即席查询-Kylin
什么是即席查询?
即席查询(Ad Hoc Queries),是用户根据自己的需求,灵活的选择查询条件,系统能根据用户的选择生成对应的统计报表。即席查询与普通应用查询的最大不同在于即席查询的 SQL 是灵活的、不确定的、短暂的。
什么是灵活的、不确定的、短暂的?
我们在日常的数仓建模中,通常都会生成很多指标供用户决策,这些指标通常都是确定的、指标算法相对稳定、指标需要长期使用。但是通常用户还需要满足他的一些突发奇想的指标,这类指标通常是临时提出来的需求,指标也不会用很长时间。
数仓能否满足即席查询?
可以满足灵活的、不确定的、短暂的查询,但是不能满足即席查询,其实即席查询还隐含这一个重要的要求那就是响应时间,这类需求通常是用户临时提出来,想要在短时间内获取结果。因此数仓不太能够满足这类需求,需要一个全新的架构。
如何实现即席查询?
即席查询所面临的痛点就是响应时间,如何能让一个查询 SQL 在秒级,亚秒级响应?目前在提高响应时间上的优化成熟的方案有两个:基于内存(Presto)和预计算(Kylin)
一、概述
1.1 定义
Apache Kylin™ 是一个开源的、分布式的分析型数据仓库,提供 Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。它能在亚秒内查询巨大的表。也是第一个由国人开发并成功在 Apache 毕业的项目,因此它的官网有中文版。
Kylin 的使用者仅需三步,即可实现超大数据集上的亚秒级查询
- 定义数据集上的一个星形或雪花形模型
- 在定义的数据表上构建cube
- 使用标准 SQL 通过 ODBC、JDBC 或 RESTFUL API 进行查询,仅需亚秒级响应时间即可获得查询结果
1.2 架构
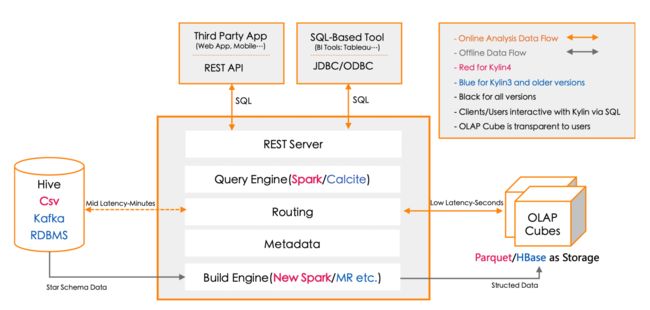
REST Server
REST Server 是一套面向应用程序开发的入口点,旨在实现针对 Kylin 平台的应用开发工作。 此类应用程序可以提供查询、获取结果、触发 cube 构建任务、获取元数据以及获取用户权限等等。另外可以通过 Restful 接口实现 SQL 查询。
Query Engine
当 cube 准备就绪后,查询引擎就能够获取并解析用户查询。它随后会与系统中的其它组件进行交互,从而向用户返回对应的结果。Kylin4 之后将使用 Spark 代替 Calcite
Rounting
在最初设计时曾考虑过将 Kylin 不能执行的查询引导去 Hive 中继续执行,但在实践后发现 Hive 与 Kylin 的速度差异过大,导致用户无法对查询的速度有一致的期望,很可能大多数查询几秒内就返回结果了,而有些查询则要等几分钟到几十分钟,因此体验非常糟糕。最后这个路由功能在发行版中默认关闭。
Metadata
Kylin 是一款元数据驱动型应用程序。元数据管理工具是一大关键性组件,用于对保存在 Kylin 当中的所有元数据进行管理,其中包括最为重要的 cube 元数据。其它全部组件的正常运作都需以元数据管理工具为基础。 Kylin4 的元数据存储在 mysql 中(之前存储在Hbase)。
Build Engine
这套引擎的设计目的在于处理所有离线任务,其中包括 shell 脚本、Java API 以及 MapReduce 任务等等。任务引擎对 Kylin 当中的全部任务加以管理与协调,从而确保每一项任务都能得到切实执行并解决其间出现的故障。Kylin4 将使用 Spark 作为唯一的的构建引擎,与之前的构建引擎相比:
- Kylin4 只需要嗅探资源和 cubing 两个步骤即可完成构建
- Kylin4 使用 parquet 存储数据,会对存储数据进行编码,Kylin4 不再需要纬度字典和对维度列编码的过程
- Kylin4 对全局字典做了全新的实现
- Kylin4 会根据集群资源、构建任务等情况自动对 spark 进行调参
- Kylin4 的构建速度将大幅提高
1.3 特点
- 可扩展超快的基于大数据的分析型数据仓库:Kylin 是为减少在 Hadoop/Spark 上百亿规模数据查询延迟而设计
- Hadoop ANSI SQL 接口:Kylin 为 Hadoop 提供标准 SQL,支持大部分查询功能
- 交互式查询能力:通过 Kylin,用户可以与 Hadoop 数据进行亚秒级交互,在同样的数据集上提供比 Hive 更好的性能
- Molap Cube:用户能够在 Kylin 里为百亿以上数据集定义数据模型并构建 Cube
- 实时 OLAP:Kylin 可以在数据产生时进行实时处理,用户可以在秒级延迟下进行实时数据的多位分析
- 与 BI 工具无缝整合:Kylin 提供与 BI 工具的整合能力,如Tableau,PowerBI/Excel,MSTR,QlikSense,Hue 和 SuperSet
1.4 cube
目前 OLAP 分析主要分为:ROLAP 和 MOLAP
| 架构 | 是否需要预计算 | |
|---|---|---|
| ROLAP | 基于关系型数据库 | 否 |
| MOLAP | 基于多维数据集 | 是 |
ROLAP 随着数据量的提升,关系型数据库的弊端将越来越明显,MOLAP 基于多维数据集目的是为了缓解 ROLAP 的性能问题,采用预聚合的思想其本质是:用空间换时间。一个多维数据集称为一个 Cube

