CTC介绍(connectionist temporal classification论文翻译)
1.摘要
我基本是基于论文《Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks 》进行翻译总结的。看论文题目就知道CTC与RNN密切相关,联系在一起的,以及应用于不分割(Unsegmented )序列,点对点预测。
在CTC(connectionist temporal classification)前,HMMs(隐马尔可夫模型hidden Markov Models)、CRFs(条件随机场模型conditional random fields)以及相关变体,是主要用来进行序列标注的方法。这些方法一是需要大量的目标识别知识,二是有一些假设条件,比如HMM的独立分布性假设,三是比如HMM,即使序列标准是不恰当的,也可以进行训练。
HMM-RNN模型,可以处理长序列结构的数据。但是其中HMM是自动分割序列,然后转换网络分类到标签序列,没有有效利用整个序列的特点。
CTC不需要预分割训练数据、后期加工的输出,直接作用于整个序列。CTC是把网络输出作为基于输入序列的所有可能标签序列的一个概率分布。
2.Temporal Classification
X:输入空间。m 维实数向量
Z:目标空间,Z=L*。基于标签的字母表L的序列集合。
L:L*中的(多个)元素是标签序列的来源。
S:基于固定的分布D(X,Z)获得的训练样本集。S中的每个样本是(x,z)。目标序列z = (z1, z2, …, zU ) ,输入序列x = (x1, x2, …, xT )。z 的长度U要小于x的长度T,即U<=T。也就是输入与目标的长度可以不一致。
h : X → Z的函数,该函数定义为temporal classification。
S`:属于固定的分布D(X,Z),但与S不相交的集合。
ED(p, q):p序列与q序列的编辑距离,即将p变成q所需要插入、替换、删除的最小数量。
下面是重点了, the label error rate (LER):指h(temporal classification)的LER, 定义为h生成的分类目标和其目标在S的编辑距离(ED),这句话我看着也饶,编辑距离是衡量两者之间的,但下面的公式却只写了一个参数。 Z is the total number of target labels in S.
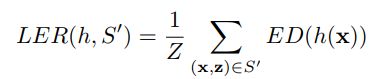
3.Connectionist Temporal Classification
本章描述如何将RNN的输出应用于CTC。
其中关键步骤是把网络的输出转换为基于标签序列的条件概率分布。然后网络就可以选择对于输入序列的最有可能的标签。
3.1 从网络输出到标签
X:网络输入,如上面所述,长度为T。X是m维。
y:网络输出,y是n维。w 是权重。N定义x->y 的带权重的函数。
![]()
![]()
![]() :定义为输出单元k在时刻t时的激活。也解释为观察标签k在时刻t的可能性(概率)
:定义为输出单元k在时刻t时的激活。也解释为观察标签k在时刻t的可能性(概率)
L` = L ∪ {blank}:多加了空白标签。
π: L`里面的元素。每个元素是一条路径

一条路径(循环网络有多条路径)的概率等于在各个时刻(共有T,长度)每个观察标签的概率积(比如预测序列是abc,等于a的概率b的概率c的概率),序列长度为T,概率相乘T次。其中是假设网络输出在不同时刻是条件独立的,

B:多对一函数,进行这个转换![]() 。论文采用简单的方法,去除空白和重复标签,比如B(a − ab−) = B(−aa − −abb) = aab.
。论文采用简单的方法,去除空白和重复标签,比如B(a − ab−) = B(−aa − −abb) = aab.
用B函数处理各条路径,那么最终的输入x到标签l的概率p(l|x)就是各个路径π的概率和。

3.2 构建Classifier
得到上面的公式后,我们就可以知道对于输入序列,输出的识别应该是取最高的概率,如下式。

但目前没找到好的方法计算上面公式。下面介绍两个近似的方法。
第一种方法(最佳路径法):认为最可能路径对应最可能得标签,即下面公式:

第二种方法是前缀查询法(prefix search decoding)。前缀的最大数量会随着输入序列长度的增长而指数级增长,尤其是当输出分布是尖峰状时,其很难在合理的时间能计算出来。但是我们找到一个启发式的方法。
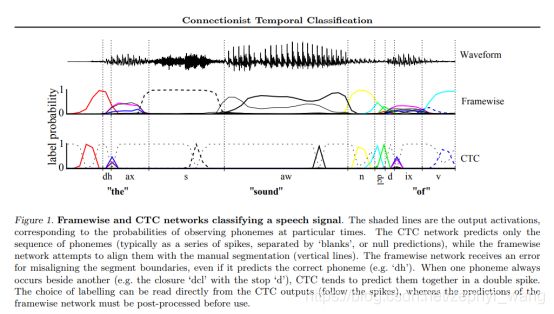
下图是前缀方法,可以看图片中的文字。

启发式的方法是来源于下图的提醒,CTC的网络输出形成了一系列被可以预见的空白分割的尖峰。我们就用这些空白分割输出,形成一段段好像有开始到结束的片段们。当然空白标签的选择是基于一定的概率阈值的。然后我们独立计算这些片段的最可能标签,最后把他们连接在一起合成最终的标签。
实际上,前缀查询方法在这种启发式方法下运行的非常好,并且优于最佳路径法。但是该方法在某些情况下也会失败,比如在片段边界的两边,相同的标签都预测非常弱时。
4.训练神经网络
如前所述,一系列路径的概率和预测了标签。而且可以近似采用前缀查找方法。这些前缀路径的迭代求和可以通过递归前向、反向参数进行有效计算。
4.1 CTC 前向反向算法

下面弄几个最主要的公式。
公式1:

公式2:

公式3:目标是计算下式的最大值,即最高概率。加了对数函数。

4.2 最大可能性计算
CTC的目标就是最大化概率p(l|x).也就是最小化下面的值。

这部分算法较多,还是看原论文吧,最终公式如下,a(s)是前向的,βt(s)是反向的。这样就可以应用梯度下降方法了。

5.实验结果
如下,用编辑距离衡量的各模型结果,CTC表现最好。

CTC的特性决定了它有这两个问题,一是如果要求序列分段,CTC不支持;二是CTC不能准确描述内部标签间的关系。
6.tf.nn.ctc_loss
Tensorflow有此方法:
https://tensorflow.google.cn/versions/r1.15/api_docs/python/tf/nn/ctc_loss
方法介绍:Computes the CTC (Connectionist Temporal Classification) Loss.
方法返回Returns:
A 1-D float Tensor, size [batch], containing the negative log probabilities.
可见返回值是负的对数概率。应该就-ln(p(l|x)).
6.1错误ctc_loss error “No valid path found.” 原因:
(1)标签的长度大于输入的长度,从而无法预测,不能计算loss;
(2)或者是学习率LEARNING_RATE设的太高,比如0.1会报错,而0.01可以运行。