使用toad库进行机器学习评分卡全流程
1 加载数据
导入模块
import pandas as pd
from sklearn.metrics import roc_auc_score,roc_curve,auc
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import numpy as np
import math
import xgboost as xgb
import toad
from toad.plot import bin_plot, badrate_plot
from matplotlib import pyplot as plt
from sklearn.preprocessing import StandardScaler
from toad.metrics import KS, F1, AUC
from toad.scorecard import ScoreCard
加载数据
# 加载数据
df = pd.read_csv('scorecard.txt')
print(df.info())
df.head()


df.describe()

数据划分
feature_list = list(df.columns)
feature_drop = ['bad_ind','uid','samp_type']
for lt in feature_drop:
feature_list.remove(lt)
df_dev = df[df['samp_type']=='dev']
df_val = df[df['samp_type']=='val']
df_off = df[df['samp_type']=='off']
print(feature_list)
print('dev',df_dev.shape)
print('val',df_val.shape)
print('off',df_off.shape)

简单数据分析
toad.detector.detect(df)

toad库能够同时处理数值型数据和分类型数据。由于没有缺失值,我们不用进行数据填充。
2 特征筛选
使用缺失率、IV和相关系数进行特征筛选。
# 根据缺失值、IV和相关系数进行特征筛选
dev_slt, drop_slt = toad.selection.select(df_dev, df_dev['bad_ind'],
empty=0.7,
iv=0.03,
corr=0.7,
return_drop=True,
exclude=feature_drop)
print('keep:', dev_slt.shape,';drop empty:',drop_slt['empty'].shape,';drop iv:',drop_slt['iv'].shape,';drop_corr:',drop_slt['corr'].shape)
keep: (65304, 12) ;drop empty: (0,) ;drop iv: (1,) ;drop_corr: (0,)
3 卡方分箱
使用toad库,能够对所有特征切分节点,然后进行分箱
# 使用卡方分箱
# 使用卡方分箱
cmb = toad.transform.Combiner()
cmb.fit(dev_slt,
dev_slt['bad_ind'],
method='chi',
min_samples=0.05,
exclude=feature_drop)
bins = cmb.export()
print(bins)
{‘td_score’: [0.7989831262724624], ‘jxl_score’: [0.4197048501965005], ‘mj_score’: [0.3615303943747963], ‘zzc_score’: [0.4469861520889339], ‘zcx_score’: [0.7007847486465795], ‘person_info’: [-0.2610139784946237, -0.1286774193548387, -0.0537175627240143, 0.013863440860215, 0.0626602150537634, 0.078853046594982], ‘finance_info’: [0.0476190476190476], ‘credit_info’: [0.02, 0.04, 0.11], ‘act_info’: [0.1153846153846154, 0.141025641025641, 0.1666666666666666, 0.2051282051282051, 0.2692307692307692, 0.358974358974359, 0.3974358974358974, 0.5256410256410257]}
调整分箱
绘制Bivar图,观察该特征分享后是否单调性,不满足单调性需要调整分箱。
# 绘制bivar图,调整分箱
# 根据节点设置分箱
dev_slt2 = cmb.transform(dev_slt)
val2 = cmb.transform(df_val[dev_slt.columns])
off2 = cmb.transform(df_off[dev_slt.columns])
# 观察分箱后的图像-act_info
bin_plot(dev_slt2, x='act_info', target='bad_ind')
bin_plot(val2, x='act_info', target='bad_ind')
bin_plot(off2, x='act_info', target='bad_ind')
开发样本
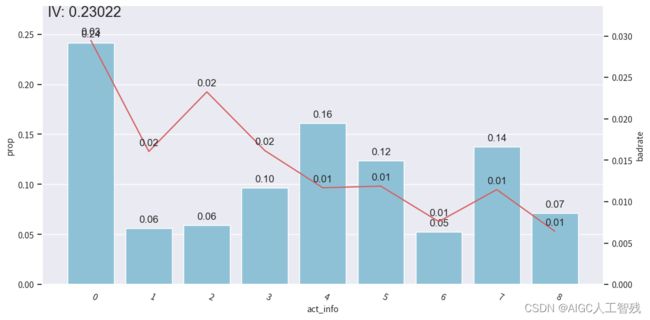
测试样本

