注意力机制(二)
上两篇文章中,我们介绍了循环神经网络经典的应用结构自编码模型,以及其应对长序列问题的改进模型——带注意力机制的自编码模型。其本质都是通过一个Encoder和一个Decoder实现机器翻译、文本转换、机器问答等功能。

传送门:序列处理之RNN模型、注意力机制(一)
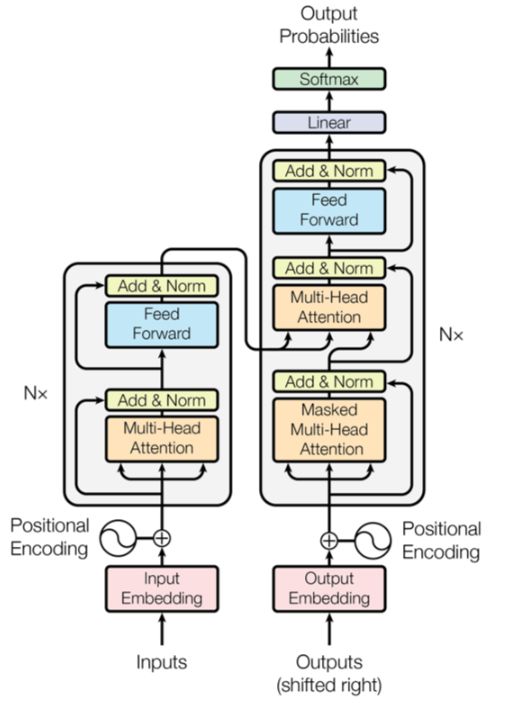
里面的网络结构通常是循环网络或卷积网络。今天我们学习另外一种网络结构,用6个结构相同的Encoder串联构成编码层,用6个结构相同的Decoder串联构成解码层,这种自编码模型称为Transformer.
![]()

Transformer架构
![]()
Transformer的架构一般如下图所示:

这里,最后一层Encoder的输出将传入Decoder的每一层。其中,每个编码器由一层自注意力和一层前馈网络构成,每一个解码器中间还多一个用来接收最后一个编码器的输出值的自编码层:

![]()

Transformer特点
![]()
上面是Transformer的主要架构,下面我们深入剖析其细节。我们知道,对于语言翻译类问题,单词的次序是一个非常重要的因素,RNN本身就考虑了单词次序位置关系,所以Transformer也要考虑这个问题。
实际上,Transformer使用位置编码(Position Encoding)来记录单词在语句中的位置或次序,位置编码取值遵循一定的规则生成,每个单词的词嵌入与对应位置编码相加(位置编码向量与词嵌入维度相同)得到最终的词嵌入(称为带有时间信息的嵌入):

对解码器的输入(目标数据)也做同样的处理。这里存在一个问题,即对语料库进行批量处理时,可能会遇到长度不一致的语句,可以做下面处理:对于短语句可用填充方式补齐;对于长语句可用截尾方法对齐(负值很大负数,进行softmax运算时变为0)
Transformer是一种自注意力机制,这与一般的注意力机制的区别点在于Query的来源不同。一般的注意力机制的query来源于目标语句(非源语句),而自注意力机制的query来源于语句本身(非目标语句)。自注意力机制的计算步骤主要如下:
1)把输入单词转换为带时间(时序)信息的嵌入向量
2)根据嵌入向量生成q、k、v三个向量,分别代表query、key、value
3)根据q,计算每个单词点积后得分:score=q•k
4)对score进行规范化处理,softmax后结果为a
5)a与对应v相乘,然后累加得到当前语句各单词之间的自注意力z=∑av
![]()

缩放点积注意力
![]()
Transformer的核心内容就是这五个计算步骤。为了加深理解,我们通过一个例子加以可视化展示。
假设要翻译的语句为:Thinking Machines。单词Thinking预处理(带有时序的词嵌入)后用向量x1表示,单词Machines预处理后用x2表示。计算单词Thinking与当前语句各单词的注意力得分(Score):

同样的方式可以计算单词Machines与当前语句各单词的注意力得分,这里不再展示了。然后对score得分进行规范化处理,考虑到实际计算中score得分可能较大,为保证计算梯度时不影响稳定性,一般进行归一化操作后再进行softmax处理,这里,score得分除以k向量维度的算术平方根:

这里需要解释一下,一般词嵌入的维度比较大(比如512),且与q、k、v维度满足以下关系:

这样就可以得到单词Thinking对当前语句各单词的注意力z。
可以看到,计算注意力都是基于向量的运算,如果把向量堆砌成矩阵,则可以进行矩阵运算得到Q、K、V:

其中,W的三个矩阵为可学习矩阵,与神经网络的权重矩阵类似。在此基础上,注意力计算过程可以表示为下面可视化过程:

这个计算注意力z的过程又称为缩放点积注意力(Scaled Dot-Product Attetion).
上图中,MatMul表示点击运算,Mask表示掩码,用于遮掩某些值使其在参数更新时不产生效果。Transformer模型涉及两张掩码方式——Padding Mask(填充掩码)和Sequence Mask(序列掩码),而后者只会用在Decoder的自注意力中,用于防止Decoder预测目标值时看到未来的值。
![]()

Transformer全流程
![]()
我们知道,Transformer的Encoder和Decoder组件分别有6层,随着网络层数的增加,表达能力也越强,但也会出现收敛速度慢、易出现梯度消失等问题。为此,Transformer采用两种方法克服这种缺陷——残差连接(Residual Connection)和归一化(Normalization),具体方法是在每个编码器或解码器的两个子层(Self-Attention和FFNN,前馈神经网络)间增加由残差连接和归一化组成的层:

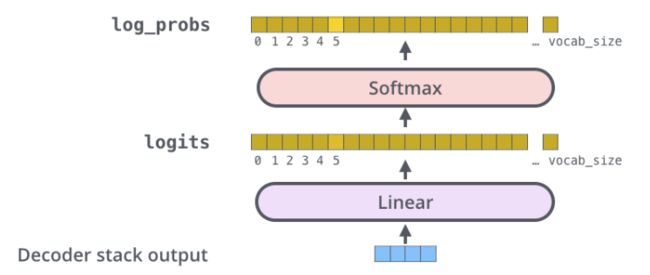
Decoder做一样的处理,特别之处是在最后的输出通过一个全连接层及Softmax函数作用后得到预测值的对数概率:

假设这里采取贪婪解码方法,用argmax函数获取概率最大值对应的索引:
![]()

多头注意力机制
![]()
类似多核卷积神经网络,自注意力采取多个组合(多个Wq,Wk,Wv矩阵),就形成了多头注意力机制(Multi-Head Attention)。它可以从3个方面提升注意力层的性能:
1)扩展模型专注于不同位置的能力
2)将缩放点注意力过程做h次,再把输出合并起来
3)为注意力层(Attention Layer)提供多个”表示子空间“
结合上面的内容,我们得到了一个完整的Transformer架构图:
参考资料:《深入浅出Embedding》