ES复杂语句查询group by 探讨
项目背景
现在公司内部使用es作为大数据存储分析库,当数据量过大的时候,通过代码可能查询时间过长或者程序宕机时不能及时查询数据进行反馈。这时候就需要直接对es进行操作查询
查询语句分析
单纯 distinct
例如sql :
SELECT DISTINCT(uuid) FROM table WHERE keyvalue= 3;
这里对应在es的查询为
{
"query": {
"term": {
"keyvalue": 3
}
},
"group": {
"field": "uuid"
}
}
ps : 这里的group只是一个聚合后的名字
{
...
"hits": {
"hits": [
{
"_index": "test01",
"_type": "keywords",
"_source": {
"userId": "1",
"userName": "huahua"
},
"fields": {
"pk": [
"1"
]
}
}
]
}
}
fields字段包含了你所需要查询的返回结果
count + distinct
sql:
SELECT COUNT(DISTINCT(userName)) FROM table WHERE userId= 3;
{
"query": {
"term": {
"userId": 3
}
},
"aggs": {
"count": {
"cardinality": {
"field": "userName"
}
}
}
}
结果
{
...
"hits": {
...
},
"aggregations": {
"count": {
"value": 121
}
}
}
这里hits中会包含全部的返回结果
count + group by
sql:
SELECT COUNT(userName) FROM table GROUP BY userId;
{
"aggs": {
"user_count": {
"terms": {
"field": "userId"
}
}
}
}
aggs中terms的字段代表需要gruop by的字段
结果
{
...
"hits": {
...
},
"aggregations": {
"user_type": {
...
"buckets": [
{
"key": 4,
"doc_count": 500
},
{
"key": 3,
"doc_count": 200
}
]
}
}
}
里面buckets就是包含的不重复的userId,值为出现的次数。
count + distinct + group by
sql:
SELECT COUNT(DISTINCT(userName)) FROM table GROUP BY userId;
{
"aggs": {
"unique_count": {
"terms": {
"field": "userId"
},
"aggs": {
"count": {
"cardinality": {
"field": "userName"
}
}
}
}
}
}
{
...
"hits": {
...
},
"aggregations": {
"unique_count": {
...
"buckets": [
{
"key": 4,
"doc_count": 500, //去重前数据1220条
"count": {
"value": 26//去重后数据276条
}
},
{
"key": 3,
"doc_count": 200, //去重前数据488条
"count": {
"value": 20//去重后数据121条
}
}
]
}
}
}
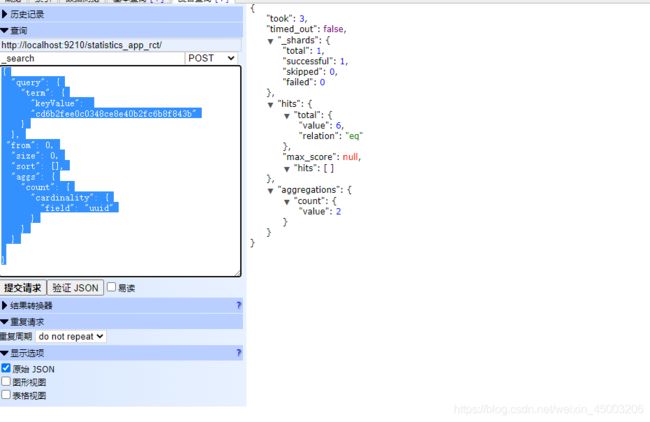
改进符合项目版本
{
"query": {
"term": {
"keyValue":
"cd6b2fee0c0348ce8e40b2fc6b8f843b"
}
},
"from": 0,
"size": 0,
"sort": [],
"aggs": {
"count": {
"cardinality": {
"field": "uuid"
}
}
}
}
这里添加了参数选择,并且去掉了hits里面的返回数据
sql:
select COUNT(DISTINCT(uuid)) from rct where keyvalue = "cd6b2fee0c0348ce8e40b2fc6b8f843b" group by uuid
返回数据中的count就是告诉我i有多少不同的用户,符合查找需求
注意点是这里的分组时的字段只能时keyword类型。
这里的查找语句借鉴了
博客 :https://blog.csdn.net/lihaiyong92/article/details/90207485
看完有用请大家点个赞,有问题的地方请大家指导,讨论下。