如图是一个三维的 Cube,针对三维的 Cube 将会有 2^3 种可能的组合,每一个组合可以称为一个 Cuboid,Kylin 就是根据这个来预计算构建完整的 Cube,来满足之后可能的查询

二、环境搭建
Kylin 不同版本依赖的组建不同,如 Kylin4 之前需要 Hadoop、Zookeeper、Hbase、Hive等,且各个组件兼容性也是一个问题,Kylin4 剔除了 HBase,使用 Parquet 替换,同时 Parquet 与 Spark、Hive 有较好的兼容,减少对 HBase 的依赖将更好的上云,预计算的结果以 Parquet 形式存储在文件系统,为了更好的测试、调式这里使用 docker 部署一个测试环境。
docker 的基本使用见:https://kpretty.tech/archives/docker1
拉取官方镜像,该镜像中 Kylin 依赖的服务均以正确的安装即部署
docker pull apachekylin/apache-kylin-standalone:4.0.0
启动容器
docker run -d \
-m 8G \
-p 7070:7070 \
-p 8088:8088 \
-p 50070:50070 \
-p 8032:8032 \
-p 8042:8042 \
-p 2181:2181 \
--name kylin \
apachekylin/apache-kylin-standalone:4.0.0
会自动启动 Kylin 和所依赖的服务,并运行$KYLIN_HOME/bin/sample.sh生成测试数据
为了让 Kylin 能够顺畅的构建 Cube,Yarn NodeManager 配置的内存资源预分配为 6G,加上各服务占用的内存,请保证容器的内存不少于 8G,以免因为内存不足导致出错。
由于 docker 已经提前映射了所需要的端口,因此:
-
Kylin 页面:http://127.0.0.1:7070/kylin/login
-
HDFS NameNode 页面:http://127.0.0.1:50070
-
YARN ResourceManager 页面:http://127.0.0.1:8088
默认用户名密码:ADMIN/KYLIN

