MySQL数据库基础
数据库相关知识:
1,什么是数据库?
数据库是数据管理的有效技术,是计算机科学的重要分支。
数据库(Database)是“按照数据结构来组织、存储和管理数据的仓库”。
2,数据库技术相关的常用术语和基本概念:
1,数据(data)
数据是数据库中存储的基本对象。
例如:文本,图形,图像,音频,视频等,这些都是数据。
数据的定义:描述事物的符号记录称为数据。
注意:描述事物符号的可以是数字,文字,图形,图像等,数据有多种表现形式,它们都可以经过数字化后存入计算机。
2,数据库(DataBase,DB)
数据库,顾名思义,是存放数据的仓库。只不过这个仓库是在计算机存储设备上,而且数据是按一定的格式存放的。
数据库定义:数据库是长期存储在计算机内,有组织的,可共享的大量数据的集合。数据库中的数据按一定的数据模型组织,描述和储存,具有较小的冗余度,较高的数据独立性和易扩展性,并可以为各种用户共享。
数据库数据具有永久存储,有组织和可共享三个基本特点。
3,数据库管理系统(DateBase Management System,DBMS)
了解了数据和数据库的概念,下一个问题就是如何科学地组织和存放数据,如何高效地获取和维护数据。完成这个任务的是一个系统软件----数据库管理系统。
数据库管理系统是位于用户与操作系统之间的一层数据管理软件。数据库管理系统和操作系统一样是计算机的基础软件,也是一个大型复杂的软件软件系统。
它的主要功能:
1,数据定义功能
数据库管理系统提供数据定义语言(Data Definition Language,DDL),用户可以方便地对数据库中的数据对象的组合与结构进行定义。
2,数据组织,存储和管理
数据库管理系统要分类组织,存储和管理各种数据,包括数据字典、用户数据、数据的存取路径等。要确定以何种文字结构和存取方式在存储级上组织这些数据,如何实现数据之间的联系。数据组织和存储的基本目标是提高存储空间利用率和方便存取,提供多种存取方法(如索引查找,hash查找,顺序查找等)来提高存取效率。
3,数据操纵功能
数据库管理系统还提供数据操纵语言(Data Manipulation Language,DML),用户可以使用它操纵数据,实现对数据库的基本操作,如查询,插入,删除和修改等。
4,数据库的事务管理和运行管理
数据库在建立,运用和维护时由数据库管理系统统一管理和控制,以保证事务的正确运行,保证数据的安全性,完整性,多用户对数据的并发使用及发生故障后的系统恢复。
5,数据库的建立和维护功能
数据库的建立和维护功能包括数据看初始数据的输入、转换功能,数据库的转储和恢复功能,数据库的重组织功能和性能监视、分析功能等。这些功能通常是由一些实用程序或管理工具完成的。
6,其他功能
包括数据库管理系统与网络中其他软件系统的通信功能,一个数据库管理系统与另一个数据库管理系统或文件系统的数据转换功能,异构数据库之间的互访和互操作功能等。
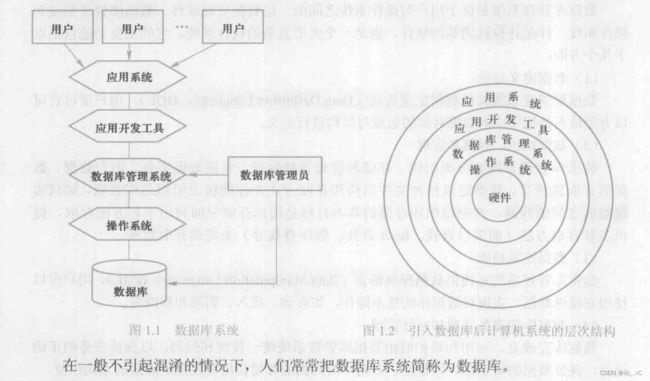
4,数据库系统
数据库系统是由数据库、数据库管理系统(及其应用开发工具)、应用程序和数据库管理员(DataBase Administrator,DBA)组成的存储,管理,处理和维护数据的系统。应当指出的是,数据库的建立,使用和维护等工作只靠一个数据库管理系统远远不够,还要有专门的人员来完成,这些人就是数据库管理员。
数据库系统也叫数据库应用系统:
数据库系统是为了适应数据处理的需要而发展起来的一种较为理想的数据处理系统,也是一个为了实际可运行的存储、维护和应用系统提供数据的软件系统,是存储介质 、处理对象和管理系统的集合体。(提供一种访问的路径 ,让外部人员操作)
一般把数据库系统简称为数据库。
什么是MySQL?
