FPGA实现NIC 25G UDP协议栈网卡,纯verilog代码编写,提供工程源码和技术支持
目录
- 1、前言
- 2、我这里已有的UDP方案
- 3、本25G/100G网卡基本性能简介
- 4、详细设计方案
-
- 接口概述
-
- PCIe HIP
- DMA IF
- AXI总线接口
- 时钟同步处理
- TXQ和RXQ队列
- TXCQ和RXCQ队列完成
- EQ
- MAC + PHY
- 流水线队列管理
- 发送调度程序
- 端口和接口
- 数据路径以及发送和接收引擎
- 分段内存接口
- 5、vivado工程详解
- 6、上板调试验证
- 7、福利:工程代码的获取
1、前言
网络接口控制器(NIC)是计算机与网络进行交互的网关。NIC构成了软件协议栈和网络之间的桥梁,该桥梁的功能定义了网络接口。网络接口的功能以及这些功能的实现都在迅速发展。这些变化是由提高线速和支持高性能分布式计算和虚拟化的NIC功能的双重要求所驱动的。不断提高的线速导致许多NIC功能必须在硬件而非软件中实现。同时,需要新的网络功能,例如对多个队列的精确传输控制,以实现高级协议和网络体系结构。
为了以实际的线速满足对新的网络协议和体系结构的开放式开发平台的需求,我们正在开发一种基于FPGA的开源高性能NIC原型平台。本25G/100G网卡平台能够以25G/100GGbps的速度运行,连同其驱动程序一起,可以在整个网络协议栈中使用。该设计既便携式又紧凑,支持许多不同的设备,同时即使在较小的设备上也留有足够的资源用于进一步的自定义。本25G/100G网卡的模块化设计和可扩展性允许共同优化的硬件/软件解决方案在现实的环境中开发和测试高级网络应用程序。
基于FPGA的NIC结合了基于ASIC的NIC和软件NIC的功能:它们能够以线速运行并提供低延迟和精确定时,同时新功能的开发周期相对较短。市面上也有开发了高性能、基于FPGA的专有NIC;例如,阿里巴巴开发了一个完全定制的基于FPGA的RDMA-onlyNIC,他们用它来运行精密拥塞控制协议(HPCC)的硬件实现。商业产品也存在,包括Exablaze和Netcope提供的产品。不幸的是,类似于基于ASIC的NIC,可商用的基于FPGA的NIC往往具有无法修改的基本“黑匣子”功能。基本NIC功能的封闭性严重限制了它们在开发新的网络应用程序时的效用和灵活性。
商业上可用的高性能DMA组件,例如Xilinx XDMA内核和QDMA内核,以及Atomic Rules ArkvilleDPDK加速内核都没有提供完全可配置的硬件来控制传输数据流。Xilinx XDMA内核是为计算卸载应用程序而设计的,因此提供了非常有限的排队功能,并且没有简单的方法来控制传输调度。Xilinx QDMA内核和Atomic Rules ArkvilleDPDK加速内核通过支持少量队列并提供DPDK驱动程序而面向网络应用程序;但是支持的队列数量很少(XDMA内核为2K队列,而Arkville内核为128个队列)而且两个内核都不提供用于精确控制数据包传输的简单方法。基于FPGA的分组处理解决方案包括实现网络应用程序卸载的Catapult和实现FPGA上可重构匹配引擎的FlowBlaze。但是,这些平台将标准的NIC功能留给了单独的基于ASIC的NIC,并且完全作为“线下突击”进行操作,没有提供对NIC调度程序或队列的明确控制。其他项目使用软件实现或部分硬件实现。