验证样本

我们能看到前3箱出现上下波动,与整体的单调递减趋势不符,所以进行分箱合并。
# 没有呈现单调性,需要进行合并
bins['act_info']
[0.1153846153846154,
0.141025641025641,
0.1666666666666666,
0.2051282051282051,
0.2692307692307692,
0.358974358974359,
0.3974358974358974,
0.5256410256410257]
将其调整为3个分箱
adj_bins = {'act_info':[0.1666666666666666,0.358974358974359]}
cmb.set_rules(adj_bins)
dev_slt3 = cmb.transform(dev_slt)
val3 = cmb.transform(df_val[dev_slt.columns])
off3 = cmb.transform(df_off[dev_slt.columns])
# 观察分箱后的图像
bin_plot(dev_slt3, x='act_info', target='bad_ind')
bin_plot(val3, x='act_info', target='bad_ind')
bin_plot(off3, x='act_info', target='bad_ind')
开发样本
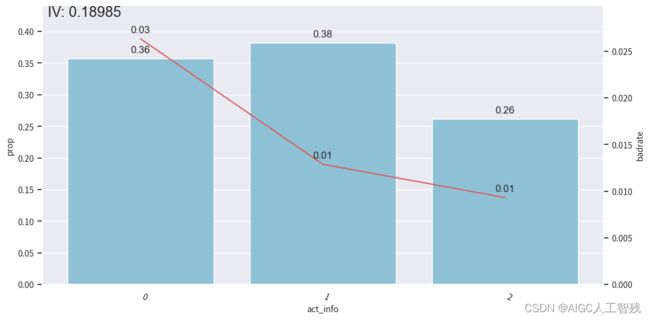
测试样本

验证样本

查看负样本占比关联图
# 绘制负样本占比关联图
data = pd.concat([dev_slt3, val3, off3], join='inner')
badrate_plot(data, x='samp_type', target='bad_ind', by='act_info')

其他特征分箱
person_info特征分箱
bins['person_info']
[-0.2610139784946237,
-0.1286774193548387,
-0.0537175627240143,
0.013863440860215,
0.0626602150537634,
0.078853046594982]
adj_bins = {'person_info':[-0.2610139784946237,-0.1286774193548387,-0.0537175627240143,0.078853046594982]}
cmb.set_rules(adj_bins)
dev_slt3 = cmb.transform(dev_slt)
val3 = cmb.transform(df_val[dev_slt.columns])
off3 = cmb.transform(df_off[dev_slt.columns])
data = pd.concat([dev_slt3, val3, off3], join='inner')
badrate_plot(data, x='samp_type', target='bad_ind', by='person_info')
# 观察分箱后的图像
bin_plot(dev_slt3, x='person_info', target='bad_ind')
bin_plot(val3, x='person_info', target='bad_ind')
bin_plot(off3, x='person_info', target='bad_ind')
bins['person_info']
负样本占比关联图

开发样本

测试样本
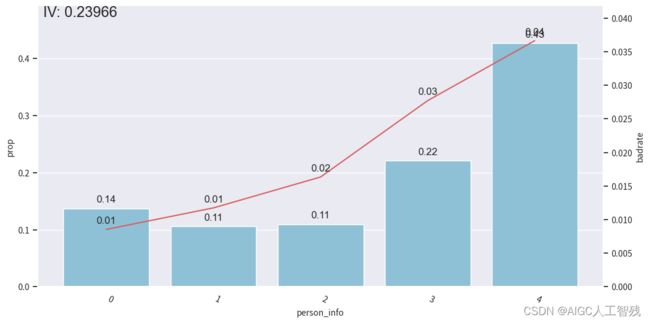
验证样本

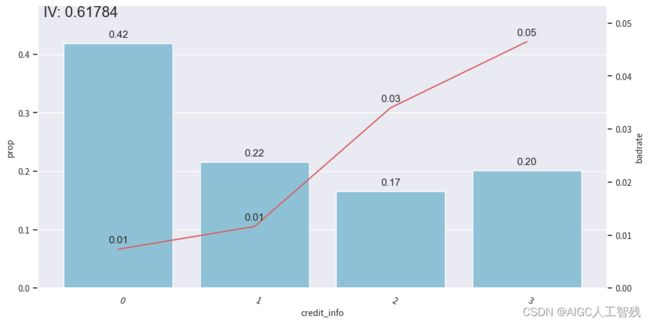
credit_info特征
# credit_info
badrate_plot(data, x='samp_type', target='bad_ind', by='credit_info')
# 观察分箱后的图像
bin_plot(dev_slt3, x='credit_info', target='bad_ind')
bin_plot(val3, x='credit_info', target='bad_ind')
bin_plot(off3, x='credit_info', target='bad_ind')
bins['credit_info']
负样本占比

