CART算法
一、Gini公式
![]()
![]()
其中:
 是类别数(label)
是类别数(label)
样本集合  根据特征A 是否取某一值
根据特征A 是否取某一值  被分割成
被分割成 、
、![]()
二、举例
假设我们有一个二元分类问题,数据集包含以下四个样本:
| id | 年龄 | 有工作 | 有房子 |
| 1 | 青年 | 无 | 无 |
| 2 | 中年 | 有 | 有 |
| 3 | 中年 | 无 | 无 |
| 4 | 老年 | 有 | 有 |
可以使用CART算法来建立一个决策树模型。
1、首先,我们需要选择一个特征和阈值来对数据集进行划分。
假设我们选择年龄和阈值a = 青年,将数据集划分成两个子集:
- 子集
- 子集
:{2,3,4},对应类别为{1, 0,1}
对于子集
对于子集
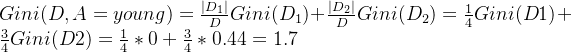
假设我们选择年龄和阈值a = 中年,将数据集划分成两个子集:
- 子集
- 子集
对于子集
对于子集
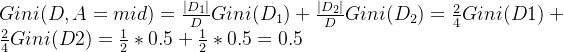
假设我们选择年龄和阈值a = 老年,将数据集划分成两个子集:
- 子集
- 子集
对于子集
对于子集
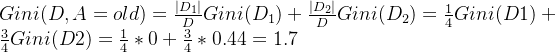
![]() 最小,所以
最小,所以![]() 为
为 的最优切分点
的最优切分点
假设我们选择有工作和阈值a = 有,将数据集划分成两个子集:
- 子集
- 子集
对于子集
对于子集
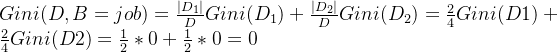
由于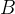 只有一个切分点,所以
只有一个切分点,所以![]() 为的最优切分点
为的最优切分点
2、在,两个特征中,![]() 最小,所以选择特征 为最优特征。
最小,所以选择特征 为最优特征。
于是根节点生成两个子节点,有工作和无工作,都是叶节点,结束。
如果不是叶节点,则重复上述过程。
有工作 = 有
├── 年龄 = young
│ |── 类别为 mid
| └── 类别为 old
└── 无