Shoal描述了一种网络架构,该网络架构使用自定义NIC和快速的第1层电交叉点交换机执行小规模路由。Shoal是用硬件构建的,但仅在没有主机连接的情况下通过综合流量进行评估。SENIC描述了基于NIC的可扩展速率限制。单独评估了调度程序的硬件实现,但是系统级评估是在具有自定义排队规则(qdisc)模块的软件中进行的。PIEO描述了一种灵活的NIC调度程序,它是在硬件中单独进行评估的。NDP是用于数据中心应用程序的拉模式传输协议。NDP已通过DPDK软件NIC和基于FPGA的交换机进行了评估。Loom描述了一种有效的NIC设计,可以使用BESS在软件中对其进行评估。
本25G/100G网卡的开发与所有这些项目都不同,因为它是完全可以看到verilog源码的的,并且可以以实际的线速与标准主机网络协议栈一起运行。它提供了数千个传输队列,并带有可扩展的传输调度程序,以实现对流的细粒度控制。最后我们建立了一个强大而灵活的开源平台,用于开发结合了硬件和软件功能的网络应用程序。
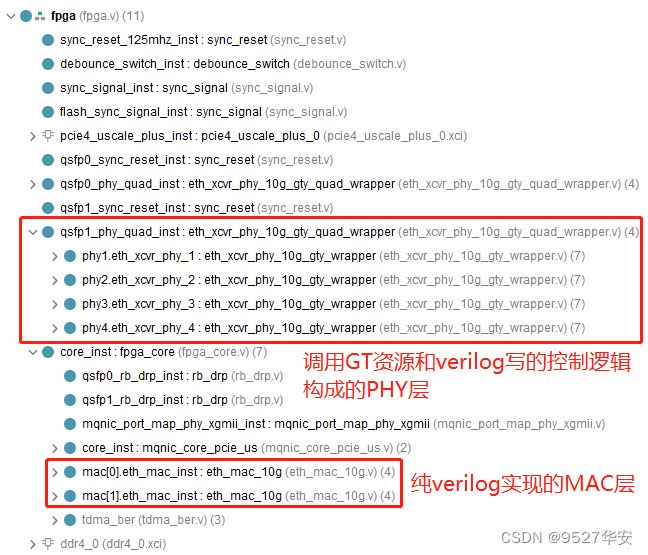
本设计是一个25G速率的网卡,Xilinx Kintex UltraScale+ XCKU3P调用UltraScale+ Integrated Block (PCIE4) for PCI Express IP核实现FPGA网卡与电脑主机的数据交互,PCIE配有纯verilog编写的DMA控制器实现PCIE数据的搬运工作;调用UltraScale FPGAs Transceivers Wizard GTY资源实现FPGA网卡与其他网卡的数据交互,GTY配置为XGMII接口,GTY配有用纯verilog代码编写的XGMII数据收发接口,实现GTY与UDP协议栈的数据交互;UDP协议栈也由纯verilog代码编写,配有XGMII数据交互接口;FPGA网卡通过SFP光口的光纤与其他网卡或者交换机连接,自身通过PCIE与电脑主机连接,实现了高速网卡的功能,其架构如下:

UDP数据通过SFP光口实现数据收发;UDP协议栈与MAC的交互接口为XGMII,速率为最高可以跑到100G,UDP协议栈的用户接口为XGMII,使得用户无需关心复杂的UDP协议而只需关心简单的用户接口时序即可操作UDP收发;
本设计经过反复大量测试稳定可靠,可在项目中直接移植使用,工程代码可综合编译上板调试,可直接项目移植,适用于在校学生、研究生项目开发,也适用于在职工程师做项目开发,可应用于医疗、军工等行业的数字通信领域;
提供完整的、跑通的工程源码和技术支持;
工程源码和技术支持的获取方式放在了文章末尾,请耐心看到最后;
2、我这里已有的UDP方案
目前我这里有大量UDP协议的工程源码,包括UDP数据回环,视频传输,AD采集传输等,也有TCP协议的工程,对网络通信有需求的兄弟可以去看看:直接点击前往
3、本25G/100G网卡基本性能简介
