Redis搭建及使用
Redis篇
一、Redis介绍
1.1Redis解决项目问题
- 为了降低对数据库的访问压力,当多个用户请求相同的数据时,我们可以第一时间从数据库查询到的数据进行缓存(存储到内存中),以减少数据库的访问次数
- 首页数据的加载效率:将大量且不经常改变的数据缓存到内存中,可大幅度提高访问速度
- 集群部署下的商品超卖:分布式事务
- 用户登录:
1.2Redis介绍
1.2.1Redis产生背景

1.2.2Redis使用
Redis是C语言开发基于内存结构进行键值对数据存储的、高性能的、非关系型Nosql数据库。
1.2.3Redis支持数据类型
redis是支持键值对数据存储,但是value可以是多种数据类型
- 字符串
- hash 映射
- list(列表)队列
- set集合
- zset无序集合
1.2.4Redis特点
- 基于内存存储、数据读写效率高
- Redis本身支持数据持久化
- Redis虽然基于key-value存储,但是支持多种数据类型
- Redis支持集群、支持主从模式
1.3Redis应用场景
- 缓存:在绝大多数互联网项目,为了提共数据访问速度、降低数据库的访问压力,我们可以使用redis作为缓存实现
- 点赞、排行版、计算器等功能,实时读写要求比较高,但是对于数据库的一致性要求不是太高的功能场景
- 分布式锁:基于redis的操作特性可以实现分布式锁功能
- 分布式会话:在分布式系统中可以使用redis实现session(共享缓存)
- 消息中间件:可以使用redis实现应用之间的通信
1.4Redis的优缺点
1.4.1优点
- redis基于内存结构,性能极高(读:1100000次/秒 写81000次/秒)
- redis基于键值对存储,但是支持多种数据
- redis的多有操作都是原子性,可以通过lua脚本将多个操作合并为一个原子操作(Redis事务)
- redis基于单线程操作,但是其多路复用实现了高性能读写
1.4.2缺点
- 缓存数据与数据库必须通过两次写操作才能保持数据的一致性
- 使用缓存会存在穿透、缓存击穿及缓存雪崩等问题,需要处理
- redis可以作为数据库使用进行数据的持久存储,存在数据丢失风险
二、Redis安装
2.1Redis安装
基于linux安装
2.1.1下载redis
wget http://download.redis.io/releases/redis-5.0.5.tar.gz
2.1.2安装redis
- 安装gcc
yum -y install gcc
- 解压并根目录编译
make MALLOC=libc
- 根目录安装
make install
- 启动redis
当我们完成安装后,就可以执行redis相关指令
redis-server
redis-server & 启动服务
redis-cli启动redis客户端服务
[root@localhost redis-5.0.5]# lsof -i:6379
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
redis-ser 72620 root 6u IPv6 316632 0t0 TCP *:6379 (LISTEN)
redis-ser 72620 root 7u IPv4 316633 0t0 TCP *:6379 (LISTEN)
2.2Redis配置
使用redis-server指定启动redis服务的时候,可以在指令后添加redis配置文件路径,已设置的redis是以何种配置启动
redis-server redis-6380.conf &
- 如果不指定配置文件的名字,则按照默认配置启动
- 我们可以在redis根目录下创建多个redis.conf文件以启动多个redis服务
常用redis配置:
##设置redis服务为守护模式---默认为no
daemonize no
##设置当前redis实例启动之后保存进程的id文件路径及名称
pidfile /var/run/redis_6379.pid
##redis服务端口
port 6379
##当前redis设置保护模式是否开启
protected-mode yes
##设置允许当前访问redis实例的IP地址列表
bind 127.0.0.1
##设置连接密码
requirepass 123456
## 设置redis实例中数据库的个数
databases 16
##设置最大并发数
maxclients
##设置客户端与redis建立连接最大空闲时间
timeout 0
三、Redis基本使用
3.1Redis存储的数据结构
Redis是以键值对的形式进行存储数据,但是value支持多种数据类型

3.2String常用指令
设定值/修改值
SET key value
设置指定的key值
GET key
批量添加
mset k1 v1 [k2 v2 k3 v3]
127.0.0.1:6379> mset key2 v2 key3 v3
OK
127.0.0.1:6379> keys *
1) "key3"
2) "k1"
3) "k2"
4) "key2"
批量取值
mget k1 k2 [k3 ...]
在key对应的value自增减
set k4 5
incr k4
decr k4
incrby key v ##在key对应的value上+ v
decrby key v ##在key对应的value上- v
获取指定key的值
SETEX key seconds(time) value ##添加键值对,并设置过期时间(TTL)
设置指定key的值,并将key的过期时间设为seconds秒
SETNX key value ##只有在key不存在时设置key的值
## 在指定的key对应的value拼接字符串
append key value
## 获取key对应字符串长度
strlen key
3.3Hash常用指令
## 向key对应的hash中添加键值对
hset key field value
##从key对应的hash获取filed对应的值
hget key field
##向key对应的hash结构中批量添加键值对
hmset key f1 v1 [f2 v2 ...]
##从key对应的hash中批量取值
hmget key f1[f2 f3 ...]
##在key对应的hash中的filed对应的value加v
hincrby key field v
##获取key对应的hash中所有的键值对
hgetall key
##获取key对应的hsah的所有field
hkeys key
##获取key对应的hash中的所有value
hvals key
##检查key对应的hash中是否有指定的field
hexists key field
##获取key对应的hash结构中键值对的个数
hlen key
## 向key对应的hash结构中添加 f-v 如果field已存在,则添加失败
hswtnx key field value
3.4list常用指令(队列先进先出)
对于list数据结构,支持2侧存取数据
同侧
![]()

3.5set常用指令

3.6zset常用指令

3.7key相关指令

3.8db常用指令

四、Redis持久化
redis是基于内存存储,但是作为一个数据库也具备数据持久化能力;但是为了提高读写效率;并不会即时进行数据的持久化,而是按照一定的规则操作----持久化策略
Redis提供了2种持久化策略:
- RDB(Redis Database)
- AOF(Append Only File)
4.1RDB
在满足特定的redis操作条件时,将内存中的数据以快照的形式存储到rdb文件中

- 原理:
- RDB是redis默认的持久化策略,当redis中的写操作达到指定的次数,同时距离上一次持久化达到指定的时间就会将redis内存中的数据生成数据快照,保存到指定的rdb文件中。
- 默认触发持久化条件:

4.2AOF
Append Only File ,当达到设定的触发条件时,将redis执行的写操作指令存储到aof文件中

- 原理:
redis将每一个成功的写操作写入到aof文件中,当redis重启的时候就执行aof文件中的指令以恢复数据
- 配置
##开启aof
appendonly no
##设置触发条件(三选一)
# appendfsync always 只要进行成功写操作就执行aof
appendfsync everysec 每秒进行aof
# appendfsync no redis自行决定aof
##设置aof存储路径
appendfilename "appendonly.aof"
- AOF细节分析
- 也可以通过拷贝aof文件进行redis数据移植
- aof存储的指令,而且会对指令进行整理,而rdb直接生成数据快照,在数据量不大时rdb比较快
- aof是指令文件进行增量更新,更适合实时性持久化
- redis官方建议同时开启2种持久化策略,如果同时存在aof和rdb文件的情况下aof优先
五、java应用连接redis
5.1设置redis允许远程连接
java应用连接redis设置允许远程连接
- 修改配置重启redis服务
##关闭保护模式 [root@localhost redis-5.0.5]# cat -n redis-6380.conf |grep protected 74 # When protected mode is on and if: 84 # By default protected mode is enabled. You should disable it only if 88 protected-mode yes 288 # If the master is password protected (using the "requirepass" configuration [root@localhost redis-5.0.5]# vim +88 redis-6380.conf [root@localhost redis-5.0.5]# redis-server redis-6380.conf & ## 将bind注释掉 (不注释只能本机访问)
- 重启redis服务
5.1在普通maven工程连接redis
5.1.1添加jedis依赖
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>2.9.0version>
dependency>
<dependency>
<groupId>com.google.code.gsongroupId>
<artifactId>gsonartifactId>
<version>2.8.6version>
dependency>
5.1.2使用案例
public class TestRedis {
public static void main(String[] args) {
Products products = new Products("101", "wahaha", 2.5);
//1.连接redis
Jedis jedis = new Jedis("192.168.36.132", 6379);
//2.操作
String set = jedis.set(products.getProductId(), new Gson().toJson(products));
System.out.println(set);
//3.关闭连接
jedis.close();
}
}
5.1.3redis远程可视化客户端
- Redis desktop manager
5.2在springboot应用连接redis
Spring Data Redis:提供了redis客户端连接
RedisTemplate
StringRedisTemplate
5.2.1创建springboot应用

5.2.2配置redis信息
application.yml文件配置redis连接信息
spring:
redis:
host: 192.168.36.132
port: 6379
database: 0
password: 123456
5.2.3使用redis客户端连接redis
直接在service注入 StringRedisTemplate或RedisTemplate ,就可以使用此对象完成redis操作
5.3Spring Data Redis
5.3.1不同数据结构的添加操作
public void addInfoToRedis() {
try {
Product product = new Product("104", "王老吉4", 4.0);
//string
String jsonstr = new ObjectMapper().writeValueAsString(product);
stringRedisTemplate.boundValueOps(product.getProductId()).set(jsonstr);
//添加数据过期时间
// stringRedisTemplate.boundValueOps("103").set(jsonstr,300);
//设置指定的key过期时间
// stringRedisTemplate.boundValueOps("103").expire(20L, TimeUnit.SECONDS);
//添加数据 setnx
// Boolean absent = stringRedisTemplate.boundValueOps("103").setIfAbsent(jsonstr);
//2.hash
// stringRedisTemplate.boundHashOps("products").put(product.getProductId(),jsonstr);
//3.list
// stringRedisTemplate.boundListOps("list").leftPush("aaa");
//4.set
// stringRedisTemplate.boundSetOps("s1").add("v1");
//zset
// stringRedisTemplate.boundZSetOps("z1").add("v2",11.2);
} catch (JsonProcessingException e) {
e.printStackTrace();
}
}
5.3.2不同数据类型的取值操作
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FhS7iISl-1678521127490)(C:\Users\86180\AppData\Roaming\Typora\typora-user-images\image-20221114162216411.png)]
六、使用Redis缓存数据库数据
6.1redis作为缓存使用流程

