- Linux ps 指令
halugin
Linux指令linux运维
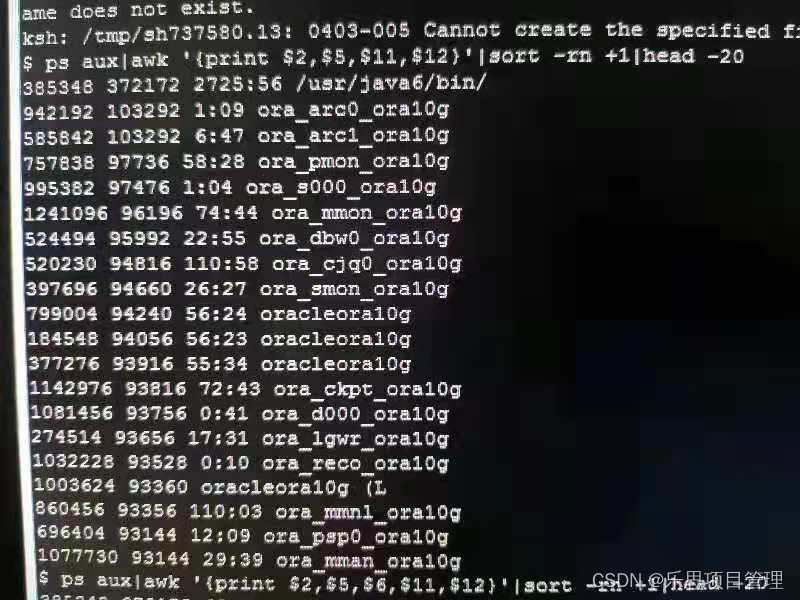
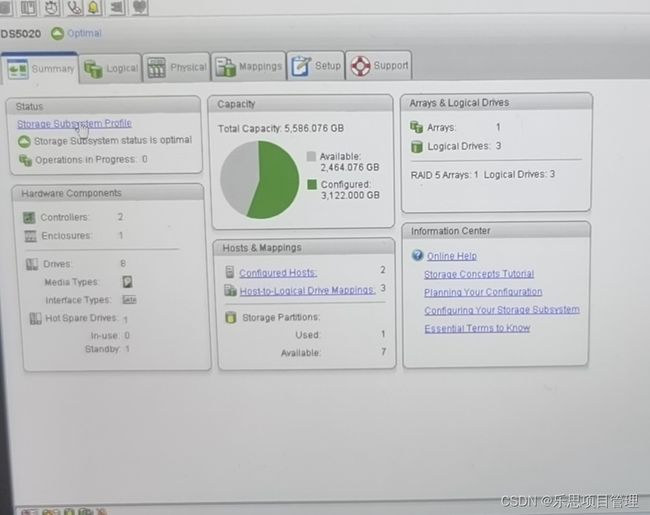
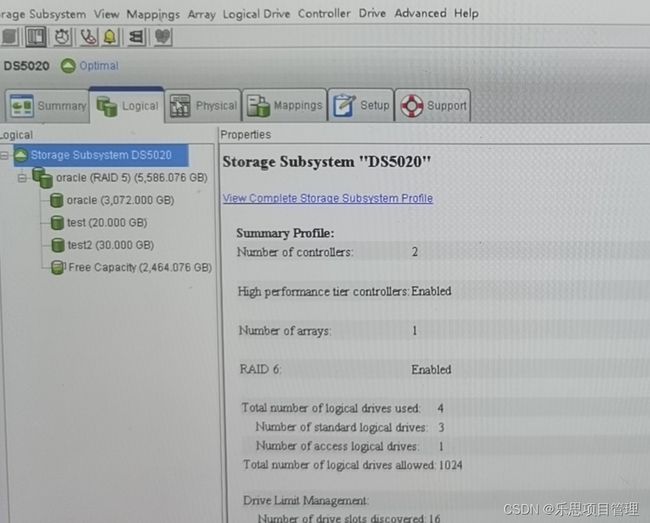
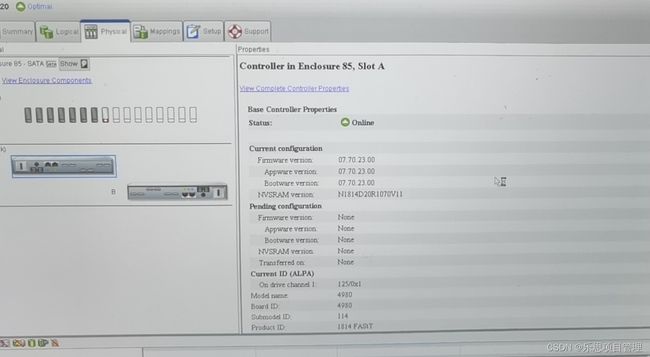
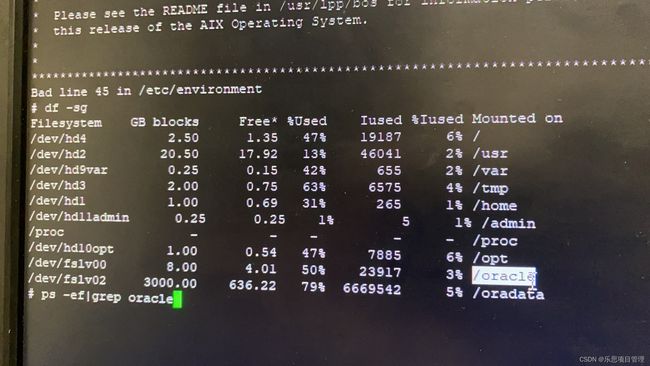
Linuxps指令ps(ProcessStatus)是Linux系统中用于查看进程状态的核心命令行工具。它提供系统当前运行进程的快照,显示进程ID、CPU和内存使用情况、运行状态等信息。作为系统管理员或开发人员,ps是监控系统资源、排查性能问题和管理系统进程的必备工具。其灵活的选项和输出格式使其适用于从简单查询到复杂分析的各种场景。什么是ps指令?概述ps是一个经典的Linux/Unix命令,用于
- Linux netstat 指令
halugin
Linux指令linux运维
Linuxnetstat指令netstat(NetworkStatistics)是Linux系统中用于查看网络状态、连接、路由表和接口统计信息的经典命令行工具。它为系统管理员和开发人员提供了强大的网络诊断功能,帮助分析网络连接、监控流量以及排查网络问题。尽管在现代Linux系统中,netstat正在被更新的工具(如ss)部分取代,但其简单性和广泛适用性使其仍然是许多场景下的首选工具。什么是nets
- Linux ss 指令
halugin
Linux指令linux运维
Linuxss指令ss(SocketStatistics)是Linux系统中用于显示网络套接字(socket)信息的现代命令行工具,是netstat的继任者,性能更高、输出更简洁。它提供详细的网络连接、监听端口和协议统计信息,广泛用于网络监控、故障排查和性能分析。相比传统的netstat,ss直接从内核获取数据显示更快,功能更强大,适合现代Linux系统。什么是ss指令?ss是Linux系统中的一