本25G/100G网卡是一个基于Xilinx高端系列FPGA为平台的,用于高达100Gbps及更高的网络接口开发平台;平台包括一些用于实现实时,高线速操作的核心功能,包括:高性能数据路径,10G/ 25G / 100G以太网MAC,PCIExpress第3代,自定义PCIeDMA引擎以及本机高精确的IEEE 1588 PTP时间戳。一个关键功能是可扩展队列管理,它可以支持超过10,000个队列以及可扩展的传输调度程序,从而可以对包传输进行细粒度的硬件控制。结合多个网络接口,每个接口多个端口以及每个端口事件驱动的传输调度,这些功能可实现高级网络接口,体系结构和协议的开发。这些硬件功能的软件接口是Linux网络协议栈的高性能驱动程序。该平台还支持分散/聚集DMA,校验和卸载,接收流散列和接收端缩放。一个全面的,基于Python的开放源代码仿真框架促进了开发和调试,该框架包括整个系统,从驱动程序和PCIExpress接口的仿真模型到以太网接口。通过实现微秒级时分多址(TDMA)硬件调度程序,以100Gbps的线速执行TDMA调度,而没有CPU开销,证明了该平台的强大功能和灵活性。
本25G/100G网卡具有几种独特的体系结构特点。首先,将硬件队列状态有效地存储在FPGA块RAM中,从而支持数千个可单独控制的队列。这些队列与接口相关联,每个接口可以具有多个端口,每个端口都有自己的独立传输调度程序。这样就可以对数据包传输进行极其精细的控制。调度器模块的设计是为了修改或交换的。完全可以实现不同的传输调度方案,包括实验调度器。再加上PTP时间同步,这样可以实现基于时间的调度,包括高精度的TDMA。
本25G/100G网卡的设计是模块化且高度参数化的。可以在综合时通过Verilog参数设置许多配置和结构选项,包括接口和端口计数,队列计数,内存大小,调度程序类型等。这些设计参数公开在驱动程序读取以确定NIC配置的配置寄存器中,使同一驱动程序无需修改即可支持许多不同的板卡和配置。
当前的设计支持Xilinx Ultrascale PCIe硬IP内核接口的PCIe DMA组件。目前尚未实现对其他FPGA中常用的PCIe TLP接口的支持,这是未来的工作。这种支持应该可以在更多的FPGA上进行操作。
4、详细设计方案
详细设计方案如下:
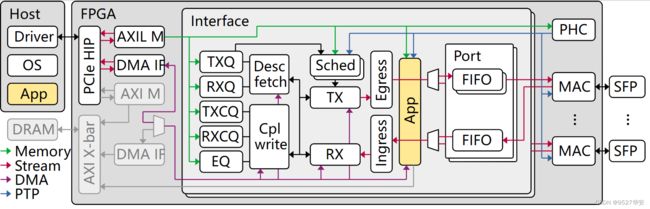
从较高的层次来看,NIC由3个主要的嵌套模块组成。顶层模块主要包含支持和接口组件。这些组件包括PCI Express硬IP内核和DMA接口,PTP硬件时钟以及包括MAC,PHY和相关串行器的以太网接口组件。顶层模块还包括一个或多个接口模块实例。每个接口模块都对应于操作系统级别的网络接口(例如eth0)。每个接口模块都包含队列管理逻辑以及描述符和完成处理逻辑。队列管理逻辑维护所有NIC队列的队列状态:传输、传输完成、接收、接收完成和事件队列。每个接口模块还包含一个或多个端口模块实例。每个端口模块都提供一个到MAC的AXI流接口,并包含一个传输调度程序,传输和接收引擎,传输和接收数据路径以及一个暂存RAM,用于在DMA操作期间临时存储传入和传出的数据包。
对于每个端口,端口模块中的传输调度程序决定将哪些队列指定用于传输。传输调度程序为发送引擎生成命令,这些命令协调传输数据路径上的操作。调度程序模块是一个灵活的功能块,可以对其进行修改或替换,以支持任意调度,这些调度可以是事件驱动的。调度程序的默认实现是简单循环。与同一接口模块关联的所有端口共享同一组传输队列,并显示为操作系统的单个统一接口。通过仅更改传输调度程序设置,而不会影响网络协议栈的其余部分,这可以使流在端口之间迁移或在多个端口之间实现负载平衡。这种动态的,调度程序定义的队列到端口的映射是本25G/100G网卡的独特功能,可以使人们能够研究新的协议和网络体系结构,包括并行网络(例如P-FatTree和光交换网络,例如RotorNet和Opera。
