动力节点最新Redis7笔记-第七章Redis缓存
7 Redis缓存
7.1 Jedis客户端
7.1.1 Jedis简介
Jedis是一个基于java的Redis客户端连接工具,旨在提升性能与易用性。
7.1.2 创建工程
首先创建一个普通的Maven工程01-jedis,然后在POM文件中添加Jedis与Junit依赖。
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<!--jedis依赖-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>4.2.0</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
</dependencies>
7.1.3 使用Jedis实例
Jedis基本使用十分简单,其提供了非常丰富的操作Redis的方法,而这些方法名几乎与Redis命令相同。在每次使用时直接创建Jedis实例即可。在Jedis实例创建好之后,Jedis底层实际会创建一个到指定Redis服务器的Socket连接。所以,为了节省系统资源与网络带宽,在每次使用完Jedis实例之后,需要立即调用close()方法将连接关闭。
首先,需要在工程的src/test/java下创建测试类JedisTest。
7.1.3.1 value为String的测试

7.1.3.2 value为Hash的测试

7.1.3.3 value为List的测试

7.1.3.4 value为Set的测试

7.1.3.5 value为ZSet的测试

7.1.4 使用JedisPool
如果应用非常频繁地创建和销毁Jedis实例,虽然节省了系统资源与网络带宽,但会大大降低系统性能。因为创建和销毁Socket连接是比较耗时的。此时可以使用Jedis连接池来解决该问题。
使用JedisPool与使用Jedis实例的区别是,JedisPool是全局性的,整个类只需创建一次即可,然后每次需要操作Redis时,只需从JedisPool中拿出一个Jedis实例直接使用即可。使用完毕后,无需释放Jedis实例,只需返回JedisPool即可。

7.1.5 使用JedisPooled
对于每次对Redis的操作都需要使用try-with-resource块是比较麻烦的,而使用JedisPooled则无需再使用该结构来自动释放资源了。

7.1.6 连接Sentinel高可用集群
对于Sentinel高可用集群的连接,直接使用JedisSentinelPool即可。在该客户端只需注册所有Sentinel节点及其监控的Master的名称即可,无需出现master-slave的任何地址信息。其采用的也是JedisPool,使用完毕的Jedis也需要通过close()方法将其返回给连接池。