6.2使用Redis缓存商品详情数据
6.2.1在service子工程添加spring data redis依赖
org.springframework.boot
spring-boot-starter-data-redis
6.2.2在mapper子工程配置redis数据源
redis:
host: 192.168.36.132
port: 6379
database: 0
password: 123456
6.3.3在ProductServiceImpl中修改业务代码
@Transactional(propagation = Propagation.SUPPORTS)
@Override
public ResultVO getProductById(String productId) {
try{
//使用缓存步骤
//1.根据商品id查询redis数据
String productsInfo = (String) stringRedisTemplate.boundHashOps("products").get(productId);
//2.如果redis中查到了商品信息,则直接返回给控制器
if (productsInfo != null){
Product product = objectMapper.readValue(productsInfo, Product.class);
String imgsStr = (String) stringRedisTemplate.boundHashOps("productImgs").get(productId);
JavaType javaType = objectMapper.getTypeFactory().constructParametricType(ArrayList.class, ProductImg.class);
List<ProductImg> productImgs = objectMapper.readValue(imgsStr, javaType);
String skusStr = (String) stringRedisTemplate.boundHashOps("productSkus").get(productId);
JavaType javaType1 = objectMapper.getTypeFactory().constructParametricType(ArrayList.class, ProductSku.class);
List<ProductSku> productSkus = objectMapper.readValue(skusStr, javaType1);
HashMap<String, Object> baseInfo = new HashMap<>();
baseInfo.put("product", product);
baseInfo.put("productImgs", productImgs);
baseInfo.put("productSkus", productSkus);
return new ResultVO(ResStatus.OK, "success", baseInfo);
}else {
// 3.如果redis中没有查到数据 则直接从数据库中查询
//1.商品基本信息
Example example = new Example(Product.class);
Example.Criteria criteria = example.createCriteria();
criteria.andEqualTo("productId", productId);
criteria.andEqualTo("productStatus", 1);//状态为1 表示上架
List<Product> products = productDao.selectByExample(example);
if (products.size()>0){
//4.将从数据库查询到的数据写入到redis
Product product = products.get(0);
String jsonStr = objectMapper.writeValueAsString(product);
stringRedisTemplate.boundHashOps("products").put(productId,jsonStr);
//根据商品id查询商品图片
//2.商品图片
Example example1 = new Example(ProductImg.class);
Example.Criteria criteria1 = example1.createCriteria();
criteria1.andEqualTo("itemId", productId);
List<ProductImg> productImgs = imgMapper.selectByExample(example1);
stringRedisTemplate.boundHashOps("productImgs").put(productId,objectMapper.writeValueAsString(productImgs));
//根据商品id查询商品套餐
//3.商品套餐
Example example2 = new Example(ProductSku.class);
Example.Criteria criteria2 = example2.createCriteria();
criteria2.andEqualTo("productId", productId);
criteria2.andEqualTo("status", 1);
List<ProductSku> productSkus = skuMapper.selectByExample(example2);
stringRedisTemplate.boundHashOps("productSkus").put(productId,objectMapper.writeValueAsString(productSkus));
HashMap<String, Object> baseInfo = new HashMap<>();
baseInfo.put("product", products.get(0));
baseInfo.put("productImgs", productImgs);
baseInfo.put("productSkus", productSkus);
return new ResultVO(ResStatus.OK, "success", baseInfo);
}else {
return new ResultVO(ResStatus.NO,"fail",null);
}
}
}catch (Exception e){
e.printStackTrace();
}
return null;
}
说明:
在电商系统中为了提高商品的详情查询速度,减少数据库并发访问压力,我们可以使用redis来缓存商品详情数据,除此以外还可以使用页面静态化技术实现。
6.3使用Redis缓存平台首页数据
6.3.1什么样的数据适合用缓存?
因为缓存中的数据需要进行一致性的维护—即:当数据库数据发生变化,要同步跟新到缓存中
因此
- 对于数据写操作较少,但是会频繁查询的数据适合使用缓存
- 对于可能会发生修改,但是对数据一致性要求不高的数据也适合使用缓存
6.3.2缓存首页轮播图信息
@Service
public class IndexImgServiceImpl implements IndexImgService {
@Resource
private IndexImgMapper imgMapper;
@Resource
private StringRedisTemplate stringRedisTemplate;
private ObjectMapper objectMapper = new ObjectMapper();
@Override
public ResultVO listIndexImgs() {
List<IndexImg> indexImgs =null;
try {
//string 结构缓存轮播图信息
// String indexImgs1 = stringRedisTemplate.opsForValue().get("indexImgs");
String imgsStr = stringRedisTemplate.boundValueOps("indexImgs").get();
if (imgsStr != null) {
//从redis中获取到了轮播图信息
JavaType javaType1 = objectMapper.getTypeFactory().constructParametricType(ArrayList.class, IndexImg.class);
indexImgs = objectMapper.readValue(imgsStr, javaType1);
} else {
//从redis中没有获取到信息 则查询数据库
indexImgs = imgMapper.listIndexImgs();
//写到redis
stringRedisTemplate.boundValueOps("indexImgs").set(objectMapper.writeValueAsString(indexImgs));
}
} catch (JsonProcessingException e) {
e.printStackTrace();
}
if (indexImgs.size() >0){
return new ResultVO(ResStatus.OK,"success",indexImgs);
}else {
return new ResultVO(ResStatus.NO,"fail",null);
}
}
}
6.3.3商品分类信息缓存
@Service
public class CategoryServiceImpl implements CategoryService {
@Resource
private CategoryMapper categoryDao;
@Resource
private StringRedisTemplate stringRedisTemplate;
private ObjectMapper objectMapper = new ObjectMapper();
@Override
public ResultVO listCategories() {
List<Category> categoryVOS =null;
try {
//1.查询redis
String cateories = stringRedisTemplate.boundValueOps("cateories").get();
//2.判断
if (cateories != null){
JavaType javaType1 = objectMapper.getTypeFactory().constructParametricType(ArrayList.class, Category.class);
categoryVOS = objectMapper.readValue(cateories,javaType1);
}else {
//如果redis中没有类别数据 则直接查询数据库
categoryVOS = categoryDao.selectAllCategories();
String str = objectMapper.writeValueAsString(categoryVOS);
stringRedisTemplate.boundValueOps("cateories").set(str,1, TimeUnit.DAYS);
}
} catch (JsonProcessingException e) {
e.printStackTrace();
}
if(categoryVOS.size()>0){
return new ResultVO(ResStatus.OK,"success",categoryVOS);
}else {
return new ResultVO(ResStatus.NO,"fail",null);
}
}
@Override
public ResultVO listCategoryFirst() {
List<Category> categories = categoryDao.selectFirstLevelCategories();
if (categories.size()>0){
return new ResultVO(ResStatus.OK,"success",categories);
}else {
return new ResultVO(ResStatus.NO,"fail",null);
}
}
}
七.使用Redis做缓存使用存在的问题
使用redis作为缓存在高并发场景下有可能出现缓存击穿、缓存穿透、缓存雪崩等问题
7.1缓存击穿
缓存击穿:大量的高并发请求同时访问同一个在redis中不存在的数据,就会导致大量的请求绕过redis同时并发访问数据库,对数据库造成了高并发访问压力。
- 使用双重检测锁解决缓存击穿问题
@Service
public class IndexImgServiceImpl implements IndexImgService {
@Resource
private IndexImgMapper imgMapper;
@Resource
private StringRedisTemplate stringRedisTemplate;
private ObjectMapper objectMapper = new ObjectMapper();
@Override
public ResultVO listIndexImgs() {
List<IndexImg> indexImgs =null;
try {
//string 结构缓存轮播图信息
// String indexImgs1 = stringRedisTemplate.opsForValue().get("indexImgs");
//1000个并发请求,请求轮播图
String imgsStr = stringRedisTemplate.boundValueOps("indexImgs").get();
if (imgsStr != null) {
//从redis中获取到了轮播图信息
JavaType javaType1 = objectMapper.getTypeFactory().constructParametricType(ArrayList.class, IndexImg.class);
indexImgs = objectMapper.readValue(imgsStr, javaType1);
} else {
// 1000个请求都会进入else(service类在spring容器中是单例的,1000个并发会启动1000个线程来处理,但是公用一个service实例)
synchronized (this){
//第二次查询redis
String s= stringRedisTemplate.boundValueOps("indexImgs").get();
if (s ==null){
//从redis中没有获取到信息 则查询数据库
//这1000个请求中 只有第一个请求再次查询redis时依然为null
indexImgs = imgMapper.listIndexImgs();
System.out.println("------------------查询数据库");
//写到redis
stringRedisTemplate.boundValueOps("indexImgs").set(objectMapper.writeValueAsString(indexImgs));
stringRedisTemplate.boundValueOps("indexImgs").expire(1L, TimeUnit.DAYS);
}else {
JavaType javaType1 = objectMapper.getTypeFactory().constructParametricType(ArrayList.class, IndexImg.class);
indexImgs = objectMapper.readValue(s, javaType1);
}
}
}
} catch (JsonProcessingException e) {
e.printStackTrace();
}
if (indexImgs.size() >0){
return new ResultVO(ResStatus.OK,"success",indexImgs);
}else {
return new ResultVO(ResStatus.NO,"fail",null);
}
}
}
7.2缓存穿透
缓存穿透:大量的请求一个数据库中不存在的数据,首先在redis中无法命中,最终所有的请求都会访问数据库,同样会导致数据库承受巨大的访问压力
- 解决方案:当前从数据库查询到一个null时,写一个非空的数据到redis中,并设置过期时间

//缓存穿透---补偿机制
if (indexImgs != null){
//写到redis
stringRedisTemplate.boundValueOps("indexImgs").set(objectMapper.writeValueAsString(indexImgs));
stringRedisTemplate.boundValueOps("indexImgs").expire(1L, TimeUnit.DAYS);
}else {
//如果不存在 插入一个非空的数据到redis并设置过期时间
List<IndexImg> arr = new ArrayList<>();
stringRedisTemplate.boundValueOps("indexImgs").set(objectMapper.writeValueAsString(arr));
stringRedisTemplate.boundValueOps("indexImgs").expire(10L, TimeUnit.SECONDS);
}
7.3缓存雪崩
缓存雪崩:缓存中大量的数据集中过期,导致请求这些数据的大量的并发请求会同时访问数据库
解决方案:
- 将缓存中的数据设置成不同的过期时间
- 在访问洪峰到达前缓存热点数据,过期时间设置到流量最低时段
7.4Jmeter测试(压测)
jmeter是基于java开发的测试工具,因此需要先安装jdk

7.4.1创建测试计划

7.4.2创建线程组


7.4.3设置HTTP请求



八.Redis高级应用(高可用)
使用redis作为缓存数据库使用目的是为了提升数据加载速度,降低数据库的访问压力,我们需要保证redis的可用性。
- 主从模式
- 哨兵模式
- 集群模式
8.1主从配置
主从配置:在多个redis实例建立起主从关系,当主redis中的数据发生变化,从redis中的数据也会同步变化。
- 通过主从配置可以实现redis的数据备份(从redis就是对主redis的备份),保证数据的安全性
- 通过主从配置可以实现redis的读写分离

主从配置示例:
- 启动3个redis实例
##在redis-5.0.5目录下创建msconf文件夹
[root@localhost redis-5.0.5]# mkdir msconf
##拷贝redis.conf文件3份到 msconf中:---->redis-master.conf
[root@localhost redis-5.0.5]# cat redis.conf | grep -v "#" | grep -v "^$" > msconf/redis-master.conf
##修改如下内容:

