ZYNQ ad9226 块设备读取数据
一,vivado硬件环境搭建:

1,修改 CPU 的时钟配置,将 FCLK_CLK2 修改为 65MHz,并将时钟引出两路,提供给两个 AD9226 芯片时钟使用:

2,连接好其余信号,保存,点开 Address Editor,查看地址配置,如果有些模块没有配置地址,
点击 Auto Assign Address。然后Generate Output Products 和 Create HDL Wrapper,在 XDC 中绑定 AD9226 引脚,之后生成 bit文件

3,整个控制流程:
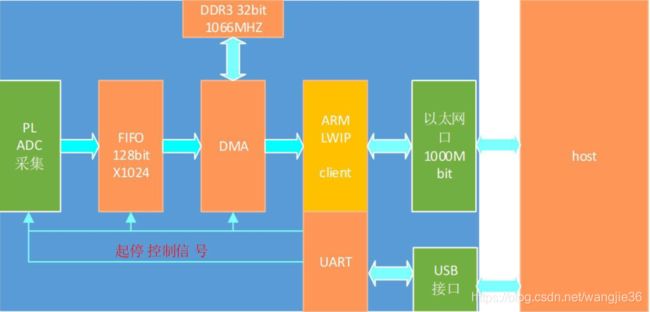
二,AD9226数据采集:
1,由于需要将 ADC 采集的数据通过 DMA 传输到 ZYNQ,与 DMA 的接口为 AXIS 流接口,因此
需要将 ADC 数据转换成 AXIS 流数据,同时 ADC 的时钟与 AXIS 时钟频率不同,因此需要添加 FIFO进行跨时钟域数据处理。同时需要实现 AXIS Master 功能。工作流程为:
1) ARM 配置启动寄存器和采集长度寄存器。
2) 由于 AD9226 的 bit0 为 MSB,做顺序调整,并扩展符号位到 16bit,便于操作,之后将 ADC 采集数据存入 FIFO。
3) DMA 使用 AXIS 接口读取 FIFO 中的数据,直到读取到所配置的数据量。
2,verilog采集模拟信号
module ad9226_data_resize(
input adc_clk,
input adc_otr,
output reg[63:0] adc_data,
output reg adc_data_valid,
input [11:0] ad9226_data
);
reg[11:0] ad9226_data_d0;
reg[11:0] ad9226_data_d1;
reg[11:0] ad9226_data_d2;
reg[11:0] ad9226_data_d3;
reg[1:0] cnt;
wire ad_data_wr;
wire empty;
always@(posedge adc_clk)
begin
ad9226_data_d0 <= {ad9226_data[0],ad9226_data[1],ad9226_data[2],ad9226_data[3],
ad9226_data[4],ad9226_data[5],ad9226_data[6],ad9226_data[7],
ad9226_data[8],ad9226_data[9],ad9226_data[10],ad9226_data[11]};
ad9226_data_d1 <= ad9226_data_d0;
ad9226_data_d2 <= ad9226_data_d1;
ad9226_data_d3 <= ad9226_data_d2;
end
always@(posedge adc_clk)
begin
cnt <= cnt + 2'd1;
end
always@(posedge adc_clk)
begin
adc_data <= { {4{ad9226_data_d0[11]}},ad9226_data_d0,{4{ad9226_data_d1[11]}},ad9226_data_d1,{4{ad9226_data_d2[11]}},ad9226_data_d2,{4{ad9226_data_d3[11]}},ad9226_data_d3};
adc_data_valid <= (cnt == 2'd3) ? 1'b1 : 1'b0;
end
endmodule
三,块设备访问流程:
1,内核空间的软件就是zImage(包含了7大子系统,比如进程管理,内存管理,文件系统等),其中内存管理最终对应底层的块设备管理,设备控制最终对应底层的字符设备驱动,网络最终对应到底层的网络设备驱动。内核空间的软件在运行的时候,CPU处于SVC管理模式,内核空间的软件同样不能直接访问硬件外设的物理地址。如果要访问,必须将外设的物理地址映射到内核空间的虚拟地址上,内核空间的软件如果对内存进行非法的访问,直接造成操作系统崩。驱动程序属于内核空间,内核空间的虚拟地址范围为:3G~4G(0xC0000000~0xffffffff)
2,内核分离思想本质:将原先驱动中的硬件和软件撤离分开, 软件一旦写好,将来硬件发生变化,无需改动软件,要改只改硬件部分即可!提高驱动的可移植性!这样驱动开发者的重心放在硬件部分即可,软件一旦写好需要改动!