7.1.7 连接分布式系统
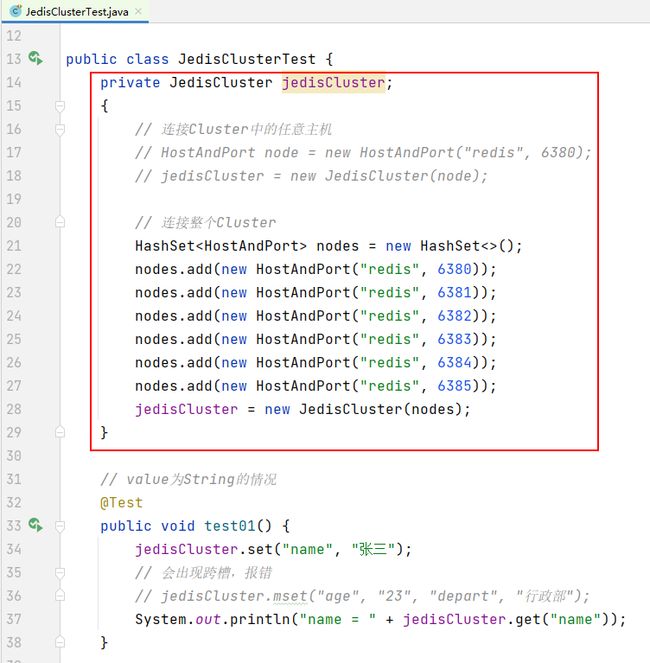
对于Redis的分布式系统的连接,直接使用JedisCluster即可。其底层采用的也是Jedis连接池技术。每次使用完毕后,无需显式关闭,其会自动关闭。
对于JedisCluster常用的构造器有两个。一个是只需一个集群节点的构造器,这个节点可以是集群中的任意节点,只要连接上了该节点,就连接上了整个集群。但该构造器存在一个风险:其指定的这个节点在连接之前恰好宕机,那么该客户端将无法连接上集群。所以,推荐使用第二个构造器,即将集群中所有节点全部罗列出来。这样就会避免这种风险了。
7.1.8 操作事务
对于Redis事务的操作,Jedis提供了multi()、watch()、unwatch()方法来对应Redis中的multi、watch、unwatch命令。Jedis的multi()方法返回一个Transaction对象,其exec()与discard()方法用于执行和取消事务的执行。
7.1.8.1 抛出Java异常
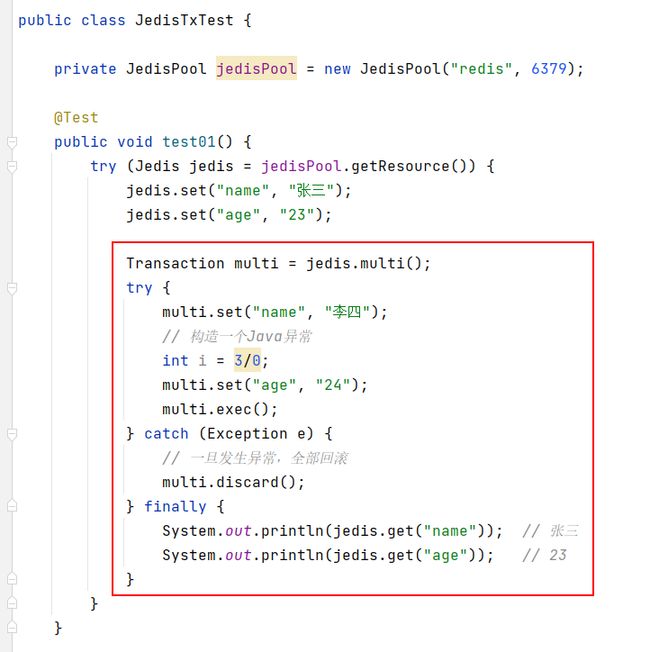
其输出结果为全部回滚的结果。
7.1.8.2 让Redis异常
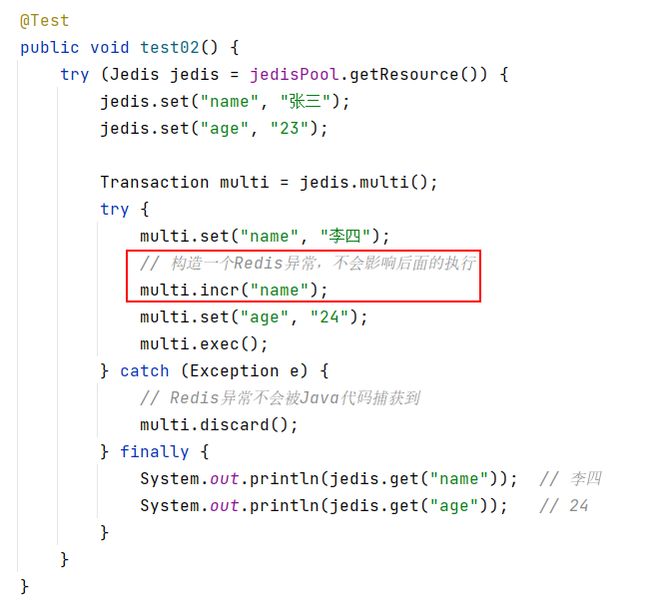
其输出结果为修改过的值。说明Redis运行时抛出的异常不会被Java代码捕获到,其不会影响Java代码的执行。

7.1.8.3 watch()