接口概述
现在对框图中的模块解释如下:
PCIe HIP:PCIe硬IP内核;AXIL M:AXI lite Master;DMA IF:DMA接口;PTP HC:PTP硬件时钟;TXQ:传输队列管理器;TXCQ:传输完成队列管理器;RXQ:接收队列管理器;RXCQ:接收完成队列管理器;EQ:事件队列管理器;MAC + PHY:以太网媒体访问控制器(MAC)和物理接口层(PHY)。
PCIe HIP
PCIe硬IP内核:
PCIe hard IP core;这里调用的是UltraScale+ Integrated Block (PCIE4) for PCI Express IP核,实现FPGA网卡与电脑主机的数据交互;IP在代码中的位置和配置如下:
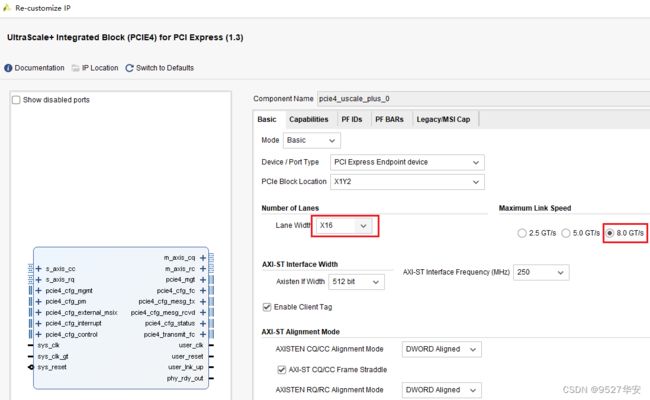
我的FPGA板卡性能很高,所以直接使用PCIE3.0 X16模式,速率直接干到单Line 8G;
DMA IF
DMA interface;纯verilog编写的DMA控制器实现PCIE数据的搬运工作;该模块在代码中的位置如下:
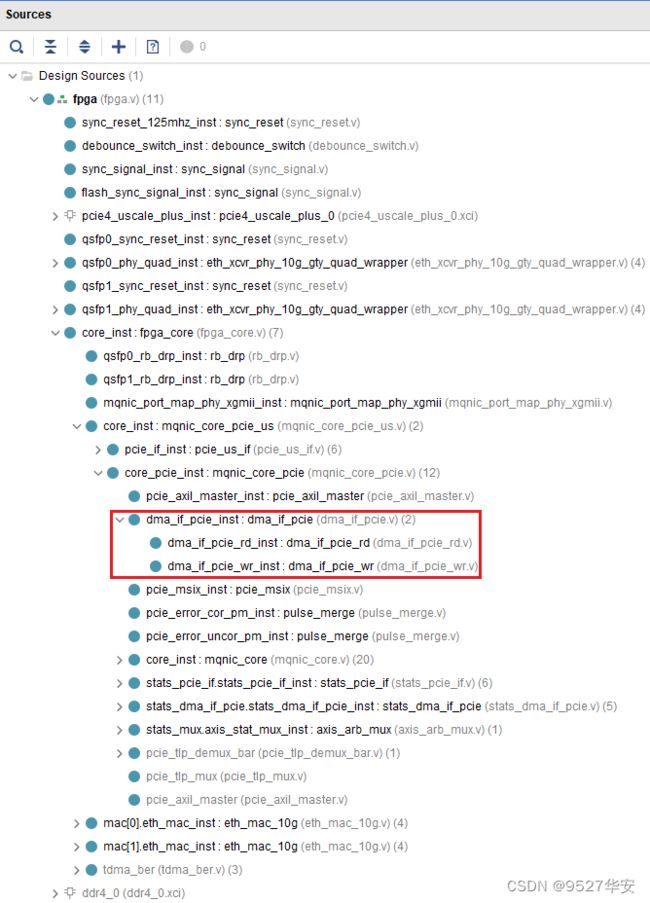
DMA IF主要由读写模块组成,完成数据搬运,很简单;
AXI总线接口
AXIL M:AXI lite master;即AXI-Lite总线主机,因为PCIE IP有AXI-Lite配置接口,这里属于挂载总线的需求;
AXI M:AXI master;即AXI-FULL总线主机,因为PCIE IP有AXI用户接口,这里属于挂载总线的需求;
时钟同步处理
PHC:PTP hardware clock;做时钟同步;主要平衡收发时钟的不同步;代码位置如下:

TXQ和RXQ队列
transmit queue manager;数据发送队列管理器;
receive queue manager; 数据接收队列管理器;
代码位置如下:

TXCQ和RXCQ队列完成
transmit completion queue manager;传输完成队列管理器;
receive completion queue manager;接收完成队列管理器;
代码位置如下:
EQ
event queue manager;事件队列管理器;
MAC + PHY
Ethernet media access controller (MAC) and physical interface layer (PHY);以太网媒体访问控制器(MAC)和物理接口层(PHY);代码位置如下:
在接收方向,传入的数据包通过流哈希模块确定目标接收队列,并为接收引擎生成命令,这些命令协调对接收数据路径的操作。由于同一接口模块中的所有端口共享同一组接收队列,因此不同端口上的传入流将合并到同一组队列中。还可以向NIC添加自定义模块,以在传入数据包通过PCIe总线之前对其进行预处理和过滤。
NIC上的组件与多个不同的接口互连,包括AXI lite,AXI流和用于DMA操作的自定义分段存储器接口,这将在后面讨论。AXI lite用于从驱动程序到NIC的控制路径。它用于初始化和配置NIC组件,并在发送和接收操作期间控制队列指针。AXI stream接口用于在NIC内传输打包数据,包括PCIe传输层数据包(TLP)和以太网帧。分段存储器接口用于将PCIe DMA接口连接到NIC数据路径以及描述符和完成处理逻辑。大部分NIC逻辑都运行在PCIe用户时钟域中,对于所有当前的设计变体,名义上为250 MHz。异步FIFO用于与MAC接口,这些MAC在串行器中运行,以适当地发送和接收时钟域–10G为156.25 MHz,25G为390.625 MHz,100G为322.266 MHz。后面各节描述了NIC中的几个关键功能块。
