伴鱼基于 Flink 构建数据集成平台的设计与实现
▼ 关注「Apache Flink」,获取更多技术干货 ▼
摘要:数据仓库有四个基本的特征:面向主题的、集成的、相对稳定的、反映历史变化的。其中数据集成是数据仓库构建的首要前提,指将多个分散的、异构的数据源整合在一起以便于后续的数据分析。将数据集成过程平台化,将极大提升数据开发人员的效率,本文主要内容为:
数据集成 VS 数据同步
集成需求
数据集成 V1
数据集成 V2
线上效果
总结
Tips:FFA 大会以及 Hackathon 比赛重磅开启,点击「阅读原文」了解详情~
A data warehouse is a subject-oriented, integrated, nonvolatile, and time-variant collection of data in support of management’s decisions.
—— Bill Inmon
一、数据集成 VS 数据同步
「数据集成」往往和「数据同步」在概念上存在一定的混淆,为此我们对这二者进行了区分:
「数据集成」特指面向数据仓库 ODS 层的数据同步过程;
「数据同步」面向的是一般化的 Source 到 Sink 的数据传输过程。
二者的关系如下图所示:

「数据同步平台」提供基础能力,不掺杂具体的业务逻辑。
「数据集成平台」是构建在「数据同步平台」之上的,除了将原始数据同步之外还包含了一些聚合的逻辑 (如通过数据库的日志数据对快照数据进行恢复,下文将会详细展开) 以及数仓规范相关的内容 (如数仓 ODS 层库表命名规范) 等。
目前「数据同步平台」的建设正在我们的规划之中,但这并不影响「数据集成平台」的搭建,一些同步的需求可提前在「实时计算平台」创建,以「约定」的方式解耦。
值得一提的是「数据集成」也应当涵盖「数据采集」(由特定的工具支持) 和「数据清洗」(由采集粒度、日志规范等因素决定) 两部分内容,这两部分内容各个公司都有自己的实现,本文将不做详细介绍。
二、集成需求
目前伴鱼内部数据的集成需求主要体现在三块:Stat Log (业务标准化日志或称统计日志)、TiDB 及 MongoDB。除此之外还有一些 Service Log、Nginx Log 等,此类不具备代表性不在本文介绍。另外,由于实时数仓正处于建设过程中,目前「数据集成平台」只涵盖离线数仓 (Hive)。
Stat Log:业务落盘的日志将由 FileBeat 组件收集至 Kafka。由于日志为 Append Only 类型, 因此 Stat Log 集成相对简单,只需将 Kafka 数据同步至 Hive 即可。
DB (TiDB、MongoDB):DB 数据相对麻烦,核心诉求是数仓中能够存在业务数据库的镜像,即存在业务数据库中某一时刻(天级 or 小时级)的数据快照,当然有时也有对数据变更过程的分析需求。因此 DB 数据集成需要将这两个方面都考虑进去。
由于以上两种类型的数据集成方式差异较大,下文将分别予以讨论。
三、数据集成 V1
伴鱼早期「数据集成平台」已具备雏形,这个阶段主要是借助一系列开源的工具实现。随着时间推进,这个版本暴露的问题也逐渐增多,接下来将主要从数据流的角度对 V1 进行阐述,更多的细节问题将在 V2 版本的设计中体现。
3.1 Stat Log
日志的集成并未接入平台,而是烟囱式的开发方式,数据集成的链路如下图所示:

Kafka 中的数据先经过 Flume 同步至 HDFS,再由 Spark 任务将数据从 HDFS 导入至 Hive 并创建分区。整体链路较长且引入了第三方组件(Flume)增加了运维的成本,另外 Kafka 的原始数据在 HDFS 冗余存储也增加了存储的开销。
3.2 DB
DB 数据的集成主要是基于查询的方式(批的方式,通过 Select 查询进行全表扫描得到快照数据)实现,其链路如下图所示:

用户通过平台提交集成任务,由 Airflow 定时任务扫描集成平台元数据库,生成对应的取数任务 (TiDB 的数据通过 Sqoop 工具,MongoDB 的数据则通过 Mongoexport 工具)。可以看到 V1 版本并没有获取数据库的变更的日志数据,不能满足对数据变更过程的分析诉求。
由于 Sqoop 任务最终要从 TiDB 生产环境的业务数据库获取数据,数据量大的情况下势必对业务数据库造成一定的影响。Mongoexport 任务直接作用在 MongoDB 的隐藏节点 (无业务数据请求),对于线上业务的影响可以忽略不计。基于此,DBA 单独搭建了一套 TiDB 大数据集群,用于将体量较大的业务数据库同步至此 (基于 TiDB Pump 和 Drainer 组件),因此部分 Sqoop 任务可以从此集群拉群数据以消除对业务数据库的影响。从数据流的角度,整个过程如下图所示:
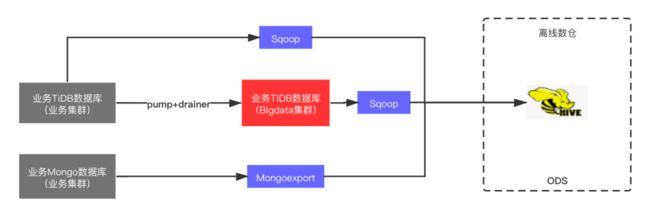
是否将生产环境 TiDB 业务数据库同步至 TiDB 大数据集群由数仓的需求以及 DBA 对于数据量评估决定。可以看出,这种形式也存在着大量数据的冗余,集群的资源随着同步任务的增加时长达到瓶颈。并且随着后续的演进,TiDB 大数据集群也涵盖一部分数据应用生产环境的业务数据库,集群作用域逐渐模糊。
四、数据集成 V2
V2 版本我们引入了 Flink,将同步的链路进行了简化,DB 数据集成从之前的基于查询的方式改成了基于日志的方式 (流的方式),大大降低了冗余的存储。
4.1 Stat Log
借助 Flink 1.11 版本后对于 Hive Integration 的支持,我们可以轻松的将 Kafka 的数据写入 Hive,因此 Stat Log 的集成也就变得异常简单 (相比 V1 版本,去除了对 Flume 组件的依赖,数据冗余也消除了),同时 Flink Exactly-Once 的语义也确保了数据的准确性。从数据流的角度,整个过程如下图所示:
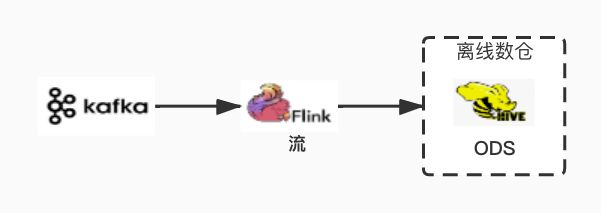
目前按照小时粒度生成日志分区,几项 Flink 任务配置参数如下:
checkpoint: 10 min
watermark: 1 min
partition.time-extractor.kind: ‘custom’
sink.partition-commit.delay: ‘3600s’
sink.partition-commit.policy.kind: ‘metastore,success-file’
sink.partition-commit.trigger: ‘partition-time’
4.2 DB
基于日志的方式对 DB 数据进行集成,意味着需要采集 DB 的日志数据,在我们目前的实现中 TiDB 基于 Pump 和 Drainer 组件(目前生产环境数据库集群版本暂不支持开启 TICDC),MongoDB 基于 MongoShake 组件,采集的数据将输送至 Kafka。
