Django的生命周期流程图(补充)、路由层urls.py文件、无名分组和有名分组、反向解析(无名反向解析、有名反向解析)、路由分发、伪静态
一、orm的增删改查方法(补充)
1. 查询
res=models.表名(类名).objects.all()[0]
res=models.表名(类名).objects.filter(username=username, password=password).all()
res = models.表名(类名).objects.first() # 判断,判断数据是否有
# res如果查询出来的是一条,直接就是对象
# res它查询来的是多条,结果就是queryset对象 [对象,对象,对象]
# 如果你使用的all查询的,就算查询一条数据,结果也是queryset对象 [对象,对象,对象]
# 我们直接可以对queryset对象进行循环
2. 增加
# 第一种方式:
res=models.表名(类名).objects.create(username='', password='')
'''增加数据的时候也有返回结果:就是当前插入成功的数据对象''' # 可不是影响的行数
res.username
res.password
# 第二种方式:
obj = models.表名(类名)(username='', password='')
obj.save()
3. 更新
res=models.表名(类名).objects.update(username='', password='') # 全表更新
res=models.表名(类名).objects.filter().update(username='', password='')
'''返回的结果才是影响的行数'''
# 第二种方式:
# 先查询
user_obj = models.表名(类名).objects.first()
user_obj.username = username
user_obj.save()
4. 删除
models.表名(类名).objects.filter().delete() # 直接就删除了
"""删除的方式有两种类型"""
1. 物理删除:直接把数据从磁盘中删除,.delete()方式就是直接物理删除
2. 软删除: 软删除的意思是,不直接从硬盘中删数据,而是在表中在增加一个字段,一般叫is_delete
它的用法就是,正常的数据这个字段的值为0,如果你要删除这条记录,is_Delete=1
# 每次删除的时候,只需要更新这个字段就可以了
id username password age gender is_delete
1 1 1 1 1 0
1 1 1 1 1 1
1 1 1 1 1 0
1 1 1 1 1 0
1 1 1 1 1 0
1 1 1 1 1 1
# 查询的时候怎么区分是正常数据还是已经被删除的数据?
models.表名(类名).objects.filter(is_delete=0).all()
二、ORM创建表关系(补充)
"""
三种关系:
一对一:一个作者能不能有多个作者详情信息,一个作者详情不能有多个作者。
一对多:一本图书能不能有多个出版社,而多个出版社可以出版多本图书
多对多:一个作者能写多本图书,一本图书能有多个作者来写。
"""
# 当你在创建表的时候,先创建基础字段,然后在考虑关系字段,外键字段
一对多:models.ForeignKey(to='被关联的表名', to_field='') # 默认是跟这个表的主键字段关联
多对多:models.ManytoManyField(to='被关联的表名', to_field='') # 默认是跟这个表的主键字段关联
一对一:models.OneToOneField(to='被关联的表名', to_field='') # 默认是跟这个表的主键字段关联
查询API
<1> all(): 查询所有结果
<2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象
<3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,
如果符合筛选条件的对象超过一个或者没有都会抛出错误。
<4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象
<5> order_by(*field): 对查询结果排序('-id')
<6> reverse(): 对且只对order_by排序的结果进行翻转
<8> count(): 返回数据库中匹配查询(QuerySet)的对象数量。
<9> first(): 返回QuerySet集中的第一个对象
<10> last(): 返回QuerySet集中的最后一个对象