3,linux内核1G虚拟内存的划分
划分的根本目的:就是让内核访问到所有的物理内存 ,又要兼顾内存的访问效率
(1)X86架构:直接内存映射区(大小:896B)
内核启动时,将1G虚拟内存的前896MB和物理内存的前896M做一一映射,内存访问效率最高!
(2)动态内存映射区:(默认大小:120MB)
当要访问某个物理地址时,内核将这个物理地址跟动态映射内存区的某个虚拟地址建立映射关系,将来访问映射的内核虚拟地址就是在访问对应的物理地址,不访问的时候要解除这种映射关系,利用动态内存映射区可以访问到其它物理内存,但是内存的访问效率低
(3)永久内存映射区:(大小4MB)
如果频繁的访问某个物理地址,可以将这个物理地址跟永久内存映射区做好映射,一旦映射好即使现在不访问,也可以不用解除映射关系,下次直接访问即可,提高了内存的访问效率映射的时候有可能会导致休眠,所以不能用于中断上下文
(4)固定内存映射区:(大小4MB)
如果频繁的访问某个物理地址,可以将这个物理地址跟永久内存映射区做好映射,一旦映射好即使现在不访问,也可以不用解除映射关系,下 +次直接访问即可,提高了内存的访问效率映射的时候不会导致休眠,所以可以用于中断上下文
ARM处理器运行的linux系统1G虚拟内存的划分:重启开发板,让linux内核启动观察内核的启动信息,获取到划分的内容:
区域名 起始地址 结束地址 大小
vector : 0xffff0000 - 0xffff1000 ( 4 kB) //异常向量表
fixmap : 0xfff00000 - 0xfffe0000 ( 896 kB) //固定内存映射区
DMA : 0xff000000 - 0xffe00000 ( 14 MB) //DMA内存映射区(DMA设备)
vmalloc : 0xf4800000 - 0xfc000000 ( 120 MB) //动态内存映射区
lowmem : 0xc0000000 - 0xf4000000 ( 832 MB) //直接内存映射区
modules : 0xbf000000 - 0xc0000000 ( 16 MB) //模块的加载区
.init : 0xc0008000 - 0xc0037000 ( 188 kB) //初始化段
.text : 0xc0037000 - 0xc0843000 (8240 kB) //代码段
.data : 0xc0844000 - 0xc0899c40 ( 344 kB) //数据段
四,块设备内核驱动:linux内核内存分配相关的函数,写到驱动.c里面的函数
(1)kmalloc,函数原型:void *kmalloc ( size_t size, gfp_t flags )
函数功能:从直接内存映射区分配内存,分配的内存访问效率最高
函数特点:分配的内存物理和虚拟内存都是连续的;分配的内存大小最小为32字节,最大4MB(老版本内核128KB)
函数参数:
size:指定分配内存的大小,单位字节
flags:指定分配内存是的行为,一般使用宏GFP_KERNEL:分配内存是,如果使用此宏,就是告诉内核,请内核努力将这次内存的分配搞定,如果内存不足了,会进行休眠操作,直到有空闲的内存,所以:此宏不能用于中断上下文!GFP_ATOMIC:分配内存是,如果内存不足,不会导致休眠操作,而是立即返回,所以可以用于中断上下文
返回值:返回分配的内核虚拟内存的首地址
(2)内存不再使用,记得要释放:kfree。函数原型:void kfree(void *addr)
内存释放kfree举例说明:
char *addr;
addr = kmalloc(0x100000, GFP_KERNEL);
memcpy(addr, "hello,world", 12);
kfree(addr); (3), __get_free_pages / free_pages —— linux系统一个页(page) = 4KB
函数原型:unsigned long __get_free_pages ( gfp_t flags, unsigned order )
函数功能:从直接内存映射区分配内存,内存访问效率高
函数特点:既然从直接内存映射区分配内存,物理和虚拟上都连续;分配内存的大小最小为1页,最大4MB
函数参数:
flgas:指定分配内存是的行为,一般使用宏GFP_KERNEL:分配内存是,如果使用此宏,就是告诉内核,请内核努力将这次内存的分配搞定,如果内存,不足了,会进行休眠操作,直到有空闲的内存,所以:此宏不能用于中断上下文!GFP_ATOMIC:分配内存是,如果内存不足,不会导致,休眠操作,而是立即返回,所以可以用于中断上下文
order: order = 0,分配1页
order = 1,分配2页
order = 2,分配4页
order = 3,分配8页
返回值:保存申请的内核虚拟内存的首地址使用时,注意数据类型的转换内存不再使用时,记得要释放内存:
void free_pages(unsigned long addr, int order);
例子:
unsigned long addr;
addr = __get_free_pages(GFP_KERNEL, 2);
memcpy( (char *)addr, "hello,world", 12 );
free_pages(addr, 2);
(4). vmalloc / vfree 函数原型:void * vmalloc ( int size )
函数功能:从动态内存映射区分配内存
函数特点:
A,分配的内核虚拟地址是连续的,但是对应的物理地址,不一定连续,所以内存的访问效率不高
B,最大分配的内存理论值为120MB
C,它分配内存是,如果内存不足,同样会导致休眠所以不能用于中断上下文
size:指定分配内存的大小
返回值:返回分配的内核虚拟内存的首地址
释放内存:void vfree ( void *addr );例子:
