部署一套完整的Kubernetes高可用集群(二进制,最新版v1.18)下
七、高可用架构(扩容多Master架构)
Kubernetes作为容器集群系统,通过健康检查+重启策略实现了Pod故障自我修复能力,通过调度算法实现将Pod分布式部署,并保持预期副本数,根据Node失效状态自动在其他Node拉起Pod,实现了应用层的高可用性。
针对Kubernetes集群,高可用性还应包含以下两个层面的考虑:Etcd数据库的高可用性和Kubernetes Master组件的高可用性。 而Etcd我们已经采用3个节点组建集群实现高可用,本节将对Master节点高可用进行说明和实施。
Master节点扮演着总控中心的角色,通过不断与工作节点上的Kubelet和kube-proxy进行通信来维护整个集群的健康工作状态。如果Master节点故障,将无法使用kubectl工具或者API做任何集群管理。
Master节点主要有三个服务kube-apiserver、kube-controller-manager和kube-scheduler,其中kube-controller-manager和kube-scheduler组件自身通过选择机制已经实现了高可用,所以Master高可用主要针对kube-apiserver组件,而该组件是以HTTP API提供服务,因此对他高可用与Web服务器类似,增加负载均衡器对其负载均衡即可,并且可水平扩容。
多Master架构图:
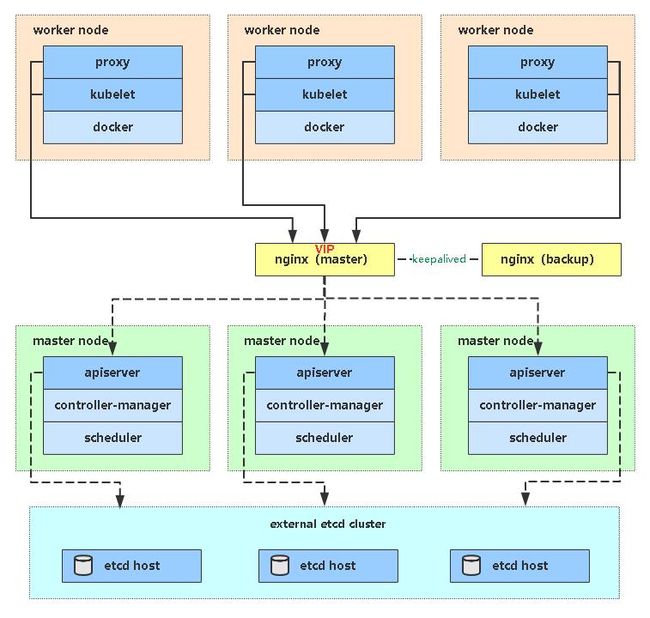
7.1 安装Docker
同上,不再赘述。
7.2 部署Master2 Node(192.168.31.74)
Master2 与已部署的Master1所有操作一致。所以我们只需将Master1所有K8s文件拷贝过来,再修改下服务器IP和主机名启动即可。
1. 创建etcd证书目录
在Master2创建etcd证书目录:
mkdir -p /opt/etcd/ssl
2. 拷贝文件(Master1操作)
拷贝Master1上所有K8s文件和etcd证书到Master2:
scp -r /opt/kubernetes [email protected]:/opt
scp -r /opt/cni/ [email protected]:/opt
scp -r /opt/etcd/ssl [email protected]:/opt/etcd
scp /usr/lib/systemd/system/kube* [email protected]:/usr/lib/systemd/system
scp /usr/bin/kubectl [email protected]:/usr/bin
3. 删除证书文件
删除kubelet证书和kubeconfig文件:
rm -f /opt/kubernetes/cfg/kubelet.kubeconfig
rm -f /opt/kubernetes/ssl/kubelet*
4. 修改配置文件IP和主机名
修改apiserver、kubelet和kube-proxy配置文件为本地IP:
vi /opt/kubernetes/cfg/kube-apiserver.conf
...