##
sed 's/6380/6382/g' redis-master.conf > redis-slave2.conf
##修改从节点配置文件 设置跟从 主服务
slaveof 127.0.0.1 6380
##启动3个实例
redis-server redis-slave2.conf &
...
8.2哨兵模式(解决redis高可用)
用于监听主库状态,发现主库宕机后,从备库中选取一个转备为主。

- 哨兵模式配置
##首先实现3个主从实例
##创建并启动3个哨兵
##拷贝sentinel.conf文件 ---3份---
cat sentinel.conf | grep -v "#" | grep -v "^&" > sentinelconf/sentinel-26830.conf
sed 's/26380/26381/g' sentinel-26830.conf > sentinel-26832.conf

8.3集群配置

高可用:保证redis一直处于可用状态,即使出现了故障也有备用方案保证可用性
高并发:一个redis实例已经可以支持达到11w并发读操作或者8.1w次并发写操作,但是如果对于有更高并发要求的应用来说,我们可以通过读写分离、集群配置 来解决高并发问题
Redis集群:
- redis集群中每个节点是对等的,务中心结构
- 数据按照slots分布式存储在不同的redis节点上,节点中的数据可共享,可动态调整数据的分布
- 可扩展性强,可以动态增删节点,最多可扩展至1000+节点
- 集群也可以做高可用:集群每个节点通过主备(哨兵模式)保证其高可用
集群搭建:
-
[root@localhost redis-5.0.5]# mkdir cluster-conf [root@localhost redis-5.0.5]# cat redis.conf | grep -v "#" |grep -v "^$" > cluster-conf/redis-7001.conf 配置修改: [root@localhost cluster-conf]# cat redis-7001.conf #bind 127.0.0.1 protected-mode no port 7001 cluster-enabled yes cluster-config-file nodes-7001.conf cluster-node-timeout 15000 daemonize yes pidfile /var/run/redis_7001.pid dbfilename dump_7001.rdb appendfilename "appendonly_7001.aof" 拷贝6个文件: [root@localhost cluster-conf]# sed 's/7001/7002/g' redis-7001.conf > redis-7002.conf [root@localhost cluster-conf]# sed 's/7001/7003/g' redis-7001.conf > redis-7003.conf [root@localhost cluster-conf]# sed 's/7001/7004/g' redis-7001.conf > redis-7004.conf [root@localhost cluster-conf]# sed 's/7001/7005/g' redis-7001.conf > redis-7005.conf [root@localhost cluster-conf]# sed 's/7001/7006/g' redis-7001.conf > redis-7006.conf [root@localhost cluster-conf]# redis-server redis-7006.conf & [1] 45884 [root@localhost cluster-conf]# 45884:C 15 Nov 2022 02:51:33.366 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo 45884:C 15 Nov 2022 02:51:33.366 # Redis version=5.0.5, bits=64, commit=00000000, modified=0, pid=45884, just started [root@localhost cluster-conf]# ps -ef | grep redis root 4622 1 0 11月14 ? 00:00:59 redis-server *:6379 root 41035 1 0 02:50 ? 00:00:00 redis-server *:7001 [cluster] root 43208 1 0 02:51 ? 00:00:00 redis-server *:7002 [cluster] root 43847 1 0 02:51 ? 00:00:00 redis-server *:7003 [cluster] root 44578 1 0 02:51 ? 00:00:00 redis-server *:7004 [cluster] root 45158 1 0 02:51 ? 00:00:00 redis-server *:7005 [cluster] root 45886 1 0 02:51 ? 00:00:00 redis-server *:7006 [cluster] root 49850 122077 0 02:06 pts/3 00:00:03 redis-server *:6381 root 51542 49973 0 02:07 pts/5 00:00:03 redis-server *:6382 root 54481 89509 0 02:52 pts/13 00:00:00 grep --color=auto redis root 55835 52559 0 02:08 pts/7 00:00:05 redis-sentinel *:26380 [sentinel] root 58802 56918 0 02:09 pts/9 00:00:05 redis-sentinel *:26381 [sentinel] root 67060 59595 0 02:10 pts/11 00:00:05 redis-sentinel *:26382 [sentinel] root 80844 120115 0 02:13 pts/1 00:00:03 redis-server *:6380 启动集群: [root@localhost cluster-conf]# redis-cli --cluster create 192.168.36.132:7001 192.168.36.132:7002 192.168.36.132:7003 192.168.36.132:7004 192.168.36.132:7005 192.168.36.132:7006 --cluster-replicas 1 >>> Performing hash slots allocation on 6 nodes... Master[0] -> Slots 0 - 5460 Master[1] -> Slots 5461 - 10922 Master[2] -> Slots 10923 - 16383 Adding replica 192.168.36.132:7005 to 192.168.36.132:7001 Adding replica 192.168.36.132:7006 to 192.168.36.132:7002 Adding replica 192.168.36.132:7004 to 192.168.36.132:7003 >>> Trying to optimize slaves allocation for anti-affinity [WARNING] Some slaves are in the same host as their master M: b473b2d08963136a73767073c868bfdbf414a6e8 192.168.36.132:7001 slots:[0-5460] (5461 slots) master M: c9a0284abcd481058ac6133ee2be5127ee564c39 192.168.36.132:7002 slots:[5461-10922] (5462 slots) master M: 4921557dc0e3d1a807f7e7202572b3f199d1e8ef 192.168.36.132:7003 slots:[10923-16383] (5461 slots) master S: c77038d74212126c829de18565f916ffcc04daf0 192.168.36.132:7004 replicates 4921557dc0e3d1a807f7e7202572b3f199d1e8ef S: 0ec9f7e6764913dd4e3d14f2473b4f2fd5182724 192.168.36.132:7005 replicates b473b2d08963136a73767073c868bfdbf414a6e8 S: a8b3b364bc2e496ccbc9c8dc4b8695f5eb1531a6 192.168.36.132:7006 replicates c9a0284abcd481058ac6133ee2be5127ee564c39 Can I set the above configuration? (type 'yes' to accept): Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join ........... >>> Performing Cluster Check (using node 192.168.36.132:7001) M: b473b2d08963136a73767073c868bfdbf414a6e8 192.168.36.132:7001 slots:[0-5460] (5461 slots) master 1 additional replica(s) M: c9a0284abcd481058ac6133ee2be5127ee564c39 192.168.36.132:7002 slots:[5461-10922] (5462 slots) master 1 additional replica(s) S: 0ec9f7e6764913dd4e3d14f2473b4f2fd5182724 192.168.36.132:7005 slots: (0 slots) slave replicates b473b2d08963136a73767073c868bfdbf414a6e8 S: a8b3b364bc2e496ccbc9c8dc4b8695f5eb1531a6 192.168.36.132:7006 slots: (0 slots) slave replicates c9a0284abcd481058ac6133ee2be5127ee564c39 M: 4921557dc0e3d1a807f7e7202572b3f199d1e8ef 192.168.36.132:7003 slots:[10923-16383] (5461 slots) master 1 additional replica(s) S: c77038d74212126c829de18565f916ffcc04daf0 192.168.36.132:7004 slots: (0 slots) slave replicates 4921557dc0e3d1a807f7e7202572b3f199d1e8ef [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. 连接集群: [root@localhost cluster-conf]# redis-cli -p 7001 -c 127.0.0.1:7001> set k1 v1 -> Redirected to slot [12706] located at 192.168.36.132:7003 OK 192.168.36.132:7003> set k2 v2 -> Redirected to slot [449] located at 192.168.36.132:7001 OK 192.168.36.132:7001> keys * 1) "k2" 192.168.36.132:7001> set k3 v3 OK 192.168.36.132:7001> keys * 1) "k3" 2) "k2" 192.168.36.132:7001>
集群管理:
1.如果集群启动失败等待节点加入:
- 云服务器检查安全组是否放行redis实例端口,以及+10000的端口
- linux是否关闭防火墙
- Linux状态top----------更换操作系统
- redis配置文件错误
2.创建集群:
ruby:脚本启动
redis-cli --cluster create 192.168.36.132:7001 192.168.36.132:7002 192.168.36.132:7003 192.168.36.132:7004 192.168.36.132:7005 192.168.36.132:7006 --cluster-replicas 1
3.查看集群状态:
[root@localhost cluster-conf]# redis-cli --cluster info 192.168.36.132:7001
192.168.36.132:7001 (b473b2d0...) -> 2 keys | 5461 slots | 1 slaves.
192.168.36.132:7002 (c9a0284a...) -> 0 keys | 5462 slots | 1 slaves.
192.168.36.132:7003 (4921557d...) -> 1 keys | 5461 slots | 1 slaves.
[OK] 3 keys in 3 masters.
0.00 keys per slot on average.
4.平衡节点数据槽数量
[root@localhost cluster-conf]# redis-cli --cluster rebalance 192.168.36.132:7001
>>> Performing Cluster Check (using node 192.168.36.132:7001)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
*** No rebalancing needed! All nodes are within the 2.00% threshold.
5.迁移节点槽