7.2 金融产品交易平台
7.2.1 Spring Boot整合Redis
7.2.2 Redis操作模板
Spring Boot中可以直接使用Jedis实现对Redis的操作,但一般不这样用,而是使用Redis操作模板RedisTemplate类的实例来操作Redis。
RedisTemplate类是一个对Redis进行操作的模板类。该模板类中具有很多方法,这些方法很多与Redis操作命令同名或类似。例如,delete()、keys()、scan(),还有事务相关的multi()、exec()、discard()、watch()等。当然还有获取对各种Value类型进行操作的操作实例的两类方法boundXxxOps(k)与opsForXxx()。
7.2.3 需求
下面通过一个例子来说明Spring Boot是如何与Redis进行整合的。
对于一个资深成熟的金融产品交易平台,其用户端首页一般会展示其最新金融产品列表,同时还为用户提供了产品查询功能。另外,为了显示平台的实力与信誉,在平台首页非常显眼的位置还会展示平台已完成的总交易额与注册用户数量。对于管理端,管理员可通过管理页面修改产品、上架新产品、下架老产品。
为了方便了解Redis与Spring Boot的整合流程,这里对系统进行了简化:用户端首页仅提供根据金融产品名称的查询,显眼位置仅展示交易总额。管理端仅实现上架新产品功能。
7.2.4 创建SSM工程
7.2.4.1 创建工程
定义一个Spring Boot工程,并命名为ssm。
7.2.4.2 定义pom文件
在pom文件中需要导入MySQL驱动、Druid等大量依赖。POM文件中的重要内容如下:
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.3.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency> <dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.12</version>
</dependency> <dependency>
<groupId>org.apache.tomcat.embed</groupId>
<artifactId>tomcat-embed-jasper</artifactId>
</dependency> <dependency>
<groupId>javax.servlet</groupId>
<artifactId>jstl</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<resources> <resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.xml
src/main/webapp
META-INF/resources
**/ *.*</include>
</includes>
</resource>
</resources>
</build>
7.2.4.3 修改主配置文件
在主配置文件中配置MyBatis、Spring、日志等配置:

