使用Apache Flink在亚马逊云科技Amazon EMR上构建统一数据湖
为了建立数据驱动型企业,在数据目录中实现企业数据资产的大众化非常重要。利用统一的数据目录,可以快速搜索数据集,并确定数据架构、数据格式和位置。亚马逊云科技Amazon Glue Data Catalog提供了一个统一的存储库,让不同的系统能够存储和查找元数据,以跟踪数据孤岛中的数据。
Apache Flink是一个应用广泛的数据处理引擎,适用于可扩展的流式处理ETL、分析和事件驱动型应用程序。该应用程序提供具备容错能力的精确时间和状态管理。Flink可以使用统一的API或应用程序处理有界流(批处理)和无界流(流式处理)。在使用Apache Flink处理数据后,下游应用程序可以使用统一的数据目录访问精心整理的数据。有了统一的元数据,数据处理和数据消耗应用程序都可以使用相同的元数据访问表。
如何将Amazon EMR中的Apache Flink与Amazon Glue Data Catalog集成,以便可以实时提取流数据,并近乎实时地访问数据进行业务分析。
Apache Flink连接器和目录架构
Apache Flink使用连接器和目录,与数据和元数据进行交互。下图显示了用于读取/写入数据的Apache Flink连接器以及用于读取/写入元数据的目录架构。
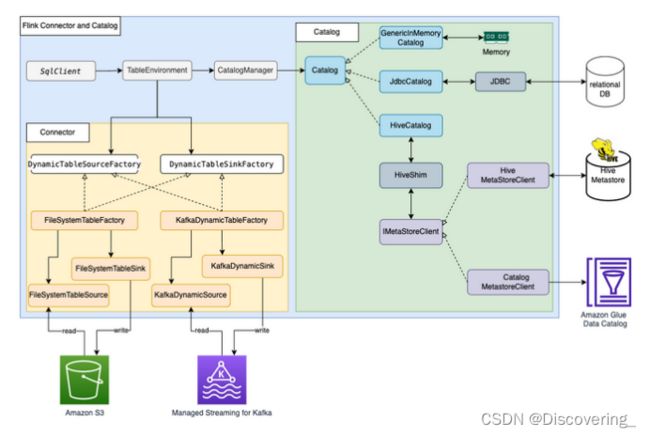
为了读取/写入数据,Flink提供了用于读取操作的DynamicTableSourceFactory接口以及用于写入操作的DynamicTableSinkFactory接口。另有一个Flink连接器实施两个接口,用于访问不同存储中的数据。例如,Flink FileSystem连接器提供了FileSystemTableFactory,用于在Hadoop Distributed File System(HDFS)或Amazon Simple Storage Service(Amazon S3)中读取/写入数据;Flink HBase连接器提供了HBase2DynamicTableFactory,用于在HBase中读取/写入数据;而Flink Kafka连接器提供了KafkaDynamicTableFactory,用于在Kafka中读取/写入数据。
对于元数据的读取/写入,Flink提供了目录接口。Flink有三种内置的目录实施。GenericInMemoryCatalog将目录数据存储在内存中。JdbcCatalog将目录数据存储在JDBC支持的关系数据库中。截至目前,JDBC目录支持MySQL和PostgreSQL数据库。HiveCatalog将目录数据存储在Hive Metastore中。HiveCatalog使用HiveShim来提供不同的Hive版本兼容性。可以配置不同的Metastore客户端,以使用Hive Metastore或Amazon Glue Data Catalog。
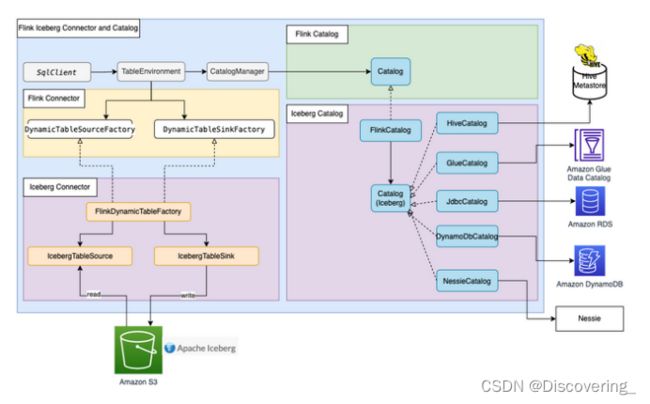
大多数Flink内置连接器(例如Kafka、Amazon Kinesis、Amazon DynamoDB、Elasticsearch或FileSystem)都可以使用Flink HiveCatalog,将元数据存储在Amazon Glue Data Catalog中。然而,一些连接器实施(如Apache Iceberg)有单独的目录管理机制。Iceberg中的FlinkCatalog实施了Flink中的目录接口。Iceberg中的FlinkCatalog对自己的目录实施提供了封装机制。下图显示了Apache Flink、Iceberg连接器和目录之间的关系。
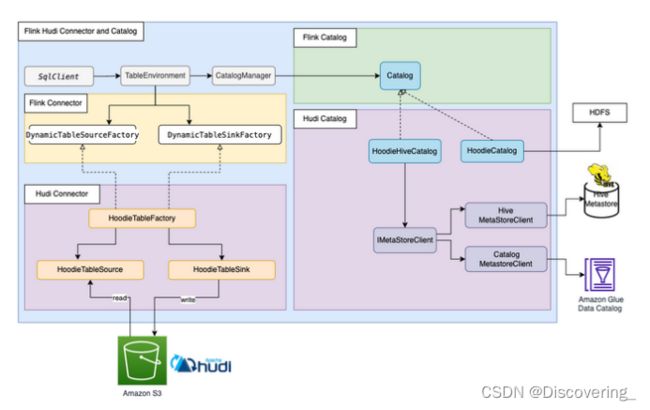
Apache Hudi也有自己的目录管理功能。HoodieCatalog和HoodieHiveCatalog都在Flink中实施了目录接口。HoodieCatalog将元数据存储在诸如HDFS这样的文件系统中。HoodieHiveCatalog将元数据存储在Hive Metastore或Amazon Glue Data Catalog中,具体取决于是否将hive.metastore.client.factory.class配置为使用com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory。下图显示了Apache Flink、Hudi连接器和目录之间的关系。
解决方案概览
下图显示了本文章中描述的解决方案的整体架构。
