Python---pyspark:RDD中数据计算成员方法(map方法、flatMap方法、reduceByKey方法、filter方法、distinct方法、sortBy方法)
1. map算子
接受一个处理函数,可用lambda表达式快速编写,对RDD内的元素逐个处理,并返回一个新的RDD
注意:对于返回值是新RDD的算子,可以通过链式调用的方式多次调用算子。
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 准备一个RDD
rdd = sc.parallelize([1, 2, 3, 4, 5])
# 通过map方法将全部数据都乘以10
# def func(data):
# return data * 10
rdd2 = rdd.map(lambda x: x * 10).map(lambda x: x + 5)
print(rdd2.collect())
# (T) -> U
# (T) -> T
# 链式调用2. flatMap算子
计算逻辑和map一样,可以比map多出,解除一层嵌套的功能
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 准备一个RDD
rdd = sc.parallelize(["女帝 幻音坊 36", "姬如雪 幻音坊 36", "陆林轩 天师府"])
# 需求,将RDD数据里面的一个个单词提取出来
rdd2 = rdd.flatMap(lambda x: x.split(" "))
print(rdd2.collect())
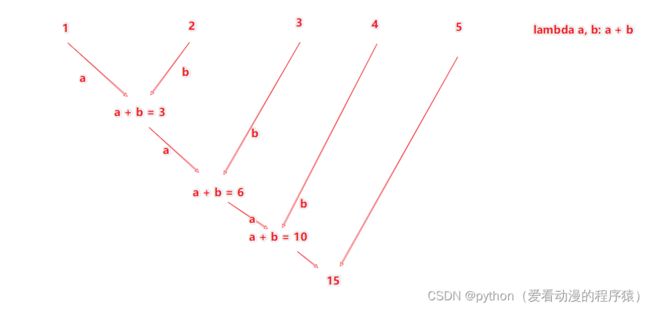
3. reduceByKey算子
![]()
接受一个处理函数,对数据进行两两计算
注意:reduceByKey中接受的函数,只负责聚合,不理会分组
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 准备一个RDD
rdd = sc.parallelize([('男', 99), ('男', 88), ('女', 99), ('女', 66)])
# 求男生和女生两个组的成绩之和
rdd2 = rdd.reduceByKey(lambda a, b: a + b)
print(rdd2.collect())
4. filter算子
接受一个处理函数,可用lambda快速编写,函数对RDD数据逐个处理,得到True的保留至返回值的RDD中,过滤想要的数据进行保留。
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 准备一个RDD
rdd = sc.parallelize([1, 2, 3, 4, 5])
# 对RDD的数据进行过滤
rdd2 = rdd.filter(lambda num: num % 2 == 0)
print(rdd2.collect())
5. distinct算子
完成对RDD内数据的去重操作
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 准备一个RDD
rdd = sc.parallelize([1, 1, 3, 3, 5, 5, 7, 8, 8, 9, 10])
# 对RDD的数据进行去重
rdd2 = rdd.distinct()
print(rdd2.collect())6. sortBy算子
接收一个处理函数,可用lambda快速编写,函数表示用来决定排序的依据,可以控制升序或降序,全局排序需要设置分区数为1
from pyspark import SparkConf, SparkContext
import os
os.environ['PYSPARK_PYTHON'] = "D:/dev/python/python310/python.exe"
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf=conf)
# 1. 读取数据文件
rdd = sc.textFile("D:/hello.txt")
# 2. 取出全部单词
word_rdd = rdd.flatMap(lambda x: x.split(" "))
# 3. 将所有单词都转换成二元元组,单词为Key,value设置为1
word_with_one_rdd = word_rdd.map(lambda word: (word, 1))
# 4. 分组并求和
result_rdd = word_with_one_rdd.reduceByKey(lambda a, b: a + b)
# 5. 对结果进行排序
final_rdd = result_rdd.sortBy(lambda x: x[1], ascending=True, numPartitions=1)
print(final_rdd.collect())
(日常美图时间)
