java中String和char
1.String 与char的区别
1 char是表示的是字符,定义的时候用单引号,只能存储一个字符。例如; char='d'.
而String表示的是字符串,定义的时候用双引号,可以存储一个或者多个字符。例如:String=“we are neuer”。
2 char是基本数据类型,而String是个类,属于引用数据类型。String类可以调用方法,具有面向对象的特征。
3 char在java中占2个字节,16位。
2.String类详解
1.创建方式两种:一种是使用双引号,一种是调用String类的构造函数
String x="abc"
String y = new String("abcd")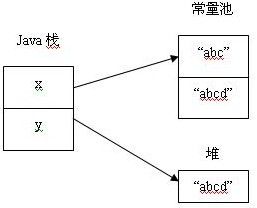
内存的分配情况。如图:
Java为String类型提供了缓冲池机制,当使用双引号定义对象时,Java环境首先去字符串缓冲池寻找内容相同的字符串,如果存在就拿出来使用,否则就创建一个新的字符串放在缓冲池中。
采用new关键字新建一个字符串对象时,JVM首先在字符串池中查找有没有"abcd"这个字符串对象,
如果有,则不在池中再去创建"abcd"这个对象了,直接在堆中创建一个"abcd"字符串对象,然后将堆中的这个"abcd"对象的地址返回赋给引用 y,这样,y就指向了堆中创建的这个"abcd"字符串对象;
如果没有,则首先在字符串池中创建一个"abcd"字符串对象,然后再在堆中创建一个"abcd"字符串对象,然后将堆中这个"abcd"字符串对象的地址返回赋给y引用,这样,y指向了堆中创建的这个"abcd"字符串对象。
注意:由于String字符串的不可变性我们可以十分肯定常量池中一定不存在两个相同的字符串
3.举例验证
eg:
public viod test{
String str1="aaa";
String str2="aaa";
System.out.println(str1==str2);
}
public static void test2() {
String str3 = new String("aaa");
String str4 = new String("aaa");
System.out.println("===========test2============");
System.out.println(str3 == str4);//false 可以看出用new的方式是生成不同的对象
}结果:true,false
test中str1与str2都指向的是常量池中的同一个对象所以是true
test2中,采用new关键字创建对象时,每次new出来的都是一个新的对象,str3与str4分别指向堆内存中不同的对象,并且常量池中保存了一份“aaa”,所以是false
/**
* 编译期确定
*/
public void test3(){
String s0="helloworld";
String s1="helloworld";
String s2="hello"+"world";
System.out.println("===========test3============");
System.out.println(s0==s1); //true 可以看出s0跟s1是指向同一个对象
System.out.println(s0==s2); //true 可以看出s0跟s2是指向同一个对象
}
因为例子中的s0和s1中的"helloworld”都是字符串常量,它们在编译期就被确定了,所以s0==s1为true;而"hello”和"world”也都是字符串常量,当一个字符串由多个字符串常量连接而成时,它自己肯定也是字符串常量,所以s2也同样在编译期就被解析为一个字符串常量,所以s2也是常量池中"helloworld”的一个引用。所以我们得出s0==s1==s2。
/**
* 编译期无法确定
*/
public void test4(){
String s0="helloworld";
String s1=new String("helloworld");
String s2="hello" + new String("world");
System.out.println("===========test4============");
System.out.println( s0==s1 ); //false
System.out.println( s0==s2 ); //false
System.out.println( s1==s2 ); //false
}用new String() 创建的字符串不是常量,不能在编译期就确定,所以new String() 创建的字符串不放入常量池中,它们有自己的地址空间
s0还是常量池中"helloworld”的引用,s1因为无法在编译期确定,所以是运行时创建的新对象"helloworld”的引用,s2因为有后半部分new String(”world”)所以也无法在编译期确定,所以也是一个新创建对象"helloworld”的引用。
/*
* 编译期无法确定
*/
public void test7(){
String s0 = "ab";