- Nginx 核心功能
?ccc?
nginx服务器网络
目录一:正向代理1:编译安装Nginx(1)安装支持软件(2)创建运行用户、组和日志目录(3)编译安装Nginx(4)添加Nginx系统服务2:配置正向代理二:反向代理1:配置nginx七层代理2:配置nginx四层代理三:Nginx缓存1:缓存功能的核心原理和缓存类型2:代理缓存功能设置四:Nginxrewrite和正则一:正向代理正向代理(ForwardProxy)是一种位于客户端和原始服务器
- 简单介绍物联网MQTT协议
Zio_Zhou
计算机网络linux
在学习mqtt应用层协议之前,我们先来介绍一下发布/订阅模型以及请求/响应模型两种模型。请求/响应模型是网络应用系统中最常见的模型。在这种模型中,一个客户端(如一个Web浏览器)向服务器发送一个请求,服务器处理这个请求并返回一个响应。这个过程是同步的,意味着客户端需要等待服务器的响应。这种模型的优点是简单和易于理解,但在处理大量并发请求时可能会导致性能问题。发布/订阅模型。在这种模型中,有一个或多
- 三阶落地:腾讯云Serverless+Spring Cloud的微服务实战架构
大熊计算机
#腾讯云架构腾讯云serverless
云原生演进的关键挑战(1)传统微服务架构痛点资源利用率低(非峰值期资源闲置率>60%)运维复杂度高(需管理数百个容器实例)突发流量处理能力弱(扩容延迟导致P99延迟飙升)(2)Serverless的破局价值腾讯云SCF(ServerlessCloudFunction)提供:毫秒级计费粒度(成本下降40%~70%)百毫秒级弹性伸缩(支持每秒万级并发扩容)零基础设施运维同步调用异步事件用户请求API网
- Nginx与Tomcat:谁更适合你的服务器?