1,MySQL是一个关系型数据库管理系统,使用的 SQL 语言是用于访问数据库的最常用标准化语言。
2, mySQL使用 C和 C++编写,并使用了多种编译器进行测试,保证了源代码的可移植性。
3, 关系数据库管理系统(Relational Database Management System:RDBMS)是指包括相互联系的逻辑组织和存取这些数据的一套程序 (数据库管理系统软件)。关系数据库管理系统就是管理关系数据库,并将数据逻辑组织的系统。RDBMS中的数据存储在被称为表(tables)的数据库对象中。表是相关的数据项的集合,它由列和行组成。
4, MySQL数据库管理系统是由瑞典的MySQLAB公司开发的,但是几经辗转,现在是Oracle产品。它是以“客户/服务器”模式实现的,是一个多用户、多线程的小型数据库服务器。而且MySQL是开源数据的,任何人都可以获得该数据库的源代码并修正MySQL的缺陷。
推荐链接:http://t.csdn.cn/oVz4X
mysql默认数据库里面的四张表(user,db,tables_priv,columns_priv)。
1、user表(用户层权限)因为字段太多,只截取了一部分。首先登陆的时候验证Host,User,Password(authentication_string)也就是ip,用户名,密码是否匹配,匹配登陆成功将会为登陆者分配权限,分配权限的顺序也是按照上面四张表的排列顺序进行的,举个例子,如果user表的Select_priv为Y说明他拥有所有表的查找权限,如果为N就需要到下一级db表中进行权限分配了。其中的%是通配符,代表任意的意思。
2、db表(数据库层权限)
来到db表之后会匹配Host,User然后会根据Db字段对应的表进行权限分配,像Select_priv这些字段对应的权限大家应该都能看出来是对应着什么权限了吧,这里不细说了(不偷懒,举个例子Select_priv,Insert_priv,Update_priv,Delete_priv,Create_priv,Drop_priv分别代表着查询,增加,更新,删除,创建,销毁)。其中Y代表这拥有此项权限,N则代表没有此项权限。3、tables_priv表(表层权限)
与上面一样,这是通过Host,Db,User,Table来进行定位到表层的一个权限分配。不过它只有Table_priv和Column_priv两个字段来记录权限。4、columns_priv表(字段层权限)
顾名思义,字段层权限,通过Host,Db,User,Table,Column来进行定位到字段层的一个权限分配,只有Column_priv来记录权限。
下载安装MySQL后,怎么使用?
1,可以在Windows下使用DOS命令进入MySQL进行操作
步骤:
(1)打开cmd,并进入mysql安装目录的bin目录下
(可以配置环境变量,就可以在用户目录上直接使用mysql -h....的命令进入)
我的安装目录是:
C:\Program Files\MySQL\MySQL Server 8.0\bin

(2) 在DOS命令窗口输入 mysql -hlocalhost -uroot -p回车 进入mysql数据库
注意:如果-h后面的服务器是本地(localhost)的话可省略
在DOS命令窗口输入 mysql -hlocalhost -uroot -p回车 进入mysql数据库,其中-h表示服务器名,localhost表示本地;-u为数据库用户名,root是mysql默认用户名;-p为密码,如果设置了密码,可直接在-p后链接输入,如:-p123456,用户没有设置密码,显示Enter password时,直接回车即可。
2,使用其他工具操作(如navicat,不介绍)
推荐链接:http://t.csdn.cn/m7nYF
操作数据库的语言SQL
SQL 是用于访问和处理数据库的标准的计算机语言。
- SQL 指结构化查询语言
- SQL 使我们有能力访问数据库
- SQL 是一种 ANSI 的标准计算机语言
SQL 可与数据库程序协同工作,比如 MS Access、DB2、Informix、MS SQL Server、Oracle、Sybase 以及其他数据库系统。但是由于各种各样的数据库出现,导致很多不同版本的 SQL 语言,为了与 ANSI 标准相兼容,它们必须以相似的方式共同地来支持一些主要的关键词(比如 SELECT、UPDATE、DELETE、INSERT、WHERE 等等),这些就是我们要学习的SQL基础。
注意:
1,在mysql数据库中的命令(一条SQL)必须以分号结尾“
;”不然不会认为是一条语句,会继续找下面的语句
2,在mysql数据库中不区分字母的大小写
SQL的分类
注意:这并不是唯一的,只是为了记忆,大家默认的分类。
DDL:模式定义语言,用于描述数据库中储存的现实世界实体的语言
定义数据库的对象有:表、视图、数据库、用户、角色、函数 eg:create,drop,alter