采用这种方式,一方面降低了业务数据库的查询压力,另一方面可以捕捉数据的变更过程,同时冗余的数据存储也消除了。不过由于原始数据是日志数据,需要通过一定的手段还原出快照数据。新的链路如下图所示:
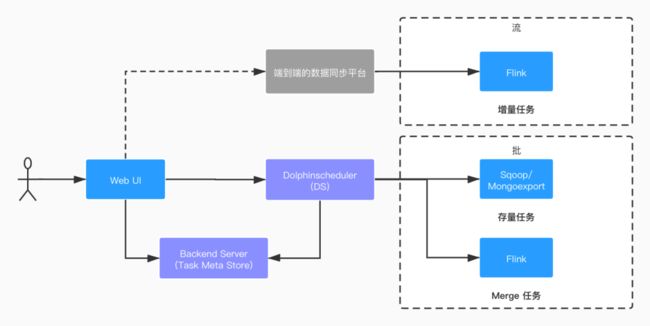
用户提交集成任务后将同步创建三个任务:
增量任务 (流):「增量任务」将 DB 日志数据由 Kafka 同步至 Hive。由于采集组件都是按照集群粒度进行采集,且集群数量有限,目前都是手动的方式将同步的任务在「实时计算平台」创建,集成任务创建时默认假定同步任务已经 ready,待「数据同步平台」落地后可以同步做更多的自动化操作和校验。
存量任务 (批):要想还原出快照数据则至少需要一份初始的快照数据,因此「存量任务」的目的是从业务数据库拉取集成时数据的初始快照数据。
Merge 任务 (批):「Merge 任务」将存量数据和增量数据进行聚合以还原快照数据。还原后的快照数据可作为下一日的存量,因此「存量任务」只需调度执行一次,获取初始快照数据即可。
「存量任务」和「Merge 任务」由离线调度平台 Dolphinscheduler (简称 DS) 调度执行,任务执行过程中将从集成任务的元数据库中获取所需的信息。目前「Merge 任务」按小时粒度调度,即每小时还原快照数据。
从数据流的角度,整个过程如下图所示:
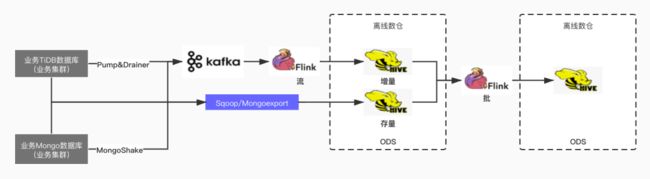
DB 的数据集成相较于 Stat Log 复杂性高,接下来以 TiDB 的数据集成为例讲述设计过程中的一些要点 (MongoDB 流程类似,区别在于存量同步工具及数据解析)。
■ 4.2.1 需求表达
对于用户而言,集成任务需要提供以下两类信息:
TiDB 源信息:包括集群、库、表。
集成方式:集成方式表示的是快照数据的聚合粒度,包括全量和增量。全量表示需要将存量的快照数据与今日的增量日志数据聚合,而增量表示只需要将今日的增量日志数据聚合 (即便增量方式无需和存量的快照数据聚合,但初始存量的获取依旧是有必要的,具体的使用形式由数仓人员自行决定)。
■ 4.2.2 存量任务
存量任务虽然有且仅执行一次,但为了完全消除数据集成对业务数据库的影响,我们选择数据库的备份-恢复机制来实现。公司内部数据库的备份和恢复操作已经平台化,集群将定期进行备份 (天粒度),通过平台可以查询到集群的最新备份,并且可由接口触发备份恢复操作,故存量的获取可直接作用于恢复的数据库。
由于数据库备份的时间点与集成任务提交的时间点并不一定是同一天,这之间存在着一定的时间差将导致存量快照数据不符合我们的预期,各时间点的关系如下图所示:
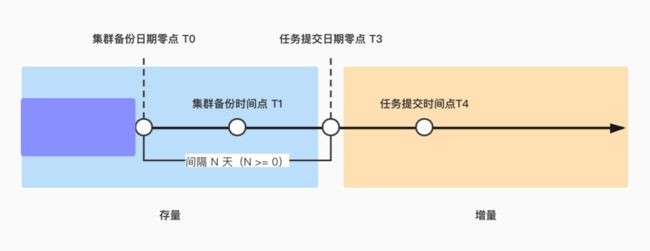
按照我们的设定,存量快照数据应当是包含 T4 之前的全部数据,而实际备份的快照数据仅包含 T1 之前的全部数据,这之间存在这 N 天的数据差。
注:这里之所以不说数据差集为 T1 至 T4 区间的数据,是因为增量的 Binlog 数据是以整点为分区的,在 Merge 的时候也是将整点的分区数据与存量数据进行聚合,并支持了数据去重。因此 T1 时刻的存量数据与 T0-T3 之间的增量数据的 Merge 结果等效于 T0 时刻的存量数据与 T0-T3 之间的增量数据的 Merge 结果。所以 T1 至 T4 的数据差集等效 T0 至 T3 的数据差集,即图示中的 N 天数据。