流水线队列管理
本25G/100G网卡NIC和驱动程序之间的数据包数据通信通过描述符和完成队列进行调解。描述符队列形成主机到NIC的通信通道,承载有关各个数据包在系统内存中存储位置的信息。完成队列构成了NIC到主机的通信通道,其中包含有关已完成的操作和关联的元数据的信息。描述符和完成队列被实现为驻留在DMA可访问的系统内存中的环形缓冲区,而NIC硬件则维护必要的队列状态信息。此状态信息包括指向环形缓冲区DMA地址的指针,环形缓冲区的大小,生产者和使用者指针以及对关联的完成队列的引用。每个队列所需的描述符状态适合128位。
本25G/100G网卡NIC的队列管理逻辑必须能够有效地存储和管理数千个队列的状态。这意味着队列状态必须完全存储在FPGA的Block RAM(BRAM)或Ultra RAM(URAM)中。由于需要128位RAM,并且URAM块为72x4096,因此存储4096个队列的状态仅需要2个URAM实例。利用 URAM 实例可以将队列管理逻辑扩展到每个接口至少处理 32768 个队列。
为了支持高吞吐量,本25G/100G网卡NIC必须能够并行处理多个描述符。因此,队列管理逻辑必须跟踪多个正在进行的操作,并在操作完成时向驱动程序报告更新的队列指针。跟踪进程中操作所需的状态比描述符状态小得多,因此可以将其存储在触发器和分布式RAM中。
本25G/100G网卡NIC设计使用两个队列管理器模块:queue_manager用于管理主机到NIC的描述符队列,而cpl_queue_manager用于管理NIC到主机的完成队列。除了指针处理,填充处理和门铃/事件生成方面的一些细微差别外,这些模块相似。由于相似之处,本节将仅讨论queue_manager模块的操作。
用于存储队列状态信息的BRAM或URAM阵列对于每个读取操作都需要几个延迟周期,因此queue_manager是使用流水线结构构建的,以促进多个并发操作。流水线支持四种不同的操作:寄存器读取,寄存器写入,出队/入队请求和出队/入队提交。通过AXI lite接口进行的寄存器访问操作使驱动程序可以初始化队列状态,并提供指向已分配的主机内存的指针,以及在正常操作期间访问生产者和使用者指针。
queue_manager模块和cpl_queue_manager模块在代码中的位置如下:

实际上,NIC中为了提高数据带宽利用率,几乎所有的模块都采用了流水线处理方式来促进高并发。本节以队列管理模块来介绍基于操作表和操作指针的流水线设计思路。
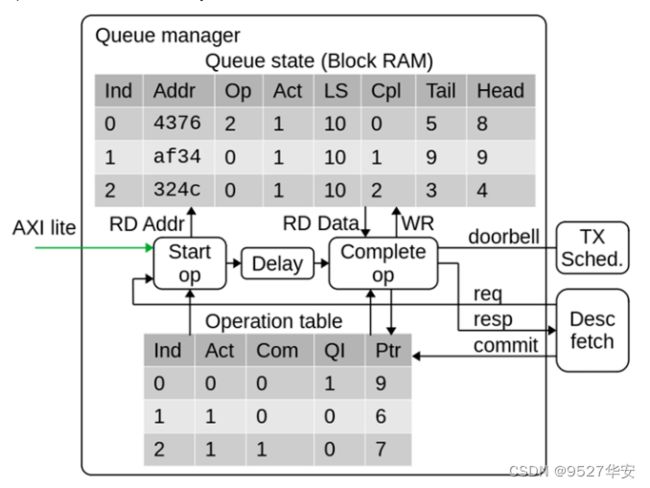