<11> exists(): 如果QuerySet包含数据,就返回True,否则返回False
<12> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列
model的实例化对象,而是一个可迭代的字典序列
<13> values_list(*field): 它与values()非常相似,但返回的是一个元组序列
<14> distinct(): 从返回结果中剔除重复纪录
三、Django的生命周期流程图(补充)
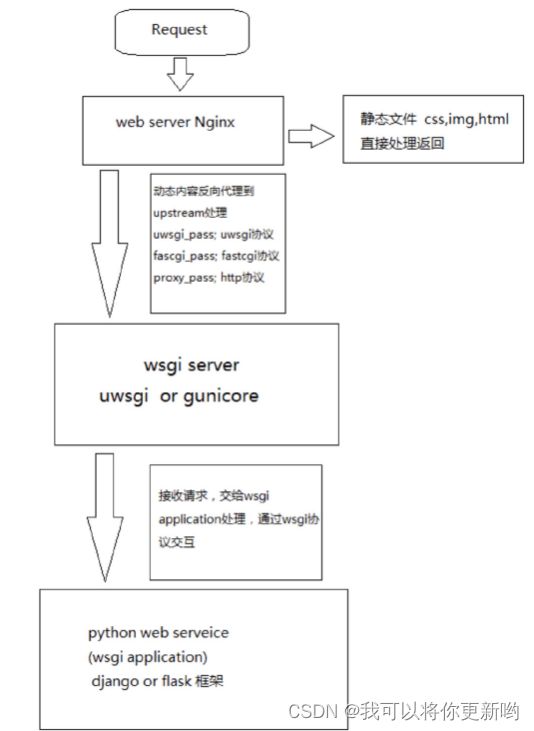
1. 用户先从浏览器发起HTTP请求
2. 请求就来到了web服务器(web服务网关接口)
socktet部分
wsgiref模块实现的socket服务端
"""
1. 请求来的时候,把HTTP格式的数据封装打包成一个字典
2. 响应走的时候,把数据封装成符合HTTP格式的数据返回给浏览器
"""
# 后面还给它改成uwsgi服务器
# wsgiref、uwsgi他们两个也都会遵循一个协议:WSGI协议
https://www.yuque.com/liyangqit/cbndkh/evyps8
3. Django应用
4. 中间件
5. 路由层
6. 视图层
7. 模板层
8. DB
"""混合项目:前端页面和Python代码都写在一个项目里面,前后端分离,前端是一个项目,后端是一个项目,中间通过json格式的数据进行数据传输"""
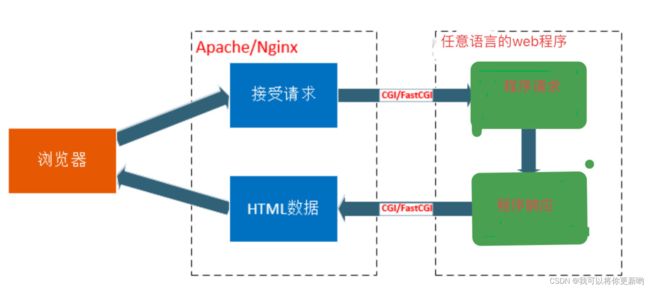
1.CGI
1、通用网关接口(Common Gateway Interface/CGI)是一种重要的互联网技术,可以让一个客户端,从网页浏览器向执行在网络服务器上的程序请求数据。CGI描述了服务器和请求处理程序之间传输数据的一种标准。
2、CGI程序可以用任何脚本语言或者是完全独立编程语言实现,只要这个语言可以在这个系统上运行。
3、用来规范web服务器传输到php解释器中的数据类型以及数据格式,包括URL、查询字符串、POST数据、HTTP header等,也就是为了保证web server传递过来的数据是标准格式的
4、一句话总结: 一个标准,定义了客户端服务器之间如何传数据
2.FastCGI
1、快速通用网关接口(Fast Common Gateway Interface/FastCGI)是一种让交互程序与Web服务器通信的协议。FastCGI是早期通用网关接口(CGI)的增强版本。
2、FastCGI致力于减少网页服务器与CGI程序之间互动的开销,从而使服务器可以同时处理更多的网页请求。
3、使用FastCGI的服务器:
Apache HTTP Server (部分)
Cherokee HTTP Server
Hiawatha Webserver
Lighttpd
Nginx
LiteSpeed Web Server
Microsoft IIS
4、一句话总结: CGI的升级版
3.WSGI
1、Web服务器网关接口(Python Web Server Gateway Interface,缩写为WSGI)是为Python语言定义的Web服务器和Web应用程序或框架之间的一种简单而通用的接口。自从WSGI被开发出来以后,许多其它语言中也出现了类似接口。
2、wsgi server (比如uWSGI) 要和 wsgi application(比如django )交互,uwsgi需要将过来的请求转给django 处理,那么uWSGI 和 django的交互和调用就需要一个统一的规范,这个规范就是WSGI WSGI(Web Server Gateway Interface)
3、WSGI,全称 Web Server Gateway Interface,或者 Python Web Server Gateway Interface ,是为 Python 语言定义的 Web 服务器和 Web 应用程序或框架之间的一种简单而通用的接口。自从 WSGI 被开发出来以后,许多其它语言中也出现了类似接口。
4、WSGI 的官方定义是,the Python Web Server Gateway Interface。从名字就可以看出来,这东西是一个Gateway,也就是网关。网关的作用就是在协议之间进行转换。
5、WSGI 是作为 Web 服务器与 Web 应用程序或应用框架之间的一种低级别的接口,以提升可移植 Web 应用开发的共同点。WSGI 是基于现存的 CGI 标准而设计的
6、一句话总结: 为Python定义的web服务器和web框架之间的接口标准
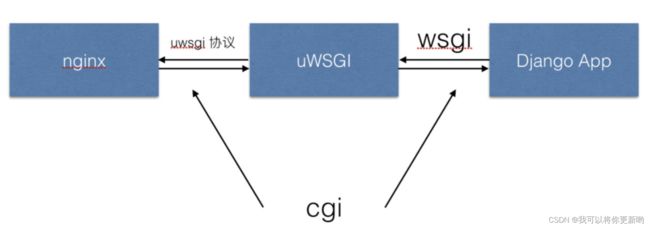