void * addr;
addr = vmalloc(0x200000);
memcpy(addr, "hello,world", 12);
vfree(addr);(5)在内核的启动参数中添加vmalloc=大小(例如vmalloc=250M),表示内核启动的时候,将动态内存映射区的大小由原先的,120M扩展到250M
例子: 重启开发板,进入uboot的命令行,设置:
setenv bootargs root=/dev/nfs nfsroot=192.168.1.8:/opt/rootfs ip=192.168.1.110:192.168.1.8:192.168.1.1:255.255.255.0::eth0:on init=/linuxrc console=ttySAC0,115200 vmalloc=250M
boot //启动linux系统观察内核打印信息,查看vmalloc区的大小是否发生变化(6)linux内核外设物理地址映射到内核虚拟地址的方法:"虚拟地址"分内核虚拟地址和用户虚拟地址
不管是用户空间还是内核空间,任何程序都不能直接访问外设的物理地址,必须将外设的物理地址映射到用户的虚拟地址上或者内核的虚拟地址上,才可以直接访问外设的物理地址。
访问外设物理地址要使用ioremap函数,它的作用是将外设的物理地址映射内核的虚拟地址上,一旦完成这种映射,将来驱动访问这个映射的内核虚拟地址, 就是在访问对应的物理地址。函数原型:void * ioremap ( unsigned long phys_addr, unsigned long size )
函数参数:
phys_addr:要映射的外设起始物理地址
size:要访问的外设所占用物理内存的大小(例如寄存器大小4字节)
返回值:返回映射的内核虚拟的起始地址
如果外设的物理地址不在使用,记得要解除地址映射:
void iounmap(void *addr)
LED的寄存器访问
物理地址 映射的内核虚拟地址
0xE0200080 gpiocon
0xE0200084 gpiodata
unsigned long *gpiocon, *gpiodata;
gpiocon = ioremap(0xE0200080, 4); //gpiocon保存的就是物理地址0xE0200080的内核虚拟地址
gpiodata = ioremap(0xE0200084, 4); //gpiodata保存的就是物理地址0xE0200084的内核虚拟地址
或者物理地址 映射的内核虚拟地址
0xE0200080 gpiocon
0xE0200084 gpiocon + 1
unsigned long *gpiocon, *gpiodata;
gpiocon = ioremap(0xE0200080, 8); //gpiocon保存的就是物理地址0xE0200080的内核虚拟地址,映射的8个字节中有4字节是gpiodata
gpiodata = gpiocon + 1;
此方法在映射时,要保证物理地址是连续的!
一旦完成这种映射,驱动即可访问映射的内核虚拟地址:
配置GPIO为输出口,输出0:
*gpiocon &= ~(0xf << 12);
*gpiocon |= (1 << 12)
*gpiodata &= ~(1 << 3);4,AD9226驱动代码:
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define DEVICE_NUM 16
#define ADC_MEM_PAGE_NUM 128
#define ADC_BUFF_SIZE 16384
#define ADC_MEM_BUFF_SIZE (ADC_BUFF_SIZE * ADC_MEM_PAGE_NUM)
#define AX_ADC_MAGIC 'x' //定义幻数
#define AX_ADC_MAX_NR 2 //定义命令的最大序数,
#define COMM_GET_CURPAGENUM _IO(AX_ADC_MAGIC, 1)
#define COMM_SET_TEST _IO(AX_ADC_MAGIC, 0)
#define AX_MAJOR 181
#define AX_DEVICES 3
struct ax_adc
{
struct class *cls;
int major;
char devname[16];
u8 *mem_vraddr1;
u32 mem_phyaddr1;
u8 *mem_vraddr2;
u32 mem_phyaddr2;
int index;
struct mutex mutex;
int mijor;
int ax_bufState;
u8 *ax_mem_msg_buf;
int ax_mem_curpage_num;
int irq;
void __iomem *base_address;
struct device *dev;
resource_size_t remap_size;
};
static struct ax_adc ax_dev[DEVICE_NUM];
static int ax_device_num = 0;
static unsigned char * malloc_reserved_mem(long size)
{
unsigned char *p = kmalloc(size, GFP_KERNEL);
unsigned char *tmp = p;
unsigned int i, n;
if(NULL == p)
{
printk("Error : malloc_reserved_mem kmalloc failed!\n");
return NULL;
}
n = size/(ADC_BUFF_SIZE) + 1;
if(0 == size % (ADC_BUFF_SIZE))
{
-- n;
}