7.2.4.4 实体类Product

| 平台交易总额,即“产品募集结束日期”小于“当前查询日期”的“产品募集总额”之和。 |
|---|
7.2.4.5 创建数据库表
在test数据库中创建一个名称为product的表。创建的sql文件如下,直接运行该文件即可。
DROP TABLE IF EXISTS `product`;CREATE TABLE `product` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`rate` double DEFAULT NULL,
`amount` double DEFAULT NULL,
`raised` double DEFAULT NULL,
`cycle` int(11) DEFAULT NULL,
`endTime` char(10) DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8;
INSERT INTO `product` VALUES (1,'天鑫添益2',2.76,50000,20000,30,'2022-07-10'),(2,'国泰添益',2.86,30000,30000,60,'2022-07-12'),(3,'国泰高鑫',2.55,60000,50000,90,'2022-07-09'),(4,'国福民安',2.96,30000,20000,7,'2022-05-10'),(5,'天益鑫多',2.65,80000,60000,20,'2022-07-05'),(6,'惠农收益',3.05,30000,20000,10,'2022-06-10'),(7,'惠农三鑫',2.76,50000,30000,30,'2022-07-02'),(8,'励学收益',2.86,30000,20000,20,'2022-07-11');
7.2.4.6 定义index.jsp
在src/main下创建webapp目录,用于存放jsp文件。这就是一个普通的目录,无需执行Mark Directory As。在webapp目录中创建一个index.jsp文件。
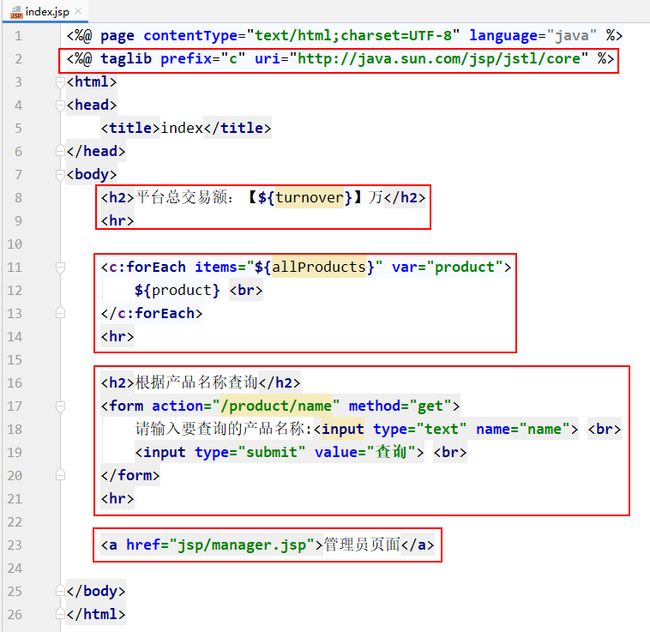
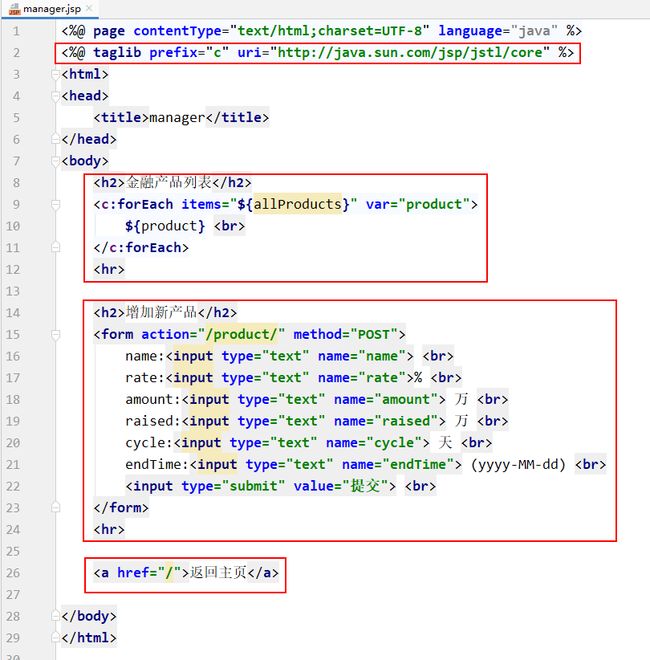
7.2.4.7 定义manager.jsp
在webapp目录下再创建一个jsp子目录,在其中定义manager.jsp。
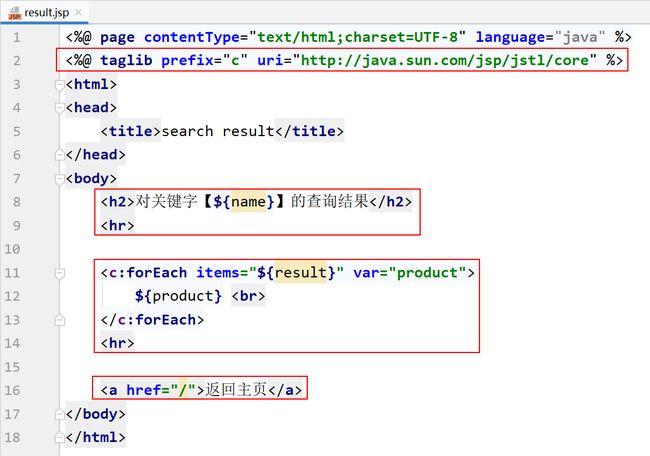
7.2.4.8 定义result.jsp
在webapp/jsp中定义result.jsp。
7.2.4.9 ProductController类
7.2.4.9.1 indexHandle()

7.2.4.9.2 registerHandle()

7.2.4.9.3 listHandle()

