【100天精通python】Day24:python 迭代器,生成器,修饰器应用详解与示例
目录
专栏导读
1 迭代器,生成器,修饰器概述
1.1 概述
1.2 应用场景
2 语法与示例
2.1 迭代器
2.2 生成器
2.3 修饰器
3 综合应用案例
专栏导读

专栏订阅地址:https://blog.csdn.net/qq_35831906/category_12375510.html

1 迭代器,生成器,修饰器概述
1.1 概述
迭代器(Iterators): 迭代器是一个对象,它实现了迭代协议,可以遍历容器中的元素。迭代器必须包含
__iter__()和__next__()两个方法。__iter__()方法返回迭代器对象自身,__next__()方法返回容器中的下一个元素。当容器中的元素遍历完毕时,__next__()应该引发StopIteration异常。生成器(Generators): 生成器是一种特殊的迭代器,它允许我们更简洁地定义迭代器。生成器使用
yield关键字来产生下一个值,而不是使用return返回结果。生成器函数在每次调用yield时暂停,并在下一次迭代时从上一次暂停的位置恢复执行。这样的特性使得生成器函数更加简洁和高效。修饰器(Decorators): 装饰器是一种高阶函数,它可以用来修改其他函数的行为。装饰器的输入是一个函数,并返回一个新的函数,通常包装了原始函数,从而允许在不修改原始函数代码的情况下添加功能。装饰器可以用于在函数执行前后添加额外的逻辑,例如日志记录、权限验证、性能分析等。
这些概念在 Python 中是非常重要的,它们提供了很多便利的方式来处理数据、优化代码和实现代码复用。迭代器和生成器使得处理大量数据时更加高效,而装饰器则使得代码更加模块化和易于维护。通过合理地运用这些概念,可以写出更加优雅和功能强大的 Python 代码。
1.2 应用场景
迭代器、生成器和修饰器是在不同编程场景中广泛使用的 Python 编程工具。以下是它们的常见编程场景:
迭代器的编程场景:
- 遍历数据集:迭代器允许在遍历大型数据集时节省内存,因为它们按需逐个获取数据,而不是一次性加载整个数据集到内存中。
- 文件处理:对于大型文件,使用迭代器可以逐行读取和处理数据,而无需一次性将整个文件读入内存。
- 自定义容器:通过实现迭代器协议,我们可以创建自定义的容器对象,例如树、图等,从而可以使用 Python 的 for 循环来遍历容器中的元素。
生成器的编程场景:
- 大数据集的处理:生成器非常适合处理大型数据集,因为它们按需生成数据,避免了一次性加载所有数据到内存中。
- 无限序列:生成器可以生成无限长度的序列,例如斐波那契数列、素数序列等。
- 延迟计算:使用生成器可以实现延迟计算,只有在需要时才生成数据,这在某些情况下可以提高性能。
修饰器的编程场景:
- 日志记录:修饰器可以用于为函数添加日志记录功能,记录函数的调用信息、参数和执行时间。
- 性能分析:通过修饰器,我们可以测量函数的执行时间,从而进行性能分析和优化。
- 权限验证:修饰器可以用于对函数进行权限验证,确保只有具有特定权限的用户可以执行函数。
- 缓存结果:修饰器可以用于缓存函数的结果,避免重复计算,提高函数的执行效率。
综合应用场景:
- 使用生成器处理大型数据集,并结合修饰器记录数据处理的日志和性能。
- 使用迭代器遍历大型文件,并结合修饰器实现权限验证和缓存文件处理结果。
- 使用生成器生成无限序列,例如生成斐波那契数列,并结合修饰器记录序列的计算时间和结果。
总结:迭代器、生成器和修饰器在 Python 编程中都有着广泛的应用场景。它们使代码更加高效、灵活和易于维护,特别是在处理大型数据集和复杂任务时,它们的优势尤为明显。
2 语法与示例
2.1 迭代器
在 Python 中,迭代器(Iterators)是一种用于遍历容器中元素的机制。它提供了一种简单而统一的方式来访问集合中的每个元素,而无需了解集合的内部结构。迭代器在处理大数据集时非常有用,因为它们不需要一次性加载整个数据集到内存中,而是按需逐个获取数据,从而节省内存和提高性能。
Python中的许多内置数据类型都支持迭代,例如列表、元组、字典、集合等。迭代器的核心思想是通过 __iter__() 和 __next__() 方法来实现遍历。当我们调用 iter(iterable) 时,它会返回一个迭代器对象,然后我们可以通过 next(iterator) 来获取容器中的下一个元素,直到所有元素遍历完毕,此时会引发 StopIteration 异常。
下面是一个简单的迭代器示例:
class MyIterator:
def __init__(self, data):
self.data = data
self.index = 0
def __iter__(self):
return self
def __next__(self):
if self.index >= len(self.data):
raise StopIteration