开发样本
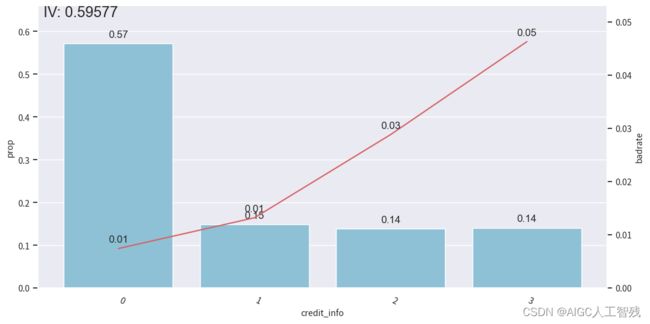
测试样本

验证样本
其他特征分箱分为两个,所以不需要单独看。
4 WOE编码,并验证IV
# WOE编码,验证IV
woet = toad.transform.WOETransformer()
dev_woe = woet.fit_transform(dev_slt3, dev_slt3['bad_ind'], exclude=feature_drop)
val_woe = woet.transform(val3[dev_slt3.columns])
off_woe = woet.transform(off3[dev_slt3.columns])
data_woe = pd.concat([dev_woe, val_woe,off_woe])
# 计算PSI
psi_df = toad.metrics.PSI(dev_woe,val_woe).sort_values(0)
psi_df = psi_df.reset_index()
psi_df = psi_df.rename(columns={'index':'feature', 0:'psi'})
psi_df

一般删除psi大于0.1的特征,但我们这里调整为0.13。
psi_013 = list(psi_df[psi_df.psi<0.13].feature)
# psi_013.extend(feature_drop)
data_psi = data_woe[psi_013]
dev_woe_psi = dev_woe[psi_013]
val_woe_psi = val_woe[psi_013]
off_woe_psi = off_woe[psi_013]
print(data_psi.shape)
(95806, 11)
由于卡方分箱后部分变量的IV降低,且整体相关程度增大,需要再次筛选特征。
dev_woe_psi2,drop_lst = toad.selection.select(dev_woe_psi,
dev_woe_psi['bad_ind'],
empty=0.6,
iv=0.001,
corr=0.5,
return_drop=True,
exclude=feature_drop)
print('keep:',dev_woe_psi2.shape,';drop empty:',drop_lst['empty'].shape,';drop iv:',drop_lst['iv'].shape,';drop corr:',drop_lst['corr'].shape)
keep: (65304, 7) ;drop empty: (0,) ;drop iv: (4,) ;drop corr: (0,)
5 再次特征筛选
使用逐步回归进行特征筛选,这里为线性回归模型,并选择KS作为评价指标。
# 特征筛选,使用逐步回归法进行筛选
dev_woe_psi_stp = toad.selection.stepwise(dev_woe_psi2,
dev_woe_psi2['bad_ind'],
exclude=feature_drop,
direction='both',
criterion='ks',
estimator='ols',
intercept=False)
val_woe_psi_stp = val_woe_psi[dev_woe_psi_stp.columns]
off_woe_psi_stp = off_woe_psi[dev_woe_psi_stp.columns]
data_woe_psi_std = pd.concat([dev_woe_psi_stp, val_woe_psi_stp, off_woe_psi_stp])
print(data_woe_psi_std.shape)
print(data_woe_psi_std.columns)
(95806, 6)
Index([‘uid’, ‘samp_type’, ‘bad_ind’, ‘credit_info’, ‘act_info’,
‘person_info’],
dtype=‘object’)
6 模型训练
定义逻辑回归模型和XGBoost模型的函数
# 进行模型训练
def lr_model(x,y,valx,valy,offx,offy,c):
model = LogisticRegression(C=c, class_weight='balanced')
model.fit(x,y)
# dev
y_pred = model.predict_proba(x)[:,1]
fpr_dev, tpr_dev, _ = roc_curve(y,y_pred)
dev_ks = abs(fpr_dev-tpr_dev).max()
print('dev_ks:',dev_ks)
y_pred = model.predict_proba(valx)[:,1]
fpr_val, tpr_val, _ = roc_curve(valy,y_pred)
val_ks = abs(fpr_val-tpr_val).max()
print('val_ks:',val_ks)
y_pred = model.predict_proba(offx)[:,1]
fpr_off, tpr_off, _ = roc_curve(offy,y_pred)
off_ks = abs(fpr_off-tpr_off).max()
print('off_ks:',off_ks)
plt.plot(fpr_dev, tpr_dev, label='dev')
plt.plot(fpr_val, tpr_val, label='val')
plt.plot(fpr_off, tpr_off, label='off')
plt.plot([0,1],[0,1],'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('lr model ROC Curve')
plt.legend(loc='best')
plt.show()
# xgb模型
def xgb_model(x,y,valx,valy,offx,offy):
model = xgb.XGBClassifier(learning_rate=0.05,
n_estimators=400,
max_depth=2,
min_child_weight = 1,
subsample=1,
nthread=-1,
scale_pos_weight=1,
random_state=1,
n_jobs=-1,
reg_lambda=300)
model.fit(x,y)
# dev
y_pred = model.predict_proba(x)[:,1]
fpr_dev, tpr_dev, _ = roc_curve(y,y_pred)
dev_ks = abs(fpr_dev-tpr_dev).max()
print('dev_ks:',dev_ks)
y_pred = model.predict_proba(valx)[:,1]
fpr_val, tpr_val, _ = roc_curve(valy,y_pred)
val_ks = abs(fpr_val-tpr_val).max()
print('val_ks:',val_ks)
y_pred = model.predict_proba(offx)[:,1]
fpr_off, tpr_off, _ = roc_curve(offy,y_pred)
off_ks = abs(fpr_off-tpr_off).max()
print('off_ks:',off_ks)
plt.plot(fpr_dev, tpr_dev, label='dev')
plt.plot(fpr_val, tpr_val, label='val')
plt.plot(fpr_off, tpr_off, label='off')
plt.plot([0,1],[0,1],'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('xgb model ROC Curve')
plt.legend(loc='best')
plt.show()
定义模型函数的使用函数,在函数中分别进行正向调用和逆向调用,验证模型的效果上限。如逆向模型训练集KS值明显小于正向模型训练集KS值,说明当前时间外样本分布与开发样本差异较大,需要重新划分样本集。
start_train(data_woe_psi_std,target='bad_ind', exclude=feature_drop)