本25G/100G网卡NIC的队列管理逻辑必须能够有效地存储和管理数千个队列的状态。为了支持高吞吐量,NIC必须能够并行处理多个描述符。因此,队列管理逻辑必须跟踪多个正在进行的操作,并在操作完成时向驱动程序报告更新的队列指针。NIC的操作表项包含激活和提交标志、所属队列号、和影子指针,操作指针包括操作表开始指针和操作表提交指针,通过不同的指针对操作表不同字段的索引就可以跟踪当前进行中的不同操作项目进展到哪一个步骤,从而可以触发流水操作。更详细的来说,当队列管理接收到出队请求时将命令放置到Pipeline同时触发队列消息,当命令到达处理周期时,对应队列的信息已经被索引到,此时可以进行处理,如果出队被允许,必要的信息会被记录到操作表,处理逻辑只需要不断写入操作表并更新操作指针,可以认为出队逻辑在处理操作表的表头,操作被提交时会触发提交逻辑,提交逻辑处理操作表末并合理的释放操作表。需要注意的是,操作表只跟踪正在进行中的处理进程,因此不需要设置太大。它和队列管理的信息RAM构成了一个双向链表,即队列信息中需要存入为该队列服务的最新的操作表项索引,用于维护正确的影子指针。其原理框图如下:
发送调度程序
本25G/100G网卡NIC中使用的默认传输调度程序是在tx_scheduler_rr模块中实现的简单循环调度程序。调度器向发送引擎发送命令,从NIC传输队列中启动传输操作。循环调度器包含所有队列的基本队列状态,一个FIFO用于存储当前活动队列并执行循环调度,一个操作表用于跟踪进程中的传输操作。与队列管理逻辑类似,循环传输调度程序还将队列状态信息存储在FPGA上的BRAM或URAM中,以便可以扩展以支持大量队列。传输调度程序还使用处理流水线来隐藏内存访问延迟。tx_scheduler_rr模块在代码中的位置如下:

传输调度器模块具有四个主要接口:AXI lite寄存器接口和三个stream接口。AXI lite接口允许驱动程序更改调度程序参数并启用/禁用队列。当驱动程序将数据包排队发送时,第一个流接口从队列管理逻辑提供门铃事件。第二个流接口将由调度器生成的传输命令携带到发送引擎。每个命令都包含要发送的队列索引以及用于跟踪进程中操作的标签。最终的流接口将传输操作状态信息返回给调度程序。状态信息会通知调度程序已传输数据包的长度,或者是否由于队列为空或禁用而导致传输操作失败。
传输调度程序模块可以扩展或替换以实现任意调度算法。这使本25G/100G网卡可用作评估实验调度算法的平台,包括SENIC、Carousel、PIEO和Loom中提出的算法。还可能向发射调度器模块提供其他输入,包括来自接收路径的反馈,这些输入可用于实现新协议和拥塞控制技术,例如NDP和HPCC。将调度程序连接到PTP硬件时钟可用于支持TDMA,TDMA可用于实现RotorNet 、Opera和其他电路交换体系结构。
端口和接口
本25G/100G网卡的独特体系结构特征是端口和网络接口之间的分隔,因此多个端口可以与同一接口关联。当前的大多数NIC每个接口支持一个端口,如下图a所示:

当网络协议栈将数据包排队以便在网络接口上传输时,数据包将通过与该接口关联的网络端口注入网络。但是,在Corundum中,每个接口都可以关联多个端口,因此可以在出队时由硬件决定将数据包注入到网络中的哪个端口,如上图b所示。
与同一网络接口模块关联的所有端口共享同一组传输队列,并显示为操作系统的单个统一接口。这样,通过仅更改传输调度程序设置,就可以在端口之间迁移流或在多个端口之间实现负载平衡,而不会影响其余的网络协议栈。动态的,由调度程序定义的队列到端口的映射使人们能够研究新的协议和网络体系结构,包括诸如P-FatTree的并行网络以及诸如RotorNet和Opera的光交换网络。
数据路径以及发送和接收引擎
