机器学习基础知识(1)
什么是机器学习
机器学习是一种通过输入大量数据来构建一种模型(网络),这个训练好的模型将会被用来预测或执行某些操作,这个训练的过程和方法就是机器学习。
我们也可以理解为构建一个“函数”,使得这个函数面对我们的输入数据能够返回出某些结果,而寻找或者说构建这个函数的过程就是机器学习。
机器学习的基本知识
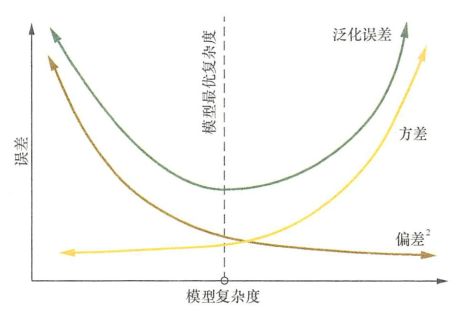
偏差:偏差度量了模型的期望预测与真实结果的偏离程度, 即刻画了学习算法本身的拟合能力。偏差则表现为在特定分布上的适应能力,偏差越大越偏离真实值。
方差:方差度量了同样大小的训练集的变动所导致的学习性能的变化, 即刻画了数据扰动所造成的影响。方差越大,说明数据分布越分散。
噪声:噪声表达了在当前任务上任何模型所能达到的泛化误差的下界, 即刻画了学习问题本身的难度 。
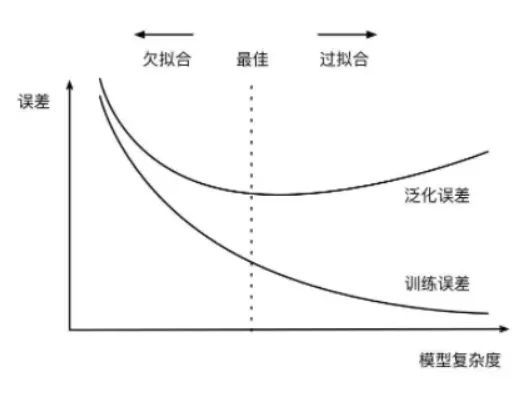
过拟合:指的是在训练数据集上表现良好,而在未知数据上表现差。
欠拟合:指的是模型没有很好地学习到数据特征,不能够很好地拟合数据,在训练数据和未知数据上表现都很差
为什么参数越小代表模型越简单
越复杂的模型,越是会尝试对所有的样本进行拟合,甚至包括一些异常样本点,这就容易造成在较小的区间里预测值产生较大的波动,这种较大的波动也反映了在这个区间里的导数很大,而只有较大的参数值才能产生较大的导数。因此复杂的模型,其参数值会比较大。因此参数越少代表模型越简单。
机器学习的方法分类
有监督学习
有监督学习就是通过标注好的数据集来进行训练,学习一个从输入变量X到输入变量Y的函数映射
训练数据通常是(n×x,y)的形式,其中n代表训练样本的大小,x和y分别是变量X和Y的样本值
有监督学习可大体分为两大类问题:分类,回归
分类:预测某一样本所属的类别。
回归:预测某一样本的所对应的实数输出。
分类任务是指在给定一组数据集合时,我们需要预测数据所属的类别或标签。例如,我们可以输入许多水果的图片和相应的标签,如苹果、香蕉或梨子,然后训练一个分类器,以便它能够在新的水果图片中识别出它所属的类别。 通常情况下,分类任务的输出是离散值,如标签。
回归任务则是指在给定一组数据集合时,我们需要预测数据的数值。例如,我们可以输入一组房屋的特征,如面积、卧室数量、卫生间数量、地理位置等,然后训练一个回归器,以便它能够预测房价。通常情况下,回归任务的输出是连续值,如价格。
分类问题
1.决策树

决策树显然是一种树形结构,可以认为是if-then结构的集合,这种结构具有良好的可读性,缺点是过拟合。
训练时,利用训练数据,根据损失函数最小化的原则建立决策树模型。
预测时,直接利用模型进行分类或回归。
决策树训练通常包括3个步骤:特征选择、决策树生成以及修剪。
特征选择
在构建决策树的时候,最重要的一步是要决定需要选取的特征。通常来说,选取的特征要与最终的分类结果有一定的相关性,如果选取该特征后与随机分类的结果没有太大分布,这样的特征是无效的。
决策树生成CART(生成算法有很多如ID3,C4.5)
CART算法由Breiman等人在1984年提出,是一种构建决策树的方法。CART算法所生成的决策树都是二叉树。其算法主要分为生成树和剪枝两个过程,生成的时候树要尽量大而深,然后再通过剪枝在大树上生成一棵表现最好的子树。
修剪