[root@localhost cluster-conf]# redis-cli --cluster reshard 192.168.36.132:7001
>>> Performing Cluster Check (using node 192.168.36.132:7001)
M: b473b2d08963136a73767073c868bfdbf414a6e8 192.168.36.132:7001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: c9a0284abcd481058ac6133ee2be5127ee564c39 192.168.36.132:7002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: 0ec9f7e6764913dd4e3d14f2473b4f2fd5182724 192.168.36.132:7005
slots: (0 slots) slave
replicates b473b2d08963136a73767073c868bfdbf414a6e8
S: a8b3b364bc2e496ccbc9c8dc4b8695f5eb1531a6 192.168.36.132:7006
slots: (0 slots) slave
replicates c9a0284abcd481058ac6133ee2be5127ee564c39
M: 4921557dc0e3d1a807f7e7202572b3f199d1e8ef 192.168.36.132:7003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: c77038d74212126c829de18565f916ffcc04daf0 192.168.36.132:7004
slots: (0 slots) slave
replicates 4921557dc0e3d1a807f7e7202572b3f199d1e8ef
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
How many slots do you want to move (from 1 to 16384)? 3
What is the receiving node ID? c9a0284abcd481058ac6133ee2be5127ee564c39
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: b473b2d08963136a73767073c868bfdbf414a6e8
Source node #2: done
Ready to move 3 slots.
Source nodes:
M: b473b2d08963136a73767073c868bfdbf414a6e8 192.168.36.132:7001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
Destination node:
M: c9a0284abcd481058ac6133ee2be5127ee564c39 192.168.36.132:7002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
Resharding plan:
Moving slot 0 from b473b2d08963136a73767073c868bfdbf414a6e8
Moving slot 1 from b473b2d08963136a73767073c868bfdbf414a6e8
Moving slot 2 from b473b2d08963136a73767073c868bfdbf414a6e8
Do you want to proceed with the proposed reshard plan (yes/no)? yes
Moving slot 0 from 192.168.36.132:7001 to 192.168.36.132:7002:
Moving slot 1 from 192.168.36.132:7001 to 192.168.36.132:7002:
Moving slot 2 from 192.168.36.132:7001 to 192.168.36.132:7002:
8.4springboot应用连接redis集群
- 添加依赖
org.springframework.boot
spring-boot-starter-data-redis
- 配置集群节点
spring:
redis:
cluster:
nodes: 192.168.36.132:7001,192.168.36.132:7002,192.168.36.132:7003
max-redirects: 3
- 测试类
@RunWith(SpringRunner.class)
@SpringBootTest(classes = RedisDemo3Application.class)
public class RedisDemo3ApplicationTests {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Test
public void contextLoads() {
stringRedisTemplate.boundValueOps("key1").set("value1");
}
@Test
public void test01(){
String key1 = stringRedisTemplate.boundValueOps("key1").get();
System.out.println(key1);
}
}
总结:Redis高频面试题
1.在项目中redis的使用场景—
- 用于缓存首页数据
1. 缓存
作为Key-Value形态的内存数据库,Redis 最先会被想到的应用场景便是作为数据缓存。而使用 Redis 缓存数据非常简单,只需要通过string类型将序列化后的对象存起来即可,不过也有一些需要注意的地方:
必须保证不同对象的 key 不会重复,并且使 key 尽量短,一般使用类名(表名)加主键拼接而成。
选择一个优秀的序列化方式也很重要,目的是提高序列化的效率和减少内存占用。
缓存内容与数据库的一致性,这里一般有两种做法:
只在数据库查询后将对象放入缓存,如果对象发生了修改或删除操作,直接清除对应缓存(或设为过期)。
在数据库新增和查询后将对象放入缓存,修改后更新缓存,删除后清除对应缓存(或设为过期)。
2. 数据共享分布式
String 类型,因为 Redis 是分布式的独立服务,可以在多个应用之间共享
例如:分布式Session
org.springframework.session
spring-session-data-redis
3、分布式锁
如今都是分布式的环境下java自带的单体锁已经不适用的。在 Redis 2.6.12 版本开始,string的set命令增加了一些参数:
EX:设置键的过期时间(单位为秒)
PX:设置键的过期时间(单位为毫秒)
NX :只在键不存在时,才对键进行设置操作。 SET key value NX 效果等同于 SETNX key value 。
XX :只在键已经存在时,才对键进行设置操作。
由于这个操作是原子性的,可以简单地以此实现一个分布式的锁,例如:
set lock_key locked NX EX 1
1
如果这个操作返回false,说明 key 的添加不成功,也就是当前有人在占用这把锁。而如果返回true,则说明得了锁,便可以继续进行操作,并且在操作后通过del命令释放掉锁。并且即使程序因为某些原因并没有释放锁,由于设置了过期时间,该锁也会在 1 秒后自动释放,不会影响到其他程序的运行。
推荐使用 redisson 第三方库实现分布式锁。
参考 java分布式锁终极解决方案之 redisson
4、全局ID
int类型,incrby,利用原子性
incrby userid 1000
分库分表的场景,一次性拿一段
5、计数器
int类型,incr方法
例如:文章的阅读量、微博点赞数、允许一定的延迟,先写入Redis再定时同步到数据库
计数功能应该是最适合 Redis 的使用场景之一了,因为它高频率读写的特征可以完全发挥 Redis 作为内存数据库的高效。在 Redis 的数据结构中,string、hash和sorted set都提供了incr方法用于原子性的自增操作,下面举例说明一下它们各自的使用场景:
如果应用需要显示每天的注册用户数,便可以使用string作为计数器,设定一个名为REGISTERED_COUNT_TODAY的 key,并在初始化时给它设置一个到凌晨 0 点的过期时间,每当用户注册成功后便使用incr命令使该 key 增长 1,同时当每天凌晨 0 点后,这个计数器都会因为 key 过期使值清零。
每条微博都有点赞数、评论数、转发数和浏览数四条属性,这时用hash进行计数会更好,将该计数器的 key 设为weibo:weibo_id,hash的 field 为like_number、comment_number、forward_number和view_number,在对应操作后通过hincrby使hash 中的 field 自增。
如果应用有一个发帖排行榜的功能,便选择sorted set吧,将集合的 key 设为POST_RANK。当用户发帖后,使用zincrby将该用户 id 的 score 增长 1。sorted set会重新进行排序,用户所在排行榜的位置也就会得到实时的更新。
6、限流
int类型,incr方法
以访问者的ip和其他信息作为key,访问一次增加一次计数,超过次数则返回false
7、位统计
String类型的bitcount(1.6.6的bitmap数据结构介绍)
字符是以8位二进制存储的
set k1 a
setbit k1 6 1
setbit k1 7 0
get k1
/* 6 7 代表的a的二进制位的修改
a 对应的ASCII码是97,转换为二进制数据是01100001
b 对应的ASCII码是98,转换为二进制数据是01100010
因为bit非常节省空间(1 MB=8388608 bit),可以用来做大数据量的统计。
*/
参考 使用Redis的bitmaps统计用户留存率、活跃用户
用户日活月活怎么统计 - Redis HyperLogLog 详解
8. 时间轴(Timeline)
list作为双向链表,不光可以作为队列使用。如果将它用作栈便可以成为一个公用的时间轴。当用户发完微博后,都通过lpush将它存放在一个 key 为LATEST_WEIBO的list中,之后便可以通过lrange取出当前最新的微博。
9. 消息队列
Redis 中list的数据结构实现是双向链表,所以可以非常便捷的应用于消息队列(生产者 / 消费者模型)。消息的生产者只需要通过lpush将消息放入 list,消费者便可以通过rpop取出该消息,并且可以保证消息的有序性。如果需要实现带有优先级的消息队列也可以选择sorted set。而pub/sub功能也可以用作发布者 / 订阅者模型的消息。无论使用何种方式,由于 Redis 拥有持久化功能,也不需要担心由于服务器故障导致消息丢失的情况。
List提供了两个阻塞的弹出操作:blpop/brpop,可以设置超时时间
blpop:blpop key1 timeout 移除并获取列表的第一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
brpop:brpop key1 timeout 移除并获取列表的最后一个元素,如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止。
上面的操作。其实就是java的阻塞队列。学习的东西越多。学习成本越低
队列:先进先除:rpush blpop,左头右尾,右边进入队列,左边出队列
栈:先进后出:rpush brpop
10、抽奖
利用set结构的无序性,通过 Spop( Redis Spop 命令用于移除集合中的指定 key 的一个或多个随机元素,移除后会返回移除的元素。 ) 随机获得值
redis> SADD myset "one"
(integer) 1
redis> SADD myset "two"
(integer) 1
redis> SADD myset "three"
(integer) 1
redis> SPOP myset
"one"
redis> SMEMBERS myset
1) "three"
2) "two"
redis> SADD myset "four"
(integer) 1
redis> SADD myset "five"
(integer) 1
redis> SPOP myset 3
1) "five"
2) "four"
3) "two"
redis> SMEMBERS myset
1) "three"
11、点赞、签到、打卡
假如上面的微博ID是t1001,用户ID是u3001
用 like:t1001 来维护 t1001 这条微博的所有点赞用户
点赞了这条微博:sadd like:t1001 u3001
取消点赞:srem like:t1001 u3001
是否点赞:sismember like:t1001 u3001
点赞的所有用户:smembers like:t1001
点赞数:scard like:t1001
是不是比数据库简单多了。
12 商品标签
老规矩,用 tags:i5001 来维护商品所有的标签。
sadd tags:i5001 画面清晰细腻
sadd tags:i5001 真彩清晰显示屏
sadd tags:i5001 流程至极
13、好友关系、用户关注、推荐模型
这个场景最开始是是一篇介绍微博 Redis 应用的 PPT 中看到的,其中提到微博的 Redis 主要是用在在计数和好友关系两方面上,当时对好友关系方面的用法不太了解,后来看到《Redis 设计与实现》中介绍到作者最开始去使用 Redis 便是希望能通过set解决传统数据库无法快速计算集合中交集这个功能。后来联想到微博当前的业务场景,确实能够以这种方式实现,所以姑且猜测一下:
对于一个用户 A,将它的关注和粉丝的用户 id 都存放在两个 set 中:
A:follow:存放 A 所有关注的用户 id
A:follower:存放 A 所有粉丝的用户 id
那么通过sinter命令便可以根据A:follow和A:follower的交集得到与 A 互相关注的用户。当 A 进入另一个用户 B 的主页后,A:follow和B:follow的交集便是 A 和 B 的共同专注,A:follow和B:follower的交集便是 A 关注的人也关注了 B。
举例
follow 关注 fans 粉丝
相互关注:
sadd 1:follow 2
sadd 2:fans 1
sadd 1:fans 2
sadd 2:follow 1
我关注的人也关注了他(取交集):
sinter 1:follow 2:fans
可能认识的人:
用户1可能认识的人(差集):sdiff 2:follow 1:follow
用户2可能认识的人:sdiff 1:follow 2:follow
14 .排行榜
使用sorted set(有序set)和一个计算热度的算法便可以轻松打造一个热度排行榜,zrevrangebyscore可以得到以分数倒序排列的序列,zrank可以得到一个成员在该排行榜的位置(是分数正序排列时的位置,如果要获取倒序排列时的位置需要用zcard-zrank)。
id 为6001 的新闻点击数加1:
zincrby hotNews:20190926 1 n6001
1
获取今天点击最多的15条:
zrevrange hotNews:20190926 0 15 withscores
1
15 .倒排索引
倒排索引是构造搜索功能的最常见方式,在 Redis 中也可以通过set进行建立倒排索引,这里以简单的拼音 + 前缀搜索城市功能举例:
假设一个城市北京,通过拼音词库将北京转为beijing,再通过前缀分词将这两个词分为若干个前缀索引,有:北、北京、b、be…beijin和beijing。将这些索引分别作为set的 key(例如:index:北)并存储北京的 id,倒排索引便建立好了。接下来只需要在搜索时通过关键词取出对应的set并得到其中的 id 即可。
16 .显示最新的项目列表
比如说,我们的一个Web应用想要列出用户贴出的最新20条评论。在最新的评论边上我们有一个“显示全部”的链接,点击后就可以获得更多的评论。
每次新评论发表时,我们会将它的ID添加到一个Redis列表。可以限定列表的长度为5000
LPUSH latest.comments
在Redis中我们的最新ID使用了常驻缓存,这是一直更新的。但是我们做了限制不能超过5000个ID,因此我们的获取ID函数会一直询问Redis。只有在超出了这个范围的时候,才需要去访问数据库。
2.Redis持久化策略
-
rdb
-
aof
持久化策略分别是:RDB和AOF
RDB:当redis中的写操作达到指定的次数同时距离上一次持久化达到指定的时间就会将redis内存中的数据生成数据快照保存到RDB文件中
AOF:redis默认的aof是未开启的,可以通过redis的配置文件中的‘APPendonly yes’进行开启,AOF存储的是指令,而且会对指令进行整理。AOF是对数据进行的是增量更新,而RDB是生成数据快照
3.redis常用数据类型
String(字符串): string 是 redis 最基本的类型,一个 key 对应一个 value.
hash(哈希):Redis hash 是一个键值(key=>value)对集合。 Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。 使用场景:存储、读取、修改用户属性
List(列表):Redis List是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
Set(集合):Redis Set是string类型的无序集合。
zset(sorted set:有序集合):Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。zset的成员是唯一的,但分数(score)却可以重复。
使用场景:
1.带有权重的元素,比如一个游戏的用户得分排行榜
2.比较复杂的数据结构,一般用到的场景不算太多
4.redis如何保证高可用
- redis支持持久化,同时开启rdb和aof。以保证数据的安全性(还是存在数据丢失风险)
- redis支持主从配置,我们可以通过哨兵,实现主备配置,保证可用性
- redis也支持集群,通过集群配置可以保证redis的高并发
5.你刚才提到redis集群,请问如何解决redis集群的脑裂问题?
Redis脑裂现象及解决方案
什么是Redis的脑裂现象
当Redis主从集群环境出现两个主节点为客户端提供服务,这时客户端请求命令可能会发生数据丢失的情况。
脑裂出现的场景
场景一
主从哨兵集群中如果当发生主从集群切换时,那么一定是超过预设quorum数量的哨兵和主库连接超时了,这时哨兵集群才会将主库判断为客观下线,然后哨兵开始选举新的主节点,进行故障转移,转移完毕后客户端和新的主节点通信恢复正常请求。
如果在哨兵进行选举,故障转移的过程中原主节点恢复和客户端的通信,那么证明原主节点没有真正的故障,这时客户端依旧可以向原主节点正常通信,这就是脑裂产生的第一个场景,示意图如下
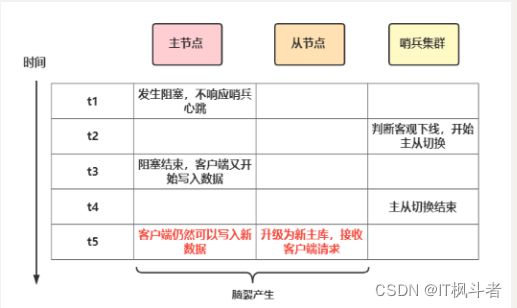
场景二
网络分区,主节点和客户端,哨兵和从库分割为了两个网络,主库和客户端处在一个网络中,从库和哨兵在另外一个网络中,此时哨兵也会发起主从切换,出现两个主节点的情况。

