【搭建神经网络模型的组成步骤】
【搭建一个神经网络模型的基本步骤】
1、导入基本库 2、导入数据集和参数设置 3、定义网络模型 4、展示网络结构并测试模型 5、模型训练与保存 6、绘制训练曲线
还有如模型加载、重训练、演示等。
1、导入基本库
如:
import os
import datetime
import torch
import torchvision
from torch import nn
import torch.nn.functional as F
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.utils import save_image
from torchvision.datasets import MNIST
2、导入数据集和参数设置
如:
size = 28
n_class = 10
num_epochs = 10
batch_size = 100
learning_rate = 1e-3
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
dataset = MNIST('data', transform = transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size = batch_size, shuffle = True)
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize(0.5,0.5)]) # Normalize对每个通道执行以下操作:image =(图像-平均值)/ std,参数mean,std分别以0.5和0.5的形式传递。这将使图像在[-1,1]范围内归一化
data2 = MNIST(root='data', train = True, transform = transform)
dataloader2 = DataLoader(dataset=data2, shuffle=True, batch_size=batch_size)
3、定义网络模型
如:
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(1,16,3,stride=3,padding=1), # b, 16, 10, 10, N=[(input_size-kernel_size+2*padding)/stride]+1,(向下取整)
nn.ReLU(inplace=True), # 产生的计算结果不会有影响。利用in-place计算可以节省内(显)存,同时还可以省去反复申请和释放内存的时间。但是会对原变量覆盖,只要不带来错误就用。
nn.MaxPool2d(2, stride=2), # b,16, 5, 5,N = [(input_size-kernel_size)/stride]+1,(向下取整)
nn.Conv2d(16, 8, 3, stride=2, padding=1), # b,8,3,3
nn.ReLU(inplace=True),
nn.MaxPool2d(2, stride=1) # b,8,2,2
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(8, 16, 3,stride=2), # b, 16, 5, 5 ,按住ctrl,鼠标点击ConvTranspose2d可查看形状计算公式
nn.ReLU(inplace=True),
nn.ConvTranspose2d(16, 8, 5,stride=3, padding=1), # b, 8, 15, 15
nn.ReLU(inplace=True),
nn.ConvTranspose2d(8, 1, 2,stride=2, padding=1), # b, 1, 28, 28
nn.Tanh()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
4、展示网络结构并测试模型
如:
# 测试模型
from torchsummary import summary
model = AutoEncoder().to(device)
summary(model, (1,28,28))
x = torch.randn(1,1,28,28).to(device)
out = model(x)
# out=out.cpu().numpy() # RuntimeError:不能在需要grad的张量上调用numpy()。请改用tensor.detach().numpy()
# out=out.detach().numpy() #不能将cuda:0设备类型张量转换为numpy。首先使用tensor.cpu()将张量复制到主机内存中。
out = out.detach().cpu().numpy() # 正确,分离出来,不带梯度,传到cpu上再调用numpy()
print(out, out.shape)
输出如下:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 16, 10, 10] 160
ReLU-2 [-1, 16, 10, 10] 0
MaxPool2d-3 [-1, 16, 5, 5] 0
Conv2d-4 [-1, 8, 3, 3] 1,160
ReLU-5 [-1, 8, 3, 3] 0
MaxPool2d-6 [-1, 8, 2, 2] 0
ConvTranspose2d-7 [-1, 16, 5, 5] 1,168
ReLU-8 [-1, 16, 5, 5] 0
ConvTranspose2d-9 [-1, 8, 15, 15] 3,208
ReLU-10 [-1, 8, 15, 15] 0
ConvTranspose2d-11 [-1, 1, 28, 28] 33
Tanh-12 [-1, 1, 28, 28] 0
================================================================
Total params: 5,729
Trainable params: 5,729
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.07
Params size (MB): 0.02
Estimated Total Size (MB): 0.10
----------------------------------------------------------------
...
-2.80570798e-03 1.85966939e-02 -1.62758911e-03 2.46294308e-02
-6.62874314e-04 1.42125208e-02 -4.63754358e-03 1.98754575e-02
-3.32397106e-03 2.01377440e-02 3.47342715e-03 1.63805503e-02
-3.00287479e-03 1.92617327e-02 -9.15799057e-04 1.99263208e-02]]]]
(1, 1, 28, 28)
5、模型训练与保存
# 创建文件夹
sample_dir = 'AutoEncoder'
if not os.path.exists(sample_dir):
os.makedirs(sample_dir)
model = AutoEncoder().to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr= learning_rate, weight_decay=1e-5)
Train_Loss = []
# 训练编码-解码的性能,损失即与原图像求均方误差
for epoch in range(num_epochs):
model.train()
for img, _ in dataloader:
img = Variable(img).to(device)
output = model(img)
loss = criterion(output, img)
optimizer.zero_grad()
loss.backward()
optimizer.step()
Train_Loss.append(loss.item()) #如果是标量则直接用.item()提取出来,存放的位置在CPU
print('epoch [{}/{}], loss:{:.4f}'.format(epoch+1, num_epochs, loss.item()))
save_image(output, os.path.join(sample_dir, 'sampled-{}.png'.format(epoch+1)))
torch.save(model.state_dict(), './conv_autoencoder.pth')
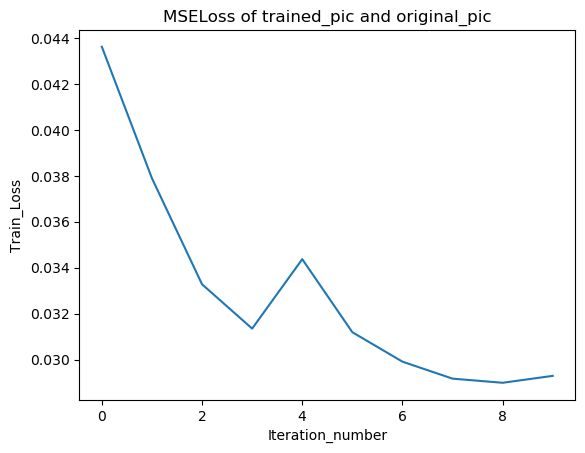
输出如下:
epoch [1/10], loss:0.0436
epoch [2/10], loss:0.0379
epoch [3/10], loss:0.0333
epoch [4/10], loss:0.0313
epoch [5/10], loss:0.0344
epoch [6/10], loss:0.0312
epoch [7/10], loss:0.0299
epoch [8/10], loss:0.0292
epoch [9/10], loss:0.0290
epoch [10/10], loss:0.0293
6、绘制训练曲线
# 绘制Train_Loss曲线
import matplotlib.pyplot as plt
# 但是要转换的list里面的元素包含多维的tensor,应该使用val= torch.tensor([item.cpu().detach().numpy() for item in val]).cuda()
print(type(Train_Loss))
# print(Train_Loss.is_cuda) # AttributeError: 'list' object has no attribute 'is_cuda'
plt.title('MSELoss of trained_pic and original_pic')
plt.plot(Train_Loss)
plt.ylabel('Train_Loss')
plt.xlabel('Iteration_number')
plt.show()