三、快速入门
3.1 准备数据
hive 中创建表
-- 部门表
create external table if not exists dept(
deptno int comment '部门id',
dname string comment '部门名称',
loc int comment '部门地区'
)
row format delimited fields terminated by '\t';
-- 员工表
create external table if not exists emp(
empno int comment '员工编号',
ename string comment '员工姓名',
job string comment '工作名称',
mgr int comment '主管编号',
hiredate string comment '出生年月',
sal double comment '薪水',
comm double comment '奖金',
deptno int comment '部门编号')
row format delimited fields terminated by '\t';
-- 部门表数据
10 ACCOUNTING 1700
20 RESEARCH 1800
30 SALES 1900
40 OPERATIONS 1700
-- 员工表数据
7369 SMITH CLERK 7902 1980-12-17 800.00 20
7499 ALLEN SALESMAN 7698 1981-2-20 1600.00 300.00 30
7521 WARD SALESMAN 7698 1981-2-22 1250.00 500.00 30
7566 JONES MANAGER 7839 1981-4-2 2975.00 20
7654 MARTIN SALESMAN 7698 1981-9-28 1250.00 1400.00 30
7698 BLAKE MANAGER 7839 1981-5-1 2850.00 30
7782 CLARK MANAGER 7839 1981-6-9 2450.00 10
7788 SCOTT ANALYST 7566 1987-4-19 3000.00 20
7839 KING PRESIDENT 1981-11-17 5000.00 10
7844 TURNER SALESMAN 7698 1981-9-8 1500.00 0.00 30
7876 ADAMS CLERK 7788 1987-5-23 1100.00 20
7900 JAMES CLERK 7698 1981-12-3 950.00 30
7902 FORD ANALYST 7566 1981-12-3 3000.00 20
7934 MILLER CLERK 7782 1982-1-23 1300.00 10
3.2 创建项目
登录系统后默认有一个 learn_kylin 项目和两个定义好的 cube(如果是 docker 部署的话),我们新建一个自己的项目

创建一个项目

选择数据源
加载数据源提供三种方式:根据表名、元数据信息、CSV,通常选择第二个
加载数据表

被选中的表会有加粗显示,选择 dept、emp 表后点击 sync,此时数据准备工作就完成了,下面开始创建 Model
3.3 创建 Model
创建 Cube 前,需要定义一个数据模型,数据模型定义了一个星型(star schema)或雪花(snowflake schema)模型。一个模型可以被多个 cube 使用。

定义模型基本信息

选择事实表

选择维度表

选择对应的维度表,并执行与维度表的 join 方式和 join 字段,点击 OK,点击 Next
选择纬度值

纬度值根据业务需求,最终体现在 group by 后
选择度量值

度量值即最终的统计字段,体现在聚合函数中
选择分区字段和过滤信息

这部分不是必须的,分区字段的意义在于构建 cube 时需要给一个时间范围,若没有则每次构建都是全量的(视具体业务和数据来定,这里不选),点击 save 保存。至此 Model 就创建完成了
3.4 创建 Cube
相同的位置选择 New Cube
定义 Cube 基本信息
主要选择基于的 Model 是什么,构建结果的通知可以不选
选择 Cube 维度信息

这里的纬度是真正影响 Cube 的维度,决定最终生成的 Cuboid 的个数,且只能从 Model 中选择,因此 Model 的构建需要考虑适用更多的多维分析场景;维度表中的维度选择 Normal,Derived 派生维度后面再说,