脑裂带来的影响
脑裂出现后带来最严重的后果就是数据丢失,为什么会出现数据丢失的问题呢,主要原因是新主库确定后会向所有的实例发送slave of命令,让所有实例重新进行全量同步,而全量同步首先就会将实例上的数据先清空,所以在主从同步期间在原主库执行的命令将会被清空(上面场景二是同样的道理,在网络分区恢复后原主节点将被降级为从节点,并且执行全量同步导致数据丢失),所以这就是数据丢失的具体原因。

如何应对脑裂
脑裂的主要原因其实就是哨兵集群认为主节点已经出现故障了,重新选举其它从节点作为主节点,而原主节点其实是假故障,从而导致短暂的出现两个主节点,那么在主从切换期间客户端一旦给原主节点发送命令,就会造成数据丢失。
所以应对脑裂的解决办法应该是去限制原主库接收请求,Redis提供了两个配置项。
min-slaves-to-write:与主节点通信的从节点数量必须大于等于该值主节点,否则主节点拒绝写入。
min-slaves-max-lag:主节点与从节点通信的ACK消息延迟必须小于该值,否则主节点拒绝写入。
这两个配置项必须同时满足,不然主节点拒绝写入。
在假故障期间满足min-slaves-to-write和min-slaves-max-lag的要求,那么主节点就会被禁止写入,脑裂造成的数据丢失情况自然也就解决了。
脑裂可以完全解决吗
通过上面的学习我们知道了脑裂出现的场景,带来的问题,以及解决办法,那么脑裂问题可以完全被解决吗?我们直接看下面的场景
为了防止脑裂我们将min-slaves-to-write设置为1,min-slaves-max-lag设置为12s,down-after-milliseconds哨兵判断主节点客观下线的限制为10s,主节点因为某些原因卡住了15s,导致哨兵集群判断主节点为主观下线,主从切换,因为没有一个从节点与主节点之间的数据复制在12s内,这样就规避脑裂的情况。
但是我们再看另外一个场景 ’
我们同样将min-slaves-to-write设置为1,min-slaves-max-lag 设置为 15s,down-after-milliseconds哨兵判断主节点客观下线的限制为10s,哨兵主从切换需要 5s。主节点因为某些原因卡住了 12s,这时还会发生脑裂吗?
主节点卡住12s这时哨兵集群判断主节点下线,同时哨兵集群做主从切换需要5s,这就意味着主从切换过程中,主节点恢复运行,而min-slaves-max-lag设置为15s那么主节点还是可写,也就是说在12s~15s这期间如果有客户端写入原主节点,那么这段时间的数据会丢失。
总结
Redis脑裂可以采用min-slaves-to-write和min-slaves-max-lag合理配置尽量规避,但无法彻底解决,Redis脑裂最本质的问题是主从集群内部没有共识算法来维护多个节点的强一致性,它不像Zookeeper那样,每次写入必须大多数节点成功后才算成功,当脑裂发生时,Zookeeper节点被孤立,此时无法写入大多数节点,写请求会直接失败,因此Zookeeper才能保证集群的强一致性。
6.redis的数据可以设置过期时间,当数据过期后有些key并没有及时清除,请问如何处理?
关于这个问题的解决之前,我们必须要了解的是,为什么会产生redis中设置了过期时间但是数据并没有及时清除这个问题是如何产生的,然后再根据具体的产生原因分别进行选择性处理。原因大致有以下几点:
对于过期数据数据的处理redis提供了两种方式,分别是惰性删除和定期删除。
惰性删除:也称被动删除,但数据过期之后,并不会马上删除。而是等到you请求访问的时候,对数据进行检查,如果过期,再删除。
优点:不需要单独的额外的扫描线程,减少了CPU资源的消耗
缺点:大量的过期数据滞留在内存中,只有主动触发才会检查删除,否则会一直占用内存资源
定期删除:每隔一段时间,默认是100ms,Redis会随机挑选一定数量的key,检查是否过期,并将过期的数据删除
为什么会产生过期数据继续能拉取到呢?这就要从客户端主库写入数据说起,当往主库中写入数据后,设置过期时间,数据会以异步的方式同步给从库,如果此时读取主库,数据已经过期,主库的惰性删除会发挥作用,主动触触发操作,客户端不会拿到已经过期的数据,由于Redis采取的一主多从,如果此时数据从‘从库’拿取数据,就会拿到过期数据,原因则是由于redis版本的原因,在Redis4.2之前的版本,读从库并不会判断数据是否过期,所以有可能返回过期数据
解决措施
升级Redis版本,至少要Redis3.2以上的版本,读从库,如果数据已经过期,则会过滤并返回空值;但是值得注意的是:升级Redis之后,同步过来的数据,虽然已经过期,但是本着谁生产谁维护,从库不会主动删除同步过来的数据,需要依赖于主节点同步过来的key删除命令
另个原因则是和Redis对过期时间的设置有关系,我们一般采取的是EXPIRE和PEXPIRE,表示从执行命令那个时刻开始,往后延长了ttl时间。严重依赖于开始时间从什么时候算起的。(EXPIRE:单位是秒 ; PEXPIRE:单位是毫秒)。当客户端将数据写入主库,主库再向从库中同步数据,这期间的时间间隔会影响数据的过期的时间。
解决措施
可以采取Redis的另外两个命令,EXPIREAT和PEXPIREAT,相对简单,表示过期时间为一个具体的时间点。避免了对开始时间从什么时候算起的依赖
EXPIREAT:单位是秒
PEXPIREAT:单位是毫秒
十一、使用Redis实现分布式会话
11.1流程分析

