模型优化调参方法介绍(Python代码)
模型算法在机器学习和深度学习中都发挥着自己的作用,但往往训练出来的模型效果不佳或稳定性不强,就需要对模型进行调优。一般来说,会从以下几个角度来优化模型。
1.优化数据维度
在需要对原始需求进行理解、准确定义好坏样本的前提下,充分优化数据,丰富数据维度才能提高模型的效果,毕竟数据决定模型的上限,而模型仅是逼近这个上限。
- 丰富数据资源,引入更多的三方数据加入到模型训练中
- 优化特征组合生成新的变量,不同维度的特征交叉衍生、对数转换、指数转换、标准化等。
2.模型参数调优
目前主流的参数优化方法如下几种:
- 手动调参 Manual adjustment
- 网格搜索 Grid Search
- 随机搜索Random Search
- 贝叶斯优化 Bayesian Optimization
- 进化算法优化 Evolutionary Algorithms
- 基于元学习的参数优化 Meta Learning
- 基于迁移学习的参数优化 Transfer Learning
3.代码示例
3.1.手动调参
max_dep = list(range(3, 7))
splits = list(range(5, 11, 5))
scores = []
best_comb = []
kfold = KFold(n_splits=5)
# tunning
for m in max_dep:
for n in splits:
rf = RandomForestClassifier(n_estimators=1000,
criterion='gini',
max_depth=m,
min_samples_split=n
)
results = cross_val_score(rf, train_x, train_y, cv=kfold)
print(f'Score:{round(results.mean(),4)} , max_depth = {m} , min_samples_split = {n}')
scores.append(results.mean())
best_comb.append((m, n))
best_param = best_comb[scores.index(max(scores))]
print(f'\nThe Best Score : {max(scores)}')
print(f"['max_depth': {best_param[0]}, 'min_samples_split': {best_param[1]}]")
![]()
- 优点:
(1)简单方便,灵活 - 缺点:
(1)没办法确保得到最佳的参数组合
3.2 网格搜索
网格搜索是一种基本的超参数调优技术。它类似于手动调优,为网格中指定的所有给定超参数值的每个排列构建模型,评估并选择最佳模型。考虑上面的例子,其中两个超参数 max_depth =[3,4,5,6] & min_samples_split =[5,10],在这个例子中,它总共构建了4*2 = 8不同的模型。
from sklearn.model_selection import GridSearchCV
def grid_search(model, param, x, y):
grid = GridSearchCV(rf, grid_param, cv=5)
grid.fit(train_x, train_y)
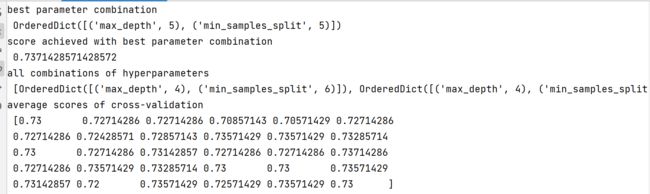
print('best parameter combination\n', grid.best_params_)
print('score achieved with best parameter combination\n', grid.best_score_)
print('all combinations of hyperparameters\n', grid.cv_results_['params'])
print('average scores of cross-validation\n', grid.cv_results_['mean_test_score'])
return grid.best_params_
grid_param = {'max_depth': list(range(3, 7)),
'min_samples_split': [5, 10]}
# tuning
grid_search(rf, grid_param, train_x, train_y)

- 优点:
(1)能够把所有给定超参数值排列组合,寻找到最佳参数 - 缺点:
(2)由于所有的组合都需学习,并且交叉验证,所以训练的非常慢。
(3)调参过程中未考虑之前的参数信息
(4)参数设置不合理,易得到局部最优
3.3 随机搜索
使用随机搜索代替网格搜索的动机是,在许多情况下,所有的超参数可能不是同等重要的。随机搜索从超参数空间中随机选择参数组合,参数由n_iter给定的固定迭代次数的情况下选择。实验证明,随机搜索的结果优于网格搜索。
from sklearn.model_selection import RandomizedSearchCV
def random_search(model, param, x, y):
rand_search = RandomizedSearchCV(model, param, cv=5, n_iter=10)
rand_search.fit(x, y)
print('best parameter combination\n', rand_search.best_params_)
print('score achieved with best parameter combination\n', rand_search.best_score_)
print('all combinations of hyperparameters\n', rand_search.cv_results_['params'])
print('average scores of cross-validation\n', rand_search.cv_results_['mean_test_score'])
return rand_search.best_params_
rscv_param = {'max_depth': list(range(3, 7)),
'min_samples_split': [5, 10]}
# tuning
random_search(rf, rscv_param, train_x, train_y)

- 优点:
(1)随机把所有给定超参数值排列组合,寻找到最佳参数 - 缺点:
(1)不能保证给出最好的参数组合,易得到局部最优
3.4 贝叶斯搜索
贝叶斯优化属于一类优化算法,称为基于序列模型的优化(SMBO)算法。这些算法使用先前对损失f的观察结果,以确定下一个(最优)点来抽样f。主要步骤概括如下:
(1)使用先前评估的点X1*:n*,计算损失f的后验期望。
(2)在新的点X的抽样损失f,从而最大化f的期望的某些方法。该方法指定f域的哪些区域最适于抽样。
(3)重复这些步骤,直到满足某些收敛准则。
from skopt import BayesSearchCV
def bayes_search(model, param, x, y):
bay_search = BayesSearchCV(model, param, n_iter=30)
bay_search.fit(x, y)
print('best parameter combination\n', bay_search.best_params_)
print('score achieved with best parameter combination\n', bay_search.best_score_)
print('all combinations of hyperparameters\n', bay_search.cv_results_['params'])
print('average scores of cross-validation\n', bay_search.cv_results_['mean_test_score'])
return bay_search.best_params_
bayes_param = {'max_depth': list(range(3, 7)),
'min_samples_split': [5, 10]}
# tuning
bayes_search(rf, bayes_param, train_x, train_y)
- 优点:
(1)调参过程中考虑了之前的参数信息,不断地更新先验信息
(2)迭代次数少,训练速度快
(3)对非凸问题依然稳健的效果 - 缺点:
(1)对参数很敏感,易低估不确定性
(2)要在2维或3维的搜索空间中得到一个好的代理曲面需要十几个样本,增加搜索空间的维数需要更多的样本。