定义 Cube 度量值

可以点击 Bulk Add Measure 批量添加预定的聚合方式如 SUM、MAX、MIN

也可以点击 +Measure 选择更多类型的聚合方式

设置刷新时间(默认)
高级设置

暂时不要动,只需要选择构建引擎即可,Kylin4 只能选择 spark(主要是高级设置我也没有摸的太清楚)
覆盖默认配置

这里可以修改 Kylin 的默认配置,如指定构建算法等
构建完成

点击 cube 可以看到一些基本信息,如:生成的SQL,还有超好看的玫瑰图执行计划 Planner

3.5 构建 Cube
点击 Build 触发计算
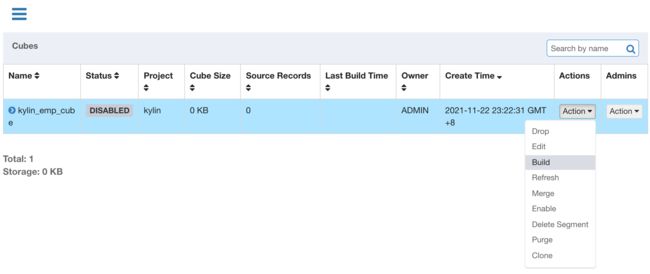
点击 Monitor,查看构建进度
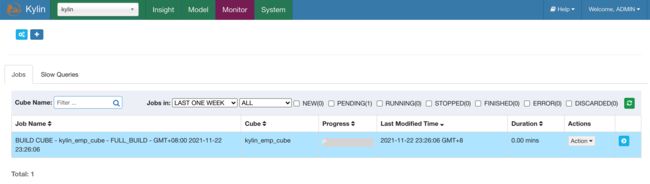
Kylin4 的构建步骤只有两步,资源嗅探和执行任务,相较于之前版本步骤大大减少
执行查询,第一次查询需要加载一段时间,之后查询都是亚秒级响应,超快的执行速度
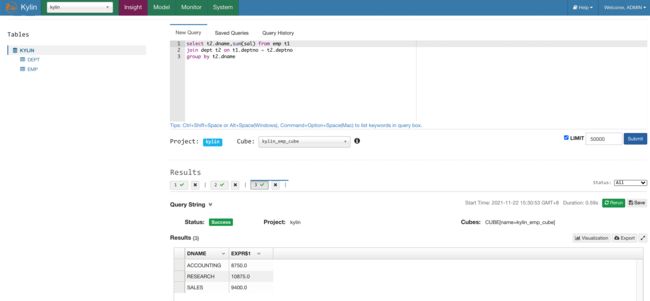
相同 sql 对比 hive 的执行速度
select t2.dname,sum(sal) from emp t1
join dept t2 on t1.deptno = t2.deptno
group by t2.dname;

这速度对比…
3.6 自动构建
目前我们构建是通过 Web 页面点击 build 触发构建计算,但 hive 的数据是每天新增,因此 cube 也需要每日的构建,且构建时间通常很久且在半夜,因此 cube 的构建需要自动化、定时
Kylin 提供 Restful API 来完成自动的 cube 构建
认证
python -c "import base64; print base64.standard_b64encode('$UserName:$Password')"
## 例如
python -c "import base64; print base64.standard_b64encode('ADMIN:KYLIN')"
QURNSU46S1lMSU4=
自动构建
curl -X PUT -H "Authorization: Basic XXXXXXXXX" -H 'Content-Type: application/json' -d '{"startTime":'1423526400000', "endTime":'1423612800000', "buildType":"BUILD"}' http://<host>:<port>/kylin/api/cubes/{cubeName}/build
- Authorization: Basic XXXXXXXXX:指定认证的字段
- -d 指定构建的参数,如开始时间,结束时间,构建类型
例如自动构建 kylin_emp_cube
curl -X PUT -H "Authorization: Basic QURNSU46S1lMSU4=" -H 'Content-Type: application/json' -d '{"startTime":'1423526400000', "endTime":'1423612800000', "buildType":"BUILD"}' http://127.0.0.1:7070/kylin/api/cubes/kylin_emp_cube/build
开始时间结束时间即使没有也可以指定

uuid用于追踪任务的唯一id,此时可以看到 Web 页面得 Monitor 已经启动了构建任务

因此我们只需要将上述的 shell 命令封装成脚本交由任务调度工具即可
#!/bin/bash
#从第 1 个参数获取 cube_name
cube_name=$1 #从第 2 个参数获取构建 cube 时间
if [ -n "$2" ]
then
do_date=$2
else
do_date=`date -d '-1 day' +%F`
fi
#获取执行时间的 00:00:00 时间戳(0 时区)
start_date_unix=`date -d "$do_date 08:00:00" +%s`
#秒级时间戳变毫秒级
start_date=$(($start_date_unix*1000))
#获取执行时间的 24:00 的时间戳
stop_date=$(($start_date+86400000))
curl -X PUT -H "Authorization: Basic QURNSU46S1lMSU4=" -H 'Content-Type:application/json' -d '{"startTime":'$start_date', "endTime":'$stop_date',"buildType":"BUILD"}' http://localhost:7070/kylin/api/cubes/$cube_name/build
四、注意事项
Kylin 在查询中需要注意很多东西,同时也很重要,所以另起一个章节来说
4.1 保持 Model 的关联方式
上面我们在构建 Model 时指定的事实表为维度表的连接方式是 inner join,因此在执行查询时也必须使用 inner join,Kylin4 之前会报错,当前版本什么都查询不到