11.2在项目中使用redis实现分布式会话

11.2.1修改登录接口
- 当登陆成功后以token为key,将用户信息保存到redis中
@Service
public class UsersServiceImpl implements UsersServie {
@Autowired
private UsersMapper usersMapper;
@Resource
private StringRedisTemplate stringRedisTemplate;
private ObjectMapper objectMapper = new ObjectMapper();
@Transactional
@Override
public ResultVO userResgit(String name, String pwd) {
...
}
@Override
public ResultVO checkLogin(String name, String pwd) {
Example example = new Example(Users.class);
Example.Criteria criteria = example.createCriteria();
criteria.andEqualTo("username",name);
List<Users> users = usersMapper.selectByExample(example);
if (users.size() == 0 ){
return new ResultVO(ResStatus.NO,"登录失败,用户名不存在!",null);
}else {
String md5 = MD5Utils.md5(pwd);
if (md5.equals(users.get(0).getPassword())){
//如何登录成功 则需要生成token(token就是按特定规则生成的字符串)
JwtBuilder builder = Jwts.builder();
HashMap<String,Object> map = new HashMap<>();
//.setClaims(map) //map中存放用户的角色权限信息
String token = builder.setSubject(name) //主题,就是token中携带的数据
.setIssuedAt(new Date()) //设置token的⽣成时间
.setId(users.get(0).getUserId() + "") //设置⽤户id为token id
.setExpiration(new Date(System.currentTimeMillis() + 24 * 60 * 60 * 1000)) //设置过期时间
.signWith(SignatureAlgorithm.HS256,"QIANfeng6666") //设置加密⽅式和加密密码
.compact();
//当用户登录成功后,以token为key 将用户信息存储到redis中
try {
String userInfo = objectMapper.writeValueAsString(users.get(0));
stringRedisTemplate.boundValueOps(token).set(userInfo,30, TimeUnit.MINUTES);
} catch (JsonProcessingException e) {
e.printStackTrace();
}
return new ResultVO(ResStatus.OK,token,users.get(0));
}else {
return new ResultVO(ResStatus.NO,"登录失败,密码错误!",null);
}
}
}
}
11.2.2在需要使用用户信息的位置,直接根据token从redis中查询
@Resource
private StringRedisTemplate stringRedisTemplate;
@Autowired
private ObjectMapper objectMapper;
@PostMapping("/add")
@ApiOperation("购物车添加接口")
public ResultVO addShoppingCart(@RequestBody ShoppingCart cart, @RequestHeader("token")String token) throws JsonProcessingException {
ResultVO resultVO = shoppingCartService.addShoppingCart(cart);
// System.out.println(resultVO+"添加购物车");
String s = stringRedisTemplate.boundValueOps(token).get();
Users users = objectMapper.readValue(s, Users.class);
System.out.println(users);
System.out.println(token+"添加购物车");
return resultVO;
}
11.2.3修改登录验证拦截器
package com.fm.interceptor;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fm.vo.ResStatus;
import com.fm.vo.ResultVO;
import io.jsonwebtoken.*;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import org.springframework.web.servlet.HandlerInterceptor;
import javax.annotation.Resource;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
import java.io.PrintWriter;
import java.util.concurrent.TimeUnit;
@Component
public class CheckTokenInterceptor implements HandlerInterceptor {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Autowired
private ObjectMapper objectMapper;
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
String method = request.getMethod();
if("OPTIONS".equalsIgnoreCase(method)){
System.out.println("OPTIONS请求,放行");
return true;
}
String token = request.getHeader("token");
System.out.println(token+"拦截器");
if(token == null){
ResultVO resultVO = new ResultVO(ResStatus.LOGIN_FAIL_NOT, "请先登录!", null);//提示请先登录
doResponse(response,resultVO);
}else{
//
String s = stringRedisTemplate.boundValueOps(token).get();
if (s ==null){
ResultVO resultVO = new ResultVO(ResStatus.LOGIN_FAIL_NOT, "请先登录!", null);
doResponse(response,resultVO);
}else {
stringRedisTemplate.boundValueOps(token).expire(30, TimeUnit.MINUTES);
return true;
}
// try {
// //验证token
// JwtParser parser = Jwts.parser();
// //解析token的SigningKey必须和⽣成token时设置密码⼀致
// parser.setSigningKey("QIANfeng6666");
// //如果token正确(密码正确,有效期内)则正常执⾏,否则抛出异常
// Jws claimsJws = parser.parseClaimsJws(token);
// //doResponse(response,new ResultVO(ResStatus.LOGIN_SUCCESS, "success",claimsJws));
// return true;
// }catch (ExpiredJwtException e){
// ResultVO resultVO = new ResultVO(ResStatus.LOGIN_FAIL_OVERDUE, "登录过期,请重新登录!", null);
// doResponse(response,resultVO);
// }catch (UnsupportedJwtException e){
// ResultVO resultVO = new ResultVO(ResStatus.NO, "Token不合法,请⾃重!", null);
// doResponse(response,resultVO);
// }catch (Exception e){
// ResultVO resultVO = new ResultVO(ResStatus.LOGIN_FAIL_NOT, "请先登录!", null);
// doResponse(response,resultVO);
// }
}
return false;
}
private void doResponse(HttpServletResponse response,ResultVO resultVO) throws IOException {
response.setContentType("application/json");
response.setCharacterEncoding("utf-8");
PrintWriter out = response.getWriter();
String s = new ObjectMapper().writeValueAsString(resultVO);
out.print(s);
out.flush();
out.close();
}
}
11.2.4创建非受限资源拦截器
即使访问的是非受限资源,但是如果已经登录,只要与服务器有交互也要续命
package com.fm.interceptor;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fm.vo.ResStatus;
import com.fm.vo.ResultVO;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import org.springframework.web.servlet.HandlerInterceptor;
import javax.annotation.Resource;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.util.concurrent.TimeUnit;
@Component
public class SetTimeInterceptor implements HandlerInterceptor {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Autowired
private ObjectMapper objectMapper;
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// String method = request.getMethod();
// if("OPTIONS".equalsIgnoreCase(method)){
// System.out.println("OPTIONS请求,放行");
// return true;
// }
String token = request.getHeader("token");
System.out.println(token+"任意放行拦截器");
if(token != null){
String s = stringRedisTemplate.boundValueOps(token).get();
if (s != null){
stringRedisTemplate.boundValueOps(token).expire(30,TimeUnit.MINUTES);
}
}
return true;
}
}
- 配置拦截器
package com.fm.config;
import com.fm.interceptor.CheckTokenInterceptor;
import com.fm.interceptor.SetTimeInterceptor;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.*;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
import javax.annotation.Resource;
@Configuration
public class InterceptorConfig implements WebMvcConfigurer {
@Resource
private CheckTokenInterceptor checkTokenInterceptor;
@Resource
private SetTimeInterceptor setTimeInterceptor;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(checkTokenInterceptor)
.addPathPatterns("/shopcart/**")
.addPathPatterns("/order/**")
.addPathPatterns("/useraddr/**")
.addPathPatterns("/users/check");
registry.addInterceptor(setTimeInterceptor).addPathPatterns("/**").excludePathPatterns("/users/login");
}
/**
* 与WebMvcConfigure类相比这里拦截方法不会与token拦截器冲突
* @param registry
*/
@Override
public void addResourceHandlers(ResourceHandlerRegistry registry) {
registry.addResourceHandler("doc.html")
.addResourceLocations("classpath:/META-INF/resources/");
registry.addResourceHandler("swagger-ui.html")
.addResourceLocations("classpath:/META-INF/resources/");
registry.addResourceHandler("/webjars/**")
.addResourceLocations("classpath:/META-INF/resources/webjars/");
}
}
十二.分布式锁
12.1分布式锁并发问题
提交订单:商品超卖问题

12.2如何解决分布式并发问题?
使用redis实现分布式锁

12.3使用Redis实现分布式锁–代码实现
@Resource
private StringRedisTemplate stringRedisTemplate;
private ObjectMapper objectMapper;
/**
*保存订单业务
* @param cids 1,6 2,7
* @return
*/
@Transactional
@Override
public Map addOrder(String cids , Orders orders) throws SQLException {
//
Map map = new HashMap<>();
//1.查询库存
String[] split = cids.split(",");
List cidsList= new ArrayList<>();
for (int i=0 ; i< split.length ;i++){
cidsList.add(Integer.parseInt(split[i]));
}
//根据用户在购物车列表选择的购物车id 查询到对应的购物车记录
List list = shoppingCartMapper.listByCids(cidsList);
//从购物车信息中获取到要购买的skuId(商品id) 以skuId为key存到redis中
boolean isLock =true;
String[] skuIds = new String[list.size()];
for (int i =0 ; i< list.size();i++){
String skuId = list.get(i).getSkuId();//订单中可能包含多个商品 每个skuid表示一个商品
Boolean ifAbsent = stringRedisTemplate.boundValueOps(skuId).setIfAbsent("fmmall");
if (ifAbsent){
skuIds[i] =skuId;
}
isLock = isLock && ifAbsent;
}
//如果isLock为true 表示”加锁“成功
if (isLock){
//1.比较库存:当第一次查询购物车记录后,在加锁成功之前,有可能被其他并发线程修改库存
List list = shoppingCartMapper.listByCids(cidsList);
//比较库存---添加订单---保存快照--修改库存--删除订单
//释放锁
for (int m =0; m< skuIds.length ;m++){
String skuId = skuIds[m];
if (skuId != null && !"".equals(skuId)){
stringRedisTemplate.delete(skuId);
}
}
}
map.put("orderId",orderId);
map.put("productNames",untitled);
return map;
}else {
//表示库存不足
return null;
}
}else {
//表示枷锁失败 订单提交失败
//当枷锁失败时 可能对部分商品已经锁定 要释放部分商品
for (int i =0; i< skuIds.length ;i++){
String skuId = skuIds[i];
if (skuId != null && !"".equals(skuId)){
stringRedisTemplate.delete(skuId);
}
}
return null;
}
}
问题:
1.如果订单中部分商品加锁成功,但是某一个加锁失败,导致最终加锁状态失败----需要对已锁定的部分商品释放锁
2.在成功加锁之前,我们根据购物车记录的id查询购物车记录(包含商品库存),能够直接使用这个库存进行库存校验?
—不能,因为查询之后加锁之前可能被并发线程修改了库存,因此在库存比较之前需要重新查询库存。
3.当当前线程加锁成功后,执行添加订单的过程中,如果当前线程出现异常导致无法释放锁,这个问题又该如何解决?
12.4解决因线程异常无法释放锁问题
解决方案:在对商品进行加锁时,设置过期时间,这样一来即使线程出现故障无法释放锁,在过期结束时也会自动释放”锁“

面试宝典
Redis概述
什么是Redis
Redis(Remote Dictionary Server) 是一个使用 C 语言编写的,开源的(BSD许可)高性能非关系型(NoSQL)的键值对数据库。
Redis 可以存储键和五种不同类型的值之间的映射。键的类型只能为字符串,值支持五种数据类型:字符串、列表、散列表、集合、有序集合。
与传统数据库不同的是 Redis 的数据是存在内存中的,所以读写速度非常快,因此 redis 被广泛应用于缓存方向,每秒可以处理超过 10万次读写操作,是已知性能最快的Key-Value DB。另外,Redis 也经常用来做分布式锁。除此之外,Redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
Redis有哪些优缺点
优点
- 读写性能优异, Redis能读的速度是110000次/s,写的速度是81000次/s。
- 支持数据持久化,支持AOF和RDB两种持久化方式。
- 数据结构丰富,除了支持string类型的value外还支持hash、set、zset、list等数据结构。
- 支持主从复制,主机会自动将数据同步到从机,可以进行读写分离。
- 支持事务,Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行。
缺点
- 数据库容量受到物理内存的限制,不能用作海量数据的高性能读写,因此Redis适合的场景主要局限在较小数据量的高性能操作和运算上。
- Redis 较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。为避免这一问题,运维人员在系统上线时必须确保有足够的空间,这对资源造成了很大的浪费。
- Redis 不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复。
- 主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性。
为什么要用 Redis /为什么要用缓存
主要从“高性能”和“高并发”这两点来看待这个问题。
高性能
假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。再将该用户访问的数据存在缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!