String s1 = "b";
String s2 = "a" + s1;
System.out.println("===========test7============");
System.out.println((s0 == s2)); //result = false
}JVM对于字符串引用,由于在字符串的"+"连接中,有字符串引用存在,而引用的值在程序编译期是无法确定的,即"a" + s1无法被编译器优化,只有在程序运行期来动态分配并将连接后的新地址赋给s2。所以上面程序的结果也就为false。
**
* 继续-编译期无法确定
*/
public void test5(){
String str1="abc";
String str2="def";
String str3=str1+str2;
System.out.println("===========test5============");
System.out.println(str3=="abcdef"); //false
}因为str3指向堆中的"abcdef"对象,而"abcdef"是字符串池中的对象,所以结果为false。JVM对String str="abc"对象放在常量池中是在编译时做的,而String str3=str1+str2是在运行时刻才能知道的。new对象也是在运行时才做的。而这段代码总共创建了5个对象,字符串池中两个、堆中三个。+运算符会在堆中建立来两个String对象,这两个对象的值分别是"abc"和"def",也就是说从字符串池中复制这两个值,然后在堆中创建两个对象,然后再建立对象str3,然后将"abcdef"的堆地址赋给str3。
步骤:
1)栈中开辟一块中间存放引用str1,str1指向池中String常量"abc"。
2)栈中开辟一块中间存放引用str2,str2指向池中String常量"def"。
3)栈中开辟一块中间存放引用str3。
4)str1 + str2通过StringBuilder的最后一步toString()方法还原一个新的String对象"abcdef",因此堆中开辟一块空间存放此对象。
5)引用str3指向堆中(str1 + str2)所还原的新String对象。
6)str3指向的对象在堆中,而常量"abcdef"在池中,输出为false。
/**
* 比较字符串常量的“+”和字符串引用的“+”的区别
*/
public void test8(){
String test="javalanguagespecification";
String str="java";
String str1="language";
String str2="specification";
System.out.println("===========test8============");
System.out.println(test == "java" + "language" + "specification");
System.out.println(test == str + str1 + str2);
}执行上述代码,结果为:true、false。
分析:为什么出现上面的结果呢?这是因为,字符串字面量拼接操作是在Java编译器编译期间就执行了,也就是说编译器编译时,直接把"java"、"language"和"specification"这三个字面量进行"+"操作得到一个"javalanguagespecification" 常量,并且直接将这个常量放入字符串池中,这样做实际上是一种优化,将3个字面量合成一个,避免了创建多余的字符串对象。而字符串引用的"+"运算是在Java运行期间执行的,即str + str2 + str3在程序执行期间才会进行计算,它会在堆内存中重新创建一个拼接后的字符串对象。总结来说就是:字面量"+"拼接是在编译期间进行的,拼接后的字符串存放在字符串池中;而字符串引用的"+"拼接运算实在运行时进行的,新创建的字符串存放在堆中。
对于直接相加字符串,效率很高,因为在编译器便确定了它的值,也就是说形如"I"+"love"+"java"; 的字符串相加,在编译期间便被优化成了"Ilovejava"。对于间接相加(即包含字符串引用),形如s1+s2+s3; 效率要比直接相加低,因为在编译器不会对引用变量进行优化。
public void test9(){
String s0 = "ab";
final String s1 = "b";
String s2 = "a" + s1;
System.out.println("===========test9============");
System.out.println((s0 == s2)); //result = true
}s1字符串加了final修饰,对于final修饰的变量,它在编译时被解析为常量值的一个本地拷贝存储到自己的常量池中或嵌入到它的字节码流中。所以此时的"a" + s1和"a" + "b"效果是一样的。故上面程序的结果为true。
/**
* 编译期无法确定
*/
public void test10(){
String s0 = "ab";
final String s1 = getS1();
String s2 = "a" + s1;