对于缺失的这部分数据实则是可以在「存量任务」中进行补全,仔细分析这其实是可以通过执行的 「Merge 任务」的补数操作实现。
整个「存量任务」的工作流如下图所示:
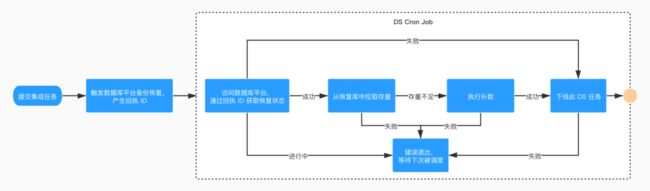
同步触发数据库平台进行备份恢复,产生回执 ID;
通过回执 ID 轮训备份恢复状态,恢复失败需要 DBA 定位异常,故将下线整个工作流,待恢复成功可在平台重新恢复执行「存量任务」。恢复进行中,工作流直接退出,借助 DS 定时调度等待下次唤醒。恢复成功,进入后续逻辑;
从恢复库中拉取存量,判定存量是否存在数据差,若存在则执行 Merge 任务的补数操作,整个操作可幂等执行,如若失败退出此次工作流,等待下次调度;
成功,下线整个工作流,任务完成。
■ 4.2.3 Merge 任务
Merge 任务的前提是存量数据与增量数据都已经 ready,我们通过 _SUCCESS 文件进行标记。整个「Merge 任务」的工作流如下图所示:
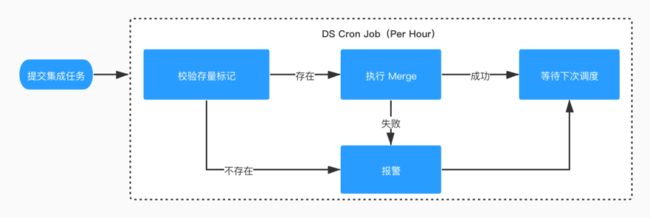
校验文件标记是否存在,若不存在说明数据未 ready ,进行报警并退出工作流等待下次调度;
执行 Merge 操作,失败报警并退出工作流等待下次调度;
成功,退出工作流等待下次调度。
Merge 操作通过 Flink DataSet API 实现。核心逻辑如下:
加载存量、增量数据,统一数据格式(核心字段:主键 Key 作为同一条数据的聚合字段;CommitTs 标识 binlog 的提交时间,存量数据默认为 0 早于增量数据;OpType 标识数据操作类型,包括:Insert、Update、Delete,存量数据默认为 Insert 类型),将两份数据进行 union;
按照主键聚合;
保留聚合后 CommitTs 最大的数据条目,其余丢弃;
过滤 OpType 为 Delete 类型的数据条目;
输出聚合结果。
核心代码:
allMergedData.groupBy(x -> x.getKeyCols())
.reduce(new ReduceFunction() {
public MergeTransform reduce(MergeTransform value1, MergeTransform value2) throws Exception {
if (value1.getCommitTS() > value2.getCommitTS()){
return value1;
}
return value2;
}
})
.filter(new FilterFunction() { //增量:过滤掉 op=delete
public boolean filter(MergeTransform merge) throws Exception {
if (merge.getOpType().equals(OPType.DELETE)){
return false;
}
return true;
}
})
.map(x -> x.getHiveColsText())
.writeAsText(outPath); 主要思想为「后来者居上」,针对于 Insert、Update 操作,最新值直接覆盖旧值,针对 Delete 操作,直接丢弃。这种方式也天然的实现了数据去重操作。
■ 4.2.4 容错性与数据一致性保证
我们大体可以从三个任务故障场景下的处理方式来验证方案的容错性。
「存量任务」异常失败:通常是备份恢复失败导致,DS 任务将发送失败报警,因「数据库平台」暂不支持恢复重试,需人工介入处理。同时「Merge 任务」检测不到存量的 _SUCCESS 标记,工作流不会向后推进。
「增量任务」异常失败:Flink 自身的容错机制以及「实时计算平台」的外部检测机制保障「增量任务」的容错性。若在「Merge 任务」调度执行期间「增量任务」尚未恢复,将误以为该小时无增量数据跳过执行,此时相当于快照更新延迟(Merge 是将全天的增量数据与存量聚合,在之后的调度时间点如果「增量任务」恢复又可以聚合得到最新的快照),或者在「增量任务」恢复后可人为触发「Merge 任务」补数。
「Merge 任务」异常失败:任务具有幂等性,通过设置 DS 任务失败后的重试机制保障容错性,同时发送失败报警。
以上,通过自动恢复机制和报警机制确保了整个工作流的正确执行。接下来我们可以从数据的角度看一下方案对于一致性的保障。
数据的一致性体现在 Merge 操作。两份数据聚合,从代码层面一定可以确保算法的正确性 (这是可验证的、可测试的),那么唯一可能导致数据不一致的情况出现在两份输入的数据上,即存量和增量,存在两种情况:
存量和增量数据有交叠:体现在初始存量与整点的增量数据聚合场景,由于算法天然的去重性可以保证数据的一致。
存量和增量数据有缺失:体现在增量数据的缺失上,而增量数据是由 Flink 将 Kafka 数据写入 Hive 的,这个过程中是有一定的可能性造成数据的不一致,即分区提交后的乱序数据。虽然说乱序数据到来后的下一次 checkpoint 时间点分区将再次提交,但下游任务一般是检测到首次分区提交就会触发执行,造成下游任务的数据不一致。
针对 Flink 流式写 Hive 过程中的乱序数据处理可以采取两种手段:
一是 Kafka 设置单分区,多分区是产生导致乱序的根因,通过避免多分区消除数据乱序。
二是报警补偿,乱序一旦产生流式任务是无法完全避免的 (可通过 watermark 设置乱序容忍时间,但终有一个界限),那么只能通过报警做事后补偿。
问题转换成了如何感知到乱序,我们可以进一步分析,既然乱序数据会触发前一个分区的二次提交,那么只需要在提交分区的时候检测前一个分区是否存在 _SUCCESS 标记便可以知晓是否是乱序数据以及触发报警。
五、线上效果
总览
存量任务
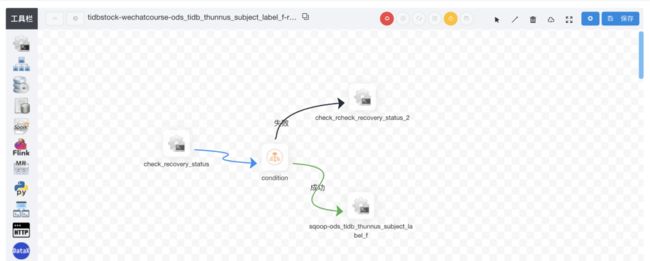
Merge 任务
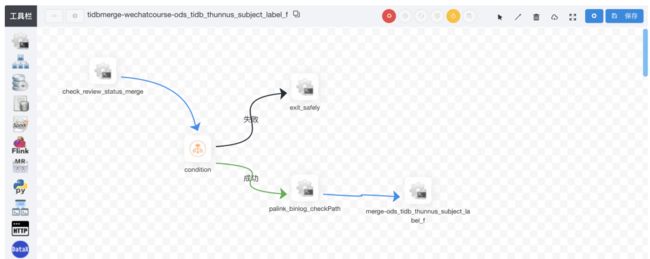
六、总结
本文阐述了伴鱼「数据集成平台」核心设计思路,整个方案还有一些细节未在文章中体现,如数据 Schema 的变更、DB 日志数据的解析等,这些细节对于平台构建也至关重要。目前伴鱼绝大部分的集成任务已切换至新的方式并稳定运行。我们也正在推进实时数仓集成任务的接入,以提供更统一的体验。
近期热点
Flink Forward Asia 2021 延期,线上相见
奖金翻倍!Flink Forward Asia Hackathon 最新参赛指南请查收

更多 Flink 相关技术问题,可扫码加入社区钉钉交流群~

 戳我,查看更多技术干货~
戳我,查看更多技术干货~