高并发
直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。

为什么要用 Redis 而不用 map/guava 做缓存?
缓存分为本地缓存和分布式缓存。以 Java 为例,使用自带的 map 或者 guava 实现的是本地缓存,最主要的特点是轻量以及快速,生命周期随着 jvm 的销毁而结束,并且在多实例的情况下,每个实例都需要各自保存一份缓存,缓存不具有一致性。
使用 redis 或 memcached 之类的称为分布式缓存,在多实例的情况下,各实例共用一份缓存数据,缓存具有一致性。缺点是需要保持 redis 或 memcached服务的高可用,整个程序架构上较为复杂。
@$Redis为什么这么快
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于 HashMap,HashMap 的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据操作也简单,Redis 中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4、使用 I/O 多路复用模型,非阻塞 IO;
数据类型
@$Redis有哪些数据类型
Redis主要有5种数据类型,包括String,List,Hash,Set,Zset,满足大部分的使用要求
| 数据类型 | 可以存储的值 | 操作 | 应用场景 |
|---|---|---|---|
| STRING | 字符串、整数或者浮点数 | 对整个字符串或者字符串的其中一部分执行操作对整数和浮点数执行自增或者自减操作 | 做简单的键值对缓存 |
| LIST | 列表 | 从两端压入或者弹出元素对单个或者多个元素进行修剪,只保留一个范围内的元素 | 存储一些列表型的数据结构,类似粉丝列表、文章的评论列表之类的数据 |
| HASH | 包含键值对的无序散列表 | 添加、获取、移除单个键值对获取所有键值对 检查某个键是否存在 | 结构化的数据,比如一个对象 |
| SET | 无序集合 | 添加、获取、移除单个元素检查一个元素是否存在于集合中 计算交集、并集、差集从集合里面随机获取元素 | 交集、并集、差集的操作,比如交集,可以把两个人的粉丝列表整一个交集 |
| ZSET | 有序集合 | 添加、获取、删除元素根据分值范围或者成员来获取元素 计算一个键的排名 | 去重但可以排序,如获取排名前几名的用户 |
Redis的应用场景
计数器
可以对 String 进行自增自减运算,从而实现计数器功能。Redis 这种内存型数据库的读写性能非常高,很适合存储频繁读写的计数量。
缓存
将热点数据放到内存中,设置内存的最大使用量以及淘汰策略来保证缓存的命中率。
会话缓存
可以使用 Redis 来统一存储多台应用服务器的会话信息。当应用服务器不再存储用户的会话信息,也就不再具有状态,一个用户可以请求任意一个应用服务器,从而更容易实现高可用性以及可伸缩性。
全页缓存(FPC)
除基本的会话token之外,Redis还提供很简便的FPC平台。以Magento为例,Magento提供一个插件来使用Redis作为全页缓存后端。此外,对WordPress的用户来说,Pantheon有一个非常好的插件 wp-redis,这个插件能帮助你以最快速度加载你曾浏览过的页面。
查找表
例如 DNS 记录就很适合使用 Redis 进行存储。查找表和缓存类似,也是利用了 Redis 快速的查找特性。但是查找表的内容不能失效,而缓存的内容可以失效,因为缓存不作为可靠的数据来源。
消息队列(发布/订阅功能)
List 是一个双向链表,可以通过 lpush 和 rpop 写入和读取消息。不过最好使用 Kafka、RabbitMQ 等消息中间件。
分布式锁实现
在分布式场景下,无法使用单机环境下的锁来对多个节点上的进程进行同步。可以使用 Redis 自带的 SETNX 命令实现分布式锁,除此之外,还可以使用官方提供的 RedLock 分布式锁实现。
其它
Set 可以实现交集、并集等操作,从而实现共同好友等功能。ZSet 可以实现有序性操作,从而实现排行榜等功能。
持久化
什么是Redis持久化?
持久化就是把内存的数据写到磁盘中去,防止服务宕机了内存数据丢失。
@$Redis 的持久化机制是什么?各自的优缺点?
Redis 提供两种持久化机制 RDB(默认) 和 AOF 机制:
RDB持久化:是Redis DataBase缩写,快照
RDB是Redis默认的持久化方式。按照一定的时间间隔将内存的数据以快照的形式保存到硬盘中,对应产生的数据文件为dump.rdb。通过配置文件中的save参数来定义快照的周期。

配置
# 表示 60 秒内如果至少有 1000 个 key 的值变化,则保存
save 60 1000
工作流程
- redis根据配置尝试去生成rdb快照文件
- redis主进程fork一个子进程出来
- 子进程尝试将内存中的数据dump到临时的rdb快照文件中
- 完成rdb快照文件的生成之后,覆盖旧的快照文件
优点
- 只有一个文件 dump.rdb,方便持久化,容灾性好。
- 性能最大化,fork 子进程来完成写操作,让主进程继续处理命令,保证了 redis 的高性能
- 数据集大时,比 AOF 的启动效率更高。
缺点
- 数据安全性低。RDB 是间隔一段时间进行持久化,如果持久化之间 redis 发生故障,会发生数据丢失。
AOF持久化:Append Only File缩写
将Redis执行的每条写命令记录到单独的aof日志文件中,当重启Redis服务时,会从持久化的日志文件中恢复数据。
当两种方式同时开启时,数据恢复时,Redis会优先选择AOF恢复。

配置
# 表示是否开启AOF持久化(默认no,关闭)
appendonly yes
# AOF持久化配置文件的名称
appendfilename “appendonly.aof”
# 缓存回写策略
appendfsync always (同步持久化,每次发生数据变更会被立即记录到磁盘,性能差但数据完整性比较好)
appendfsync everysec (异步操作,每秒记录,如果一秒钟内宕机,有数据丢失)
appendfsync no (将缓存回写的策略交给操作系统,linux 默认是30秒将缓冲区的数据回写硬盘的)
AOF的Rewrite(重写) :
定义:AOF采用文件追加的方式持久化数据,所以文件会越来越大,为了避免这种情况发生,增加了重写机制。重写机制主要是将文件中无效的命令去除。如同一个key的值,只保留最后一次写入,已删除或者已过期数据相关命令会被去除。
重写的触发方式:1.手动执行 bgrewriteaof 触发AOF重写;2.在redis.conf文件中配置重写的条件
# 当文件比上次重写后的文件大100%时进行重写
auto-aof-rewrite-percentage 100
# 当文件大于64M时进行重写
auto-aof-rewrite-min-size 64mb
工作流程
- 所有的写入命令会追加到AOF缓冲中。
- AOF缓冲区根据对应的策略向硬盘做同步操作。
- 随着AOF文件越来越大,需要定期对AOF文件进行重写,达到压缩的目的。
- 当Redis服务器重启时,可以加载AOF文件进行数据恢复。
优点
- 数据安全,可以配置每进行一次命令操作就记录到 aof 文件中一次。
- 通过 append 模式写文件,即使中途服务器宕机,可以通过 redis-check-aof 工具解决数据一致性问题。
缺点
- AOF 文件比 RDB 文件大,且恢复速度慢。
- 数据集大时,比 rdb 启动效率低。
如何选择合适的持久化方式
- 一般来说, 如果想达到足以媲美PostgreSQL的数据安全性,你应该同时使用两种持久化功能。在这种情况下,当 Redis 重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。
- 如果你非常关心你的数据, 但仍然可以承受数分钟以内的数据丢失,那么你可以只使用RDB持久化。
- 如果你只希望你的数据在服务器运行的时候存在,你也可以不使用任何持久化方式。
- 有很多用户都只使用AOF持久化,但并不推荐这种方式,因为定时生成RDB快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比AOF恢复的速度要快,除此之外,使用RDB还可以避免AOF程序的bug。
过期键的删除策略
@$Redis的过期键的删除策略
我们都知道,Redis是key-value数据库,我们可以设置Redis中缓存key的过期时间。Redis的过期策略就是指当Redis中缓存的key过期了,Redis如何处理。
过期策略通常有以下三种:
- 定时过期:每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源,从而影响缓存的响应时间和吞吐量。
- 惰性过期:只有当访问一个key时,才会判断该key是否已过期,过期则清除。该策略可以最大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
- 定期过期:每隔一段时间,对一些key进行检查,删除里面过期的key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以使得CPU和内存资源达到最优的平衡效果。
Redis中同时使用了惰性过期和定期过期两种过期策略。通过配合使用这两种过期键的删除策略,服务器可以很好地在合理使用CPU时间和避免浪费内存空间之间取得平衡。
内存淘汰策略
@$Redis的内存淘汰策略有哪些
Redis的内存淘汰策略是指在Redis服务器用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。
全局的键空间选择性移除
- allkeys-lru(常用):当内存不足以容纳新写入数据时,在全局键空间中,移除最近最少使用的key。
- allkeys-random:当内存不足以容纳新写入数据时,在全局键空间中,随机移除某个key。
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。
设置过期时间的键空间选择性移除
- volatile-lru(常用):当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。
- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
注意
Redis的内存淘汰策略的选取并不会影响过期的key的处理。内存淘汰策略用于处理内存不足时的需要申请额外空间的数据;过期策略用于处理过期的缓存数据。
线程模型
@$Redis线程模型
Redis基于Reactor模型开发了网络事件处理器,这个处理器被称为文件事件处理器(file event handler)。它的组成结构为4部分:多个套接字、IO多路复用程序、文件事件分派器、事件处理器。因为文件事件分派器队列的消费是单线程的,所以Redis才叫单线程模型。

- 文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字, 并根据套接字目前执行的任务来为套接字关联对应的事件处理器。
- 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关闭(close)等操作时,与操作相对应的文件事件就会产生, 这时文件事件分派器就会分派套接字给对应的事件处理器来处理这些事件。
虽然文件事件处理器以单线程方式运行, 但通过使用 I/O 多路复用程序来监听多个套接字, 文件事件处理器既实现了高性能的网络通信模型, 又可以很好地与 redis 服务器中其他同样以单线程方式运行的模块进行对接, 这保持了 Redis 内部单线程设计的简单性。
事务
Redis事务
事务是逻辑上的一组操作,要么都执行,要么都不执行。Redis 事务不是严格意义上的事务,只是用于帮助用户在一个步骤中执行多个命令。单个 Redis 命令的执行是原子性的,但 Redis 没有在事务上增加任何维持原子性的机制,所以 Redis 事务的执行并不是原子性的。
Redis 事务可以理解为一个打包的批量执行脚本,redis 事务不保证原子性,且没有回滚,中间某条命令执行失败,前面已执行的命令不回滚,后续的指令继续执行。
Redis 事务可以一次执行多个命令, 并且带有以下三个重要的保证:
- 批量操作在发送 EXEC 命令前被放入队列缓存。
- 收到 EXEC 命令后进入事务执行,事务中任意命令执行失败,前面已执行的命令不回滚,后续的命令继续执行。
- 事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
在传统的关系式数据库中,常常用 ACID 性质来检验事务功能的安全性。Redis 事务保证了其中的一致性(C)和隔离性(I),但并不保证原子性(A)和持久性(D)。
redis为什么不支持回滚
- Redis 命令只会因为错误的语法而失败(并且这些问题不能在入队时发现),或是命令用在了错误类型的键上面:这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中。
- 因为不需要对回滚进行支持,所以 Redis 的内部可以保持简单且快速。
有种观点认为 Redis 处理事务的做法会产生 bug , 然而需要注意的是, 在通常情况下, 回滚并不能解决编程错误带来的问题。举个例子, 如果你本来想通过 INCR 命令将键的值加上 1 , 却不小心加上了 2 , 又或者对错误类型的键执行了 INCR , 回滚是没有办法处理这些情况的。
鉴于没有任何机制能避免程序员自己造成的错误, 并且这类错误通常不会在生产环境中出现, 所以 Redis 选择了更简单、更快速的无回滚方式来处理事务。
Redis事务的三个阶段
- 事务开始 MULTI
- 命令入队
- 事务执行 EXEC
Redis事务命令
| 序号 | 命令 | 描述 |
|---|---|---|
| 1 | WATCH | WATCH 命令是一个乐观锁,可以为 Redis 事务提供 check-and-set (CAS)行为。可以监控一个或多个键,一旦其中有一个键被修改(或删除),之后的事务就不会执行,监控一直持续到EXEC命令。 |
| 2 | UNWATCH | UNWATCH命令可以取消watch对所有key的监控。 |
| 3 | MULTI | MULTI命令用于开启一个事务,它总是返回OK。MULTI执行之后,客户端可以继续向服务器发送任意多条命令,这些命令不会立即被执行,而是被放到一个队列中,当EXEC命令被调用时,所有队列中的命令才会被执行。 |
| 4 | EXEC | EXEC:执行所有事务块内的命令。返回事务块内所有命令的返回值,按命令执行的先后顺序排列。当操作被打断时,返回空值 nil 。 |
| 5 | DISCARD | 通过调用DISCARD,客户端可以清空事务队列,并放弃执行事务, 并且客户端会从事务状态中退出。 |
集群方案
@$哨兵模式