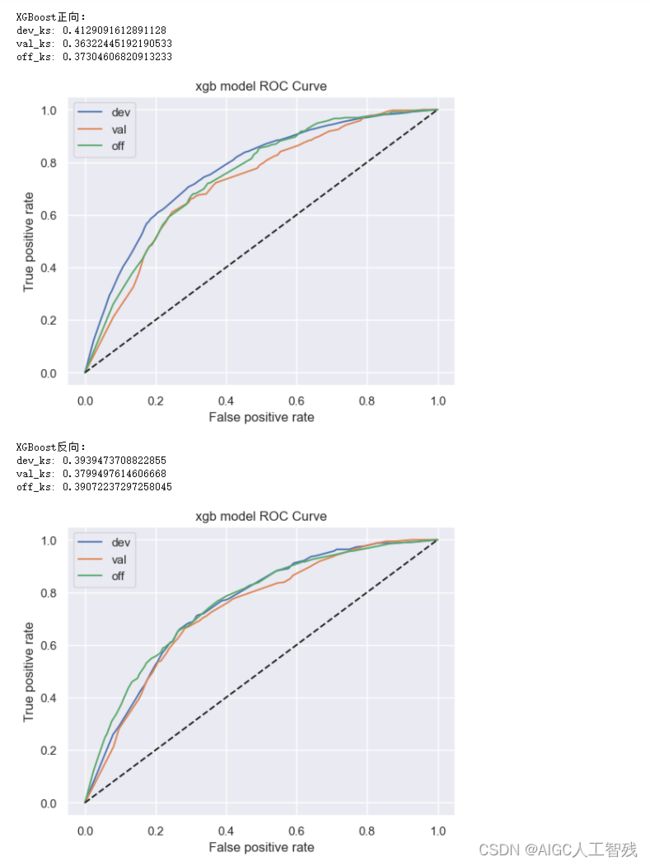
- XGBoost的效果没有好于逻辑回归模型,因此特征不需要进行再组合;
- 反向lr模型的结果没有显著好于正向调用的结果,因此该模型在当前特征空间下没有优化的空间;
- lr正向训练和反向训练的ks值在5%以内,所以不需要调整时间稳定性较差的变量。
计算训练集、测试集和验证集的ks、F1和auc值
7 计算指标评估模型,生成模型报告
# 分别计算ks,F1和auc值
target = 'bad_ind'
lt = list(data_woe_psi_std.columns)
for i in feature_drop:
lt.remove(i)
devv = data_woe_psi_std[data_woe_psi_std['samp_type']=='dev']
vall = data_woe_psi_std[data_woe_psi_std['samp_type']=='val']
offf = data_woe_psi_std[data_woe_psi_std['samp_type']=='off']
x,y=devv[lt], devv[target]
valx,valy = vall[lt],vall[target]
offx,offy = offf[lt], offf[target]
lr = LogisticRegression()
lr.fit(x,y)
prob_dev = lr.predict_proba(x)[:,1]
print('训练集')
print('F1:',F1(prob_dev,y))
print('KS:',KS(prob_dev,y))
print('AUC:',AUC(prob_dev,y))
prob_val = lr.predict_proba(valx)[:,1]
print('测试集')
print('F1:',F1(prob_val,valy))
print('KS:',KS(prob_val,valy))
print('AUC:',AUC(prob_val,valy))
prob_off = lr.predict_proba(offx)[:,1]
print('验证集')
print('F1:',F1(prob_off,offy))
print('KS:',KS(prob_off,offy))
print('AUC:',AUC(prob_off,offy))
# 验证集的模型PSI和特征PSI
print('模型PSI:', toad.metrics.PSI(prob_dev,prob_off))
print('特征PSI:\n', toad.metrics.PSI(x,offx).sort_values(0))
训练集
F1: 0.02962459026532253
KS: 0.40665138719594446
AUC: 0.7683462756870743
测试集
F1: 0.03395860284605433
KS: 0.3709553758048945
AUC: 0.723771920780572
验证集
F1: 0
KS: 0.38288372897789186
AUC: 0.7447410631197128
模型PSI: 0.3372146799079187
特征PSI:
credit_info 0.098585
act_info 0.124820
person_info 0.127210
dtype: float64
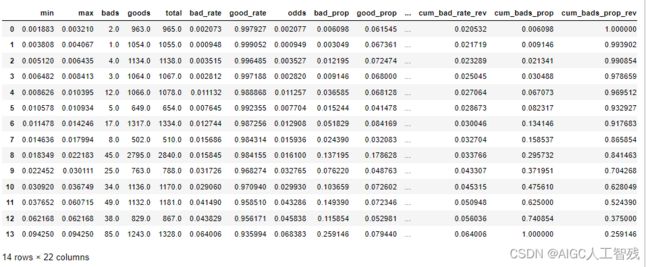
生成验证集的ks报告
toad.metrics.KS_bucket(prob_off, offy, bucket=15, method='quantile')
8 生成评分卡
# 用toad生成评分卡
card = ScoreCard(combiner=cmb,
transer=woet, C=0.1,
class_weight='balanced',
base_score=600,
base_odds=35,
pdo=60,
rate=2)
card.fit(x,y)
final_card = card.export(to_frame=True)
final_card