for(i =0; i < n; ++i)
{
SetPageReserved(virt_to_page(tmp));
tmp += ADC_BUFF_SIZE;
}
return p;
}
static int ax_adc_mmap(struct file *file, struct vm_area_struct *vma)
{
struct inode *inode = file_inode(file);
int imi = iminor(inode);
int ima = imajor(inode);
int i = 0;
for(i=0;i=ax_device_num-1)
return 0;
}
unsigned long offset = vma->vm_pgoff << PAGE_SHIFT;
unsigned long physics = ((unsigned long)ax_dev[i].ax_mem_msg_buf)- PAGE_OFFSET;
unsigned long mypfn = physics >> PAGE_SHIFT;
unsigned long vmsize = vma->vm_end-vma->vm_start;
unsigned long psize = ADC_MEM_BUFF_SIZE - offset;
if(vmsize > psize)
return -ENXIO;
if(remap_pfn_range(vma,vma->vm_start,mypfn,vmsize,vma->vm_page_prot))
return -EAGAIN;
return 0;
}
static long ax_adc_ioctl(struct file *file, unsigned int cmd, unsigned long arg)
{
int ret = 0;
if(_IOC_TYPE(cmd) != AX_ADC_MAGIC) return - EINVAL;
if(_IOC_NR(cmd) > AX_ADC_MAX_NR) return - EINVAL;
switch(cmd)
{
case COMM_GET_CURPAGENUM:
if(arg>=0 && arg =ax_device_num-1)
{
printk(KERN_ALERT "ax_adc_interrupt irq error\n");
return IRQ_HANDLED;
}
}
int count = 0;
mutex_lock(&ax_dev[index].mutex);
int state = readl(ax_dev[index].base_address + 0x3 * 4);
ax_dev[index].ax_bufState = (state>>3) & 0x7;
count = readl(ax_dev[index].base_address + 0x5 * 4);
if(ax_dev[index].ax_mem_msg_buf==NULL)
{
printk(KERN_ALERT "ax_adc_interrupt ax_mem_msg_buf=NULL error\n");
}
else
{
if(ax_dev[index].ax_mem_curpage_num<0)
{
printk(KERN_ALERT "ax_adc curpage error\n");
}
else
if(ax_dev[index].ax_mem_curpage_num< ADC_MEM_PAGE_NUM ) //物理内存数据拷贝到共享内存区域
{
if(ax_dev[index].ax_bufState)
{
memcpy(ax_dev[index].ax_mem_msg_buf+ax_dev[index].ax_mem_curpage_num*ADC_BUFF_SIZE,ax_dev[index].mem_vraddr2,ADC_BUFF_SIZE);
}
else
{ memcpy(ax_dev[index].ax_mem_msg_buf+ax_dev[index].ax_mem_curpage_num*ADC_BUFF_SIZE,ax_dev[index].mem_vraddr1,ADC_BUFF_SIZE);
}
ax_dev[index].ax_mem_curpage_num++;
if(ax_dev[index].ax_mem_curpage_num>= ADC_MEM_PAGE_NUM)
ax_dev[index].ax_mem_curpage_num = 0;
}
}
writel(1, ax_dev[index].base_address + 0x4 * 4);
udelay(1);
writel(0, ax_dev[index].base_address + 0x4 * 4);
mutex_unlock(&ax_dev[index].mutex);
return IRQ_HANDLED;
}
static int ax_adc_probe(struct platform_device *pdev)
{
struct ax_adc ax;
struct resource *res;
int err, i;
struct device *dev;
dev_t devt;
for(i=0;idev, MKDEV(ax.major, ax.mijor), NULL, ax.devname);
if (IS_ERR(dev))
{
class_destroy(ax.cls);
unregister_chrdev(ax.major, ax.devname);
if(i>=DEVICE_NUM-1)
{
return 0;
}
}
else
{
ax_device_num++;
break;
}
}
