docker学习笔记
传统虚拟机和docker的区别
-
虚拟机是在物理资源层面实现的隔离,相对于虚拟机,Docker是你APP层面实现的隔离,并且省去了虚拟机操作系统(Guest OS)),从而节省了一部分的系统资源;
-
Docker守护进程可以直接与主操作系统进行通信,为各个Docker容器分配资源;它还可以将容器与主操作系统隔离,并将各个容器互相隔离。
-
虚拟机启动需要数分钟,而Docker容器可以在数毫秒内启动。由于没有臃肿的从操作系统,Docker可以节省大量的磁盘空间以及其他系统资源。
-
虚拟机与容器docker的区别,在于vm多了一层guest OS,虚拟机的Hypervisor会对硬件资源也进行虚拟化,而容器Docker会直接使用宿主机的硬件资源。 因为虚拟机对物理环境操作系统也进行了虚拟,所以它隔离的更加彻底。而docker只是通过namespce使容器与主机隔离,容器与容器隔离,但仍然使是直接使用主机的操作系统资源。
-
容器只是运行在宿主机上的一种特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作系统内核。 如果想要运行不同操作系统的环境容器,docker做不到。
docker隔离性
-
文件系统隔离: 每个Docker容器都有自己的文件系统根目录,这意味着一个容器中的文件对其他容器不可见。这样就可以避免不同容器之间的文件冲突和干扰。
-
网络隔离: 每个Docker容器都有自己的网络命名空间,因此每个容器可以具有不同的网络配置。这样就可以防止容器之间互相干扰,并且容器可以更好地控制容器访问外部网络的方式。
-
进程隔离: 每个Docker容器都有自己的进程命名空间,这意味着一个容器中的进程对其他容器不可见。这样就可以防止容器之间的进程互相干扰,也可以更好地控制进程资源的使用。
-
用户隔离: 每个Docker容器都有自己的用户命名空间,这意味着一个容器中的用户对其他容器不可见。这样就可以防止容器之间的用户干扰,从而提高容器的安全性。
run命令执行
首先会在本地查找运行的镜像,找到镜像,以该镜像为模板生成容器实例运行,未找到该对象,会去dockerhub远程仓库查找该镜像,找到了会下载到本地,并以该镜像为模板生产容器实例运行,未找到报错。
docker常用命令
docker image # 罗列本地镜像 TAG:镜像的版本号
docker search name #从dockerhub仓库查找某一镜像
docker pull name #从dockerhub 拉去某一镜像
docker system df #查看docker数据卷的使用情况
docker rmi name/id #删除某一个镜像
docker run [OPTIONS] IMAGE [COMMAND] [ARG...] //启动docker
// options 说明
//--name=容器名字 为容器指定一个启动名字
//-d 后台运行容器,并返回容器id
//-i 以交互模式运行容器,与-t配合使用
//-t 为容器重新分配一个为输入终端
//-p 小写p,指定端口号映射
//-P 大写P,随机端口映射
//启动交互式容器后,输入exit退出并关闭容器,ctrl+p+q退出终端,但不关闭
docker rm 容器id //删已经关闭的容器
docker stop id/name //停止容器
docker start/restart id/name //开启/重启 容器
docker kill id/name //强制停止容器
docker logs id //查看某一容器的日志
docker top id //查看某一容器运行的进程
docker inspect id //查看某一容器内部运行细节
docker exec -it id /bin/bash //在容器中打开新的终端,并且可以启动新进程,用exit是退出当前终端,不会导致容器关闭
docker attach id//直接进入容器启动命令的终端,exit会让容器关闭
docker cp id:容器上的文件路径 主机路径 //将容器上的文件拷贝到主机
docker导入导出
docker export id > name.tar //导出
docker import name.tar :TAG //导入
遇到的坑
我尝试使用export导出一个redis容器,再通过import导入,但是出现了问题,导入的镜像无法启动。
大概原因:export 导出(import 导入)是根据容器拿到的镜像,再导入时会丢失镜像所有的历史记录和元数据信息(即仅保存容器当时的快照状态),所以无法进行回滚操作。
正确做法:我们可以将存有数据的redis容器commit成一个新的镜像,再通过save将镜像保存为tar文件,然后通过load加载tar文件,获得新镜像,使用该镜像启动的容器会保留原有数据。
docker 镜像加载原理
分层文件系统
docker 在下载镜像时是很明显的分层下载的,因为docker使用的是分层文件系统。
UnionFS(联合文件系统)
- docker的镜像是一层一层叠加形成的,我们可以在基础镜像生成的实例化容器上添加自己的配置后,打包成新的镜像,此时这个新镜像就挂载了原先镜像的文件目录,但有在此基础上新增了一些内容。
- docker的镜像文件是不可写的,容器是可写的。
镜像加载
docker镜像加载
Docker的镜像实际上由一层一层的文件系统组成,这种层级的文件系统UnionFS(联合文件系统)。
分为两个部分:
-
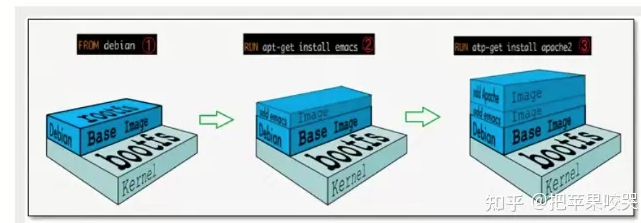
