Spark
Spark
为什么要掌握Spark
大数据技术及人工智能的蓬勃发展,促进了我国的经济更快更好地进入高质量发展阶段,加快建设制造强国,质量强国,航天强国,交通强国,网络强国,数据中国。基于开源技术地Hadoop分布式框架在行业中地应用十分广泛,但是Hadoop本身还存在诸多缺陷,主要的缺陷是Hadoop的MapReduce分布式框架在计算时延迟过高,无法满足实时,快速的计算需求。
Spark继承了MapReduce分布式计算框架的优点并改进了MapReduce的明显欠缺,与MapReduce不同的是,Spark的中间输出的结果可以保存在内存中,从而大大减少了读写HDFS(Hadoop分布式文件系统)的次数,因此Spark能更好地适用于数据挖掘与机器学习中迭代次数较多的算法。

简介
Spark是一个开源的大数据处理框架,由Apache软件基金会开发和维护的,提供了一个分布式计算引擎,可以处理大规模数据集的高速计算。Spark能够在内存中进行数据处理,因此具有较高的性能和效率。
特点

- 高速计算:
- Spark使用内存计算,相较于传统的磁盘计算更加快速,能够实现迭代计算和交互式查询
- 支持多种语言
- Spark支持多种语言,包括Java,Scala,Python和R等,使得开发人员可以使用自己熟悉的语言进行开发
- 分布式数据集
- Spark提供了弹性分布式数据集(Resilient Distributed Datasets,RDDs),它是一种可靠且可并行操作的数据结构,支持对数据集进行高级操作和转换。
- 多种应用场景
- Spark可以应用于批处理,实时流处理, 机器学习和图形化处理等不同类型的大数据处理任务。
- 生态系统丰富
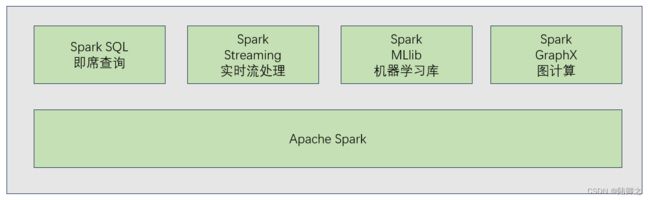
- Spark生态系统提供了许多相关工具和库,如Spark SQL,Spark Streaming,MLlib和GraphX等,用于处理不同领域的数据处理需求
搭建Spark集群
注意在安装之前必须安装hadoop:http://t.csdn.cn/iAMBr
下载scala安装包
https://downloads.lightbend.com/scala/2.13.10/scala-2.13.10.tgz
下载Spark安装包
https://dlcdn.apache.org/spark/spark-3.4.1/spark-3.4.1-bin-hadoop3.tgz
上传压缩
[root@master local]# cd /usr/local
[root@master local]# ll
总用量 402356
drwxr-xr-x. 11 root root 195 6月 16 10:29 apache-hive-2.3.9-bin
drwxr-xr-x. 11 1000 mysql 272 5月 25 08:49 hadoop-3.3.1
drwxr-xr-x. 8 10143 10143 273 4月 8 2021 jdk1.8.0_291
drwxr-xr-x. 10 775 mysql 141 6月 15 10:40 mysql
-rw-r--r--. 1 root root 23669298 7月 19 11:11 scala-2.13.10.tgz
-rw-r--r--. 1 root root 388341449 7月 19 11:11 spark-3.4.1-bin-hadoop3.tgz
解压安装包
[root@master local]# tar -zxvf scala-2.13.10.tgz
[root@master local]# tar -zxvf spark-3.4.1-bin-hadoop3.tgz
[root@master local]# ll
总用量 402356
drwxr-xr-x. 11 root root 195 6月 16 10:29 apache-hive-2.3.9-bin
drwxr-xr-x. 11 1000 mysql 272 5月 25 08:49 hadoop-3.3.1
drwxr-xr-x. 8 10143 10143 273 4月 8 2021 jdk1.8.0_291
drwxr-xr-x. 10 775 mysql 141 6月 15 10:40 mysql
drwxrwxr-x. 6 2000 2000 79 10月 9 2022 scala-2.13.10
-rw-r--r--. 1 root root 23669298 7月 19 11:11 scala-2.13.10.tgz
drwxr-xr-x. 13 1000 mysql 211 6月 20 07:23 spark-3.4.1-bin-hadoop3
-rw-r--r--. 1 root root 388341449 7月 19 11:11 spark-3.4.1-bin-hadoop3.tgz
重命名
[root@master local]# mv scala-2.13.10 scala
[root@master local]# mv spark-3.4.1-bin-hadoop3 spark
[root@master local]# ll
总用量 402356
drwxr-xr-x. 11 root root 195 6月 16 10:29 apache-hive-2.3.9-bin
drwxr-xr-x. 11 1000 mysql 272 5月 25 08:49 hadoop-3.3.1
drwxr-xr-x. 8 10143 10143 273 4月 8 2021 jdk1.8.0_291
drwxr-xr-x. 10 775 mysql 141 6月 15 10:40 mysql
drwxrwxr-x. 6 2000 2000 79 10月 9 2022 scala
-rw-r--r--. 1 root root 23669298 7月 19 11:11 scala-2.13.10.tgz
drwxr-xr-x. 13 1000 mysql 211 6月 20 07:23 spark
-rw-r--r--. 1 root root 388341449 7月 19 11:11 spark-3.4.1-bin-hadoop3.tgz
修改环境变量