res = platform_get_resource(pdev, IORESOURCE_MEM, 0);
if(res == NULL)
{
printk(KERN_ALERT "ax_adc_probe res error!\n");
return -ENOENT;
}
ax.base_address = devm_ioremap_resource(&pdev->dev, res);
if (IS_ERR(ax.base_address))
{
return PTR_ERR(ax.base_address);
}
ax.remap_size = resource_size(res);
ax.irq = platform_get_irq(pdev,0);
if (ax.irq <= 0)
{
return -ENXIO;
}
mutex_init(&ax.mutex);
ax.dev = &pdev->dev;
ax.ax_bufState = 0;
ax.ax_mem_msg_buf = NULL;
ax.ax_mem_curpage_num = 0;
ax.mem_vraddr1 = dma_alloc_writecombine(ax.dev, ADC_BUFF_SIZE, &ax.mem_phyaddr1, GFP_KERNEL);
if (!ax.mem_vraddr1)
{
goto fail1;
}
ax.mem_vraddr2 = dma_alloc_writecombine(ax.dev, ADC_BUFF_SIZE, &ax.mem_phyaddr2, GFP_KERNEL);
if (!ax.mem_vraddr2)
goto fail2;
writel(ax.mem_phyaddr1, ax.base_address + 0x13 * 4);
writel(ax.mem_phyaddr2, ax.base_address + 0x14 * 4);
writel(ADC_BUFF_SIZE, ax.base_address + 0x11 * 4);
writel(0, ax.base_address + 0x12 * 4);
writel(1, ax.base_address + 0x12 * 4);
ax.ax_mem_msg_buf = malloc_reserved_mem(ADC_MEM_BUFF_SIZE);
if(ax.ax_mem_msg_buf==NULL)
{
printk(KERN_ALERT "ax_adc_probe malloc error\n");
goto fail3;
}
err = request_threaded_irq(ax.irq, NULL,
ax_adc_interrupt,
IRQF_TRIGGER_RISING | IRQF_ONESHOT,
ax.devname, &ax);
if (err)
{
printk(KERN_ALERT "ax_adc_probe irq error=%d\n", err);
goto fail3;
}
memcpy(&ax_dev[i], &ax, sizeof(struct ax_adc));
platform_set_drvdata(pdev, &ax_dev[i]);
return 0;
fail3:
if(ax.ax_mem_msg_buf!=NULL)
{
kfree(ax.ax_mem_msg_buf);
ax.ax_mem_msg_buf = NULL;
}
free_irq(ax.irq, &ax);
dma_free_writecombine(ax.dev, ADC_BUFF_SIZE, ax.mem_vraddr2, ax.mem_phyaddr2);
fail2:
dma_free_writecombine(ax.dev, ADC_BUFF_SIZE, ax.mem_vraddr1, ax.mem_phyaddr1);
fail1:
device_destroy(ax.cls, MKDEV(ax.major, ax.mijor));
class_destroy(ax.cls);
unregister_chrdev(ax.major, ax.devname);
return -ENOMEM;
}
static int ax_adc_remove(struct platform_device *pdev)
{
int i = 0;
for(i=0;i 5,如何添加ad9226.ko到内核:
(1)往/home/alinx/linux-xlnx-xilinx-v2017.4/drivers/dma/xilinx/中添加驱动程序xilinx_ad9226.c
(2)在makefile中添加obj-$(CONFIG_XILINX_DMA) += xilinx_ad9226.o
(3)在kconfig中添加
config XILINX_AD9226
tristate "ADC 9226 for XILINX"
depends on GPIOLIB
select IIO_BUFFER
select IIO_TRIGGERED_BUFFER
help
say yes here to build support for xilinx Devices:
adc to digital converters(ADC)扇区是硬件传输数据的基本单位,硬件一次传输一个扇区的数据到内存中。但是和扇区不同的是,块是虚拟文件系统传输数据的基本单位。在Linux中,块的大小必须是2的幂,但是不能超过一个页的大小(4k)。(在X86平台,一个页的大小是4094个字节,所以块大小可以是512,1024,2048,4096)。
四, 将外设的物理地址映射用户的虚拟地址:
一个物理地址可以由多个对应的虚拟地址,如果用户在用户空间想直接来访问硬件外设,只需利用mmap将外设的物理地址映射用户的虚拟地址上;一旦完成映射,将来用户在用户空间放置映射的这个用户,虚拟地址就是在访问外设的物理地址。