本25G/100G网卡在数据路径中同时使用了内存映射接口和流接口。AXI stream用于在端口DMA模块,以太网MAC,校验和与哈希计算模块之间传输以太网数据包数据。AXI stream还用于将PCIe硬IP内核连接到PCIe AXI lite主模块和PCIe DMA接口模块。定制的分段存储器接口用于将PCIe DMA接口模块,端口DMA模块以及描述符和完成处理逻辑连接到内部暂存器RAM。
AXI stream接口的宽度由所需带宽确定。除以太网MAC外,核心数据路径逻辑完全在250 MHz PCIe用户时钟域中运行。因此,到PCIe硬IP内核的AXI流接口必须与硬核接口宽度匹配-PCIe Gen 3 x8为256位,PCIe Gen 3 x16为512位。在以太网端,接口宽度与MAC接口宽度匹配,除非250 MHz时钟太慢而无法提供足够的带宽。对于10G以太网,MAC接口是156.25 MHz的64位,可以以相同的宽度连接到250 MHz的时钟域。对于25G以太网,MAC接口在390.625 MHz时为64位,因此必须转换为128位才能在250 MHz时提供足够的带宽。对于100G以太网,本25G/100G网卡在Ultrascale Plus FPGA上使用Xilinx 100G硬CMAC内核。MAC接口在322.266 MHz时为512位,它以512位在250 MHz时钟域上连接,因为它需要以大约195 MHz的频率运行才能提供100 Gbps。
本25G/100G网卡NIC数据路径的框图如下图所示:
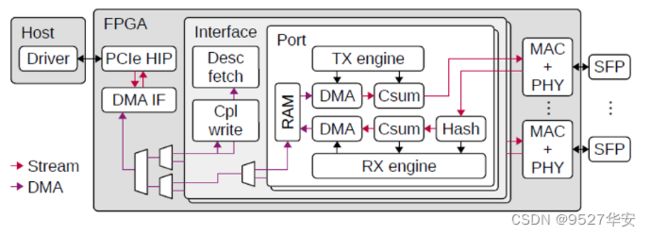
它是前面的第4章节详细设计方案图的简化版本。PCIe硬IP内核(PCIe HIP)将NIC连接到主机。两个AXI stream接口将PCIe DMA接口模块连接到PCIe硬IP内核。一个接口用于读写请求,一个接口用于读取数据。然后,PCIe DMA接口模块通过一组DMA接口多路复用器连接到描述符获取模块,完成写入模块,端口暂存RAM模块以及RX和TX引擎。在朝向DMA接口的方向上,多路复用器组合了来自多个源的DMA传输命令。在相反的方向上,它们路由传输状态响应。它们还管理分段存储器接口以进行读取和写入。顶层多路复用器将描述符流量与分组数据流量结合在一起,为描述符流量提供更高的优先级。接下来,一对多路复用器组合来自多个接口模块的流量。最后,每个接口模块内的一个附加多路复用器将来自多个端口实例的分组数据流量组合在一起。
发送引擎和接收引擎负责协调传输和接收数据包所需的操作。发送和接收引擎可以处理多个正在进行的数据包,以实现高吞吐量。如第4章节详细设计方案图所示,发送和接收引擎连接到发送和接收数据路径中的几个模块,包括端口DMA模块以及哈希和校验和卸载模块,以及描述符和完成处理逻辑以及时间戳接口模块、以太网MAC模块。
发送引擎负责协调数据包的传输操作。发送引擎处理来自传输调度程序的特定队列的传输请求。使用PCIe DMA引擎进行低级处理后,数据包将通过传输校验和模块,MAC和PHY。一旦发送了数据包,发送引擎将从MAC接收PTP时间戳,建立完成记录,并将其传递给完成写入模块。
与发送引擎类似,接收引擎负责协调数据包的接收操作。传入的数据包通过PHY和MAC。在包括哈希和时间戳的底层处理之后,接收引擎将向PCIe DMA引擎发出一个或多个写请求,以将数据包数据写出到主机内存中。写操作完成后,接收引擎将构建一个完成记录,并将其传递给完成写模块。