当归1024
java中间件nginxnginxtomcat服务器
nginx和Tomcat是两种不同类型的服务器软件,它们各有不同的用途和特点:基本定义nginx轻量级的HTTP服务器和反向代理服务器主要用于静态文件服务、负载均衡、反向代理TomcatJavaWeb应用服务器专门用于运行JavaWeb应用(JSP、Servlet)主要区别1.功能定位nginx:静态文件服务器反向代理服务器负载均衡器HTTP缓存服务器Tomcat:Java应用容器JSP/Serv
- Node.js 全局对象
froginwe11
开发语言
Node.js全局对象引言Node.js作为一种流行的JavaScript运行环境,以其高性能、轻量级和跨平台的特点,被广泛应用于服务器端编程、网络应用开发等领域。在Node.js中,全局对象是一个重要的概念,它为开发者提供了一系列内置的全局变量和方法,使得编程变得更加便捷。本文将详细介绍Node.js的全局对象,帮助开发者更好地理解和运用它们。Node.js全局对象概述Node.js的全局对象指
- Linux操作系统,故障排查
月堂
linux运维服务器
案例1:GRUB引导故障故障现象:系统启动卡在"GRUB>"提示符,无法进入系统原因分析:GRUB配置文件损坏(/boot/grub/grub.cfg)引导文件被误删或磁盘损坏解决步骤:在GRUB命令行依次执行:insmodxfssetroot=(hd0,msdos1)linux/vmlinuz-root=/dev/sda1initrd/initramfs-.imgboot进入系统后执行:grub
- linux mysql命令行操作
命令行,linux,命令行操作相关学习资料:https://edu.51cto.com/video/797.htmlhttps://edu.51cto.com/video/1400.htmlhttps://edu.51cto.com/video/3832.htmlLinuxMySQL命令行操作入门指南作为一名刚入行的开发者,掌握Linux系统下的MySQL命令行操作是一项基本技能。本文将带你一步步
- Ansible——lookup,过滤器
凤凰战士芭比Q
Ansibleansiblelinux
文章目录Ansible——lookup,过滤器lookup读取文件lookup生成随机密码lookup读取环境变量lookup读取Linux命令的执行结果lookup读取template变量替换后的文件lookup读取配置文件lookup读取DNS解析的值过滤器过滤器使用的位置过滤器对普通变量的操作过滤器对文件路径的操作过滤器对字符串变量的操作过滤器对JSON的操作过滤器对数据结构的操作过滤器的链
- 【linux】yum工具篇
nanguochenchuan
Linux操作系统linux运维服务器
Yum工具概述Yum(YellowdogUpdaterModified)是RedHat系列Linux发行版(如CentOS、Fedora)中最核心的软件包管理工具,它基于RPM包管理系统构建,通过自动解决依赖关系极大简化了软件管理流程。与直接使用rpm命令相比,Yum能自动处理软件包依赖,让系统管理员从"依赖地狱"中解脱出来。Yum工作原理深度解析Yum的工作流程可分为四个关键阶段:仓库配置读取:
- Linux命令行基础:常用命令与技巧
m0_73843831
chrome前端Linux命令行常用命文件操作权限管理
1.Linux命令行概述Linux命令行(也称为终端或Shell)是Linux操作系统中与用户交互的文本界面。通过命令行,用户可以执行各种任务,如文件管理、进程控制、系统配置等。相比图形用户界面(GUI),命令行具有更高的效率和灵活性,尤其适用于服务器管理和自动化任务。本文将涵盖以下内容:常用命令文件与目录操作权限管理进程管理命令行技巧2.常用命令2.1文件与目录操作ls功能:列出当前目录下的文件
- Linux tcp_info:监控TCP连接的秘密武器
CodeWithMe
网络linuxtcp/ip