value = self.data[self.index]
self.index += 1
return value
# 使用自定义迭代器遍历列表
my_list = [1, 2, 3, 4, 5]
my_iterator = MyIterator(my_list)
for item in my_iterator:
print(item)
输出:
1
2
3
4
5
在上面的示例中,我们定义了一个名为 MyIterator 的迭代器类,并在其中实现了 __iter__() 和 __next__() 方法。然后,我们使用自定义的迭代器遍历了一个列表 my_list。
值得注意的是,Python 提供了内置函数 iter() 和 next(),因此我们在实际编程中很少需要自己定义迭代器类。直接使用 iter() 和 next() 即可对可迭代对象进行迭代。
my_list = [1, 2, 3, 4, 5]
my_iterator = iter(my_list)
while True:
try:
item = next(my_iterator)
print(item)
except StopIteration:
break
输出结果与之前相同
1
2
3
4
5
这里我们使用 iter() 和 next() 函数来手动遍历列表,当遇到 StopIteration 异常时停止遍历。
总结:迭代器是 Python 中非常强大且常用的特性,它使得遍历数据变得简单而高效。无论是自定义迭代器类还是使用内置的 iter() 和 next() 函数,迭代器在处理数据集时都是非常有用的。
2.2 生成器
在 Python 中,生成器(Generators)是一种特殊类型的迭代器,它使用 yield 关键字来产生值,而不是使用 return 返回结果。生成器函数的执行在每次调用 yield 时暂停,而在下一次迭代时从上一次暂停的位置继续执行。这种特性使得生成器函数更加简洁、高效,并且节省内存。
生成器的好处在于它不需要一次性将所有数据加载到内存中,而是按需生成数据。这在处理大量数据时非常有用,因为它可以减少内存占用并提高程序性能。
下面是一个简单的生成器示例:
def countdown(n):
while n > 0:
yield n
n -= 1
# 使用生成器遍历倒计时
for i in countdown(5):
print(i)
输出
5
4
3
2
1
在上面的示例中,我们定义了一个名为 countdown 的生成器函数。它在每次循环中使用 yield 关键字产生一个倒计时的值,并在下一次迭代时从上一次暂停的位置继续执行。因此,每次迭代都会输出一个倒计时的值。
值得注意的是,生成器函数并不返回一个值,而是生成一个迭代器。我们可以通过调用生成器函数来获得生成器对象,并使用它进行迭代。当所有值都生成完毕后,生成器会引发 StopIteration 异常。
除了通过 yield 来定义生成器,Python 还支持使用生成器表达式来快速创建生成器。生成器表达式类似于列表推导式,但使用圆括号而不是方括号。
示例:
# 使用生成器表达式生成一个包含 1 到 5 的生成器
my_generator = (x for x in range(1, 6))
# 遍历生成器并输出值
for item in my_generator:
print(item)
输出
1
2
3
4
5
生成器是 Python 中强大而灵活的工具。通过使用 yield 关键字定义生成器函数或生成器表达式,我们可以在处理大数据集时节省内存、提高性能,并使代码更加简洁。
2.3 修饰器
修饰器(Decorators)是 Python 中的一种高级功能,它允许我们在不修改原始函数代码的情况下,为函数添加额外的功能或行为。修饰器本质上是一个函数,它接受另一个函数作为参数,并返回一个新的函数。通过这种方式,我们可以在调用函数之前、之后或在函数执行过程中注入一些通用的逻辑。
修饰器的语法使用 @ 符号,将修饰器应用到目标函数之前。
让我们看一个简单的示例:
# 定义一个简单的修饰器函数
def my_decorator(func):
def wrapper():
print("Something is happening before the function is called.")
func()
print("Something is happening after the function is called.")
return wrapper
# 使用修饰器来装饰函数
@my_decorator
def say_hello():
print("Hello!")
# 调用被装饰的函数
say_hello()
输出:
Something is happening before the function is called.
Hello!
Something is happening after the function is called.