[root@master local]# vi /etc/profile
# Scala & Spark
export SCALA_HOME=/usr/local/scala
export SPARK_HOME=/usr/local/spark
export SPARKPYTHON=/usr/local/spark/python
export PATH=$PATH:$SCALA_HOME/bin:$SPARK_HOME/sbin:$SPARKPYTHON
# 刷新环境变量
[root@master local]# source /etc/profile
修改文件
Spark-env.sh
[root@master local]# cd spark/conf/
[root@master conf]# cp spark-env.sh.template spark-env.sh
[root@master conf]# vi spark-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_291
export HADOOP_CONF_DIR=/usr/local/hadoop-3.3.1/etc/hadoop
export SPARK_MASTER_IP=master
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_MEMORY=512m
export SPARK_WORKER_CORES=1
export SPARK_EXECUTOR_MEMORY=512m
export SPARK_EXECUTOR_CORES=1
export SPARK_WORKER_INSTANCES=1
- JAVA_HOME
- Java的安装路径
- HADOOP_CONF_DIR
- hadoop配置文件的路径
- SPARK_MASTER_IP
- Spark主节点的IP地址或主机名
- SPARK_MASTER_PORT
- Spark主节点的端口号
- SPARK_WORKER_MENORY
- 工作(worker)节点能给予Executor的内存大小
- SPARK_WORKER_CORES
- 每个节点可以使用的内核数
- SPARK_EXECUTOR_MEMORY
- 每个Executor的内存大小
- SPARK_EXECUTOR_CORES
- Executor的内核数
- SPARK_WORKER_INSTANCES
- 每个节点的Worker进程数
Workers
[root@master conf]# cp workers.template workers
[root@master conf]# vi workers
# 删除原有的内容,加入其他子节点的主机名
slave01
slave02
slave03
spark-defaults.conf
[root@master conf]# cp spark-defaults.conf.template spark-defaults.conf
[root@master conf]# vi spark-defaults.conf
spark.master spark://master:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://master:8020/spark-logs
spark.history.fs.logDirectory hdfs://master:8020/spark-logs
- spark.master
- Spark主机点所在机器及端口,默认写法是spark://
- spark.eventLog.enabled
- 是否打开任务日志功能,默认为false,即不打开
- spark.eventLog.dir
- 任务日志默认存放位置,配置为一个HDFS路径即可
- spark.history.fs.logDirectory
- 存放历史应用日志文件的目录
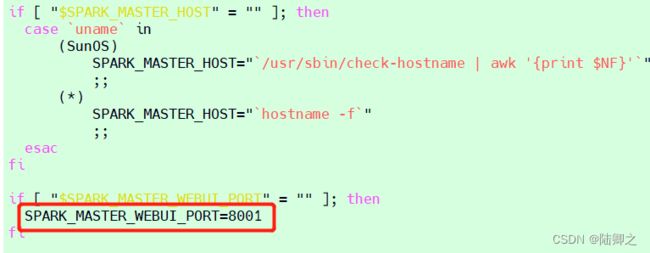
修改端口号
[root@master ~]# vi /usr/local/spark/sbin/start-master.sh
分发文件
[root@master conf]# scp -r /usr/local/spark/ slave01:/usr/local/
[root@master conf]# scp -r /usr/local/spark/ slave02:/usr/local/
[root@master conf]# scp -r /usr/local/spark/ slave03:/usr/local/
启动Hadoop
[root@master conf]# hdfs namenode -format
[root@master conf]# start-dfs.sh
[root@master conf]# start-yarn.sh
# 创建/spark-logs目录
[root@master conf]# hdfs dfs -mkdir /spark-logs
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l9gcNGKv-1689818377066)(E:\Java笔记\大数据\Spark\Spark.assets\image-20230719151156421.png)]](http://img.e-com-net.com/image/info8/e5c462fbb9ab4a4aabc3f95626f4f0f6.jpg)
启动Spark
[root@master ~]# /usr/local/spark/sbin/start-all.sh
[root@master conf]# /usr/local/spark/sbin/start-history-server.sh
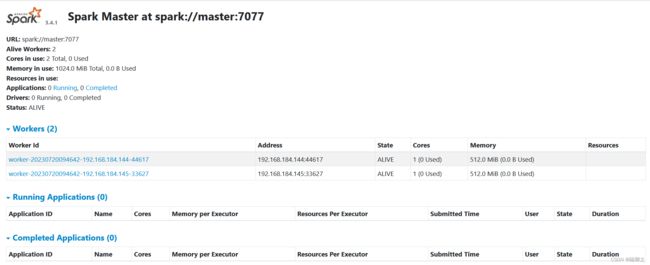
监控界面http://master:8001/
HistoryServer的监控https://master:18080
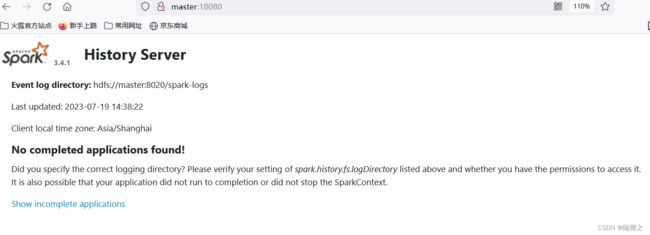
该界面记录了作业的信息,包括已经运行完成的作业的信息和正在运行的作业的信息。