深入解析Linuxtcp_info:TCP状态的实时监控利器在开发和运维网络服务时,我们常常遇到这些问题:我的TCP连接为什么速度慢?是发生了重传,还是窗口太小?拥塞控制到底有没有生效?这些问题的答案,其实隐藏在内核的tcp_info结构中。本文将详细介绍:tcp_info是什么,怎么用?各字段含义和实际用途在调优TCP服务中的应用实践一、什么是tcp_info?tcp_info是Linux内核中
- 【Linux】ghb工具
nanguochenchuan
Linux操作系统linux运维服务器
GDB简介GDB(GNUDebugger)是Linux系统中最强大的命令行调试工具,由GNU项目开发。作为程序员调试C/C++程序的利器,GDB能帮助你:定位程序崩溃原因分析程序运行状态跟踪变量值变化检测内存错误安装与配置安装方法#Ubuntu/Debiansudoaptinstallgdb#CentOS/RHELsudoyuminstallgdb#ArchLinuxsudopacman-Sgdb
- ssh -T [email protected]失败后解决方案
青草地溪水旁
linuxsshgitgithub
这个错误表示你的SSH连接无法到达GitHub服务器。以下是详细解决方案,按照优先级排序:首选解决方案:使用SSHoverHTTPS(端口443)这是最有效的解决方案,因为许多网络会阻止22端口:#编辑SSH配置文件nano~/.ssh/config添加以下内容:Hostgithub.comHostnamessh.github.comPort443Usergit保存后测试连接:ssh-Tgit@g
- Linux命令行操作基础
EnigmaCoder
Linuxlinux运维服务器
目录前言目录结构✍️语法格式操作技巧Tab补全光标操作基础命令登录和电源管理命令⚙️login⚙️last⚙️exit⚙️shutdown⚙️halt⚙️reboot文件命令⚙️浏览目录类命令pwdcdls⚙️浏览文件类命令catmorelessheadtail⚙️目录操作类命令mkdirrmdir⚙️文件操作类命令mvrmtouchfindgziptar⚙️cp前言大家好!我是EnigmaCod
- Sonatype Nexus3安装配置及使用
無法複制
nexus
1、简介SonatypeNexusRepositoryManager是一款强大的仓库管理工具,用于存储、管理和发布软件组件。它能够支持多种格式的仓库,如Maven、npm、Docker等。在企业开发中,私有Maven仓库常用于存储自定义依赖和发布组件,确保代码安全性和内部共享。本文将从服务器环境搭建、Nexus安装与配置、仓库创建、依赖上传,再到Maven项目中使用私有仓库的全过程,帮助你掌握如何
- webpack和vite对比解析(AI)
秉承初心
AI创造webpack前端node.js
以下是Webpack和Vite的对比解析,从核心机制、性能、配置扩展性、适用场景等维度进行详细说明:⚙️一、核心机制差异构建模式Webpack:采用打包器模式,启动时需遍历整个模块依赖图,将所有资源打包成Bundle,再启动开发服务器。Vite:基于ESModules原生支持,开发环境跳过打包,按需编译(浏览器请求时实时编译)。生产环境才用Rollup打包。依赖处理Webpack:冷启动时需全量打
- 什么是Node.js,有什么特点
前端与小赵
node.js
Node.js简介Node.js是一个基于ChromeV8引擎的JavaScript运行时环境,由RyanDahl于2009年创建。Node.js允许开发者使用JavaScript编写服务器端应用程序,打破了JavaScript仅限于浏览器端的限制。Node.js的设计目标是提供一种简单、高效的方式来构建可伸缩的网络应用。Node.js的特点非阻塞I/O特点:Node.js使用事件驱动的非阻塞I/
- 渗透测试/漏洞赏金/src/黑客自学指南
Web渗透测试方法论方法论概要在此方法论中我们的目标范围仅是一个域名或一个子域名,因此你应当针对你测试范围内的每一个不确定其web服务的域名,子域名或ip进行测试1.首先确定web服务器所使用的技术,其次如果你成功识别到技术,那么接下来要知道如何利用检索的信息。·该技术版本有任何已知的漏洞吗·使用的是常规的技术吗?有什么有用的技巧以此来检索更多的信息?·有没有针对某种技术的专用的扫描器可以用?比如