4.2 保证事实表维度表顺序
Kylin 要求查询时事实表在前,维度表在后,否则什么都查询不到

4.3 保证聚合维度的正确性
Kylin 要求查询的 group by 字段必须是构建 cube 选择的维度字段,否则什么都查询到
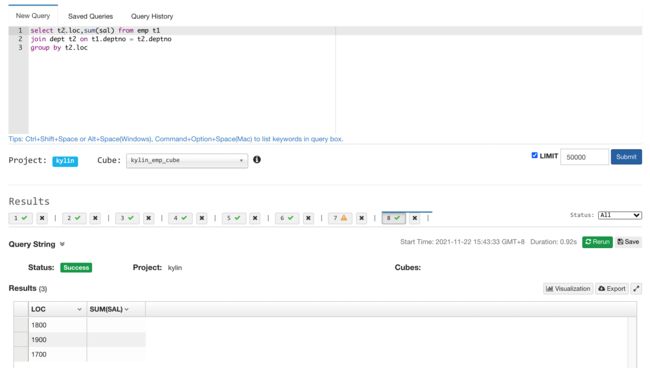
4.4 保证度量值的正确性
Kylin 要求查询时聚合的度量值必须是构建 cube 选择的度量值字段,否则什么都查询不到

五、构建原理
5.1 逐层构建(By-layer)
我们知道,一个 N 维的 Cube,是由 1 个 N 维子立方体、N 个 (N-1) 维子立方体、N*(N-1)/2 个(N-2) 维子立方体、…、N 个 1 维子立方体和 1 个 0 维子立方体构成,总共有 2^N 个子立方体组成,在逐层算法中,按维度数逐层减少来计算,每个层级的计算(除了第一层,它是从原始数据聚合而来),是基于它上一层级的结果来计算的。比如,[Group by A, B]的结果,可以基于[Group by A, B, C]的结果,通过去掉 C 后聚合得来的;这样可以减少重复计算;当 0 维度 Cuboid 计算出来的时候,整个 Cube 的计算也就完成了。
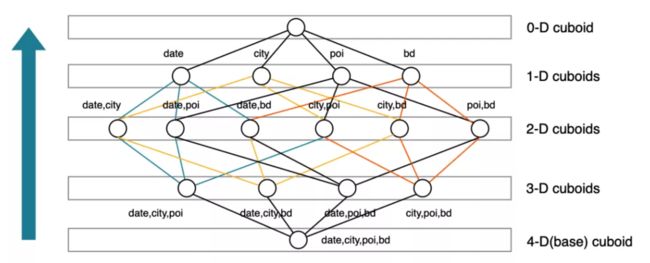
Kylin4 在构建过程中去掉了纬度字典的编码,省去了编码的一个构建步骤,同时去掉 HFile 的生成,所有的构建步骤都是在 Spark 中进行的。
5.2 快速构建(inmem)
也被称作“逐段”(By Segment) 或“逐块”(By Split) 算法,从 1.5.x 开始引入该算法,该算法的主要思想是,每个 Mapper 将其所分配到的数据块,计算成一个完整的小 Cube 段(包含所有Cuboid)。每个 Mapper 将计算完的 Cube 段输出给 Reducer 做合并,生成大 Cube,也就是最终结果;其本质是在内存中进行预聚合。
构建引擎的配置参数为,默认 auto,Kylin 根据具体情况选择对应的构建算法
# auto、layer、inmem
kylin.cube.algorithm=inmem
六、深入探究
Kylin4 的元数据默认存储在 MySQL 中,基于 docker 的部署方式查看 kylin.properties
kylin.env=QA
kylin.server.mode=all
kylin.server.host-address=127.0.0.1:7070
server.port=7070
# Display timezone on UI,format like[GMT+N or GMT-N]
kylin.web.timezone=GMT+8
kylin.source.hive.client=cli
kylin.source.hive.database-for-flat-table=kylin4
kylin.engine.spark-conf.spark.eventLog.enabled=true
kylin.engine.spark-conf.spark.history.fs.logDirectory=hdfs://localhost:9000/kylin4/spark-history
kylin.engine.spark-conf.spark.eventLog.dir=hdfs://localhost:9000/kylin4/spark-history
kylin.engine.spark-conf.spark.hadoop.yarn.timeline-service.enabled=false
kylin.engine.spark-conf.spark.yarn.submit.file.replication=1
kylin.engine.spark-conf.spark.master=yarn
kylin.engine.spark-conf.spark.driver.memory=512M
kylin.engine.spark-conf.spark.driver.memoryOverhead=512M
kylin.engine.spark-conf.spark.executor.memory=1G
kylin.engine.spark-conf.spark.executor.instances=1
kylin.engine.spark-conf.spark.executor.memoryOverhead=512M
kylin.engine.spark-conf.spark.executor.cores=1
kylin.engine.spark-conf.spark.sql.shuffle.partitions=1
kylin.engine.spark-conf.spark.yarn.jars=hdfs://localhost:9000/spark2_jars/*
kylin.storage.columnar.shard-rowcount=2500000
kylin.storage.columnar.shard-countdistinct-rowcount=1000000
kylin.storage.columnar.repartition-threshold-size-mb=128
kylin.storage.columnar.shard-size-mb=128
kylin.query.auto-sparder-context-enabled=true