DML:数据库操作语言,插入,修改,删除-----insert,update, delect
DCL:数据库控制语言,用于控制数据库组件的存取许可,存储权限等--revoke,grant
DQL:数据库查询语言,进行数据查询,select 语句
数据库的数据类型:
一、数值类型
MySQL 的数值类型可以大致划分为两个类别,一个是整数,另一个是浮点数或小数。许多不同的子类型对这些类别中的每一个都是可用的,每个子类型支持不同大小的数据,并且 MySQL 允许我们指定数值字段中的值是否有正负之分或者用零填补。
下表列出了各种数值类型以及它们的允许范围和占用的内存空间。
| 类型 | 字节大小 | 范围(有符号) | 范围(无符号) | 用途 |
| TINYINT | 1 字节 | 最小:-128 最大:127 |
最小:0 最大:255 |
小整数值 |
| SMALLINT | 2 字节 | 最小:-32768 最大:32767 |
最小:0 最大:65535 |
短整数值 |
| MEDIUMINT | 3 字节 | 最小:-8388608 最大:8388607 |
最小:0 最大:16777215 |
大整数值 |
| INT或INTEGER | 4 字节 | 最小:-2147483648 最大:2147483647 |
最小:0 最大:4294967295 |
大整数值 |
| BIGINT | 8 字节 | 最小:-9233372036854775808 最大:9223372036854775807 |
最小:0 最大:18446744073709551615 |
极大整数值 |
| FLOAT | 4 字节 | 单精度 浮点数值 |
||
| DOUBLE | 8 字节 | 双精度 浮点数值 |
||
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
二、字符串类型
MySQL 提供了 8 个基本的字符串类型,可以存储的范围从简单的一个字符到巨大的文本块或二进制字符串数据。
| 类型 | 大小 | 用途 |
| CHAR | 0-255字节 | 定长字符串 |
| VARCHAR | 0-255字节 | 变长字符串 |
| TINYBLOB | 0-255字节 | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255字节 | 短文本字符串 |
| BLOB | 0-65535字节 | 二进制形式的长文本数据 |
| TEXT | 0-65535字节 | 长文本数据 |
| MEDIUMBLOB | 0-16777215字节 | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16777215字节 | 中等长度文本数据 |
| LOGNGBLOB | 0-4294967295字节 | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4294967295字节 | 极大文本数据 |
三、 日期和时间类型
在处理日期和时间类型的值时,MySQL 带有 5 个不同的数据类型可供选择。它们可以被分成简单的日期、时间类型,和混合日期、时间类型。根据要求的精度,子类型在每个分类型中都可以使用,并且 MySQL 带有内置功能可以把多样化的输入格式变为一个标准格式。
| 类型 | 大小 (字节) |
范围 | 格式 | 用途 |
| DATE | 3 | 1000-01-01到9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | -838:59:59到838:59:59 | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901到2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00到9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 8 | 1970-01-01 00:00:00/2037 年某时 | YYYYMMDD HHMMSS | 混日期和时合间值, 时间戳 |
SQL基础语言学习:
DDL(数据定义)语句:
1,对数据库结构的操作:
(1)创建数据库
create database 数据库名称;
(2)查看数据库基本信息
show create database 数据库名称;
(3)查看mysql下所有的数据库
show databases;
(4)将数据库的字符集修改为gbk MySQL命令
alter database +表名 set gdk;
(5)切换数据库
use 数据库;
(6)删除数据库
drop dayabase +数据库名;
2,对数据表结构的操作
(1)创建表
create table +表名称
(
列名称1 数据类型,
列名称2 数据类型,
列名称3 数据类型,
......