- go关闭linux进程,Golang信号处理和优雅退出守护进程
凯然
go关闭linux进程
Golang中的信号处理信号类型个平台的信号定义或许有些不同。下面列出了POSIX中定义的信号。Linux使用34-64信号用作实时系统中。命令mansignal提供了官方的信号介绍。在POSIX.1-1990标准中定义的信号列表信号值动作说明SIGHUP1Term终端控制进程结束(终端连接断开)SIGINT2Term用户发送INTR字符(Ctrl+C)触发SIGQUIT3Core用户发送QUIT
- 深入剖析Redis高性能的原因,IO多路复用模型,Redis数据迁移,分布式锁实现
一、深入剖析Redis单线程处理命令仍具备高性能的原因Redis虽然是单线程处理命令的(主线程负责网络I/O和命令处理),但它依然具备百万级QPS的吞吐能力。这个看似矛盾的现象,其实是Redis高性能架构设计和底层实现精妙配合的结果。下面我们从架构、内核原理、操作系统机制、与其他系统对比等多维度深入剖析,为何Redis单线程却读写性能极高。1.Redis是“单线程处理命令”,但不是完全单线程模块是
- 深入剖析Nginx架构及其不同使用场景下的配置
LiRuiJie
NginxNginx系统架构反向代理
一、Nginx整体架构概览1.Nginx简介Nginx是采用C语言编写的高性能Web服务器、反向代理服务器及邮件代理服务器,特点是:高并发、高可用、低内存占用、模块化设计。架构核心理念:Master-Worker多进程模型事件驱动(Event-Driven)+异步非阻塞高度模块化设计2.进程模型Nginx的进程模型非常轻量,通常包含:1.Master进程启动时由shell进程fork出来主要负责:
- Cursor MySQL MCP 完整操作配置指南
z日火
开发分享mcpcursormysql
概述本指南帮助您在Windows环境下配置Cursor编辑器的MySQLMCP服务器,实现通过AI助手对数据库进行完整的增删改查操作。功能特性:✅自然语言数据库查询✅智能数据插入和更新✅安全的数据删除操作✅自动数据分析和报告生成快速配置1.环境检查#检查必要组件node--version#Node.js>=16mysql--version#MySQL5.7+cursor--version#Curs
- Linux工作常用命令记录
A little storm
linuxubuntujvmc++
Linux常用命令#列出当前系统中所有的网络连接和监听端口,可通过grep配合查找需要的信息netstat-nat#列出所有进程信息,可通过grep配合查找需要的信息psaux#查看防火墙规则iptables-L#查找文件,如查找RDB_SVRfind/-name"RDB_SVR"#查看所有磁盘空间使用情况df-h#查看文件或目录的磁盘空间使用情况,示例为查看当前目录中所有文件和目录的空间使用情况
- linux日志文件详解
MagnumOvO
云计算linux5Glinux运维centos
目录一、日志文件的分类二、日志文件位置三、常见日志文件1.分析日志文件2.内核及系统日志四、日志消息等级五、日志文件分析1.用户日志2.程序日志六、日志分析注意事项一、日志文件的分类日志文件是用于记录Linux系统中各种运行消息的文件,相当于Linux主机的“日记”。不同的日志文件记载了不同类型的信息,如Linux内核消息、用户登录事件、程序错误等·日志文件对于诊断和解决系统中的问题很有帮助,因为
- C# 中 EventWaitHandle 实现多进程状态同步的深度解析
Leon@Lee
c#开发语言
在现代软件开发中,多进程应用场景日益普遍。无论是分布式系统、微服务架构,还是传统的客户端-服务器模型,进程间的状态同步都是一个关键挑战。C#提供了多种同步原语,其中EventWaitHandle是一个强大的工具,特别适合处理跨进程的同步需求。本文将深入探讨EventWaitHandle的工作原理、使用场景及最佳实践。一、EventWaitHandle基础原理EventWaitHandle是.NET