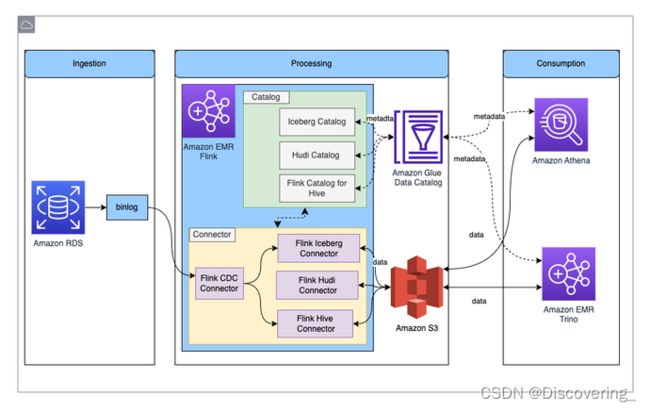
在此解决方案中,启用Amazon RDS for MySQL binlog来实时提取事务更改。Amazon EMR Flink CDC连接器读取binlog数据并处理数据。经过转换的数据可以存储在Amazon S3中。使用Amazon Glue Data Catalog来存储元数据,例如表架构和表位置。Amazon Athena或Amazon EMR Trino等下游数据使用者应用程序访问数据,以便用于业务分析。
下面是设置此解决方案的大致步骤:
- 为Amazon RDS for MySQL启用binlog并初始化数据库。
- 使用Amazon Glue Data Catalog创建EMR集群。
- 在Amazon EMR中使用Apache Flink CDC提取更改数据捕获(CDC,Change Data Capture)数据。
- 将处理后的数据存储在Amazon S3中,并将元数据存储在Amazon Glue Data Catalog中。
- 确认所有表元数据都存储在Amazon Glue Data Catalog中。
- 通过Athena或Amazon EMR Trino使用数据进行业务分析。
- 更新和删除Amazon RDS for MySQL中的源记录,并验证数据湖表中是否发生相应更改。
使用Amazon Glue Data Catalog
创建EMR集群
从Amazon EMR 6.9.0开始,Flink表API/SQL可以与Amazon Glue Data Catalog集成。要使用Flink与Amazon Glue的集成,您必须创建Amazon EMR 6.9.0或更高版本。
- 为Amazon EMR Trino与Data Catalog的集成创建文件iceberg.properties。当表格格式为Iceberg时,您的文件应包含如下内容:

2. 将iceberg.properties上传到S3存储桶,例如DOC-EXAMPLE-BUCKET。
3. 创建trino-glue-catalog-setup.sh文件以配置Trino与Data Catalog的集成。使用trino-glue-catalog-setup.sh作为引导脚本。
4. 将trino-glue-catalog-setup.sh上传到S3存储桶(DOC-EXAMPLE-BUCKET)。
5. 创建flink-glue-catalog-setup.sh文件,以配置Flink与Data Catalog的集成。
6. 使用脚本运行器,将flink-glue-catalog-setup.sh脚本作为步骤函数运行。
7. 将flink-glue-catalog-setup.sh上传到S3存储桶(DOC-EXAMPLE-BUCKET)。
8. 使用Hive、Flink和Trino应用程序创建EMR 6.9.0集群。
您可以使用Amazon命令行界面(Amazon CLI)或Amazon管理控制台创建EMR集群。
小结
这篇文章展示了如何将Amazon EMR中的Apache Flink与Amazon Glue Data Catalog集成。可以使用Flink SQL连接器在不同的存储区读取/写入数据,例如Kafka、CDC、HBase、Amazon S3、Iceberg或Hudi。您也可以将元数据存储在Data Catalog中。Flink表API具有相同的连接器和目录实施机制。在单个会话中,可以使用多个指向不同类型的目录实例(如IcebergCatalog和HiveCatalog),然后在查询中互换使用它们。也可以使用Flink表API编写代码,开发集成Flink与Data Catalog的相同解决方案。借助Amazon EMR Flink统一的批处理和流式数据处理功能,可以通过一个计算引擎提取和处理数据。通过将Apache Iceberg和Hudi集成到Amazon EMR中,可以构建一个可演变且可扩展的数据湖。通过Amazon Glue Data Catalog,可以统一管理所有企业数据目录并轻松使用数据。
转载自:
使用 Apache Flink 在 Amazon EMR 上构建统一数据湖 https://aws.amazon.com/cn/blogs/china/build-a-unified-data-lake-with-apache-flink-on-amazon-emr/
https://aws.amazon.com/cn/blogs/china/build-a-unified-data-lake-with-apache-flink-on-amazon-emr/