);
(2)查看当前数据库中所有表
show tables;
(3)查表的基本信息
show create table 表名;
(4)查看表的字段信息
desc +表名;
(5)修改表名
alter table 原表名 rename to 新表名;
(6)修改字段名
alter table 表名 change 原字段名 新字段名 数据类型;
(7)修改字段数据类型
altre table +表名 modify +字段名 数据类型;
(8)增加字段
alter table +表名 add +字段名 数据类型;
(9)删除字段
alter table +表名 drop 字段名;
(10)删除数据表
drop table 表名;
临时修改数据库编码格式
当然我们上面修改的格式是默认的格式,用的时候也是可以临时性地修改编码格式,只不过退出数据库后,编码格式又是默认的了。
修改数据库编码格式:
alter database <数据库名> character set <编码格式>;
修改数据表格编码格式:
alter table <表名> character set <编码格式>;
修改字段编码格式
alter table <表名> change <字段名> <字段名> <类型> character set <编码格式>;
eg:
alter table user change username username varchar(20) character set utf8 not null;
创建数据库时指定数据库的字符集:
create database <数据库名> character set utf8;
DML(数据库操作语言)语句:
(1)insert-插入数据
insert into语句用于向表格中插入新的行
insert into+表名 values (值1,值2,值3,.....);
注意 :适合表当中的字段(列)是对于的。
也可以指定要插入数据的列:
insert into+表名(列名1,列名2......) values (值1,值2,.....);
(2)update-更新数据
update语句用于修改表中的数据。
update 表名 set 列名=新的值 where 列名=某值;
一般是一定是要有条件的,要不然会更改整张表的数据
(3)delete-删除数据
delete语句用于删除表中的行。
delete from 表名 where 列名=某值;
删除所有的行。
delete from+表名;
DQL(数据库查询语言)语句:
(1)查看当前使用的数据库
select database();
(2) 查询表中的字段
select 列名 from 表名;
会展示该列(字段)的所有数据。
使用*查询表中所有的列
select * from 表名;
(3)使用where--条件查询
不是将表中所有数据都查出来,是查询符合条件的。
select ... from ... where 条件;
下面的运算符可在 WHERE 子句中使用:
| 操作符 | 描述 |
|---|---|
| = | 等于 |
| <>或者!= | 不等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| between...and.. | 两个值之间,等同于>= and <= |
| is null | 是null(is not null 不为空) 注意:在数据库中null不能使用等号进行衡量。需要使用is null因为数据库中Null代表什么都没有,它不是一个值,所以不能使用=衡量。 |
| like | 模糊查询,支持%或下划线匹配 %匹配任意个字符 一个下划线只能匹配一个字符 |
| and | 并且 |
| or | 或者 |
| in | 包含,相当于多个or |
| not in | 不包含 |
| not | 可以取非,主要用在is或in中 |
(4)使用between...and...
必须遵循左小右大的。它们是闭区间,包括两边的值。
如小面的例子:
mysql> select *from goods;
+------+----------+--------+---------+
| gid | gname | price | address |
+------+----------+--------+---------+
| 1002 | yfy | 3.20 | 美国 |
| 1003 | 可口可乐 | 2.00 | 俄罗斯 |
| 1004 | 雪域春 | 199.00 | 中国 |
| 1005 | 疏导香 | 99.00 | 中国 |
+------+----------+--------+---------+
4 rows in set (0.00 sec)mysql> select *from goods where price between 2 and 100;
+------+----------+-------+---------+
| gid | gname | price | address |
+------+----------+-------+---------+
| 1002 | yfy | 3.20 | 美国 |
| 1003 | 可口可乐 | 2.00 | 俄罗斯 |
| 1005 | 疏导香 | 99.00 | 中国 |
+------+----------+-------+---------+
3 rows in set (0.00 sec)(5)and 和or的使用
如果and和or同时使用的话要主要优先级的问题,
and的优先级更高,会先执行,如果想让or先执行需要加"小括号"
mysql> select *from goods where gid=1003 or gid=1004 and price<100;
+------+----------+-------+---------+
| gid | gname | price | address |
+------+----------+-------+---------+
| 1003 | 可口可乐 | 2.00 | 俄罗斯 |
+------+----------+-------+---------+
1 row in set (0.00 sec)mysql> select * from goods where gid=1004 or gid=1003 and price<100;
+------+----------+--------+---------+
| gid | gname | price | address |
+------+----------+--------+---------+
| 1003 | 可口可乐 | 2.00 | 俄罗斯 |
| 1004 | 雪域春 | 199.00 | 中国 |
+------+----------+--------+---------+
2 rows in set (0.00 sec)(6)in 和not in
in包含。 不是一个区间,in后面跟的是具体的值。
not in不包含。 不是一个区间,后面跟的是具体的值
mysql> select * from goods where gid in(1002,1003);
+------+----------+-------+---------+
| gid | gname | price | address |
+------+----------+-------+---------+
| 1002 | yfy | 3.20 | 美国 |
| 1003 | 可口可乐 | 2.00 | 俄罗斯 |
+------+----------+-------+---------+
2 rows in set (0.00 sec)
mysql> select * from goods where gid not in(1002,1003);
+------+--------+--------+---------+
| gid | gname | price | address |
+------+--------+--------+---------+
| 1004 | 雪域春 | 199.00 | 中国 |
| 1005 | 疏导香 | 99.00 | 中国 |
+------+--------+--------+---------+
2 rows in set (0.00 sec)(7)模糊查询like:

order by排序:
select ...from ...where ...order by...