- Linux系统日志管理
多肉葡萄~
linux运维服务器
日志文件作用日志文件用于记录linux系统的各种运行信息的文件,相当于linux主机的日记,不同的日志文件记载了不同类型的信息,如Linux内核消息、用户登录事件、程序错误等。日志文件对于诊断和解决问题很有帮助,因为linux运行的程序通常把系统的消息和错误写入对应的日志文件,这样系统可以有据可查,此外,当主机遭受攻击时,日志文件还可以帮助寻找攻击者留下的痕迹。几种日志管理工具的介绍在Linux系
- 【lua】Linux上安装lua和luarocks包管理工具
果壳~
lualinux开发语言
目录安装lua安装luarocksluarocks其他命令安装lua首先打开lua官网https://lua.org点击download就可以看到安装脚本新建一个目录将压缩包下载到这个目录里curl-L-R-Ohttps://www.lua.org/ftp/lua-5.4.8.tar.gztarzxflua-5.4.8.tar.gzcdlua-5.4.8makealltest#最后还得加上make
- Java常用排序算法/程序员必须掌握的8大排序算法
cugfy
java
分类:
1)插入排序(直接插入排序、希尔排序)
2)交换排序(冒泡排序、快速排序)
3)选择排序(直接选择排序、堆排序)
4)归并排序
5)分配排序(基数排序)
所需辅助空间最多:归并排序
所需辅助空间最少:堆排序
平均速度最快:快速排序
不稳定:快速排序,希尔排序,堆排序。
先来看看8种排序之间的关系:
1.直接插入排序
(1
- 【Spark102】Spark存储模块BlockManager剖析
bit1129
manager
Spark围绕着BlockManager构建了存储模块,包括RDD,Shuffle,Broadcast的存储都使用了BlockManager。而BlockManager在实现上是一个针对每个应用的Master/Executor结构,即Driver上BlockManager充当了Master角色,而各个Slave上(具体到应用范围,就是Executor)的BlockManager充当了Slave角色
- linux 查看端口被占用情况详解
daizj
linux端口占用netstatlsof
经常在启动一个程序会碰到端口被占用,这里讲一下怎么查看端口是否被占用,及哪个程序占用,怎么Kill掉已占用端口的程序
1、lsof -i:port
port为端口号
[root@slave /data/spark-1.4.0-bin-cdh4]# lsof -i:8080
COMMAND PID USER FD TY
- Hosts文件使用
周凡杨
hostslocahost
一切都要从localhost说起,经常在tomcat容器起动后,访问页面时输入http://localhost:8088/index.jsp,大家都知道localhost代表本机地址,如果本机IP是10.10.134.21,那就相当于http://10.10.134.21:8088/index.jsp,有时候也会看到http: 127.0.0.1:
- java excel工具
g21121
Java excel
直接上代码,一看就懂,利用的是jxl:
import java.io.File;
import java.io.IOException;
import jxl.Cell;
import jxl.Sheet;
import jxl.Workbook;
import jxl.read.biff.BiffException;
import jxl.write.Label;
import
- web报表工具finereport常用函数的用法总结(数组函数)
老A不折腾
finereportweb报表函数总结
ADD2ARRAY
ADDARRAY(array,insertArray, start):在数组第start个位置插入insertArray中的所有元素,再返回该数组。
示例:
ADDARRAY([3,4, 1, 5, 7], [23, 43, 22], 3)返回[3, 4, 23, 43, 22, 1, 5, 7].