--bind-address=192.168.31.74 \
--advertise-address=192.168.31.74 \
...
vi /opt/kubernetes/cfg/kubelet.conf
--hostname-override=k8s-master2
vi /opt/kubernetes/cfg/kube-proxy-config.yml
hostnameOverride: k8s-master2
5. 启动设置开机启动
systemctl daemon-reload
systemctl start kube-apiserver
systemctl start kube-controller-manager
systemctl start kube-scheduler
systemctl start kubelet
systemctl start kube-proxy
systemctl enable kube-apiserver
systemctl enable kube-controller-manager
systemctl enable kube-scheduler
systemctl enable kubelet
systemctl enable kube-proxy
6. 查看集群状态
kubectl get cs
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-1 Healthy {"health":"true"}
etcd-2 Healthy {"health":"true"}
etcd-0 Healthy {"health":"true"}
7. 批准kubelet证书申请
kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
node-csr-JYNknakEa_YpHz797oKaN-ZTk43nD51Zc9CJkBLcASU 85m kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending
kubectl certificate approve node-csr-JYNknakEa_YpHz797oKaN-ZTk43nD51Zc9CJkBLcASU
kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master Ready <none> 34h v1.18.3
k8s-master2 Ready <none> 83m v1.18.3
k8s-node1 Ready <none> 33h v1.18.3
k8s-node2 Ready <none> 33h v1.18.3
如果你在学习中遇到问题或者文档有误可联系阿良~ 微信: init1024
7.3 部署Nginx负载均衡器
kube-apiserver高可用架构图:
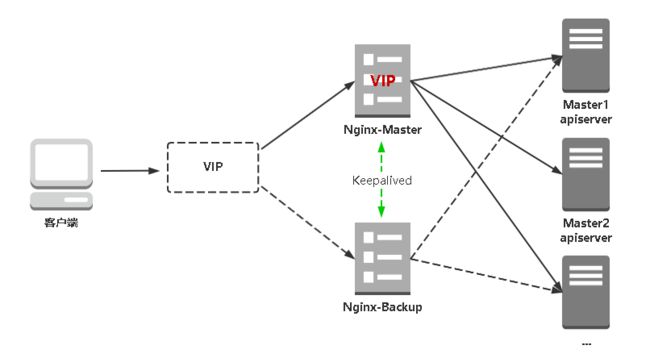
- Nginx是一个主流Web服务和反向代理服务器,这里用四层实现对apiserver实现负载均衡。
- Keepalived是一个主流高可用软件,基于VIP绑定实现服务器双机热备,在上述拓扑中,Keepalived主要根据Nginx运行状态判断是否需要故障转移(偏移VIP),例如当Nginx主节点挂掉,VIP会自动绑定在Nginx备节点,从而保证VIP一直可用,实现Nginx高可用。
1. 安装软件包(主/备)
yum install epel-release -y
yum install nginx keepalived -y
2. Nginx配置文件(主/备一样)
cat > /etc/nginx/nginx.conf << "EOF"
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
include /usr/share/nginx/modules/*.conf;
events {
worker_connections 1024;
}
# 四层负载均衡,为两台Master apiserver组件提供负载均衡
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
server 192.168.31.71:6443; # Master1 APISERVER IP:PORT
server 192.168.31.74:6443; # Master2 APISERVER IP:PORT
}
server {
listen 6443;
proxy_pass k8s-apiserver;
}
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
server {
listen 80 default_server;
server_name _;
location / {
}
}
}
EOF
3. keepalived配置文件(Nginx Master)
cat > /etc/keepalived/keepalived.conf << EOF
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_MASTER
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
}
vrrp_instance VI_1 {
state MASTER
interface ens33 # 修改为实际网卡名
virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的
priority 100 # 优先级,备服务器设置 90
advert_int 1 # 指定VRRP 心跳包通告间隔时间,默认1秒
authentication {
auth_type PASS
auth_pass 1111
}
# 虚拟IP
virtual_ipaddress {
192.168.31.88/24
}
track_script {
check_nginx
}
}
EOF
-
vrrp_script:指定检查nginx工作状态脚本(根据nginx状态判断是否故障转移)
-
virtual_ipaddress:虚拟IP(VIP)
检查nginx状态脚本:
cat > /etc/keepalived/check_nginx.sh << "EOF"
#!/bin/bash
count=$(ps -ef |grep nginx |egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
exit 1
else
exit 0
fi
EOF
chmod +x /etc/keepalived/check_nginx.sh
4. keepalived配置文件(Nginx Backup)