由于在训练过程中树的深度过大,产生了过拟合。为了避免这种情况发生,在树生成之后,要对其进行剪枝处理,对于删除分类过细的叶节点,使其退化回其父节点,有望可以改善其过拟合的程度。
通常来讲,我们会先定义好损失函数,然后根据各个节点计算所得熵来决定剪枝。
![]()
当某个叶节点t中的各类样本分布越均匀,证明该节点的分类效果越差,得到的熵也就越大,因此该项可以表示决策树的分类误差。式中第二项是描述决策树的复杂度的,当决策树越复杂,叶节点也就越多,该项也就越大。
2.朴素贝叶斯(贝叶斯是基于贝叶斯概率理论的,请提前了解相关概率论知识)
利用Bayes定理来预测一个未知类别的样本属于某个类别的可能性
区别于knn,决策树,神经网络等很多其他方法的直接学习Y与X之间额F(x)关系,贝叶斯采用的是生成方法。
优点:在数据较少的情况下仍然有效,可以处理多类别问题。
缺点:对于输入数据的准备方式较为敏感。
适用数据类型:标称型数据
先验概率P(X): 先验概率是指根据以往经验和分析得到的概率。
后验概率P(Y|X): 事情已发生,要求这件事情发生的原因是由某个因素引起的可能性的大小,后验分布P(Y|X)表示事件X已经发生的前提下,事件Y发生的概率,称事件X发生下事件Y的条件概率。
后验概率P(X|Y): 在已知Y发生后X的条件概率,也由于知道Y的取值而被称为X的后验概率。
朴素: 朴素贝叶斯算法是假设各个特征之间相互独立,也是朴素这词的意思,那么贝叶斯公式中的P(X|Y)可写成:
![]()
例:

图中给出了weather和player(列省略)对应的play状态,
比如第一个选手在sunny day的时候会选择no play
请根据已有信息,推断天气味sunny的时候某一未知选手的paly状态
显然如下
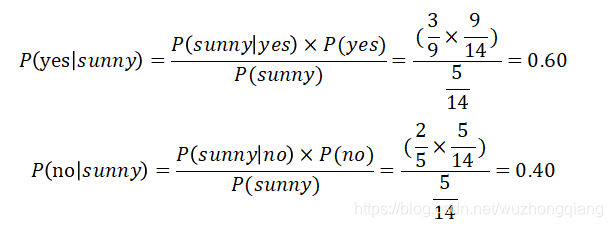
朴素贝叶斯公式:
![]()
朴素贝叶斯分类器: 朴素贝叶斯分类器(Naïve Bayes Classifier)采用了“属性条件独立性假设” ,即每个属性独立地对分类结果发生影响。为方便公式标记,不妨记P(C=c|X=x)为P(c|x),基于属性条件独立性假设,贝叶斯公式可重写为:
![]()
朴素贝叶斯分类器的训练器的训练过程就是基于训练集D估计类先验概率P(C),并为每个属性估计条件概率 P(xi|c),令Dc表示训练集D中第c类样本组合的集合,则类先验概率:
![]()
3.K-近邻(kNN)
我的妈,终于有个简单算法。
KNN的原理就是当预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别
对于k临近只有几个需要注意的地方
1.k临近的k值选择
k值的选择其实很重要,对于样本较小的数据集你选择一个较大的k值显然不合适,比如样本一共50个元素你选择了的k里面包含45个,这不就是“欺负”弱势群体吗。
如图所示k值逐渐增大时knn的判断错误率不断上升。

2.kNN的非参、惰性特征
非参:除了变动的k值外不需要任何参数,不会对输入做出假设,模型的判断完全由数据决定
惰性:KNN不许要训练,不像目前使用的大参数网络。
4.人工神经网络
神经网络目前主要有:CNN,RNN,FNN,BPNN,DBN
这些网络里相信初学者一定最先接触的BPNN(至少科班通常是这样开的课程,给你整几个神经元分析分析),不过目前的深度神经网络都比当初学的要复杂的太多,这里不细展开将神经网络,只列举目前在nlp,cv这些方向的主流模型和神经网络基本种类。