关键字顺序不能变,
默认是升序排列(asc可省略不写),降序排列使用desc
以上语句执行顺序:
第一步:from
第二部:where
第三步:select
第四步:order by(排序总是在最后执行)
如果排序后面有多个字段,前面的起主导作用,只有前面的相等后面的才起作用。
mysql> select *from goods order by price desc;
+------+----------+--------+---------+
| gid | gname | price | address |
+------+----------+--------+---------+
| 1004 | 雪域春 | 199.00 | 中国 |
| 1005 | 疏导香 | 99.00 | 中国 |
| 1002 | yfy | 3.20 | 美国 |
| 1003 | 可口可乐 | 2.00 | 俄罗斯 |
+------+----------+--------+---------+
4 rows in set (0.00 sec)AS – 别名
通过使用 SQL,可以为列名称和表名称指定别名(Alias),别名使查询程序更易阅读和书写。
表别名:
select 列名 from 表名 as 别名;
列别名:
select 列名 as 别名 from 表名;
as可以省略。
mysql> select gid as id from goods;
+------+
| id |
+------+
| 1002 |
| 1003 |
| 1005 |
| 1004 |
+------+
4 rows in set (0.00 sec)
mysql> select gid id from goods;
+------+
| id |
+------+
| 1002 |
| 1003 |
| 1005 |
| 1004 |
+------+
4 rows in set (0.00 sec)数据处理函数
1.1、数据处理函数又被称为单行处理函数
单行处理函数的特点:一个输入对应一个输出。
多行处理函数(组合/聚合函数):多个输入,一个输出。
1.2、常见的单行处理函数?
lower 转换小写
upper 转换大写
substr 取子串(substr(被截取的字符串,起始下标,截取的长度))
length 取长度
concat 进行字符串的拼接
trim 去空格
str_to_date 将字符串转换成日期
date_formate 格式化日期
format 设置千分位
round 四舍五入
rand() 生成随机数
ifnull() 可以将null转换成一个具体值
upper/lower --转换大/小写
select upper(字段)from 表名;转大写
select lower(字段)from 表名;转小写
mysql> select account from login;
+---------+
| account |
+---------+
| admin |
| root |
+---------+
2 rows in set (0.01 sec)
mysql> select lower(account) from login;
+----------------+
| lower(account) |
+----------------+
| admin |
| root |
+----------------+
2 rows in set (0.00 sec)
mysql> select upper (account) from login;
+-----------------+
| upper (account) |
+-----------------+
| ADMIN |
| ROOT |
+-----------------+
2 rows in set (0.00 sec)substr --取子串
substr(被截取的字符串,起始下标,截取的长度);
select substr(被截取的字符串,起始下标,截取的长度)from 表名 ;
截取每个字段的第一个字符
select 字段 from 表 where 字段 like "A%";
等效于:select 字段 from 表 where subste(字段,1,1)="A";
mysql> select substr(account,1,1) from login;
+---------------------+
| substr(account,1,1) |
+---------------------+
| a |
| r |
+---------------------+
2 rows in set (0.00 sec)length--取长度
length(字段)
字段的字符数量。
mysql> select length(account) from login;
+-----------------+
| length(account) |
+-----------------+
| 5 |
| 4 |
+-----------------+
2 rows in set (0.00 sec)concat--进行字符串的拼接
concat(字段,字段...)