7.2.4.10 ProductService接口

7.2.4.11 ProductServiceImpl类
7.2.4.11.1 saveProduct()

7.2.4.11.2 三个find方法
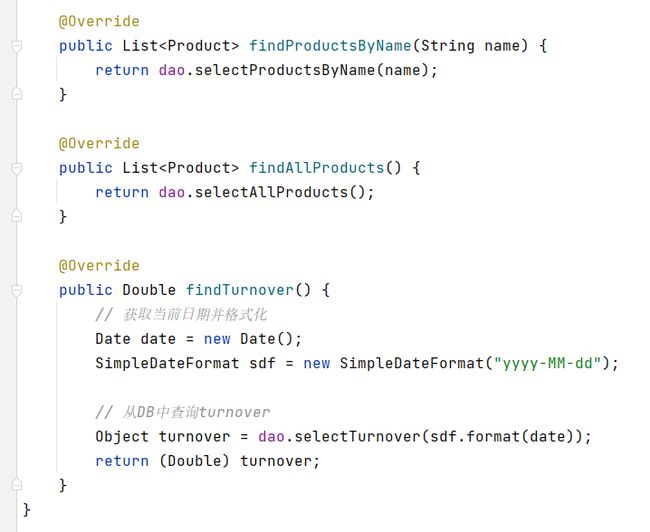
7.2.4.12 ProductDao接口
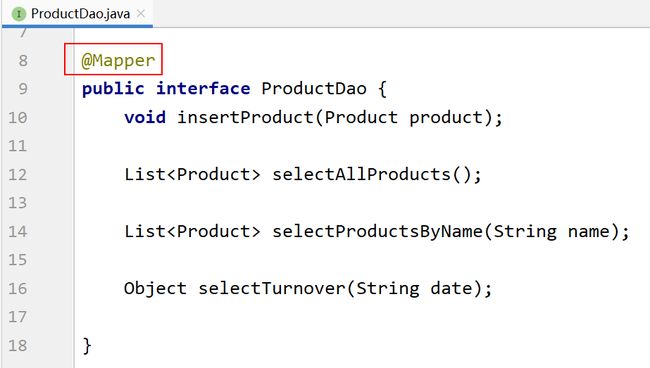
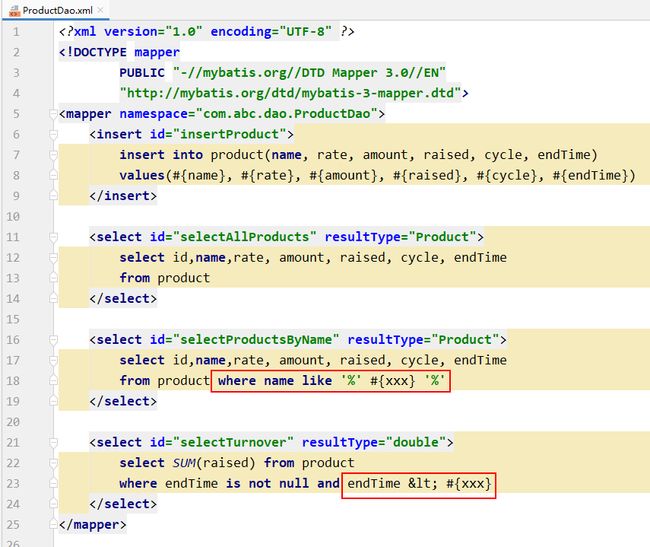
7.2.4.13 映射文件
7.2.4.14 Application启动类

7.2.5 创建SSRM工程
7.2.5.1 创建工程
复制ssm工程,并重命名为springboot-redis。
7.2.5.2 修改pom文件
在pom文件中添加Spring Boot与Redis整合依赖。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
7.2.5.3 修改配置文件
在配置文件中增加Redis及缓存相关配置。

7.2.5.4 修改Product实体类
由于要将查询的实体类对象缓存到Redis,Redis要求实体类必须序列化。所以需要实体类实现序列化接口。

7.2.5.5 修改ProductServiceImpl类
7.2.5.5.1 修改saveProduct()

@CacheEvict用于实现value指定缓存空间中缓存数据的清空。allEntries为true指定清空该缓存空间所有数据。如果不想清空所有,则需通过key属性指定要清理的key数据。
7.2.5.5.2 修改两个find方法

@Cacheable用于指定将查询结果使用指定的key缓存到指定缓存空间。如果再有对该查询数据的访问,则会先从缓存中查看。
7.2.5.5.3 修改findTurnover()