在上面的例子中,我们定义了一个名为 my_decorator 的修饰器函数,它接受一个函数 func 作为参数,并返回一个新的函数 wrapper。在 wrapper 函数内部,我们添加了额外的逻辑,即在目标函数 func 被调用之前和之后打印出一些信息。
然后,我们使用 @my_decorator 语法将 my_decorator 修饰器应用到函数 say_hello 上,相当于执行了以下操作:
say_hello = my_decorator(say_hello)
这样,当我们调用 say_hello() 函数时,实际上是调用了被修饰后的 wrapper 函数,从而在打印 "Hello!" 之前和之后分别执行了额外的逻辑。
除了上述示例外,修饰器还可以带有参数,使其更加灵活。例如:
def repeat(num_times):
def my_decorator(func):
def wrapper(*args, **kwargs):
for _ in range(num_times):
result = func(*args, **kwargs)
return result
return wrapper
return my_decorator
@repeat(num_times=3)
def say_hello(name):
print(f"Hello, {name}!")
say_hello("John")
输出:
Hello, John!
Hello, John!
Hello, John!
在这个例子中,我们定义了一个带有参数的修饰器 repeat,它可以指定函数执行的次数。通过使用 @repeat(num_times=3) 语法,我们将 repeat 修饰器应用到 say_hello 函数上,并指定该函数将会被执行三次。
总结:修饰器是 Python 中一种强大且灵活的编程工具,它使得代码更加模块化、可读性更高,并允许在不修改原始函数代码的情况下添加通用的逻辑。通过使用修饰器,我们可以轻松地实现日志记录、性能分析、权限验证等通用功能,从而使代码更加优雅和可维护。
3 综合应用案例
假设你有一个包含大量整数的列表,现在需要对其中的每个整数进行平方运算,并在每次运算前后记录日志,包括函数的执行时间。
要求实现一个程序,包含以下功能:
- 定义一个生成器函数
square_generator(data),该函数接受一个整数列表data作为参数,并返回一个生成器。生成器会逐个生成列表中每个整数的平方值。 - 定义一个修饰器函数
log_decorator(func),该函数接受一个函数func作为参数,并返回一个新的函数wrapper。在wrapper函数内部,它会记录func函数的执行时间,并输出执行时间日志。 - 将修饰器
log_decorator应用到生成器函数square_generator上,创建一个新的经过修饰的生成器函数log_square_generator。 - 创建一个包含大量整数的列表
data_list,调用经过修饰的生成器函数log_square_generator(data_list),并观察运行时间的日志输出。
最终,程序能够处理大量数据并自动记录执行时间,使代码更加高效和可维护。
代码如下:
import time
# 生成器函数:平方生成器
def square_generator(data):
for item in data:
yield item ** 2
# 修饰器函数:日志记录
def log_decorator(func):
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
print(f"Function {func.__name__} executed in {end_time - start_time:.6f} seconds.")
return result
return wrapper
# 经过修饰的生成器函数:带有日志记录的平方生成器
@log_decorator
def log_square_generator(data):
for item in data:
yield item ** 2
# 创建一个大型数据集的列表
data_list = list(range(1, 1000000001))
# 使用经过修饰的生成器处理数据,并观察日志输出
for square in log_square_generator(data_list):
pass
输出结果如下:
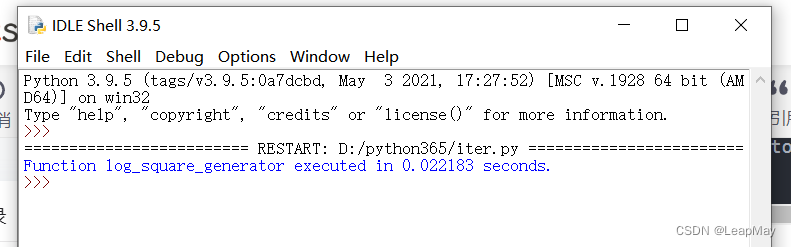
以上案例中,我们首先定义了
square_generator生成器函数,它可以将列表中的每个元素平方后返回。然后,我们定义了log_decorator修饰器函数,用于记录函数的执行时间和参数。接下来,我们将修饰器应用到
square_generator上,创建一个新的经过修饰的生成器函数log_square_generator,它将在运算前后记录日志。最后,我们创建一个大型数据集的列表,并使用经过修饰的生成器函数
log_square_generator来处理数据,并观察日志输出。在运行代码时,你会看到生成器的运行时间被记录下来。这个完整版的案例演示了如何利用迭代器、生成器和修饰器来处理大型数据集,并添加通用的日志记录功能,从而使代码更加高效、灵活和易于维护。