Mysql系列之六(视图,事务,触发器等)
视图
1.什么是视图
视图就是通过查询一张表储存起来,下次可以接着用
2.为什么要用视图
如果要频繁的使用一张虚拟表,你可以制作成视图,后续直接使用
3.如何操作
# 固定语法
create view 视图表明 as sql语句获得的虚拟表
具体操作
# 具体操作
create view teacher2course as
select * from teacher INNER JOIN course
on teacher.tid = course.teacher_id
;
注意
1.视图创建在硬盘里只有表结构,数据并没有写入硬盘
2.视图只能用来查看,如果对视图的数据进行修改则可能会影响原始表中的数据
3.视图不方便维护
综上:视图很少使用
触发器
什么是触发器
触发器是指在对数据进行增删改查操作的基础上,自动触发的功能
主要用于:日志记录监控等方面
主要有以下的几种组合
before/after delete/update/insert
触发器的具体用法
# 固定语法
create trigger 触发器的名字 before/after delete/update/insert on 表名 for each row
begin
sql语句
end
# 针对命名
要见名知意,如 tri_bef_del_student
# 增对;问题
由于在定义触发器的过程中需要用;来明确语意,所以通常在使用前后更改。
方法:
delimiter \\
delimiter ;
触发器的实例式**
# 案例
CREATE TABLE cmd (
id INT PRIMARY KEY auto_increment,
USER CHAR (32),
priv CHAR (10),
cmd CHAR (64),
sub_time datetime, #提交时间
success enum ('yes', 'no') #0代表执行失败
);
CREATE TABLE errlog (
id INT PRIMARY KEY auto_increment,
err_cmd CHAR (64),
err_time datetime
);
"""
当cmd表中的记录succes字段是no那么就触发触发器的执行去errlog表中插入数据
NEW指代的就是一条条数据对象
"""
delimiter $$
create trigger tri_after_insert_cmd after insert on cmd
for each row
begin
if NEW.success = 'no' then
insert into errlog(err_cmd,err_time) values(NEW.cmd,NEW.sub_time);
end if;
end $$
delimiter ;
# 朝cmd表插入数据
INSERT INTO cmd (
USER,
priv,
cmd,
sub_time,
success
)
VALUES
('jason','0755','ls -l /etc',NOW(),'yes'),
('jason','0755','cat /etc/passwd',NOW(),'no'),
('jason','0755','useradd xxx',NOW(),'no'),
('jason','0755','ps aux',NOW(),'yes');
# 删除触发器
drop trigger tri_aft;
事务(**)
1.什么是事务
事务是指在数据在多条数据一起操作的过程中,要么都成功,要么都失败
2.事务的四大特性
ACID四大特性
1.原子性
原子性是指将一个事务作为原子,整体操作,一个失败则全体失败
2.一致性
一致性是指事务从一个状态到另外一个状态,与原子性精密相连
3.隔离性
隔离性是指事务与事务之间不受干扰
4.持久性
持久性是指事务结束后,数据更改应该是永久性的,而不是短暂的
事务的用法
1.开启事务
start transaction;
2.回滚操作(回到事务之前的操作)
rollback;
3.确认(确认之后就无法回滚)
commit
"""模拟转账功能"""
create table user(
id int primary key auto_increment,
name char(16),
balance int
);
insert into user(name,balance) values
('jason',1000),
('egon',1000),
('tank',1000);
# 1 先开启事务
start transaction;
# 2 多条sql语句
update user set balance=900 where name='jason';
update user set balance=1010 where name='egon';
update user set balance=1090 where name='tank';
"""
总结
当你想让多条sql语句保持一致性 要么同时成功要么同时失败
你就应该考虑使用事务
"""
存储过程
什么是存储过程
存储过程就是讲各种执行封装成函数,以供调用
基本使用
定义:
create procedure 名称(
in m int #只接受数据,
out n int #输出数据,
inout b int #即输出有接受
)
begin
sql代码;
end;
调用:call p1(参数)
三种开发模式
第一种
"""
应用程序:程序员写代码开发
MySQL:提前编写好存储过程,供应用程序调用
好处:开发效率提升了 执行效率也上去了
缺点:考虑到认为元素、跨部门沟通的问题 后续的存储过程的扩展性差
"""
第二种
'''
应用程序:程序员写代码开发之外 设计到数据库操作也自己动手写
优点:扩展性很高
缺点:
开发效率降低
编写sql语句太过繁琐 而且后续还需要考虑sql优化的问题
'''
第三种
"""