System.out.println("===========test10============");
System.out.println((s0 == s2)); //result = false
}
private static String getS1() {
return "b";
}这里面虽然将s1用final修饰了,但是由于其赋值是通过方法调用返回的,那么它的值只能在运行期间确定,因此s0和s2指向的不是同一个对象,故上面程序的结果为false。
总结:
(1)单独使用""引号创建的字符串都是常量,编译期就已经确定存储到String Pool中;
(2)使用new String("")创建的对象会存储到heap中,是运行期新创建的;
new创建字符串时首先查看池中是否有相同值的字符串,如果有,则拷贝一份到堆中,然后返回堆中的地址;如果池中没有,则在堆中创建一份,然后返回堆中的地址
(3)使用只包含常量的字符串连接符如"aa" + "aa"创建的也是常量,编译期就能确定,已经确定存储到String Pool中;
(4)使用包含变量的字符串连接符如"aa" + s1创建的对象是运行期才创建的,存储在heap中;
4.intern方法
String 有一个intern() 方法,native,用来检测在String pool是否已经有这个String存在。
public String intern()
返回字符串对象的规范化表示形式。
一个初始时为空的字符串池,它由类 String 私有地维护。
当调用 intern 方法时,如果池已经包含一个等于此 String 对象的字符串(该对象由 equals(Object) 方法确定),则返回池中的字符串。否则,将此 String 对象添加到池中,并且返回此池中 String 对象的引用。
它遵循对于任何两个字符串 s 和 t,当且仅当 s.equals(t) 为 true 时,s.intern() == t.intern() 才为 true。
所有字面值字符串和字符串赋值常量表达式都是内部的。
返回:
一个字符串,内容与此字符串相同,但它保证来自字符串池中。
public static void test5(){
String s2 = new String("abcd");
String s1 = "abcd";
String s3 = s2.intern();
String s4 = s1.intern();
System.out.println(s2==s3);
System.out.println(s1==s4);
System.out.println(s3==s4);
}false
true
true5.关于equals和==
(1)对于==,如果作用于基本数据类型的变量(byte,short,char,int,long,float,double,boolean ),则直接比较其存储的"值"是否相等;如果作用于引用类型的变量(String),则比较的是所指向的对象的地址(即是否指向同一个对象)。
(2)equals方法是基类Object中的方法,因此对于所有的继承于Object的类都会有该方法。在Object类中,equals方法是用来比较两个对象的引用是否相等,即是否指向同一个对象。
(3)对于equals方法,注意:equals方法不能作用于基本数据类型的变量。如果没有对equals方法进行重写,则比较的是引用类型的变量所指向的对象的地址;而String类对equals方法进行了重写,用来比较指向的字符串对象所存储的字符串是否相等。其他的一些类诸如Double,Date,Integer等,都对equals方法进行了重写用来比较指向的对象所存储的内容是否相等。
6. .String、StringBuffer、StringBuilder的区别
(1)可变与不可变:String是不可变字符串对象,StringBuilder和StringBuffer是可变字符串对象(其内部的字符数组长度可变)。
(2)是否多线程安全:String中的对象是不可变的,也就可以理解为常量,显然线程安全。StringBuffer 与 StringBuilder 中的方法和功能完全是等价的,只是StringBuffer 中的方法大都采用了synchronized 关键字进行修饰,因此是线程安全的,而 StringBuilder 没有这个修饰,可以被认为是非线程安全的。
(3)String、StringBuilder、StringBuffer三者的执行效率:
StringBuilder > StringBuffer > String 当然这个是相对的,不一定在所有情况下都是这样。比如String str = "hello"+ "world"的效率就比 StringBuilder st = new StringBuilder().append("hello").append("world")要高。因此,这三个类是各有利弊,应当根据不同的情况来进行选择使用:
当字符串相加操作或者改动较少的情况下,建议使用 String str="hello"这种形式;
当字符串相加操作较多的情况下,建议使用StringBuilder,如果采用了多线程,则使用StringBuffer。