4.uWSGI
wsgiref,werkzeug(一个是符合wsgi协议的web服务器+工具包(封装了一些东西))
uWSGI 用c语言写的,性能比较高
gunicorn:python写的
tornado:也可以部署django项目
1、它是一个Web服务器(类似的有wsgiref,gunicorn),它实现了WSGI协议、uwsgi、http等协议。用于接收前端服务器转发的动态请求并处理后发给 web 应用程序。
2、Nginx中HttpUwsgiModule的作用是与uWSGI服务器进行交换
3、一句话总结: 一个Web Server,即一个实现了WSGI的服务器,大体和Apache是一个类型的东西,处理发来的请求。
5.uwsgi
location / {
#方式一
#include uwsgi_params; # 导入一个Nginx模块他是用来和uWSGI进行通讯的
#uwsgi_connect_timeout 30; # 设置连接uWSGI超时时间
#uwsgi_pass 101.133.225.166:8080;
#方式二
#include uwsgi_params; # 导入一个Nginx模块他是用来和uWSGI进行通讯的
#uwsgi_pass unix:///var/www/script/uwsgi.sock; # 指定uwsgi的sock文件所有动态请求
#方式三
proxy_pass http://101.133.225.166:8088
}
它是uWSGI服务器实现的独有的协议,用于定义传输信息的类型,是用于前端服务器与 uwsgi 的通信规范。
一句话总结: uWSGI自有的一个协议
uWSGI:web服务器,等同于wsgiref
uwsgi:uWSGI自有的协议

四、路由层urls.py文件
- url函数的使用(支持正则表达式)
- 无名分组
- 有名分组
- 反向解析
- 无名分组反向解析
- 有名分组反向解析
- 路由分发
- 伪静态的概念
- 虚拟环境(纯净版的解释器)
- 视图层
- 每个视图函数都要返回HttpResponse对象、render、redirect
- 序列化(JsonResponse对象、drf中会有专门的序列化文件)
- form表单如何上传文件
- CBV(class based view)和FBV(function based view)
- CBV的源码分析
- 面试题:你看过Django的哪些源码?
- 频率、权限、认证等的源码
五、url函数的使用(支持正则表达式)
# django1中使用的是url
url(r'^admin/', admin.site.urls), # 默认的路由地址,它是django自带的后台管理系统
url('test', views.test),
url函数的第一个参数是支持正则表达式的
如果匹配到一个路由,就不再往下匹配,直接执行路由对应的视图函数
# http://127.0.0.1:8000/test/
是django默认设置的,django会先拿着test去匹配,如果匹配不到,它会自动加一个斜杠再次去匹配
# 缓存:redis数据库缓存
APPEND_SLASH = False # 不加斜杠匹配, 默认的是 APPEND_SLASH = True
# django2中使用的是path
path('test/', admin.site.urls), # path是不支持正则的,它是精准匹配,输入的内容和路由地址必须是完全匹配
re_path('^test/$', admin.site.urls) # django1中的url是完全一样的
六、无名分组
分组:在正则表达式中使用小括号括起来的内容就是分组
单独的分组其实是没有意义的,它不影响我们的正常匹配
re模块中的分组优先原则 re.match()
先把分组的内容显示出来
url('^test/(\d+)/(\d+)$', views.test),
def test(request, xx, yy):
print(xx, yy) # 123
return HttpResponse("test")
注意:无名分组就是把路由地址匹配的的数据以位置参数的形式传递给视图函数
七、有名分组
分组:在正则表达式中使用小括号括起来的内容然后给它起个名字就是有名分组
url('^testadd/(?P\d+)/(?P\d+)$' , views.testadd)
注意:有名分组就是把路由地址匹配的的数据以关键字参数的形式传递给视图函数
# 这种形式也是第二种传参方式
http://127.0.0.1:8000/testadd/123/11
http://127.0.0.1:8000/testadd/?a=1&b=2
注意:1.有名分组和无名分组能否一起使用?