描述符读取和完成写入模块的操作类似于发送和接收引擎。这些模块处理来自发送和接收引擎的描述符/完成读/写请求,向队列管理器发出入队/出队请求,以获取主机内存中的队列元素地址,然后向PCIe DMA接口发出请求以传输数据。完成写入模块还负责通过将发送和接收完成队列排队在适当的事件队列中并写出事件记录来处理事件。
分段内存接口
对于PCIe上的高性能DMA,Corundum使用自定义分段存储器接口。该接口被分成最大128位的段,并且整体宽度是PCIe硬IP内核的AXI流接口宽度的两倍。例如,将PCIe Gen 3 x16与PCIe硬核中的512位AXI流接口一起使用的设计将使用1024位分段接口,该接口分成8个段,每个段128位。与使用单个AXI接口相比,该接口提供了改进的“阻抗匹配”,从而消除了DMA引擎中的对齐和互连逻辑中的仲裁,从而消除了背压,从而提高了PCIe链路利用率。具体地说,该接口保证DMA接口可以在每个时钟周期执行全宽度,未对齐的读取或写入。此外,使用简单的双端口RAM(专用于在单个方向上移动的流量)消除了读写路径之间的争用。
除了使用三个接口(而不是五个)之外,每个网段的运行方式均与AXI lite类似。一个通道提供写地址和数据,一个通道提供读地址,一个通道提供读数据。与AXI不同,不支持突发和重新排序,从而简化了接口逻辑。互连组件(多路复用器)负责维护操作的顺序,即使在访问多个RAM时也是如此。这些段通过单独的流控制连接和互连排序逻辑的单独实例彼此完全独立地运行。另外,操作是基于单独的选择信号而不是通过地址解码进行路由的。此功能消除了分配地址的需要,并允许使用可参数化的互连组件,这些组件以最少的配置适当地路由操作。
字节地址被映射到分段的接口地址上,最低的地址位确定段中的字节通道,接下来的位选择段,最高的位确定该段的字地址。例如,在一个1024位分段接口中,分成8个128位段,最低的4个地址位将确定段中的字节通道,接下来的3位将确定该段。其余位确定该段的地址总线。
5、vivado工程详解
开发板FPGA型号:Xilinx–xcvu9p-fsgd2104-2L-e;
开发环境:Vivado2022.2;
输入/输出:PCIE3.0/SFP光口
应用:25G网卡应用
工程代码架构如下:
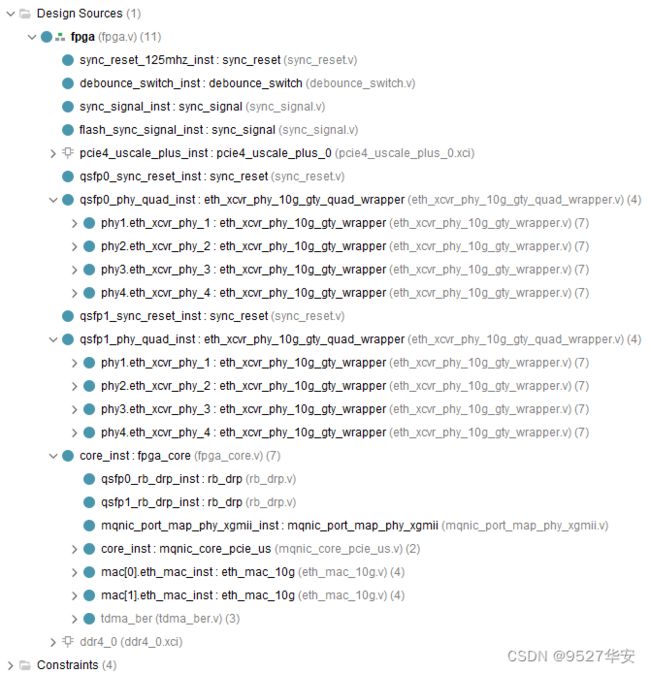
本工程用到的IP核有:MIG(DDR4)、GTY(UltraScale FPGAs Transceivers Wizard)、UltraScale+ Integrated Block (PCIE4) for PCI Express;IP核与逻辑设计之间的连接和作用如下:

GTY选择25G线速率,如下:
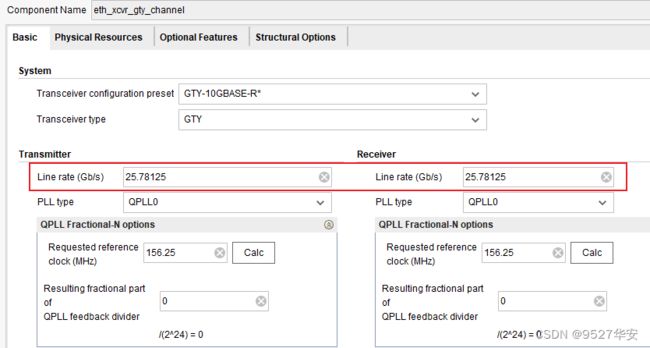
PCIE选择3.0标准的8GT/s和X16模式,如下:

综合编译完成后的FPGA资源消耗和功耗预估如下:

6、上板调试验证
上板调试需要在Linux系统下进行,目前已经测试过了,但速率跑不到25G,在20G左右,关于上板测试方法,我会后续更新,目前还没空写详细测试方法和步骤,敬请期待。。。对工程源码感兴趣的朋友可以先拿着代码去研究,代码比较复杂,想要看懂个七七八八估计也得半个月。。。
7、福利:工程代码的获取
福利:工程代码的获取
代码太大,无法邮箱发送,以某度网盘链接方式发送,
资料获取方式:私,或者文章末尾的V名片。
网盘资料如下: