SQL Server数据库 -- 索引与视图

文章目录
- 一、索引
- 聚集索引
- 非聚集索引
- 二、视图
- 三、自定义函数
- 标量函数
- 表值函数
- 四、游标
- 五、总结
前言
在学习完创建库表、查询等知识点后,为了更加方便优化数据库的存储和内容,我们需要学习一系列的方法例如索引与视图等等,从而使我们更加熟练和使用数据库,突破表面,触摸内部!
一、索引
1、索引简介
索引是加快数据查询效率的一种有效方法,因为建立索引可以改变数据的搜索结构。多数情况下索引是建立在基础表上的,但也可以建立在视图上。
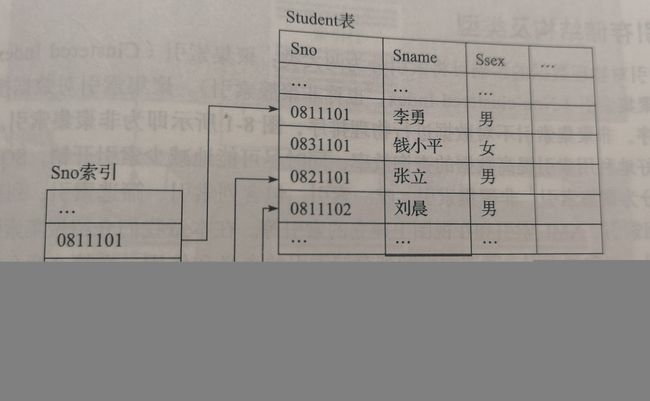
在数据库中建立索引是为了提高数据的查询速度,与书本前面的目录或书后面的术语表类似。利用目录或属于快速查找所需信息,而无需翻阅整本书。
但是使用索引也是有代价的:
首先,索引在数据库中占有一定的存储空间。其次,在对数据进行插入、修改、删除操作时,为了使索引与数据保持一致,还需要对索引进行相应的维护,而维护是需要时间成本的。
2、聚集索引
聚集索引对数据按索引关键词进行物理排序,像一颗B树(平衡树)一样,最上层结点和中间层结点放置索引页码编号范围,最下层才放置数据。从上往下查找,直至找到相同的页码编号。
例如下图所示:
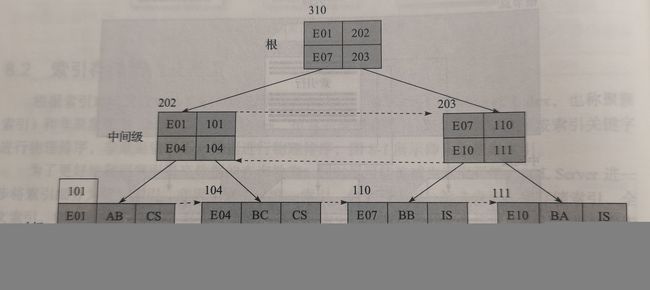
例如:查找E08的所有信息
解析:首先看顶层,如果比E07小则选择左边,和E07相等或者大于E07则选择右边。E08比EE07大则看向右边!以此类推,E08比E10小则选择左边,最终看向E08所对应的所有信息!
聚集索引的关键词:clustered index,用于给什么表的什么字段创建添加索引
现有学生表如下:
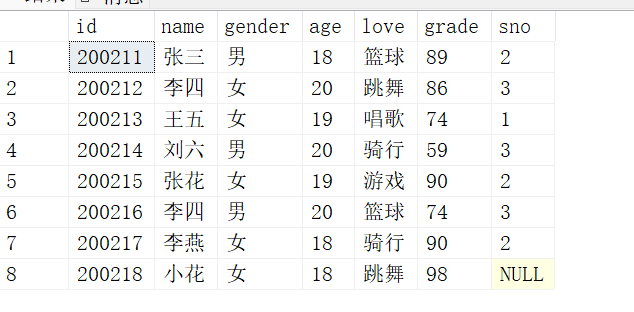
当创建表时有主键时会自动创建一个聚集索引,因此一般不需要我们再去创建聚集索引,
并且要求聚集索引只能由一个。
1.创建聚集索引
给student表中的id字段添加聚集索引
create clustered index index_id
on student(id)2.查看聚集索引
select *from sys.indexes where name = 'index_id'3.删除聚集索引
drop index index_id on student3、非聚集索引
非聚集索引与书本后面的术语表差不多,但非聚集索引不对数据进行物理排序,并且非聚集索引的最后一层结点并不放数据。非聚集索引是可以定义多个的,SQL Server2017最多允许在一个表上建立999个非聚集索引。
非聚集索引关键字:nonclustered index
1.创建非聚集索引
给student表中的id字段添加一个非聚集聚集索引index_id
create nonclustered index index_id
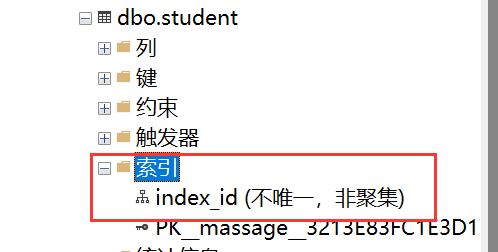
on student(id)2.查看非聚集索引
select *from sys.indexes where name = 'index_id'
3.删除非聚集索引
drop index index_id on student4、聚集索引与非聚集索引的区别
1、聚集索引按索引关键字进行物理排序,非聚集索引不对数据 进行物理排序。
2、聚集索引最后一层结点存放数据,非聚集索引最后一层结点不放置数据。
二、视图
1、视图简介
视图是从数据库的基本表中选取出来的数据组成的逻辑窗口,是基本表部分行、部分列数据的组合。与基本表不同的是,视图是一个虚表,数据库中只存储视图的定义,而不存储视图的数据,这些数据仍存放在原来的基本表中。
使用视图的好处:
1、视图数据会始终与基本表数据保持一致。
2、节省存储空间。当数据量非常大时,重复存储数据是非常耗费空间的。
2、视图语句
现有学生表如下:
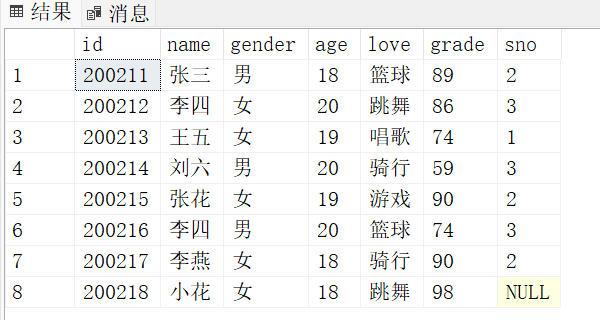
对上面的学生表进行操作!
1.创建视图
建立年龄在十八岁以上学生的学号、姓名、年龄的视图
create view is_student
as
select id,name,age from student
where age>182.查看视图
select *from is_student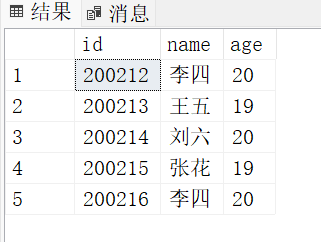
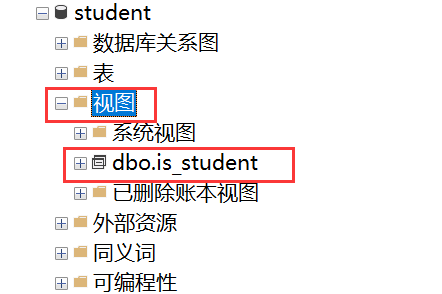
3.删除视图
drop view is_student三、自定义函数
用户自定义函数可以扩展数据操作的功能,在概念上类似于一般的程序设计语言函数中定义的函数。SQL Server支持两类用户定义函数:标量函数和表值函数。标量函数只返回单个数据值,而表值函数是返回一个表。函数关键词:function
1、标量函数
当调用标量函数时,必须提供最少由两部分组成的名称:函数所属架构名和函数名。只要类型一致,可在任何允许出现表达的SQL语句中调用标量函数。
现有学生表student如下:
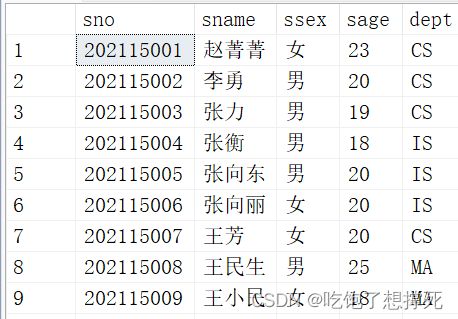
1.创建标量函数
创建查询指定学生(学号)的所在系名称的标量函数 -> 输入学号得到学生所在系
create function myself(@sno char(9))
returns char(2)
as
begin
return (select dept from student where sno = @sno)
end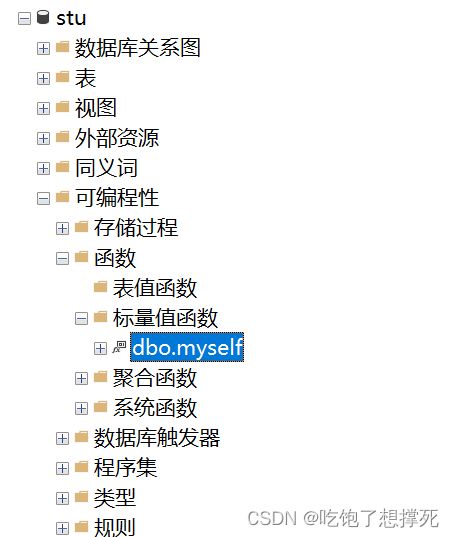
2.调用标量函数
查询学生学号为:202115005所在系名称
select dbo.myself(202115005)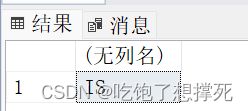
3.删除标量函数
删除标量函数myself
drop function dbo.myself2、表值函数
表值函数的使用方法与视图非常类似,需要将其放置在查询语句的from子句部分,其作用类似于带参数的视图。
现有学生表student如下:
1.创建表值函数
创建查询指定系的学生学号、姓名、性别和年龄 -> 输入系得到所有系内的学生信息
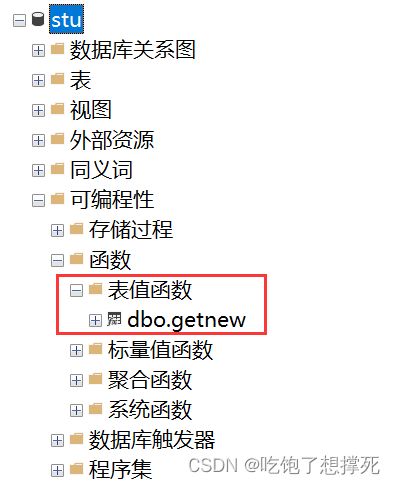
create function getnew(@dept char(2))
returns table
as
return(
select *from student
where dept = @dept
)
2.调用表值函数