7.2.5.6 修改Application启动类
@EnableCaching用于开启当前应用的缓存功能。

7.2.6 总结
如何将Spring Boot与Redis整合?
- 在POM中导入依赖
- 在配置文件中注册Redis连接信息与缓存信息
- 需要缓存到Redis中的实体类必须要序列化
- Spring Boot启动类中要添加@EnableCaching注解
- 查询方法上要添加@Cacheable注解
- 对数据进行写操作的方法上添加@CacheEvict注解
- 对于需要手工操作Redis的方法,需通过RedisTemplate来获取操作对象
7.3 高并发问题
Redis做缓存虽减轻了DBMS的压力,减小了RT,但在高并发情况下也是可能会出现各种问题的。
7.3.1 缓存穿透
当用户访问的数据既不在缓存也不在数据库中时,就会导致每个用户查询都会“穿透”缓存“直抵”数据库。这种情况就称为缓存穿透。当高度发的访问请求到达时,缓存穿透不仅增加了响应时间,而且还会引发对DBMS的高并发查询,这种高并发查询很可能会导致DBMS的崩溃。
缓存穿透产生的主要原因有两个:一是在数据库中没有相应的查询结果,二是查询结果为空时,不对查询结果进行缓存。所以,针对以上两点,解决方案也有两个:
- 对非法请求进行限制
- 对结果为空的查询给出默认值
7.3.2 缓存击穿
对于某一个缓存,在高并发情况下若其访问量特别巨大,当该缓存的有效时限到达时,可能会出现大量的访问都要重建该缓存,即这些访问请求发现缓存中没有该数据,则立即到DBMS中进行查询,那么这就有可能会引发对DBMS的高并发查询,从而接导致DBMS的崩溃。这种情况称为缓存击穿,而该缓存数据称为热点数据。
对于缓存击穿的解决方案,较典型的是使用“双重检测锁”机制。
7.3.3 缓存雪崩
对于缓存中的数据,很多都是有过期时间的。若大量缓存的过期时间在同一很短的时间段内几乎同时到达,那么在高并发访问场景下就可能会引发对DBMS的高并发查询,而这将可能直接导致DBMS的崩溃。这种情况称为缓存雪崩。
对于缓存雪崩没有很直接的解决方案,最好的解决方案就是预防,即提前规划好缓存的过期时间。要么就是让缓存永久有效,当DB中数据发生变化时清除相应的缓存。如果DBMS采用的是分布式部署,则将热点数据均匀分布在不同数据库节点中,将可能到来的访问负载均衡开来。
7.3.4 数据库缓存双写不一致
以上三种情况都是针对高并发读场景中可能会出现的问题,而数据库缓存双写不一致问题,则是在高并发写场景下可能会出现的问题。
对于数据库缓存双写不一致问题,以下两种场景下均有可能会发生:
7.3.4.1 “修改DB更新缓存”场景
对于具有缓存warmup功能的系统,DBMS中常用数据的变更,都会引发缓存中相关数据的更新。在高并发写请求场景下,若多个请求要对DBMS中同一个数据进行修改,修改后还需要更新缓存中相关数据,那么就有可能会出现缓存与数据库中数据不一致的情况。

7.3.4.2 “修改DB删除缓存”场景
在很多系统中是没有缓存warmup功能的,为了保持缓存与数据库数据的一致性,一般都是在对数据库执行了写操作后,就会删除相应缓存。
在高并发读写请求场景下,若这些请求对DBMS中同一个数据的操作既包含写也包含读,且修改后还要删除缓存中相关数据,那么就有可能会出现缓存与数据库中数据不一致的情况。

7.3.4.3 解决方案:延迟双删
延迟双删方案是专门针对于“修改DB删除缓存”场景的解决方案。但该方案并不能彻底解决数据不一致的状况,其只可能降低发生数据不一致的概率。
延迟双删方案是指,在写操作完毕后会立即执行一次缓存的删除操作,然后再停上一段时间(一般为几秒)后再进行一次删除。而两次删除中间的间隔时长,要大于一次缓存写操作的时长。

7.3.4.4 解决方案:队列
以上两种场景中,只所以会出现数据库与缓存中数据不一致,主要是因为对请求的处理出现了并行。只要将请求写入到一个统一的队列,只有处理完一个请求后才可处理下一个请求,即使系统对用户请求的处理串行化,就可以完全解决数据不一致的问题。
7.3.4.5 解决方案:分布式锁
使用队列的串行化虽然可以解决数据库与缓存中数据不一致,但系统失去了并发性,降低了性能。使用分布式锁可以在不影响并发性的前提下,协调各处理线程间的关系,使数据库与缓存中的数据达成一致性。
只需要对数据库中的这个共享数据的访问通过分布式锁来协调对其的操作访问即可。