环境,存放了分片相关的元数据信息。
4)test
MongoDB默认创建的一个测试库,连接mongod服务时,如果不指定连接的具体数据库,默认就会连接到test库。
2.1.2集合
集合由若干条文档记录构成。
前面介绍MongoDB的时候提到过,集合是schema-less的(无模式或动态模式),这意味着集合不需要在读写数据前创建模式就可以使用, 集合中的文档也可以拥有不同的字段,随时可以任意增减某个文档的字段。
在集合上可以对文档进行增删改查以及进行聚合操作。
在集合上还可以对文档中的字段创建索引。
除了一般的集合外,还可以创建一种叫做定容集合(capped collection)类型的集合, 这种集合与一般集合主要的区别是,它可以限制集合的容量大小,在数据写满的时候,又可以从头开始覆盖最开始的文档进行循环写入。副本集就是利用这种类型的集合作为oplog,记录primary节点上的写操作,并且同步到从节点重放,以实现主副节点数据复制的功能。
2.1.3文档
文档是MongoDB中数据的基本存储单元,它以一种叫做BSON文档的结构表示。
BSON,即Binary JSON,多个键及其关联的值有序地存放在其中,类似映射,散列或字典。
注意:文档中的键/值对是有序的,不同序则是不同文档。并且键是区分大小写的,否则也为不同文档。
文档的键是字符串,而值除了字符串,还可以是int, long, double,boolean,子文档,数组等多种类型。
文档中不能有重复的键。
每个文档都有一个默认的_id键,它相当于关系型数据库中的主键,这个键的值在同一个集合中必须是唯一的,_id键值默认是ObjectId类型,在插入文档的时候,如果用户不设置文档的_id值得花,MongoDB会自动生成生成一个唯一的ObjectId值进行填充。
3.MongoDB的数据存储结构
3.1数据库文件类型
MongoDB的数据库文件主要有3种:
- journal 日志文件
- namespace 表名文件
- data 数据及索引文件
日志文件
MongoDB的日志文件只是用来在系统出现宕机时候恢复尚未来得及同步到硬盘的内存数据。日志文件会存放在一个分开的目录下面。启动时候MongoDB会自动预先创建3个每个为1G的日志文件(初始为空)。除非你真的有持续海量数据并发写入,一般来说3个G已经足够。
命名文件 dbname.ns
用来存储整个数据库的集合以及索引的名字。这个文件不大,默认16M,可以存储24000个集合或者索引名以及那些集合和索引在数据文件中得具体位置。通过这个文件MongoDB可以知道从哪里去开始寻找或插入集合的数据或者索引数据。这个值可以通过参数调整至2G。
数据文件 dbname.0, dbname.1,… dbname.n
MongoDB的数据以及索引都存放在一个或者多个MongoDB数据文件里。第一个数据文件会以“数据库名.0”命名,如 my-db.0。这个文件默认大小是64M,在接近用完这个64M之前,MongoDB 会提前生成下一个数据文件如my-db.1。数据文件的大小会2倍递增。第二个数据文件的大小为128M,第三个为256M。一直到了2G以后就会停止,一直按这个2G这个大小增加新的文件。
当然MongoDB还会生成一些临时文件如 _tmp 和 mongod.lock等, 不过他们跟我们的讨论都没有太大相关性。
3.1数据文件结构
Extent