哨兵的介绍
sentinel,中文名是哨兵。哨兵是 redis 集群机构中非常重要的一个组件,主要有以下功能:
- 集群监控:负责监控 redis master 和 slave 进程是否正常工作。
- 消息通知:如果某个 redis 实例有故障,那么哨兵负责发送消息作为报警通知给管理员。
- 故障转移:如果 master node 挂掉了,会自动转移到 slave node 上。
- 配置中心:如果故障转移发生了,通知 client 客户端新的 master 地址。
哨兵用于实现 redis 集群的高可用,本身也是分布式的,作为一个哨兵集群去运行,互相协同工作。
哨兵的核心知识
- 哨兵至少需要 3 个实例,来保证自己的健壮性。
- 哨兵 + redis 主从的部署架构,是不保证数据零丢失的,只能保证 redis 集群的高可用性。
- 对于哨兵 + redis 主从这种复杂的部署架构,尽量在测试环境和生产环境,都进行充足的测试和演练。
Redis 主从复制的原理
复制过程
复制的过程步骤如下:
- 从节点执行 slaveof 命令
- 从节点只是保存了 slaveof 命令中主节点的信息,并没有立即发起复制
- 从节点内部的定时任务发现有主节点的信息,开始使用 socket 连接主节点
- 连接建立成功后,发送 ping 命令,希望得到 pong 命令响应,否则会进行重连
- 如果主节点设置了权限,那么就需要进行权限验证;如果验证失败,复制终止。
- 权限验证通过后,进行数据同步,这是耗时最长的操作,主节点将把所有的数据全部发送给从节点。
- 当主节点把当前的数据同步给从节点后,便完成了复制的建立流程。接下来,主节点就会持续的把写命令发送给从节点,保证主从数据一致性。

生产环境中的 redis 是怎么部署的?
redis cluster,10 台机器,5 台机器部署了 redis 主实例,另外 5 台机器部署了 redis 的从实例,每个主实例挂了一个从实例,5 个节点对外提供读写服务,每个节点的读写高峰qps可以达到每秒 5 万,5 台机器最多是 25 万读写请求/s。
机器是什么配置?32G 内存+ 8 核 CPU + 1T 磁盘,但是分配给 redis 进程的是10g内存,一般线上生产环境,redis 的内存尽量不要超过 10g,超过 10g 可能会有问题。
5 台机器对外提供读写,一共有 50g 内存。
因为每个主实例都挂了一个从实例,所以是高可用的,任何一个主实例宕机,都会自动故障迁移,redis 从实例会自动变成主实例继续提供读写服务。
你往内存里写的是什么数据?每条数据的大小是多少?商品数据,每条数据是 10kb。100 条数据是 1mb,10 万条数据是 1g。常驻内存的是 200 万条商品数据,占用内存是 20g,仅仅不到总内存的 50%。目前高峰期每秒就是 3500 左右的请求量。
其实大型的公司,会有基础架构的 team 负责缓存集群的运维。
@$Redis实现分布式锁
Redis为单进程单线程模式,采用队列模式将并发访问变成串行访问,且多客户端对Redis的连接并不存在竞争关系,Redis中可以使用SETNX命令实现分布式锁。
SETNX 是『SET if Not eXists』(如果不存在,则 SET)的简写。
当且仅当 key 不存在,将 key 的值设为 value。若给定的 key 已经存在,则 SETNX 不做任何动作
返回值:设置成功,返回 1 。设置失败,返回 0 。

使用SETNX完成同步锁的流程及事项如下:
-
使用SETNX命令获取锁,若返回0(key已存在,锁已存在)则获取失败,若返回1则获取成功
-
为了防止获取锁后程序出现异常,导致其他线程/进程调用SETNX命令总是返回0而进入死锁状态,需要为该key设置一个合理的过期时间
-
释放锁,使用DEL命令将锁数据删除
缓存异常
@$缓存雪崩
缓存雪崩是指缓存同一时间大面积的失效,导致所有的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案
- 缓存数据过期时间随机:过期时间设置随机,防止同一时间大量数据过期现象发生。
- 热点数据不设置过期时间,主动刷新缓存:缓存设置成永不过期,在更新或删除 DB 中的数据时,也主动地把缓存中的数据更新或删除掉。
- 检查更新:缓存依然保持设置过期时间,每次 get 缓存的时候,都和数据的过期时间和当前时间进行一下对比,当间隔时间小于一个阈值的时候,主动更新缓存。
- 使用锁:通过互斥锁或者队列,控制读数据库和写缓存的线程数量。
缓存穿透
缓存穿透是指缓存和数据库中都没有的数据,导致所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案
- 接口层增加逻辑校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
- 采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力
缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,读缓存没读到数据,造成数据库短时间内承受大量请求而崩掉。和缓存雪崩不同的是,缓存击穿指并发查同一条数据,缓存雪崩是缓存同一时间大面积失效。
解决方案
- 设置热点数据永远不过期。
- 加互斥锁
其他问题
Redis与Memcached的区别
两者都是非关系型内存键值数据库,现在公司一般都是用 Redis 来实现缓存,而且 Redis 自身也越来越强大了!
redis与memcached区别总结
| redis | memcached | |
|---|---|---|
| 值类型 | 支持字符串,列表,散列表,集合,有序集合 | 只支持字符串 |
| 线程模型和性能 | 单线程的多路IO复用模型,存取数据快 | 多线程的非阻塞IO模型,存取数据比redis慢 |
| 持久化 | 支持 | 不支持 |
| 集群模式 | 原生支持 | 没有原生支持 |
| 适用场景 | 复杂数据结构,有持久化,高可用需求,value存储内容较大的场景 | 纯key-value,数据量非常大,并发量非常大的场景 |
@$如何保证缓存与数据库双写时的数据一致性?
缓存与数据库双存储双写,就一定会有数据一致性的问题
数据强一致性方案:读请求和写请求串行化,串到一个内存队列里去,这样就可以保证一定不会出现不一致的情况,串行化之后,就会导致系统的吞吐量会大幅度的降低
还有一种方式就是可能会暂时产生数据不一致的情况,但是发生的几率特别小,就是先更新数据库,然后再删除缓存。
| 问题场景 | 描述 | 解决 |
|---|---|---|
| 先写缓存,再写数据库,缓存写成功,数据库写失败 | 缓存写成功,但写数据库失败或者响应延迟,则下次读取(并发读)缓存时,就出现脏读 | 这个写缓存的方式,本身就是错误的,需要改为先写数据库,把旧缓存置为失效;读取数据的时候,如果缓存不存在,则读取数据库再写缓存 |
| 先写数据库,再写缓存,数据库写成功,缓存写失败 | 写数据库成功,但写缓存失败,则下次读取(并发读)缓存时,则读不到数据 | 缓存使用时,假如读缓存失败,先读数据库,再回写缓存的方式实现 |
| 需要缓存异步刷新 | 指数据库操作和写缓存不在一个操作步骤中,比如在分布式场景下,无法做到同时写缓存或需要异步刷新(补救措施)时候 | 确定哪些数据适合此类场景,根据经验值确定合理的数据不一致时间,用户数据刷新的时间间隔 |
十四、Redis代理配置使用
14.1Twemproy
14.2Predixy
github地址:https://github.com/joyieldInc/predixy/blob/master/README_CN.md
安装:直接下载编译好的release包解压使用。
所有的请求都落到数据库上,造成数据库短时间内承受大量请求而崩掉。
解决方案
- 接口层增加逻辑校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击
- 采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的 bitmap 中,一个一定不存在的数据会被这个 bitmap 拦截掉,从而避免了对底层存储系统的查询压力
缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,读缓存没读到数据,造成数据库短时间内承受大量请求而崩掉。和缓存雪崩不同的是,缓存击穿指并发查同一条数据,缓存雪崩是缓存同一时间大面积失效。
解决方案
- 设置热点数据永远不过期。
- 加互斥锁
其他问题
Redis与Memcached的区别
两者都是非关系型内存键值数据库,现在公司一般都是用 Redis 来实现缓存,而且 Redis 自身也越来越强大了!
redis与memcached区别总结
| redis | memcached | |
|---|---|---|
| 值类型 | 支持字符串,列表,散列表,集合,有序集合 | 只支持字符串 |
| 线程模型和性能 | 单线程的多路IO复用模型,存取数据快 | 多线程的非阻塞IO模型,存取数据比redis慢 |
| 持久化 | 支持 | 不支持 |
| 集群模式 | 原生支持 | 没有原生支持 |
| 适用场景 | 复杂数据结构,有持久化,高可用需求,value存储内容较大的场景 | 纯key-value,数据量非常大,并发量非常大的场景 |
@$如何保证缓存与数据库双写时的数据一致性?
缓存与数据库双存储双写,就一定会有数据一致性的问题
数据强一致性方案:读请求和写请求串行化,串到一个内存队列里去,这样就可以保证一定不会出现不一致的情况,串行化之后,就会导致系统的吞吐量会大幅度的降低
还有一种方式就是可能会暂时产生数据不一致的情况,但是发生的几率特别小,就是先更新数据库,然后再删除缓存。
| 问题场景 | 描述 | 解决 |
|---|---|---|
| 先写缓存,再写数据库,缓存写成功,数据库写失败 | 缓存写成功,但写数据库失败或者响应延迟,则下次读取(并发读)缓存时,就出现脏读 | 这个写缓存的方式,本身就是错误的,需要改为先写数据库,把旧缓存置为失效;读取数据的时候,如果缓存不存在,则读取数据库再写缓存 |
| 先写数据库,再写缓存,数据库写成功,缓存写失败 | 写数据库成功,但写缓存失败,则下次读取(并发读)缓存时,则读不到数据 | 缓存使用时,假如读缓存失败,先读数据库,再回写缓存的方式实现 |
| 需要缓存异步刷新 | 指数据库操作和写缓存不在一个操作步骤中,比如在分布式场景下,无法做到同时写缓存或需要异步刷新(补救措施)时候 | 确定哪些数据适合此类场景,根据经验值确定合理的数据不一致时间,用户数据刷新的时间间隔 |