1,mmap系统调用函数:mmap的功能就是将外设的物理地址映射到用户虚拟地址上
void *addr;
int fd = open("a.txt", O_RDWR);
addr = mmap(0, 0x1000, PROT_READ|PROT_WRITE,MAP_SHARED, fd, 0);函数功能:将文件a.txt映射到用户3G虚拟内存的MMAP虚拟内存映射区中,一旦完成这种映射,将来用户访问这块用户虚拟内存区域就是在访问对应的文件。函数本质:与其说是将一个文件映射到用户的虚拟地址上不如说是将这个文件对应的硬件的物理地址,映射用户的虚拟地址上,将来用户访问这个用户虚拟地址就是在访问对应的外设的物理地址。
参数说明:
0:告诉内核,请内核在MMAP虚拟内存区域找一块空闲的内存用来映射硬件外设的物理地址
0x1000:要找的空闲虚拟内存区域的大小
PROT_READ|PROT_WRITE:给这块空闲的虚拟内存区域赋予的相关读写权限
fd:要映射的硬件外设
0:文件偏移量
返回值addr:返回内核帮你找的空闲虚拟内存区域的首地址
//将来访问这块映射的用户虚拟内存区域就是在访问对应的硬件外设的物理地址
memcpy(addr, "1234", 4);
2,mmap系统调用函数实现过程:
<1>.当应用程序调用mmap系统调用函数
<2>首先调用到C库的mmap函数实现
<3>C库的mmap函数实现将做两件事:保存mmap系统调用号到r7 和 调用svc指令触发软中断异常
<4>一旦触发软中断异常,最终CPU跑到软中断的处理入口地址
<5>软中断的处理入口地址做两件事:
A,从r7中取出之前保存的系统调用号。B,以系统调用号为下标在系统调用表中找到对应的内核函数sys_mmap。
<6>调用内核已经编写好得sys_mmap,此函数做三件事:
A,在MMAP虚拟内存区域帮你找一块空闲的虚拟内存
B,内核找到空闲虚拟内存区域以后,内核会用,结构体struct vm_area_struct分配一个对象,然后根据用户mmap系统调用函数传递参数作为属性初始化这个对象,这个对象就是来描述内核帮你找到的这块空闲的虚拟内存
struct vm_area_struct
{
unsigned long vm_start; //空闲用户虚拟内存的首地址
unsigned long vm_end; //结束地址
pgprot_t vm_page_prot; //访问权限(PROT_READ|PROT_WRITE)
unsigned long vm_pgoff; //偏移量
};C, 最终sys_mmap调用底层驱动的mmap接口,并且内核将第2步创建这个对象的首地址传递给底层驱动的mmap
接口,将来底层驱动的mmap接口可以通过这个对象的指针来获取到用户空闲虚拟内存的属性 (PROT_READ|PROT_WRITE,起始地址,大小,偏移量等等)
3,底层驱动的mmap接口所做的调用:永远仅做只做唯一的事情,将外设的物理地址映射到用户的虚拟地址上,后续如何访问硬件,跟mmap没有关系。
(1)底层驱动的mmap接口永远只做一件事:将已知的物理地址和已知的用户虚拟地址,进行映射即可,将来用户如何访问硬件跟驱动没有关系了,将来对硬件的访问都是在用户空间的应用程序中完成。
“已知的用户虚拟地址”:底层驱动mmap接口可以通过传递过来的对象指针获取用户虚拟内存区域的属性。
底层驱动的mmap类似“媒婆”,底层驱动的mmap接口:
struct file_operations
{
int (*mmap)(struct file *file, struct vm_area_struct *vma)
};(2)mmap函数参数:
file:文件指针
vma:此指针变量指向内核sys_mmap创建的描述空闲的用户虚拟内存区域属性对象
mmap接口就可以通过此指针来后去空闲的虚拟内存的属性
总结:底层驱动的mmap就可以将已知的物理地址(通过原理图和芯片手册)和已知的用户虚拟地址(通过vma指针获取)进行映射即可,"万事俱备只欠东风",接下来只需调用以下函数("东风")即可完成最终的映射
(3) int remap_pfn_range(struct vm_area_struct *vma, unsigned long addr, unsigned long pfn, unsigned long size, pgprot_t prot)
函数功能:将已知的物理地址和已知的用户虚拟地址进行映射
函数参数:
vma:传递指向内核创建的描述空闲虚拟内存区域属性的对象
addr:已知的用户虚拟起始地址(vm_start)
pfn:已知的物理起始地址,注意,需要将物理起始地址>>12
size:用户虚拟内存的大小(vm_end - vm_start)
prot:访问权限(vm_page_prot)
切记:物理地址必须页面大小的整数倍! 用0xe0200080做地址映射就不行!扇区是硬件传输数据的基本单位,硬件一次传输一个扇区的数据到内存中。但是和扇区不同的是,块是虚拟文件系统传输数据的基本单位。在Linux中,块的大小必须是2的幂,但是不能超过一个页的大小(4k)。(在X86平台,一个页的大小是4094个字节,所以块大小可以是512,1024,2048,4096)。
物理地址 用户虚拟地址
0xE0200000 vm_start->最终就是mmap系统调用函数的返回值addr
0xE0200080 vm_start + 0x80
0xE0200084 vm_start + 0x84
(4)总结调用关系:应用程序mmap->软中断->内核sys_mmap->驱动mmap接口
五,应用层地址映射
1,打开接口使用open,并将ADC存入的用户物理地址映射到应用程序中的用户虚拟地址
recvDevFd1 =open("/dev/ax_adc1",O_RDWR);
recvDevFd2 =open("/dev/ax_adc2",O_RDWR);
if ((0 >= recvDevFd1) && (0 >= recvDevFd2))
{
printf("open device failed !"\n);
return;
}
if(recvDevFd1>0)
{
m_pShareMem1 = mmap(NULL, ADC_MEM_BUFF_SIZE,PROT_READ,MAP_SHARED, recvDevFd1,0);
if( m_pShareMem1 == MAP_FAILED )
{
printf("Error : getMemMsgBuf() fail mmap!\n");
}
}
if(recvDevFd2>0)
{
m_pShareMem2 = mmap(NULL, ADC_MEM_BUFF_SIZE,PROT_READ,MAP_SHARED, recvDevFd2,0 );
if( m_pShareMem2 == MAP_FAILED )
{
printf("Error : getMemMsgBuf() fail mmap!\n");
}
}2,内存拷贝memcpy
if(ioctl(recvDevFd1, COMM_GET_CURPAGENUM,0)>0)
if(m_bepagenum1>m_curpagenum1)
{
memcpy(paintBuff1, m_pShareMem1 + (m_bepagenum1+1)*ADC_BUFF_SIZE, DISPLAYPIXELS * 2);
}else if(m_bepagenum1 < m_curpagenum1)
{
memcpy(paintBuff1, m_pShareMem1 + (m_bepagenum1+1)*ADC_BUFF_SIZE, DISPLAYPIXELS * 2);
}else{
memcpy(paintBuff1, m_pShareMem1 + (m_curpagenum1+1)*ADC_BUFF_SIZE, DISPLAYPIXELS * 2);
}
六,linux内核分离思想
1,本质:将原先驱动中的硬件和软件撤离分开, 软件一旦写好,将来硬件发生变化,无需改动软件,要改只改硬件部分即可!提高驱动的可移植性!这样驱动开发者的重心放在硬件部分即可,软件一旦写好需要改动!
2,linux内核分离思想的实现基于platform机制原理
总结:如果要采用platform机制实现一个硬件设备驱动,驱动开发者只需要关注两个数据结构即可:
struct platform_device
struct platform_driver
剩下的:什么遍历,什么匹配,什么调用(probe),什么传参(传硬件节点首地址)都四个"什么"统统由内核来实现!
3,struct platform_device数据结构的使用编程步骤
struct platform_device
{
const char * name;
int id;
u32 num_resources;
struct resource * resource;
};数据结能:描述纯硬件信息
成员说明:name:描述硬件节点名称,此字段将来用于匹配,必须要初始化!
id:描述硬件节点的编号,如果dev链表上只有一个名称为name的硬件节点,id给-1,
如果dev链表上有多个名称同时为name的硬件节点,通过id进行区分:0,1,2...
4,resource:用来装在纯硬件信息内容
strcut resource
{
unsigned long start;
unsigned long end;
unsigned long flags;
...
};说明:描述纯硬件信息内容
start:硬件起始信息
end:硬件结束信息
flags:硬件信息的标志,一般指定以下标志
IORESOURCE_MEM:表示这个硬件信息为地址信息 —— 例如:0xE0200080,这个信息就用此宏来表示
IORESOURCE_IRQ:表示这个硬件信息为GPIO信息——例如:GPC1_3中的3(GPC1组的第3个),这个信息就用此宏表示
+IRQ_EINT(0)(第一个中断),这个信息也可以用此宏来表示
例如:描述LED1,LED2的硬件信息:
struct resource led_info[] =
{
{ //描述寄存器的物理地址信息
.start = 0xE0200080, //起始地址
.end = 0xE0200080 + 8, //结束地址
.flags = IORESOURCE_MEM //地址信息 },
{ //描述LED1的GPIO编号信息
.start = 3, //第3个GPIO
.end = 3, //第3个GPIO
.flags = IORESOURCE_IRQ //GPIO信息
},
{ //描述LED2的GPIO编号信息
.start = 4, //第3个GPIO
.end = 4, //第3个GPIO
.flags = IORESOURCE_IRQ //GPIO信息
}
};总结:如果将来硬件上发生变化,只需resource描述的,硬件信息即可!num_resources:用struct resource描述的硬件信息的个数ARRAY_SIZE(led_info)
5,配套函数:platform_device_register(&硬件节点对象);功能如下:
(1).将定义初始化的硬件节点添加到dev链表上
(2).内核会帮你遍历drv链表,取出drv链表上每一个软件节点跟这个要注册的硬件节点进行匹配,匹配通过内核调用总线提供的match,比较软件节点和硬件节点的name是否相等,如果相等,内核调用软件节点的probe函数,并且把这个要注册的硬件节点的首地址传给 + probe函数,完成硬件和软件的再次结合!如果匹配不成功,没关系,硬件节点静静等待着软件节点的到来!
