OpenAI的提供的Model简要介绍
OpenAI提供的model
通过OpenAI的接口可以查看所有支持的模型(目前的账号无GPT4的权限,所以没有列举GPT4相关的模型)。
import os
import openai
import pandas as pd
from IPython.display import display
openai.api_key = os.getenv("OPENAI_API_KEY")
# list all open ai models
engines = openai.Engine.list()
pd = pd.DataFrame(openai.Engine.list()['data'])
display(pd[['id', 'owner']])入下所示显示了所有支持的models,下面的model大致可以分为三类:
类型一:GPT-3.5 家族的模型,包括 ChatGPT 所使用的 gpt-3.5-turbo 或者 gpt-3.5-turbo-0301,以及 text-davinci-003 和 text-davinci-002 这两个模型。前者专门针对对话的形式进行了微调,并且价格便宜。后两个里,003 的模型有一个特殊的功能,就是支持“插入文本”这个功能。003 也是基于强化学习微调的,而 002 则是做了监督学习下的微调。text-davinci-003 和 002 模型比 3.5-turbo 要贵 10 倍,但是输出更稳定。
类型二:是 Ada、Babbage、Curie 以及 Davinci 这四个基础模型。只适合用于下达单轮的指令,不适合考虑复杂的上下文和进行逻辑推理。这四个模型按照首字母排序,价格越来越贵,效果越来越好。而且如果要微调一个属于自己的模型,也需要基于这四个基础模型。
类型三:是 text-embedding-ada-002、text-similarity-ada-001 这些专门用途模型。一般来说,通过这个模型来获取 Embedding,再用在其他的机器学习模型的训练,或者语义相似度的比较上。
通过下面的代码,可以查看下不同的model生成的文字向量的维度。
from openai.embeddings_utils import get_embedding
text = "让我们来算算Embedding"
embedding_ada = get_embedding(text, engine="text-embedding-ada-002")
print("embedding-ada: ", len(embedding_ada))
similarity_ada = get_embedding(text, engine="text-similarity-ada-001")
print("similarity-ada: ", len(similarity_ada))
babbage_similarity = get_embedding(text, engine="babbage-similarity")
print("babbage-similarity: ", len(babbage_similarity))
babbage_search_query = get_embedding(
text, engine="text-search-babbage-query-001")
print("search-babbage-query: ", len(babbage_search_query))
curie = get_embedding(text, engine="curie-similarity")
print("curie-similarity: ", len(curie))
davinci = get_embedding(text, engine="text-similarity-davinci-001")
print("davinci-similarity: ", len(davinci))
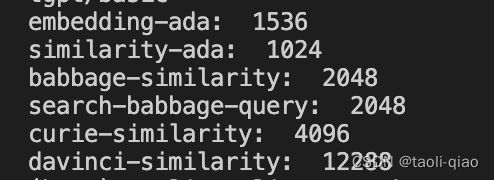
可以看到选用不同的模型,生成的向量维度是不同的,最小的是1024,最大的是12288,相差近10倍,所以,选用不同的模型,价格也不相同。
使用Moderation接口可以提出某些问题
当我们调用gpt-3.5-turbo的模型,问一些涉及暴力等的问题时,例如下面代码中问题,模型大概会这样回答"很抱歉,我是一台人工智能助手,没有实体存在,也不会对任何人或事物造成伤害。同时,我也不会对任何不适当或暴力的言语做出回应。请尊重彼此,保持良好的沟通和交流方式。"实际如果想识别某些有害的问题,可以直接调用Moderation.create(input=text)接口,如下面代码所示:
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
threaten = "你不听我的我就拿刀砍死你"
def moderation(text):
response = openai.Moderation.create(
input=text
)
output = response["results"][0]
return output
print(moderation(threaten))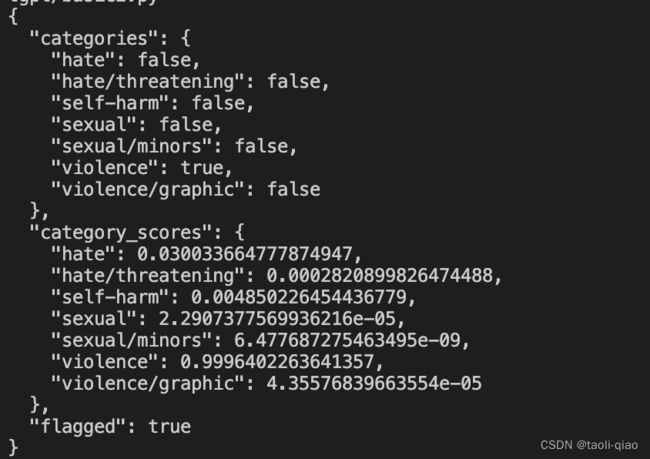
返回的接口中violence=true,说明这个问题有暴力内容在里面。有了这个接口,在实际应用中就可以利用该接口提供的能力提出有害问题,保证机器人的健康性。
Completion接口中的logit_bias参数
在completion接口中,对于logit_bias参数的使用说明是这样"
Modify the likelihood of specified tokens appearing in the completion.
Accepts a json object that maps tokens (specified by their token ID in the GPT tokenizer) to an associated bias value from -100 to 100. You can use this tokenizer tool (which works for both GPT-2 and GPT-3) to convert text to token IDs. Mathematically, the bias is added to the logits generated by the model prior to sampling. The exact effect will vary per model, but values between -1 and 1 should decrease or increase likelihood of selection; values like -100 or 100 should result in a ban or exclusive selection of the relevant token.
As an example, you can pass {"50256": -100} to prevent the <|endoftext|> token from being generated."
总结而言,就是对某些文字进行分词处理后,对每个token进行赋值,如果赋值是100,表示生成的答案中一定要包含这个文字,如果是-100则说明生成的答案的一定不能包含该文字,若果在-1和1间那么会影响不包含或者包含的概率。如果在实际业务中,不想生成的答案中包含某些特定文字,那么可以通过赋值100来解决。如下面的代码所示,将“灾害”两个字赋值为-100.
import tiktoken
import openai
import os
encoding = tiktoken.get_encoding('p50k_base')
token_ids = encoding.encode("灾害")
print(token_ids)
bias_map = {}
for token_id in token_ids:
bias_map[token_id] = -100
def make_text_short(text):
messages = []
messages.append(
{"role": "system", "content": "你是一个用来将文本改写得短的AI助手,用户输入一段文本,你给出一段意思相同,但是短小精悍的结果"})
messages.append({"role": "user", "content": text})
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo", messages=messages, temperature=0.5, max_tokens=2048,
n=2, presence_penalty=0, frequency_penalty=2,
logit_bias=bias_map,
)
return response
long_text = """
列举全球遇到的重大灾害问题,例如全球变暖,经济下行等
"""
short_version = make_text_short(long_text)
index = 1
for choice in short_version["choices"]:
print(f"version {index}: " + choice["message"]["content"])
index += 1
生成的结果如下所示:虽然例子里面出现了“重大灾害”四个字,但是生成的结果里面都没有灾害两个字。

可以看到,利用logit_bias参数可以实现某些敏感字体脱敏的效果。