cat > /etc/keepalived/keepalived.conf << EOF
global_defs {
notification_email {
[email protected]
[email protected]
[email protected]
}
notification_email_from [email protected]
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id NGINX_BACKUP
}
vrrp_script check_nginx {
script "/etc/keepalived/check_nginx.sh"
}
vrrp_instance VI_1 {
state BACKUP
interface ens33
virtual_router_id 51 # VRRP 路由 ID实例,每个实例是唯一的
priority 90
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
192.168.31.88/24
}
track_script {
check_nginx
}
}
EOF
上述配置文件中检查nginx运行状态脚本:
cat > /etc/keepalived/check_nginx.sh << "EOF"
#!/bin/bash
count=$(ps -ef |grep nginx |egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
exit 1
else
exit 0
fi
EOF
chmod +x /etc/keepalived/check_nginx.sh
注:keepalived根据脚本返回状态码(0为工作正常,非0不正常)判断是否故障转移。
5. 启动并设置开机启动
systemctl daemon-reload
systemctl start nginx
systemctl start keepalived
systemctl enable nginx
systemctl enable keepalived
6. 查看keepalived工作状态
ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:04:f7:2c brd ff:ff:ff:ff:ff:ff
inet 192.168.31.80/24 brd 192.168.31.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.31.88/24 scope global secondary ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe04:f72c/64 scope link
valid_lft forever preferred_lft forever
可以看到,在ens33网卡绑定了192.168.31.88 虚拟IP,说明工作正常。
7. Nginx+Keepalived高可用测试
关闭主节点Nginx,测试VIP是否漂移到备节点服务器。
在Nginx Master执行 pkill nginx
在Nginx Backup,ip addr命令查看已成功绑定VIP。
8. 访问负载均衡器测试
找K8s集群中任意一个节点,使用curl查看K8s版本测试,使用VIP访问:
curl -k https://192.168.31.88:6443/version
{
"major": "1",
"minor": "18",
"gitVersion": "v1.18.3",
"gitCommit": "2e7996e3e2712684bc73f0dec0200d64eec7fe40",
"gitTreeState": "clean",
"buildDate": "2020-05-20T12:43:34Z",
"goVersion": "go1.13.9",
"compiler": "gc",
"platform": "linux/amd64"
}
可以正确获取到K8s版本信息,说明负载均衡器搭建正常。该请求数据流程:curl -> vip(nginx) -> apiserver
通过查看Nginx日志也可以看到转发apiserver IP:
tail /var/log/nginx/k8s-access.log -f
192.168.31.81 192.168.31.71:6443 - [30/May/2020:11:15:10 +0800] 200 422
192.168.31.81 192.168.31.74:6443 - [30/May/2020:11:15:26 +0800] 200 422
到此还没结束,还有下面最关键的一步。
7.4 修改所有Worker Node连接LB VIP
试想下,虽然我们增加了Master2和负载均衡器,但是我们是从单Master架构扩容的,也就是说目前所有的Node组件连接都还是Master1,如果不改为连接VIP走负载均衡器,那么Master还是单点故障。
因此接下来就是要改所有Node组件配置文件,由原来192.168.31.71修改为192.168.31.88(VIP):
| 角色 | IP |
|---|---|
| k8s-master1 | 192.168.31.71 |
| k8s-master2 | 192.168.31.74 |
| k8s-node1 | 192.168.31.72 |
| k8s-node2 | 192.168.31.73 |
也就是通过kubectl get node命令查看到的节点。
在上述所有Worker Node执行:
sed -i 's#192.168.31.71:6443#192.168.31.88:6443#' /opt/kubernetes/cfg/*
systemctl restart kubelet
systemctl restart kube-proxy
检查节点状态:
kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master Ready <none> 34h v1.18.3
k8s-master2 Ready <none> 101m v1.18.3
k8s-node1 Ready <none> 33h v1.18.3
k8s-node2 Ready <none> 33h v1.18.3
至此,一套完整的 Kubernetes 高可用集群就部署完成了!
PS:如果你是在公有云上,一般都不支持keepalived,那么你可以直接用它们的负载均衡器产品(内网就行,还免费~),架构与上面一样,直接负载均衡多台Master kube-apiserver即可!
如果你在学习中遇到问题或者文档有误可联系阿良~ 微信: init1024