不要一起使用
2.但是无名或者有名单独的可以使用多次
url('^testadd/(?P\d+)/(?P\d+)/(?P\d+)/(?P\d+)$' , views.testadd)
def testadd(request, year, month):
print('testadd')
print(year)
print(year)
return HttpResponse('testadd')
url('^test/(\d+)/(\d+)/(\d+)/(\d+)/(\d+)/(\d+)/(\d+)$', views.test),
django2中的用法:用法和django1一样
re_path('^test/(\d+)/(\d+)/(\d+)/(\d+)/(\d+)/(\d+)/(\d+)$', views.test),
re_path('^testadd/(?P\d+)/(?P\d+)/(?P\d+)/(?P\d+)$' , views.testadd)
八、反向解析
1.反向解析: 意思是可以给路由起一个名字,然后通过一个方法可以解析出这个名字对应的路由地址
url('^testadd/(?P\d+)/(?P\d+)$' , views.testadd, name='testadd') # name路由名字
2.后端解析
后端反向解析
print(reverse('test')) # /test/ /test/v1/ /test/v1/v2
3.前端解析 {% url '待匹配的名字' %}
<a href="{% url 'test' %}">点我</a>
九、无名分组反向解析
1.前端解析
<a href="{% url 'test' 111 %}">点我</a>
2.后端解析
print(reverse('test', args=(123, ))) # /test/1 /test/123
问题:这个参数到底指定几或者说指定给谁?
reverse('test', args=(123, ))
十、有名分组反向解析
1.前端解析
<a href="{% url 'testadd' 2023 12 %}">点我</a>
2.后端解析
print(reverse('testadd',kwargs={'year':2023, 'month':12})) # /testadd/2023 /testadd/2023/12
十一、django2中的path函数支持的5种转换器
path('test/', admin.site.urls)
Django默认支持以下5个转化器:
● str,匹配除了路径分隔符(/)之外的非空字符串,这是默认的形式
● int,匹配正整数,包含0。
● slug,匹配字母、数字以及横杠、下划线组成的字符串。
● uuid,匹配格式化的uuid,如 075194d3-6885-417e-a8a8-6c931e272f00。
● path,匹配任何非空字符串,包含了路径分隔符(/)(不能用?)
urlpatterns = [
path('articles/2003/', views.special_case_2003),
path('articles//' , views.year_archive),
path('articles///' , views.month_archive),
path('articles////' , views.article_detail),
# path才支持,re_path不支持
path('order/' ,views.order),
]
十二、路由分发
# 目前一个django项目只有一个总路由文件urls.py
# 但是当我们的路由比较多的时候,这个文件就会产生很多的路由地址,产生的问题就是理由比较臃肿,不太容易管理,也不太容易排查错误
我们针对每一个应用也可以有自己的路由文件,每一个应用下的路由我们称之为是子路由
但是你会发现每一个应用下面没有urls.py这个文件
我们需要自己手动创建出来一个文件
'''这个时候产生了很多的路由文件,匹配的时候先匹配总路由,然后有总路由进行分发到每个子路由'''
# 这个时候总路由的作用就是分发了,总路由就不再执行具体的视图函数,而是交给子路由
1.第一种方式:
url('^app01/', include(app01_urls)),
url('^app02/', include(app02_urls)),
2.第二种方式
url('^app01/', include('app01.urls')),
url('^app02/', include('app02.urls')),
"""
总路由中的路由分发地址后面一定不能加$
"""
十三、伪静态的概念
# 静态文件 .html
index.html
http://127.0.0.1:8000/app01/index
https://www.cnblogs.com/fanshaoO/p/17592993.html # 其实就是伪静态之后的地址
原本这个地址是动态的,数据是从数据库中查询出来的,而不是在html页面中写死的
为什么要伪静态呢?
"""
作用就是让搜索引擎增大seo的查询力度,言外之意就是让我们的页面能够更加容易的被搜索引擎搜索出来
"""
# 比如你在百度中搜索一个关键词,百度的搜索引擎就会去全网搜索数据
# 其实搜索引擎(百度、谷歌、bing、等)就是一个巨大的爬虫程序
因为静态的页面更加容易被搜索引擎抓到,这个称之为是seo
seo就是优化你们的产品能够被更容易的搜多到
SEO---------------------->一般是通过技术手段等实现
SEM---------------------->它是需要收费的,其实就是广告
十四、虚拟环境
# 一般我们开发项目是一个单独的项目使用一个单独的解释器环境
举例:
开发一个CRM系统:3.6
开发一个OA系统:3.7
开发一个商城系统:3.6
难道我们每一个项目都使用一个解释器吗? 肯定不是
每个项目单独使用一个解释器版本,这个解释器中只安装这个项目使用到的模块
注意1:每开发一个项目我就下载一个解释器,当然能够解决问题,都是这样做吗?
我们会使用虚拟环境来解决这个问题
虚拟环境其实就是一个纯净版本的解释器,不用每次都下载和安装
它就是一个文件夹形式存在的解释器
注意2:虚拟环境尽量不要创建,创建出来够你的项目使用就行了
注意3:虚拟环境还可以通过命令创建