platform_device_unregister(&硬件节点对象);
从dev链表中将硬件节点对象删除,同时内核调用匹配成功的软件节点的remove函数
案例:利用platform机制优化之前的LED驱动程序
#include
#include
#include
//定义初始化描述LED的硬件信息
//如果将来硬件发生改变,只需该此数据结构即可
static struct resource led_info[] =
{//寄存器地址信息
{
.start = 0xE0200080,//起始地址
.end = 0xE0200080 + 8, //结束地址
.flags = IORESOURCE_MEM //地址类信息
},
//GPC1_3的GPIO信息
{
.start = 3, //第3个GPIO
.end = 3,
.flags = IORESOURCE_IRQ //GPIO类信息
},
//GPC1_4的GPIO信息
{
.start = 4, //第3个GPIO
.end = 4,
.flags = IORESOURCE_IRQ //GPIO类信息
}
};
//仅仅是去除警告
static void led_release(struct device *dev) {}
//定义初始化描述LED的硬件节点对象
static struct platform_device led_dev =
{
.name = "tarena",//硬件节点对象名,用于匹配
.id = -1,//编号
.resource = led_info, //装载硬件信息
.num_resources = ARRAY_SIZE(led_info), //硬件信息个数
.dev =
{
.release = led_release //仅仅去除警告
}
};
static int led_dev_init(void)
{
//1.添加硬件节点到dev链表
//2.什么遍历,什么匹配,什么调用,什么传参由此函数完成
platform_device_register(&led_dev);
return 0;
}
static void led_dev_exit(void)
{
//从dev卸载硬件节点
platform_device_unregister(&led_dev);
}
module_init(led_dev_init);
module_exit(led_dev_exit);
MODULE_LICENSE("GPL"); 6, struct platform_driver 数据结构的使用编程步骤
struct platform_driver
{
int (*probe) (struct platform_device *pdev);
int (*remove) (struct platform_device *pdev);
struct device_driver driver;
...
}; 功能:描述硬件对应的纯软件信息(if...else,swtich..case,fops,miscdevice等)
函数成员:
driver:重点关注其中的name字段,将来用于匹配,必须要初始化
probe:硬件节点和软件节点匹配成功,内核调用此函数形参pdev指向匹配成功的硬件节点对象,将来probe函数可以通过此参数获取到纯硬件信息
remove:当从dev删除硬件节点或者从drv删除软件节点内核都会调用remove函数形参pdev指向匹配成功的硬件节点对象,将来probe函数可以通过此参数获取到纯硬件信息
总结:probe函数是否被调用至关重要!如果probe函数被内核调用,说明一个完整的驱动程序诞生,也就预示着硬件和软件匹配成功!probe函数一般所做的工作:
(1)通过形参pdev获取纯硬件信息
(2)处理获取到的纯硬件信息, 该申请的申请(GPIO资源,中断资源)
该映射的映射(物理地址映射到内核虚拟地址)
该初始化的初始化(配置GPIO为输出口等等)
该注册的注册(中断处理函数)
(3)注册字符设备驱动或者混杂设备驱动,关键是为了给用户提供访问硬件的操作接口
总结:采用platform机制实现驱动,也就是将原先驱动中的入口函数所做的事情现在统统移到probe函数中完成(因为probe函数的调用,预示着一个完整的驱动诞生,有了硬件还有了软件)remove和probe是死对头!
7,配套函数:platform_driver_register ( &软件节点对象 );
函数功能:
(1)将定义初始化的软件节点添加到drv链表上
(2)内核会帮你遍历dev链表,取出dev链表上每一个硬件节点,跟这个要注册的软件节点进行匹配,匹配通过内核调用总线提供
的match,比较软件节点和硬件节点的name是否相等,如果相等,内核调用软件节点的probe函数,并且把 匹配成功的硬件节点的首地址传给probe函数,完成硬件和软件的再次结合!如果匹配不成功,没关系,软件节点静静等待着硬件节点的到来!
platform_driver_unregister ( &软件节点对象 );