对训练集、测试集和验证集应用评分卡,预测用户的分数。这里要注意要传入原始数据,不要传入woe编码转化后和分箱后的数据。
# 评分卡进行预测
df_dev['score'] = card.predict(df_dev)
df_val['score'] = card.predict(df_val)
df_off['score'] = card.predict(df_off)
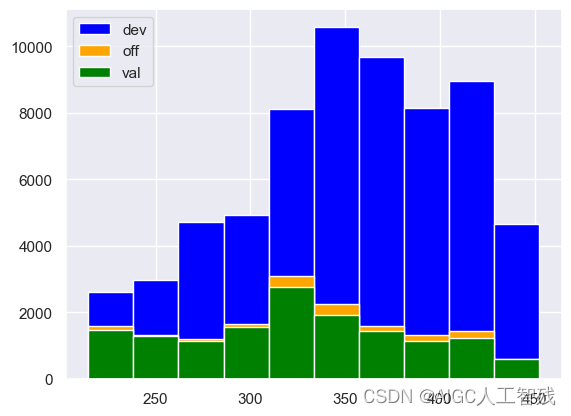
plt.hist(df_dev['score'], label = 'dev',color='blue', bins = 10)
plt.legend()

plt.hist(df_val['score'], label = 'val',color='green', bins = 10)
plt.legend()

plt.hist(df_off['score'], label = 'off',color='orange', bins = 10)
plt.legend()

三组评分数据在一个图中
plt.hist(df_dev['score'], label = 'dev',color='blue', bins = 10)
plt.hist(df_off['score'], label = 'off',color='orange', bins = 10)
plt.hist(df_val['score'], label = 'val',color='green', bins = 10)
plt.legend()