在每一个数据文件内,MongoDB把所存储的BSON文档的数据和B树索引组织到逻辑容器“Extent”里面。如下图所示(my-db.1和my-db.2 是数据库的两个数据文件):
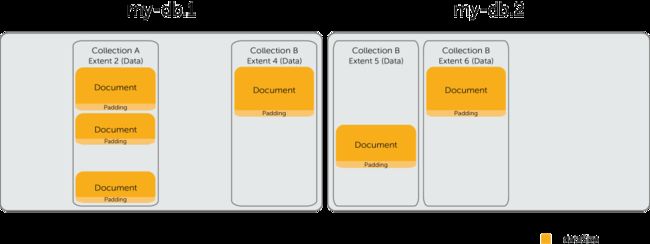
- 一个文件可以有多个Extent
- 每一个Extent只会包含一个集合的数据或者索引
- 同一个集合的数据或索引可以分布在多个Extent内。这几个Extent也可以分步于多个文件内
- 同一个Extent不会又有数据又有索引
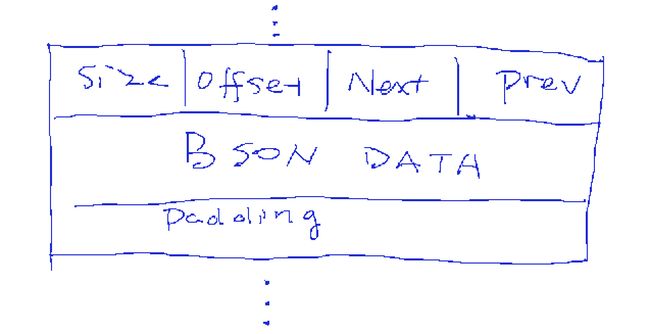
Record 记录
在每个Extent里面存放有多个”Record“, 每一个记录里包含一个记录头以及MongoDB的BSON文档,以及一些额外的padding空间。Padding是MongoDB在插入记录时额外分配一些未用空间,这样将来文档变大的时候不至于需要把文档迁移到别处。 记录头以整个记录的大小开始,包括该记录自己的位置以及前一个记录和后一个记录的位置。可以想象成一个Double Linked List。
数据库大小参数
在之前的基础上,我们可以来理解一下db.stats()里面关于空间大小参数的含义。
dataSize
dataSize是最接近真实数据大小的一个参数。你可以用来检查你的数据有多少。这个大小包括了数据库(或者集合)的每条记录的总和。注意每条记录除了BSON文档外还有header及padding这些额外开销。所以实际大小会比真正数据所占空间会稍大。
当删除文档的时候,这个参数会相应变小因为它是所有文档数的大小总和。如果你的文档没有删除,只是文档内部的字段被删除或缩小,则不会对dataSize 有影响。原因就是因为文档所在记录还在,并且整条记录所占空间并无改动,只不过记录内的未用空间变多了而已。
storageSize
这个参数等于数据库或者某个集合所有用到的Data Extents的总和。注意这个数字会大于dataSize因为Extent里面会有一些删除文档之后留下来的碎片(deleted)。及时你的storageSize大出dataSize很多,这个也不一定就是很糟糕的情况。 如果有新插入的文档小于或等于碎片的大小,MongoDB会重新利用这个碎片来存储新的文档。不过在这之前这些碎片将一直会被保留在那里占用空间。由于这个原因,你删除文档的时候这个参数不会变小。
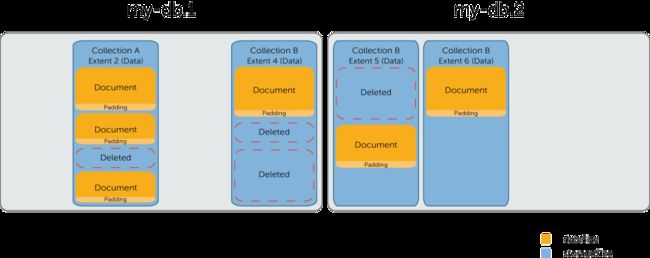
碎片问题会因为运行的时间变长而变得严重。你可以通过 compact 命令来进行碎片清理或者通过新架一台从机复制所有数据,然后变成主节点的方式来解决这些碎片。
fileSize
这个参数只在数据库上有效,指的是实际文件系统中用到的文件的大小。它包括所有的数据Extents的总和,索引Extent的总和,以及一些未被分配的空间。之前提到MongoDB会对数据库文件创建时候进行预分配,例如最小就是64M,哪怕你只有几百个KB的数据。所以这个参数可能会比实际的数据大小会大不少。 这些额外未用空间是用来保证MongoDB可以在新的数据写入时候快速的分配新的Extent,避免引起磁盘空间分配引起的延迟。
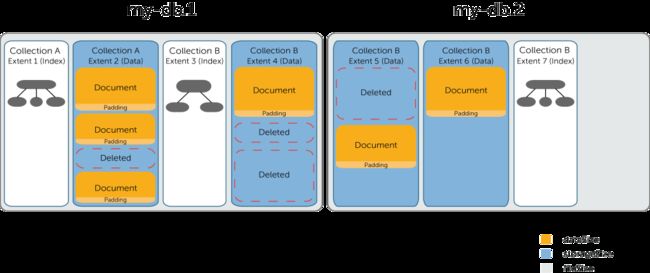
值得注意的是,当你删除文档,或甚至集合和索引,这个参数不会变小。换句话说,数据库所使用的硬盘空间只会上升(或者不变),而不会因为删除数据而变小。当然需要知道的是这并不就意味着浪费,只是说有很多预留空间而已。