查询CS系的所有学生信息
select *from dbo.getnew('CS')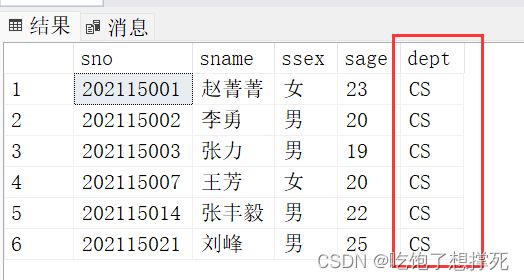
3.删除表值函数
drop function dbo.getnew四、游标
由select语句返回的行集中包括所有满足条件子句的行,这一完整的行集被称为结果集。但有时候用户需要对结果集中的每一行或部分行进行单独的处理,而这在select结果集中无法实现。游标就是提供上述机制的结果集扩展,我们可以使用游标逐行处理结果集。游标的关键词为:cursor
1、游标的组成及特点
游标由两部分组成:游标结果集 和 游标当前行指针
游标具有如下特点:
1、允许定位结果集中的特定行
2、允许从结果集的当前位置检索一行或多行
3、支持对结果集中当前行数据的修改
4、为其他用户对显示在结果集中的数据的更改提供不同级别的可见性支持
现有学生表student如下:
2、游标的用法
定义查询姓 ”王“的学生的姓名和所在系的游标,并输出游标结果
1.创建游标
declare @sname char(10),@dept varchar(20)-- 声明存放结果集数据的变量
declare s1 cursor for --创建游标
select sname,dept from student
where sname like '王%'2.打开游标
open s13.提取行数据
fetch next from s1 into @sname,@dept --首先提取第一行数据
while @@FETCH_STATUS = 0 --通过检查判断是否还有可读取的值
begin
print
@sname + @dept
fetch next from s1 into @sname,@dept --提取下一行数据
end4.关闭和删除游标
close s1 --关闭游标
deallocate s1 --删除游标整体代码如下:
declare @sname char(10),@dept varchar(20)-- 声明存放结果集数据的变量
declare s1 cursor for --创建游标
select sname,dept from student
where sname like '王%'
open s1
fetch next from s1 into @sname,@dept --首先提取第一行数据
while @@FETCH_STATUS = 0 --通过检查判断是否还有可读取的值
begin
print
@sname + @dept
fetch next from s1 into @sname,@dept --提取下一行数据
end
close s1 --关闭游标
deallocate s1 --删除游标运行结果如下:

五、总结
本次主要介绍了索引与视图、函数和游标。各自的关键词分别为:index、view、function、cursor。它们都是为了方便和简化数据库的操作,索引是为了加快查询效率,视图是为了节省空间、函数能够根据输入显示输出结果、游标能够获取特定行数据。
它们都是可以创建使用和删除的,灵活运用这些额外功能能够很大程度提高效率和空间,也是数据库进阶的必经之路,本次也只是简单列举了如何使用它们,更多复杂的功能还得继续往下学。
如果这篇文章能够帮助到你,还请点个小赞支持一下!!!