ADDARRAY([3,4, 1, 5, 7], "测试&q
- 游戏服务器网络带宽负载计算
墙头上一根草
服务器
家庭所安装的4M,8M宽带。其中M是指,Mbits/S
其中要提前说明的是:
8bits = 1Byte
即8位等于1字节。我们硬盘大小50G。意思是50*1024M字节,约为 50000多字节。但是网宽是以“位”为单位的,所以,8Mbits就是1M字节。是容积体积的单位。
8Mbits/s后面的S是秒。8Mbits/s意思是 每秒8M位,即每秒1M字节。
我是在计算我们网络流量时想到的
- 我的spring学习笔记2-IoC(反向控制 依赖注入)
aijuans
Spring 3 系列
IoC(反向控制 依赖注入)这是Spring提出来了,这也是Spring一大特色。这里我不用多说,我们看Spring教程就可以了解。当然我们不用Spring也可以用IoC,下面我将介绍不用Spring的IoC。
IoC不是框架,她是java的技术,如今大多数轻量级的容器都会用到IoC技术。这里我就用一个例子来说明:
如:程序中有 Mysql.calss 、Oracle.class 、SqlSe
- 高性能mysql 之 选择存储引擎(一)
annan211
mysqlInnoDBMySQL引擎存储引擎
1 没有特殊情况,应尽可能使用InnoDB存储引擎。 原因:InnoDB 和 MYIsAM 是mysql 最常用、使用最普遍的存储引擎。其中InnoDB是最重要、最广泛的存储引擎。她 被设计用来处理大量的短期事务。短期事务大部分情况下是正常提交的,很少有回滚的情况。InnoDB的性能和自动崩溃 恢复特性使得她在非事务型存储的需求中也非常流行,除非有非常
- UDP网络编程
百合不是茶
UDP编程局域网组播
UDP是基于无连接的,不可靠的传输 与TCP/IP相反
UDP实现私聊,发送方式客户端,接受方式服务器
package netUDP_sc;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.Ine
- JQuery对象的val()方法执行结果分析
bijian1013
JavaScriptjsjquery
JavaScript中,如果id对应的标签不存在(同理JAVA中,如果对象不存在),则调用它的方法会报错或抛异常。在实际开发中,发现JQuery在id对应的标签不存在时,调其val()方法不会报错,结果是undefined。
- http请求测试实例(采用json-lib解析)
bijian1013
jsonhttp
由于fastjson只支持JDK1.5版本,因些对于JDK1.4的项目,可以采用json-lib来解析JSON数据。如下是http请求的另外一种写法,仅供参考。
package com;
import java.util.HashMap;
import java.util.Map;
import
- 【RPC框架Hessian四】Hessian与Spring集成
bit1129
hessian
在【RPC框架Hessian二】Hessian 对象序列化和反序列化一文中介绍了基于Hessian的RPC服务的实现步骤,在那里使用Hessian提供的API完成基于Hessian的RPC服务开发和客户端调用,本文使用Spring对Hessian的集成来实现Hessian的RPC调用。
定义模型、接口和服务器端代码
|---Model
&nb
- 【Mahout三】基于Mahout CBayes算法的20newsgroup流程分析
bit1129
Mahout
1.Mahout环境搭建
1.下载Mahout
http://mirror.bit.edu.cn/apache/mahout/0.10.0/mahout-distribution-0.10.0.tar.gz
2.解压Mahout
3. 配置环境变量
vim /etc/profile
export HADOOP_HOME=/home
- nginx负载tomcat遇非80时的转发问题
ronin47
nginx负载后端容器是tomcat(其它容器如WAS,JBOSS暂没发现这个问题)非80端口,遇到跳转异常问题。解决的思路是:$host:port
详细如下:
该问题是最先发现的,由于之前对nginx不是特别的熟悉所以该问题是个入门级别的:
? 1 2 3 4 5
- java-17-在一个字符串中找到第一个只出现一次的字符
bylijinnan
java
public class FirstShowOnlyOnceElement {
/**Q17.在一个字符串中找到第一个只出现一次的字符。如输入abaccdeff,则输出b
* 1.int[] count:count[i]表示i对应字符出现的次数
* 2.将26个英文字母映射:a-z <--> 0-25
* 3.假设全部字母都是小写
*/
pu
- mongoDB 复制集
开窍的石头
mongodb
mongo的复制集就像mysql的主从数据库,当你往其中的主复制集(primary)写数据的时候,副复制集(secondary)会自动同步主复制集(Primary)的数据,当主复制集挂掉以后其中的一个副复制集会自动成为主复制集。提供服务器的可用性。和防止当机问题
mo
- [宇宙与天文]宇宙时代的经济学
comsci
经济
宇宙尺度的交通工具一般都体型巨大,造价高昂。。。。。
在宇宙中进行航行,近程采用反作用力类型的发动机,需要消耗少量矿石燃料,中远程航行要采用量子或者聚变反应堆发动机,进行超空间跳跃,要消耗大量高纯度水晶体能源
以目前地球上国家的经济发展水平来讲,
- Git忽略文件
Cwind
git