字段的拼接
mysql> select * from login;
+----+---------+----------+------+-------+
| id | account | PASSWORD | salt | email |
+----+---------+----------+------+-------+
| 1 | admin | admin | NULL | NULL |
| 2 | root | 123456 | NULL | NULL |
+----+---------+----------+------+-------+
2 rows in set (0.00 sec)
mysql> select concat(account,password) from login;
+--------------------------+
| concat(account,password) |
+--------------------------+
| adminadmin |
| root123456 |
+--------------------------+
2 rows in set (0.00 sec)trim--去空格
如果在查询时条件出现多余的空格没去掉的话是会出现以下错误的
mysql> select * from login where account=" admin";
Empty set (0.00 sec)
mysql> select * from login where account=trim(" admin");
+----+---------+----------+------+-------+
| id | account | PASSWORD | salt | email |
+----+---------+----------+------+-------+
| 1 | admin | admin | NULL | NULL |
+----+---------+----------+------+-------+
1 row in set (0.00 sec)rand() --生成随机数
mysql> select rand() from login;
+---------------------+
| rand() |
+---------------------+
| 0.37686475960245797 |
| 0.8711193500749016 |
+---------------------+
2 rows in set (0.00 sec)round --四舍五入
可以看出select后面可以跟某个表的字段名,也可以跟字面量/字面值(数据)
mysql> select round(10.5) from login;
+-------------+
| round(10.5) |
+-------------+
| 11 |
| 11 |
+-------------+
2 rows in set (0.00 sec)ifnull()---null的转换
ifnull是空处理函数,专门处理空的。
在所有的数据库中,只要又Null参与的数学运算,最终结果就是null;
ifnull函数的用法:ifnull(数据,被当作的那个值)
分组函数:
分组函数也叫多行处理函数,输入多行,最终输出一行
5个分组函数:
count(字段/*) 计数
sum(字段) 求和
avg(字段) 平均值
max(字段) 最大值
min(字段) 最小值
注意:
1,分组函数在使用时必须先进行分组,然后才能用,如果没有对数据进行分组,整张表默认为一组。
2,分组函数自动忽略Null,不需要对null提前处理。
3,分组函数不能直接使用在where字句中。
4,所有分组函数可以组合起来一起使用。
5,如果分组函数里面的字段不是int类型,也会被转成数字进行运算(不太了解)
count的使用
count(具体字段):表示统计该字段所有不为null的元素的总数。
count(*):统计表当中的总行数。
mysql> select min(price),max(price),avg(price),count(price),count(*),
sum(price) from goods;
+------------+------------+------------+--------------+----------+------------+
| min(price) | max(price) | avg(price) | count(price) | count(*) | sum(price) |
+------------+------------+------------+--------------+----------+------------+
| 2.00 | 199.00 | 75.800000 | 4 | 4 | 303.20 |
+------------+------------+------------+--------------+----------+------------+
1 row in set (0.01 sec)
mysql> select min(price),max(price),avg(price),count(price),count(*),
sum(price) from goods where gid=1002;
+------------+------------+------------+--------------+----------+------------+
| min(price) | max(price) | avg(price) | count(price) | count(*) | sum(price) |
+------------+------------+------------+--------------+----------+------------+
| 3.20 | 3.20 | 3.200000 | 1 | 1 | 3.20 |
+------------+------------+------------+--------------+----------+------------+
1 row in set (0.01 sec)如果直接在where后面使用分组函数会出现以下错误
mysql> select gid from goods where gid=max(gid);
ERROR 1111 (HY000): Invalid use of group function分组查询:
分组查询:就是把数据按一定要求进行分组,然后再对每一组数据进行操作。
select ...from ...group by...
mysql> select avg(price) from goods group by address;
+------------+
| avg(price) |
+------------+
| 3.200000 |
| 2.000000 |
| 149.000000 |
+------------+
3 rows in set (0.00 sec)将所有的关键字组合
select...from...where...group by...order by...
注意:
1,以上关键字的顺序是不能颠倒的。
2,执行顺序:
1,from
2,where
3,group by
4,select
5,order by
从上面可以直到为什么分组函数不能直接使用在where语句后面
分组在where后面执行的,
但是却可以直接使用在select语句后面,
因为它是在分组之后执行的(会自动分组)
重要结论:
在一条select语句当中,如果有group by 语句的话,select后面只能跟:参加分组的字段,以及分组函数。其它一律不能跟。
having
having的出现是为了对分组之后的数据进一步过滤。
having不能单独使用,having不能代替where,having必须和group by联合使用。
执行顺序:
1,from
2,where
3,group by
4,having
5,select
6,order by