应用程序:只写程序代码 不写sql语句 基于别人写好的操作MySQL的python框架直接调用操作即可 ORM框架
优点:开发效率比上面两种情况都要高
缺点:语句的扩展性差 可能会出现效率低下的问题
"""
存储过程具体演示
delimiter \\
create procedure p1(
in m int,
in n int,
out res int
)
begin
select * from cmd where id > m and id <n;
set res = 666;
end \\
delimiter ;
注意:在Mysql客户端使用的话必须要先定义一个变量res,输出的时候才能有变量名绑定
定义语法:
set @res = 0;
呼叫语法:
select @res;
在pymysql中如何调用存储过程
import pymysql
conn = pymysql.connect(
host='127.0.0.1',
port=3306,
user='root',
password='123456',
database='day49',
)
cursor = conn.cursor(pymysql.cursors.DictCursor)
res = cursor.callproc('p1', (10, 14, 666))
cursor.featchall() # 有返回值
'''
这里pymysql模块自动对传入的值进行了变形操作
@_p1_0
@_p1_1
@_p1_2
'''
cursor.execute('select @_p1_2')
# [{'@_p1_2': 666}]
print(cursor.fetchall())
函数
函数就是mysql内置的一些功能,通过关键字()的方式可以调用
NOW()方法
('jason','0755','ls -l /etc',NOW(),'yes')
CREATE TABLE blog (
id INT PRIMARY KEY auto_increment,
NAME CHAR (32),
sub_time datetime
);
INSERT INTO blog (NAME, sub_time)
VALUES
('第1篇','2015-03-01 11:31:21'),
('第2篇','2015-03-11 16:31:21'),
('第3篇','2016-07-01 10:21:31'),
('第4篇','2016-07-22 09:23:21'),
('第5篇','2016-07-23 10:11:11'),
('第6篇','2016-07-25 11:21:31'),
('第7篇','2017-03-01 15:33:21'),
('第8篇','2017-03-01 17:32:21'),
('第9篇','2017-03-01 18:31:21');
select date_format(sub_time,'%Y-%m'),count(id) fr
流程控制
例如python中的if,while循环在mysql中也有固定的语法
# if判断
delimiter //
CREATE PROCEDURE proc_if ()
BEGIN
declare i int default 0;
if i = 1 THEN
SELECT 1;
ELSEIF i = 2 THEN
SELECT 2;
ELSE
SELECT 7;
END IF;
END //
delimiter ;
# while循环
delimiter //
CREATE PROCEDURE proc_while ()
BEGIN
DECLARE num INT ;
SET num = 0 ;
WHILE num < 10 DO
SELECT....
num ;
SET num = num + 1 ;
END WHILE ;
索引
数据存放在硬盘中,当我们查询数据时候不得不与硬盘打交道,那么就必须要进行IO操作。
索引:类似于书的目录,是一种数据结构,是用来加速数据的查找的。
索引在MySQL中也叫'键',主要有以下三种:
primary key
unique key
index key
注意foreign key不是用来加速查询用的,不在我们的而研究范围之内
上面的三种key,前面两种除了可以增加查询速度之外各自还具有约束条件,而最后一种index key没有任何的约束条件,只是用来帮助你快速查询数据
本质
我们原来查找数据是一页一页的找,没有目的性,
而索引则形成了一种固定的机制来帮助我们查找数据。
索引的优缺点
'''
在同一个表中可以有多个不同的索引,但是我们不是每一个字段都需要加上索引
'''
'''
索引的优缺点:
优点:
· 能够加速查找的顺序
缺点:
· 当列表中已经存在大量数据的情况下,创建索引需要的时间很长
· 当我们更改数据时,那么原来的索引失效,所以会在我们更改数据的同时创建索引,使我们对表修改的速度大大降低
'''
b+树
b+树是一种数据查询机制
通过多分法将数据分为几个范围,逐渐缩小查询,
注意:在体干上存放的是虚拟数据,只有叶子(最底层存放了真实的数据)
为什么会将id列通常作为主键?
因为id列站硬盘空间小,在同一个block中存放的数据更多,这样b+树的层级低,速度更快
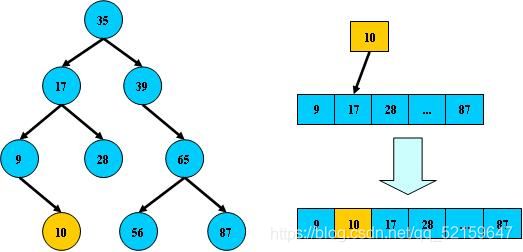
聚集索引
聚集索引就是指主键
primary key
辅助索引(unique,index)
查询数据的时候不可能一直使用主键,有时我们需要用其他的列,给其他的列创建索引
'''
注意:
在辅助索引中存放的是主键的id号
拿到id号后还要在聚合索引中进行查找
'''
覆盖索引
'''
是指所查询的数据就是在索引列,那么此时会直接返回数据,不要再次查找(在辅助索引的叶子节点就已经拿到了需要的数据)
'''
# 给name设置辅助索引
select name from user where name='jason';
# 非覆盖索引
select age from user where name='jason';