卷积神经网络(Convolutional Neural Network,
CNN):主要用于处理具有网格结构的数据,如图像、音频等,通过卷积和池化等操作提取输入数据中的特征。
循环神经网络(Recurrent Neural Network,
RNN):可以处理时序数据的神经网络,每个时间步都会接收上一个时间步输出的信息,从而实现对历史信息的记忆。
反向传播神经网络(Backpropagation Neural Network,
BPNN):是前馈神经网络的一种变种,可以利用反向传播算法进行训练,使得网络能够逼近复杂的非线性函数。
前馈神经网络(Feedforward Neural Network, FNN):最为基础和常见的人工神经网络,由输入层、隐藏层和输出层组成,每一层都由多个神经元构成。
深度信念网络(Deep Belief Network, DBN):一种由多个受限玻尔兹曼机组成的深度神经网络,可以用于特征提取和分类等任务。
卷积神经网络列举
由于项目相关,我主要讲一下CV方向目前最为常用的几个,然后再加上一个可能成为黑马的transformer系列(这个方向现在就是主打一个炼丹+魔改,那天你碰出一个很牛逼的你就牛逼了)
目前计算机视觉领域最常用的模型有:
Faster R-CNN: 基于区域提取的神经网络模型,可以在目标检测的任务上取得很好的效果。
YOLO(You Only Look Once): 一种基于单阶段检测器的目标检测模型,速度较快,适合实时应用场景。
SSD(Single Shot MultiBox Detector): 一种基于单阶段检测器的目标检测模型,具有较快的检测速度和较高的精度。
Mask R-CNN: 在Faster R-CNN的基础上,增加了实例分割的能力,可以同时获取物体的位置和分割掩模。
单阶段和二阶段目标检测
而这里面有分为二阶段检测和单阶段检测,二阶段检测的参数量大速率慢,但是准确性极高,使用于人脸识别,医学图像等领域,而单阶段目标检测适用于无人机目标识别,自动驾驶等需要快速反应的场景。
单阶段: 以YOLO为例(目前最新到YOLOv8),这种主要分为三个大段的模型,在保证了也具有良好的检测准确率(这个我之后和Fast R-CNN那些详细总结一下)
二阶段
R-CNN系列模型:包括R-CNN、Fast R-CNN、Faster R-CNN,是基于区域提取的神经网络模型,先通过区域选择网络对候选区域进行筛选,再通过分类网络和回归网络对筛选后的区域进行分类和位置回归,最终得到检测结果。
Mask R-CNN:在Faster R-CNN的基础上增加了对实例分割的支持,不仅能得到物体的位置和类别,还可以获取物体的分割掩模。
Transformer: transformer属于深度神经网络。不同于传统的CNN,它通过多层非线性变换来构建深层次的模型,以学习输入序列中的信息表示。
原本Transformer为基础的模型应用主要在本文领域,对于长程的处理由于一般的CNN模型,但是目前也有许多Transformer变型之后的模型开始在cv方向有了良好的表现,如:DETR,ViT
参考博文
机器学习知识点全面总结
机器学习的分类、回归、聚类问题
决策树
回归问题有时间总结一下,明天我开始YOLO和Fast R-cnn,DeepSort的原理总结,今天还有数据结构没复习。