flink Sql自定义kafka连接器
文章目录
- flink sql自定义kafka连接器
-
- 1. Overview
- 2. 自定义kafka连接器
-
- 2.2 maven相关依赖
- 2.3 自定义Factory
- 2.4 测试
flink sql自定义kafka连接器
在流式计算平台当中,为保证flink sql connector相关参数不暴露,官方提供的连接器不满足业务场景及产品本身的要求,通过可以改源码或者说自定义连接器解决。
1. Overview
源码架构
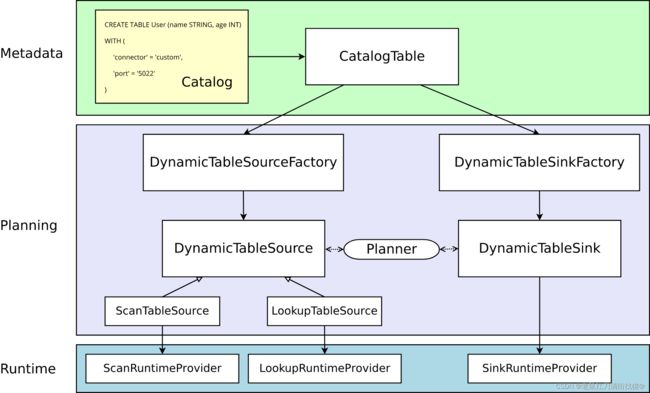
源码查找:FactoryUtil.discoverFactory 获取所有的连接器Factory,包括自定义工厂
获取工厂调用 factory.createDynamicTableSource(context);
2. 自定义kafka连接器
要求:添加kafka连接器参数connection-name,通过http请求到数据安全平台获取数据
2.2 maven相关依赖
根据自身的开放场景添加依赖
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.12.0</flink.version>
<scala.version>2.11</scala.version>
<flink.connector.jdbc.version>1.12.7</flink.connector.jdbc.version>
<mysql.connector.java.version>5.1.38</mysql.connector.java.version>
<flink.csv.version>1.12.7</flink.csv.version>
<google.guava.version>20.0</google.guava.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- 实现自定义的数据格式来做序列化,可以引入下面的依赖 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc_${scala.version}</artifactId>
<version>${flink.connector.jdbc.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_${scala.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.connector.java.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.csv.version}</version>
</dependency>
<!--lombok依赖,自动生成实体类中的get set 构造方法-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.10</version>
<optional>true</optional>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.28</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.5.2</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>${google.guava.version}</version>
</dependency>
</dependencies>
2.3 自定义Factory
- DynamicTableSourceFactory:所有自定的连接器工厂需要继承它
- resources/META-INF/services目录下要创建org.apache.flink.table.factories.Factory文件,将自定义的工厂全路径添加进去;注意org.apache.flink.table.factories.Factory必须是这个,否则classLoader加载不到
import com.alibaba.fastjson.JSONObject;
import lombok.SneakyThrows;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.annotation.Internal;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.configuration.ConfigOption;
import org.apache.flink.configuration.ConfigOptions;
import org.apache.flink.configuration.ReadableConfig;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase;
import org.apache.flink.streaming.connectors.kafka.table.KafkaDynamicTableFactory;
import org.apache.flink.streaming.connectors.kafka.table.KafkaOptions;
import org.apache.flink.table.api.ValidationException;
import org.apache.flink.table.catalog.CatalogTable;
import org.apache.flink.table.catalog.ObjectIdentifier;
import org.apache.flink.table.connector.format.DecodingFormat;
import org.apache.flink.table.connector.format.Format;
import org.apache.flink.table.connector.source.DynamicTableSource;
import org.apache.flink.table.data.RowData;
import org.apache.flink.table.factories.FactoryUtil;
import org.apache.flink.table.types.DataType;
import pupu.flink.constan.Constant;
import java.lang.reflect.Method;
import java.time.Duration;
import java.util.*;
import static org.apache.flink.streaming.connectors.kafka.table.KafkaOptions.*;
/**
* @describe
* @author
*/
@Internal
@Slf4j
public class MineKafkaDynamicTableFactory extends KafkaDynamicTableFactory {
// 反射,用于调用类中的的(static)private方法
private final Class<KafkaDynamicTableFactory> clazz = KafkaDynamicTableFactory.class;
// 映射sql中的connector
public static final String IDENTIFIER = "mine-kafka";
public static final ConfigOption<String> CONNECTION_NAME = ConfigOptions
.key("connection—name")
.stringType()
.noDefaultValue()
.withDescription("映射kafka集群的参数!");
@Override
public String factoryIdentifier() {
return IDENTIFIER;
}
/**
* @describe 必传参数
* @return none doc
*/
@Override
public Set<ConfigOption<?>> requiredOptions() {
final Set<ConfigOption<?>> options = new HashSet<>();
return options;
}
/**
* @describe 与源码流程不变,变化是对properties参数的处理与相关方法通过反射调用
* @param context none doc
* @return none doc
*/
public DynamicTableSource createDynamicTableSource(Context context) {
final FactoryUtil.TableFactoryHelper helper = FactoryUtil.createTableFactoryHelper(this, context);
final ReadableConfig tableOptions = helper.getOptions();
final Optional<DecodingFormat<DeserializationSchema<RowData>>> keyDecodingFormat =
invokeGetKeyDecodingFormat(helper);
final DecodingFormat<DeserializationSchema<RowData>> valueDecodingFormat =
invokeGetValueDecodingFormat(helper);
helper.validateExcept(PROPERTIES_PREFIX);
validateTableSourceOptions(tableOptions);
invokeValidatePKConstraints(context.getObjectIdentifier(), context.getCatalogTable(), valueDecodingFormat);
final StartupOptions startupOptions = getStartupOptions(tableOptions);
final Properties properties = getPupuKafkaProperties(context);
// add topic-partition discovery
properties.setProperty(FlinkKafkaConsumerBase.KEY_PARTITION_DISCOVERY_INTERVAL_MILLIS,
String.valueOf(tableOptions
.getOptional(SCAN_TOPIC_PARTITION_DISCOVERY)
.map(Duration::toMillis)
.orElse(FlinkKafkaConsumerBase.PARTITION_DISCOVERY_DISABLED)));
final DataType physicalDataType = context.getCatalogTable().getSchema().toPhysicalRowDataType();
final int[] keyProjection = createKeyFormatProjection(tableOptions, physicalDataType);
final int[] valueProjection = createValueFormatProjection(tableOptions, physicalDataType);
final String keyPrefix = tableOptions.getOptional(KEY_FIELDS_PREFIX).orElse(null);
return createKafkaTableSource(
physicalDataType,
keyDecodingFormat.orElse(null),
valueDecodingFormat,
keyProjection,
valueProjection,
keyPrefix,
getSourceTopics(tableOptions),
getSourceTopicPattern(tableOptions),
properties,
startupOptions.startupMode,
startupOptions.specificOffsets,
startupOptions.startupTimestampMillis);
}
/**
* @describe 重写getKafkaProperties,kafka-servers从元数据系统获取
* @param context none doc
* @return none doc
*/
public Properties getPupuKafkaProperties(Context context) {
final Properties kafkaProperties = new Properties();
Map<String, String> tableOptions = context.getCatalogTable().getOptions();
if (invokeHasKafkaClientProperties(tableOptions)) {
tableOptions.keySet().stream()
.filter(key -> key.startsWith(PROPERTIES_PREFIX))
.forEach(key -> {
final String value = tableOptions.get(key);
final String subKey = key.substring((PROPERTIES_PREFIX).length());
kafkaProperties.put(subKey, value);
});
}
httpMetadata(context, kafkaProperties);
return kafkaProperties;
}
/**
* @describe http请求元数据获取properties.bootstrap.servers信息
* @param context 上下文
* @param kafkaProperties kafka连接器参数
*/
private void httpMetadata(Context context, Properties kafkaProperties) {
// 获取自定义参数
ReadableConfig configuration = context.getConfiguration();
String metaUrl = configuration.get(ConfigOptions.key(Constant.HTTP_PARAMS_METAURL).stringType().defaultValue("metaSecret"));
String metaSecret = configuration.get(ConfigOptions.key(Constant.HTTP_PARAMS_METASECRET).stringType().defaultValue("metaSecret"));
String metaDbSecret = configuration.get(ConfigOptions.key(Constant.HTTP_PARAMS_METADBSECRET).stringType().defaultValue("metaDbSecret"));
context.getCatalogTable().getOptions().get(CONNECTION_NAME.key());
// 参数进行非空校验
if (StringUtils.isAnyBlank(metaUrl, metaSecret, metaDbSecret)) {
throw new ValidationException(
String.format("请检查数据参数【%s,%s,%s】是否正确!",
Constant.HTTP_PARAMS_METAURL,
Constant.HTTP_PARAMS_METASECRET,
Constant.HTTP_PARAMS_METADBSECRET));
}
String connectName = context.getCatalogTable().getOptions().get(CONNECTION_NAME.key());
Optional<JSONObject> jsonObjectOptions = toHttp(metaUrl, metaSecret, metaDbSecret, connectName);
if (jsonObjectOptions.isPresent()) {
final String key = "url";
final String bootStrapServers = "bootstrap.servers";
JSONObject jsonObject = jsonObjectOptions.get();
if(jsonObject.containsKey(key)) {
kafkaProperties.put(bootStrapServers, jsonObject.getString(key));
}
}
}
/**
* @describe 反射执行父类getKeyDecodingFormat方法
* @param helper none doc
* @return none doc
*/
@SneakyThrows
private Optional<DecodingFormat<DeserializationSchema<RowData>>> invokeGetKeyDecodingFormat(FactoryUtil.TableFactoryHelper helper) {
final String methodName = "getKeyDecodingFormat";
Method method = clazz.getDeclaredMethod(methodName, FactoryUtil.TableFactoryHelper.class);
method.setAccessible(true);
Object value = method.invoke(this, helper);
return (Optional<DecodingFormat<DeserializationSchema<RowData>>>) value;
}
/**
* @describe 反射执行父类getValueDecodingFormat方法
* @param helper none doc
* @return node doc
*/
@SneakyThrows
private DecodingFormat<DeserializationSchema<RowData>> invokeGetValueDecodingFormat(FactoryUtil.TableFactoryHelper helper) {
final String methodName = "getValueDecodingFormat";
Method method = clazz.getDeclaredMethod(methodName, FactoryUtil.TableFactoryHelper.class);
method.setAccessible(true);
Object value = method.invoke(this, helper);
return (DecodingFormat<DeserializationSchema<RowData>>) value;
}
/**
* @describe 反射执行父类validatePKConstraints方法
* @return none doc
*/
@SneakyThrows
private void invokeValidatePKConstraints(ObjectIdentifier tableName, CatalogTable catalogTable, Format format) {
final String methodName = "validatePKConstraints";
Method method = clazz.getDeclaredMethod(methodName, ObjectIdentifier.class, CatalogTable.class, Format.class);
method.setAccessible(true);
method.invoke(this, tableName, catalogTable, format);
}
/**
* @describe 反射执行父类hasKafkaClientProperties方法
* @return none doc
*/
@SneakyThrows
private boolean invokeHasKafkaClientProperties(Map<String, String> tableOptions) {
final Class<KafkaOptions> clazz = KafkaOptions.class;
final String methodName = "hasKafkaClientProperties";
Method method = clazz.getDeclaredMethod(methodName, Map.class);
method.setAccessible(true);
// 静态方法调用,调用对象可以传空
return (Boolean) method.invoke(null, tableOptions);
}
/**
* @describe 元数据http请求
* @param Url url
* @param Secret 秘钥
* @param Secret 秘钥
* @param connectName 库名
* @return
*/
private Optional<JSONObject> toHttp(String Url, String Secret, String DbSecret, String connectName) {
// 相关加强业务代码
System.out.println("我加强了MineKafkaDynamicTableFactory");
return Optional.empty();
}
}
2.4 测试
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import pupu.flink.pupu.bean.User;
public class MineKafkaDynamicTableFactoryTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
env.setParallelism(1);
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env, bsSettings);
tableEnv.getConfig().getConfiguration().setString("abc", "abc");
String kafkaConnectorSql = "CREATE TABLE kafkaTable (\n" +
" id INT,\n" +
" name STRING,\n" +
" age INT\n" +
") WITH (\n" +
" 'connector' = 'mine-kafka',\n" +
" 'topic' = 'csv-message',\n" +
" 'properties.bootstrap.servers' = 'xxxx',\n" +
" 'properties.group.id' = 'testGroup',\n" +
" 'scan.startup.mode' = 'earliest-offset',\n" +
" 'format' = 'csv'\n" +
")";
tableEnv.executeSql(kafkaConnectorSql);
Table table = tableEnv.sqlQuery("select * from kafkaTable");
tableEnv.toAppendStream(table, User.class).print();
env.execute();
}
}
执行结果:kafka走的是自定义连接器