有很多文件不必使用git管理。例如Eclipse或其他IDE生成的项目文件,编译生成的各种目标或临时文件等。使用git status时,会在Untracked files里面看到这些文件列表,在一次需要添加的文件比较多时(使用git add . / git add -u),会把这些所有的未跟踪文件添加进索引。
==== ==== ==== 一些牢骚
- MySQL连接数据库的必须配置
dashuaifu
mysql连接数据库配置
MySQL连接数据库的必须配置
1.driverClass:com.mysql.jdbc.Driver
2.jdbcUrl:jdbc:mysql://localhost:3306/dbname
3.user:username
4.password:password
其中1是驱动名;2是url,这里的‘dbna
- 一生要养成的60个习惯
dcj3sjt126com
习惯
一生要养成的60个习惯
第1篇 让你更受大家欢迎的习惯
1 守时,不准时赴约,让别人等,会失去很多机会。
如何做到:
①该起床时就起床,
②养成任何事情都提前15分钟的习惯。
③带本可以随时阅读的书,如果早了就拿出来读读。
④有条理,生活没条理最容易耽误时间。
⑤提前计划:将重要和不重要的事情岔开。
⑥今天就准备好明天要穿的衣服。
⑦按时睡觉,这会让按时起床更容易。
2 注重
- [介绍]Yii 是什么
dcj3sjt126com
PHPyii2
Yii 是一个高性能,基于组件的 PHP 框架,用于快速开发现代 Web 应用程序。名字 Yii (读作 易)在中文里有“极致简单与不断演变”两重含义,也可看作 Yes It Is! 的缩写。
Yii 最适合做什么?
Yii 是一个通用的 Web 编程框架,即可以用于开发各种用 PHP 构建的 Web 应用。因为基于组件的框架结构和设计精巧的缓存支持,它特别适合开发大型应
- Linux SSH常用总结
eksliang
linux sshSSHD
转载请出自出处:http://eksliang.iteye.com/blog/2186931 一、连接到远程主机
格式:
ssh name@remoteserver
例如:
ssh
[email protected]
二、连接到远程主机指定的端口
格式:
ssh name@remoteserver -p 22
例如:
ssh i
- 快速上传头像到服务端工具类FaceUtil
gundumw100
android
快速迭代用
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOExceptio
- jQuery入门之怎么使用
ini
JavaScripthtmljqueryWebcss
jQuery的强大我何问起(个人主页:hovertree.com)就不用多说了,那么怎么使用jQuery呢?
首先,下载jquery。下载地址:http://hovertree.com/hvtart/bjae/b8627323101a4994.htm,一个是压缩版本,一个是未压缩版本,如果在开发测试阶段,可以使用未压缩版本,实际应用一般使用压缩版本(min)。然后就在页面上引用。
- 带filter的hbase查询优化
kane_xie
查询优化hbaseRandomRowFilter
问题描述
hbase scan数据缓慢,server端出现LeaseException。hbase写入缓慢。
问题原因
直接原因是: hbase client端每次和regionserver交互的时候,都会在服务器端生成一个Lease,Lease的有效期由参数hbase.regionserver.lease.period确定。如果hbase scan需
- java设计模式-单例模式
men4661273
java单例枚举反射IOC
单例模式1,饿汉模式
//饿汉式单例类.在类初始化时,已经自行实例化
public class Singleton1 {
//私有的默认构造函数
private Singleton1() {}
//已经自行实例化
private static final Singleton1 singl
- mongodb 查询某一天所有信息的3种方法,根据日期查询
qiaolevip
每天进步一点点学习永无止境mongodb纵观千象
// mongodb的查询真让人难以琢磨,就查询单天信息,都需要花费一番功夫才行。
// 第一种方式:
coll.aggregate([
{$project:{sendDate: {$substr: ['$sendTime', 0, 10]}, sendTime: 1, content:1}},
{$match:{sendDate: '2015-
- 二维数组转换成JSON
tangqi609567707
java二维数组json
原文出处:http://blog.csdn.net/springsen/article/details/7833596
public class Demo {
public static void main(String[] args) { String[][] blogL
- erlang supervisor
wudixiaotie
erlang
定义supervisor时,如果是监控celuesimple_one_for_one则删除children的时候就用supervisor:terminate_child (SupModuleName, ChildPid),如果shutdown策略选择的是brutal_kill,那么supervisor会调用exit(ChildPid, kill),这样的话如果Child的behavior是gen_