bootfs(boot file system):主要包含bootloader和kernel(Linux内核),bootloader主要是引导加载kernel,Linux刚启动时会加载bootfs文件系统,而在Docker镜像的最底层也是bootfs这一层,这与我们典型的Linux/Unix系统是一样的,包含boot加载器和内核。当boot加载完成之后,整个内核就都在内存中了,此时内存的使用权已由bootfs转交给内核,此时系统也会卸载bootfs。即:系统启动时需要的引导加载,这个过程会需要一定时间。就是黑屏到开机之间的这么一个过程。电脑、虚拟机、Docker容器启动都需要的过程。在说回镜像,所以这一部分,无论是什么镜像都是公用的。
-
rootfs(root file system):rootfs在bootfs之上。包含的就是典型Linux系统中的/dev,/proc,/bin,/etc等标准目录和文件。rootfs就是各种不同的操作系统发行版,比如Ubuntu,Centos等等。即:镜像启动之后的一个小的底层系统,这就是我们之前所说的,容器就是一个小的虚拟机环境,比如Ubuntu,Centos等,这个小的虚拟机环境就相当于rootfs。
bootfs和rootfs关系如下图:
docker容器数据卷
大致概念:映射本机目录与容器目录,实现两个数据的互通,防止重要数据的丢失。
卷是文件目录的意思,通过设置容器数据卷,容器就会绕过联合文件系统,将数据存储到指定的文件目录中
数据卷挂载命令
在docker运行时加上-v参数 进行 文件的映射,-v参数如下:
-v 主机目录: 容器目录 :参数
参数可以是 rw 或者 ro,-v也可以有多组
- rw 表示容器可读可写,也是默认参数
- ro 表示容器只能读
数据卷挂载后,若容器崩了,数据不会丢失。
容器数据卷的继承
在启动容器时,可以通过数据卷的继承来使用其他容器的目录映射关系。
docker run -it --volumnes-from 父类 镜像
继承后,父类数据卷容器挂掉,不会影响继承数据卷的新容器。
常用软件的下载
mysql
- 启动时需要设置密码。
-e MYSQL_ROOT_PASSWORD='密码'
- 需要进行数据卷的映射。
这里需要映射三处,如下:
-v 主机目录:/var/log/mysql
-v 主机目录:/var/lib/mysql
-v 主机目录: /etc/mysql/conf.d
- 需要改配置文件,解决中文乱码问题。
在conf文件夹下创建my.cnf,并添加如下内容
[client]
default_character_set=utf8
[mysqlId]
collation_server = utf8_general_ci
character_set_server = utf8
使用如下:
docker run -d -p 3306:3306 -e MYSQL_ROOT_PASSWORD=111111
-v /home/gtl/docker_data/mysql/data:/var/lib/mysql
-v /home/gtl/docker_data/mysql/log:/var/log/mysql
-v /home/gtl/docker_data/mysql/conf:/etc/mysql/conf.d --name mysql mysql
redis
- 添加redis配置文件 需要在容器的/etc/redis/目录下添加redis.conf文件,我们可以通过数据卷映射该目录。
使用如下:
docker run -d -p 6379:6379 --name redis
-v /home/gtl/docker_data/redis/redis.conf:/etc/redis/redis.conf
-v /home/gtl/docker_data/redis/data:/data redis redis-server /etc/redis/redis.conf
mysql主从复制
- 启动两个docker 的mysql容器,分别代表主服务器和从服务器,两个容器要有各自的数据卷映射。
docker run -d -p 3307:3306 -e MYSQL_ROOT_PASSWORD=111111
-v /home/gtl/docker_data/mysql/mysql_master/data:/var/lib/mysql
-v /home/gtl/docker_data/mysql/mysql_master/log:/var/log/mysql
-v /home/gtl/docker_data/mysql/mysql_master/conf:/etc/mysql/conf.d --name mysql_master mysql
docker run -d -p 3308:3306 -e MYSQL_ROOT_PASSWORD=111111
-v /home/gtl/docker_data/mysql/mysql_slave/data:/var/lib/mysql
-v /home/gtl/docker_data/mysql/mysql_slave/log:/var/log/mysql
-v /home/gtl/docker_data/mysql/mysql_slave/conf:/etc/mysql/conf.d --name mysql_slave mysql
2 .为master容器添加配置文件。
在conf目录下添加 my.cnf
[mysqld]
## 设置server_id,同一局域网中需要唯一
server_id=101
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能
log-bin=mysql-test-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
- 重启master容器,并且在容器实例中创建数据同步用户并授予权限。
create user 'slave'@'%' identified with mysql_native_password by '111111';