kylin.query.sparder-context.app-name=sparder_on_docker
kylin.query.spark-conf.spark.master=yarn
kylin.query.spark-conf.spark.driver.memory=512M
kylin.query.spark-conf.spark.driver.memoryOverhead=512M
kylin.query.spark-conf.spark.executor.memory=1G
kylin.query.spark-conf.spark.executor.instances=1
kylin.query.spark-conf.spark.executor.memoryOverhead=512M
kylin.query.spark-conf.spark.executor.cores=1
kylin.query.spark-conf.spark.serializer=org.apache.spark.serializer.JavaSerializer
kylin.query.spark-conf.spark.sql.shuffle.partitions=1
kylin.query.spark-conf.spark.yarn.jars=hdfs://localhost:9000/spark2_jars/*
kylin.query.spark-conf.spark.eventLog.enabled=true
kylin.query.spark-conf.spark.history.fs.logDirectory=hdfs://localhost:9000/kylin4/spark-history
kylin.query.spark-conf.spark.eventLog.dir=hdfs://localhost:9000/kylin4/spark-history
# for local cache
kylin.query.cache-enabled=false
# for pushdown query
kylin.query.pushdown.update-enabled=false
kylin.query.pushdown.enabled=true
kylin.query.pushdown.runner-class-name=org.apache.kylin.query.pushdown.PushDownRunnerSparkImpl
# for Cube Planner
kylin.cube.cubeplanner.enabled=true
kylin.server.query-metrics2-enabled=false
kylin.metrics.reporter-query-enabled=false
kylin.metrics.reporter-job-enabled=false
kylin.metrics.monitor-enabled=false
kylin.web.dashboard-enabled=false
# metadata for mysql
kylin.metadata.url=kylin4@jdbc,url=jdbc:mysql://localhost:3306/kylin4,username=root,password=123456,maxActive=10,maxIdle=10
kylin.env.hdfs-working-dir=/kylin4_metadata
kylin.env.zookeeper-base-path=/kylin4
kylin.env.zookeeper-connect-string=127.0.0.1
kylin.storage.clean-after-delete-operation=true
可以看到 Kylin 的元数据和基于 Parquet 存储的预计算文件
6.1 元数据
结合配置文件,Kylin 的元数据存储在 kylin4.kylin4 表中,数据太多就不在展示了,其表结构如下:
mysql> desc kylin4.kylin4;
+--------------------+--------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+--------------------+--------------+------+-----+---------+-------+
| META_TABLE_KEY | varchar(255) | NO | PRI | NULL | |
| META_TABLE_TS | bigint(20) | YES | MUL | NULL | |
| META_TABLE_CONTENT | longblob | YES | | NULL | |
+--------------------+--------------+------+-----+---------+-------+
META_TABLE_KEY 大致存储了 acl、cube、execute、kafka、model、project、table、user信息,以/开头,例如我有一个 kylin_emp_cube,因此查询它的元数据信息 sql 如下:
select META_TABLE_CONTENT from kylin4.kylin4 where META_TABLE_KEY = '/cube/kylin_emp_cube.json';
其结果是一个 json
{
"uuid": "fcf56290-72d9-34f2-b18a-2645fa8b48fd",
"last_modified": 1637600267652,
"version": "4.0.0.0",
"name": "kylin_emp_cube",
"owner": "ADMIN",
"descriptor": "kylin_emp_cube",
"display_name": "kylin_emp_cube",
"cost": 50,
"status": "READY",
"segments": [
{
"uuid": "7a88b61f-9778-ca64-4b97-789c06de56fe",
"name": "FULL_BUILD",
"storage_location_identifier": "KTH",
"date_range_start": 0,
"date_range_end": 9223372036854775807,
"source_offset_start": 0,
"source_offset_end": 0,
"status": "READY",
"size_kb": 22,
"is_merged": false,
"estimate_ratio": null,
"input_records": 14,
"input_records_size": 726,
"last_build_time": 1637597110112,
"last_build_job_id": "6eaccbf3-44b2-4e9e-a18a-c8cee4089da2",
"create_time_utc": 1637596985285,
"cuboid_shard_nums": {
"1": 1,
"2": 1,
"3": 1,
"4": 1,
"5": 1,
"6": 1,
"7": 1,
"8": 1,
"9": 1,
"10": 1,
"11": 1,
"12": 1,
"13": 1,
"14": 1,
"15": 1
},
"total_shards": 0,
"blackout_cuboids": [],
"binary_signature": null,
"dictionaries": null,
"snapshots": {
"KYLIN.DEPT": "kylin/table_snapshot/KYLIN.DEPT/42b8a8bf-9d86-46a3-a772-fc2e2a7f5df7"
},
"rowkey_stats": [],
"stream_source_checkpoint": null,
"additionalInfo": {
"storageType": "4"
}
}
],
"create_time_utc": 1637594551123,
"cuboid_bytes": null,
"cuboid_bytes_recommend": null,
"cuboid_last_optimized": 0,
"snapshots": {}
}
主要关注 cuboid_shard_nums 的 cuboid 信息,15个代表着 3 个维度的组合,以及 KYLIN.DEPT 记录 cube 快照的存储位置。更加详细的元数据可以自己研究研究
6.2 预处理文件
kylin.env.hdfs-working-dir=/kylin4_metadata
改配置指定 kylin 在 hdfs 的工作路径,包括其预处理文件,找到对应的预处理文件存放地

每个 cuboid 一个文件夹,随便点进去一个 cuboid

其文件是 Snappy 压缩的 Parquet 文件,教你如何查看这个文件!!!哪个框架对 Parquet 文件支持的非常好?答案是:spark
scala> import spark.implicits._
import spark.implicits._
scala> val source = spark.read.parquet("hdfs://localhost:9000//kylin4_metadata/kylin4/kylin/parquet/kylin_emp_cube/FULL_BUILD_KTH/1/part-00000-a7aa4850-6c2d-4733-8dba-7a2346b9a828-c000.snappy.parquet")
source: org.apache.spark.sql.DataFrame = [0: string, 6: bigint ... 2 more fields]
scala> source.show()
+----------+---+-------+------+
| 0| 6| 7| 8|
+----------+---+-------+------+
|ACCOUNTING| 3| 8750.0|5000.0|
| RESEARCH| 5|10875.0|3000.0|
| SALES| 6| 9400.0|2850.0|
+----------+---+-------+------+
博主也没有在生产中用过 Kylin,该文章皆为博主学习过程中的总结,欢迎一起探讨
更多关于 Kylin 的资料:https://kylin.apache.org/cn/blog