grant replication slave ,replication client on *.* TO 'slave'@'%';
- 为slave容器添加配置文件。
在conf目录下添加my.cnf配置文件
[mysqld]
## 设置server_id,同一局域网中需要唯一
server_id=102
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能,以备Slave作为其它数据库实例的Master时使用
log-bin=mall-mysql-slave1-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=mixed
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
## relay_log配置中继日志
relay_log=mall-mysql-relay-bin
## log_slave_updates表示slave将复制事件写进自己的二进制日志
log_slave_updates=1
## slave设置为只读(具有super权限的用户除外)
read_only=1
5.启动slave容器,根据master容器状态(show master status)来配置slave,如下:
change master to
master_host='222.24.34.220',
master_user='slave2',
master_password='111111',
master_port=3307,
master_log_file='mysql-bin.000003',
master_log_pos=1239,
master_connect_retry=30;
参数说明
master_host:主数据库的IP地址;
master_port:主数据库的运行端口;
master_user:在主数据库创建的用于同步数据的用户账号;
master_password:在主数据库创建的用于同步数据的用户密码;
master_log_file:指定从数据库要复制数据的日志文件,通过查看主数据的状态,获取File参数;
master_log_pos:指定从数据库从哪个位置开始复制数据,通过查看主数据的状态,获取Position参数;
master_connect_retry:连接失败重试的时间间隔,单位为秒。
- 启动slave,
start slave。查看运行slave状态,show slave status,下面是开启成功。
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
遇到的坑
- 配置文件名叫my.cnf,最开始写成了my.conf`
- 从机报错2061。因为mysql8.0使用了
caching_sha2_password加密算法,该加密算法是非对称加密。我们在master创建复制用户时,默认采用的就是这种加密算法,从机在请求连接时,发现对方采用的是该种加密算法,但是自己有不知道对方公钥,所以就会报错,这里的解决办法是创建用户时放弃使用非对称加密算法,但这并不是最优解决办法。
可以参考文章:主从复制报错2061
redis集群配置(六个redis节点)
- 启动六个redis容器
docker run -d --name redis-node-1 --net host -v /home/gtl/docker_data/redis/redis-node-1:/data redis --cluster-enabled yes --appendonly yes --port 6380
docker run -d --name redis-node-2 --net host -v /home/gtl/docker_data/redis/redis-node-2:/data redis --cluster-enabled yes --appendonly yes --port 6379
docker run -d --name redis-node-3 --net host -v /home/gtl/docker_data/redis/redis-node-3:/data redis --cluster-enabled yes --appendonly yes --port 6381
docker run -d --name redis-node-4 --net host -v /home/gtl/docker_data/redis/redis-node-4:/data redis --cluster-enabled yes --appendonly yes --port 6382
docker run -d --name redis-node-5 --net host -v /home/gtl/docker_data/redis/redis-node-5:/data redis --cluster-enabled yes --appendonly yes --port 6383
docker run -d --name redis-node-6 --net host -v /home/gtl/docker_data/redis/redis-node-6:/data redis --cluster-enabled yes --appendonly yes --port 6384
- 进入一个redis容器,配置主从关系。
redis-cli --cluster create 127.0.0.1:6379 127.0.0.1:6381
127.0.0.1:6382 127.0.0.1:6383 127.0.0.1:6384 192.168.179.139:6380 --cluster-replicas 1
此时就已经配置好了三主三从的redis集群。
- 查看集群状态
集群环境下,我们可以在任何容器下进入任意一个redis,redis-cli -c -p 6381这里我们从6381端口进入,-c表示以集群方式进入。
查看集群状态
cluster info
cluster nodes
redis-cli --cluster check 127.0.0.1:6379 # 查看的信息最具体
-
set 和key的使用
在集群环境下,当我们使用set命令时,会自动进行hash,匹配到相应哈希槽对应的redis节点,get也同样如此。 -
主从容错
当我们将一个主节点容器stop后,它的从节点会自动晋升为主节点。如果主节点和从节点都被stop后,集群状态就转为fail。
当我们重启被stop的节点后,集群又能自动恢复。
6.集群扩容
启动新的节点容器,执行下面命令将新节点加入集群
redis-cli --cluster add-node 新节点ip 集群任意节点ip
此时新加入的节点是没有槽位的,执行下面命令重新分配槽位
redis-cli --cluster reshard 集群ip
执行该命令分别要进行三次输入:
要分配的槽位数,槽位要分配给哪个节点,这些被分配的节点来自于哪些节点
在重新分配节点时并不是全盘重洗,而是按需重洗。
dockerFile
Dockerfile是用来构建Docker镜像文件的文本文件,是一条条构建镜像所需的指令和参数构成的脚本。
Docker常用命令
常见命令参考菜鸟Dockerfile
下面是使用dockerfile构建golang语言环境的Dockerfile文件
#基础镜像
FROM ubuntu
#作者
MAINTAINER gtl<[email protected]>
ENV MYPATH /home/gtl
#进入容器的默认所在目录
WORKDIR $MYPATH
#叠加镜像,安装所需软件
RUN apt-get update --fix-missing && apt-get install -y vim --fix-missing && apt-get install -y net-tools --fix-missing
#将主机目录下的go压缩包解压到容器目录中
ADD go1.20.3.linux-amd64.tar.gz /usr/local/
#配置go环境
ENV PATH /usr/local/go/bin:$PATH
ENV GOROOT /usr/local/go
ENV GOPATH $MYPATH/go
ENV GOPROXY goproxy.cn
EXPOSE 80
CMD echo $MYPATH
CMD echo "success"
构建命令
docker build -t Name:tag .
构建命令最后有一个点,表示需要打包的上下文路径,docker是cs架构,在构建镜像时会将需要的文件打包发送给docker引擎。上面的Dockerfile文件中需要使用go1.20.3.linux-amd64.tar.gz ,该文件要放到与Dockerfile同一文件夹下。
Docker 网络
docker有三种网络模式,如上图,除此之外还有可以使用其它容器的网络模式,被称为container模式
bridge — 网桥模式
在下载Docker之后会为主机分配一个默认的虚拟网桥Docker0,在该主机上使用该网络(默认)启动docker容器时,Docker0就会为它专门分配一个子网IP,容器也会将Docker0当作默认网关。
启动一个容器后,该容器的ip如下:

Docker 将 veth pair 设备的一端放在新创建的容器中,并命名为eth0(容器的网卡),另一端放在主机中,以vethxxx这样类似的名字命名,并将这个网络设备加入到 docker0 网桥中。可以通过brctl show命令查看。

使用bridge模式的容器(也时默认使用的模式),主机上的不同容器可以借助网桥相互连接,同样也可以借助网桥访问互联网。
我认为这里的网桥类似于一个NAT路由器,为子网内的ip分配一个私有IP,子网内的主机可以互相连接,同样也可以借助路由器访问互联网,但是互联网无法直接访问子网内主机。
在使用默认的网桥模式时,不同容器之间需要通过IP才能互相连接,但是如果使用自定义的网桥模式,可以直接通过容器名连接。
创建网络:docker network create -d bridge my-net -d 表示指定网络模式
指定网络创建容器docker run -it --network my-net images
Host模式
如果启动容器的时候使用host模式,那么这个容器将不会获得一个独立的Network Namespace,而是和宿主机共用一个 Network Namespace。容器将不会虚拟出自己的网卡,配置自己的 IP 等,而是使用宿主机的 IP 和端口。但是,容器的其他方面,如文件系统、进程列表等还是和宿主机隔离的。
None模式
使用none模式,Docker 容器拥有自己的 Network Namespace,但是,并不为Docker 容器进行任何网络配置。也就是说,这个 Docker 容器没有网卡、IP、路由等信息。需要我们自己为 Docker 容器添加网卡、配置 IP 等。
Container模式
这个模式指定新创建的容器和已经存在的一个容器共享一个 Network Namespace,而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的 IP,而是和一个指定的容器共享 IP、端口范围等。同样,两个容器除了网络方面,其他的如文件系统、进程列表等还是隔离的。两个容器的进程可以通过 lo 网卡设备通信。 如果被共享的容器被stop,他就会转为None模式。