编程大杂烩(三)
编程大杂烩(三)
39.double转int并四舍五入
public static void main(String[] args) {
System.out.println("向上取整:" + (int) Math.ceil(96.1));// 97 (去掉小数凑整:不管小数是多少,都进一)
System.out.println("向下取整" + (int) Math.floor(96.8));// 96 (去掉小数凑整:不论小数是多少,都不进位)
System.out.println("四舍五入取整:" + Math.round(96.1));// 96 (这个好理解,不解释)
System.out.println("四舍五入取整:" + Math.round(96.8));// 97
}
40.sql的to_date()函数
参考链接:https://blog.csdn.net/keyuzhang/article/details/89473384
-- 日期例子:
SELECT TO_DATE('2006-05-01 19:25:34', 'YYYY-MM-DD HH24:MI:SS')
SELECT TO_DATE('2006-05-01 19:25', 'YYYY-MM-DD HH24:MI')
SELECT TO_DATE('2006-05-01 19', 'YYYY-MM-DD HH24')
SELECT TO_DATE('2006-05-01', 'YYYY-MM-DD')
SELECT TO_DATE('2006-05', 'YYYY-MM')
SELECT TO_DATE('2006', 'YYYY')
日期格式
格式控制 描述
YYYY、YYY、YY 分别代表4位、3位、2位的数字年
YEAR 年的拼写
MM 数字月
MONTH 月的全拼
MON 月的缩写
DD 数字日
DAY 星期的全拼
DY 星期的缩写
AM 表示上午或者下午
HH24、HH12 12小时制或24小时制
MI 分钟
SS 秒钟
SP 数字的拼写
TH 数字的序数词
日期说明:
当省略HH、MI和SS对应的输入参数时,Oracle使用0作为DEFAULT值。
如果输入的日期数据忽略时间部分,Oracle会将时、分、秒部分都置为0,也就是说会取整到日。
同样,忽略了DD参数,Oracle会采用1作为日的默认值,也就是说会取整到月。
但是,不要被这种“惯性”所迷惑,如果忽略MM参数,Oracle并不会取整到年,取整到当前月。
注意:
1.在使用Oracle的to_date函数来做日期转换时,可能会直觉地采用“yyyy-MM-dd HH:mm:ss”的格式
作为格式进行转换,但是在Oracle中会引起错误:“ORA 01810 格式代码出现两次”。如:
select to_date('2005-01-01 13:14:20','yyyy-MM-dd HH24:mm:ss') from dual;
原因是SQL中不区分大小写,MM和mm被认为是相同的格式代码,所以Oracle的SQL采用了mi代替分钟。
select to_date('2005-01-01 13:14:20','yyyy-MM-dd HH24:mi:ss') from dual;
2.另要以24小时的形式显示出来要用HH24
select to_char(sysdate,'yyyy-MM-dd HH24:mi:ss') from dual;//mi是分钟
select to_char(sysdate,'yyyy-MM-dd HH24:mm:ss') from dual;//mm会显示月份
例子:
select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') as nowTime from dual; //日期转化为字符串
select to_char(sysdate,'yyyy') as nowYear from dual; //获取时间的年
select to_char(sysdate,'mm') as nowMonth from dual; //获取时间的月
select to_char(sysdate,'dd') as nowDay from dual; //获取时间的日
select to_char(sysdate,'hh24') as nowHour from dual; //获取时间的时
select to_char(sysdate,'mi') as nowMinute from dual; //获取时间的分
select to_char(sysdate,'ss') as nowSecond from dual; //获取时间的秒
求某天是星期几:
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day') from dual;
星期一
select to_char(to_date('2002-08-26','yyyy-mm-dd'),'day','NLS_DATE_LANGUAGE = American') from dual;
monday
设置日期语言
ALTER SESSION SET NLS_DATE_LANGUAGE='AMERICAN';
也可以这样
TO_DATE ('2002-08-26', 'YYYY-mm-dd', 'NLS_DATE_LANGUAGE = American')
两个日期间的天数:
select floor(sysdate - to_date('20020405','yyyymmdd')) from dual;
41.sql的position函数
参考链接:http://www.yiidian.com/sql/position-function-in-sql.html
示例
示例 1:以下 SELECT 查询显示字符 S 在原始字符串中的位置:
SELECT POSITION('S' IN 'SUSTAINABLE')AS POSITION_S;
输出结果为:
| POSITION_S |
|---|
| 1 |
示例 2:以下 SELECT 查询显示 DELHI 单词在给定字符串中的位置:
SELECT POSITION( 'DELHI' IN 'NEW DELHI') AS POSITION_DELHI;
输出结果为:
| POSITION_DELHI |
|---|
| 5 |
42.时间比较大小compareTo
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd");
Date date = format.parse(format.format(new Date())); // 当前时间为2022-07-26
Date date1 = format.parse("2022-07-26");
System.out.println("当前时间:"+date); //当前时间:Sun Apr 17 00:00:00 CST 2022
System.out.println("输入比较时间:"+date1);//输入比较时间:Sat Apr 16 00:00:00 CST 2022
// date.compareTo(date1)
// 如果指定的数与参数相等返回 0。(date1等于date)
// 如果指定的数大于参数返回 1。(date1小于date)
// 如果指定的数小于参数返回 -1。(date1大于date)
System.out.println(date.compareTo(date1));//0
Date date2 = format.parse("2022-07-25");
System.out.println(date.compareTo(date2));//1
Date date3 = format.parse("2022-07-27");
System.out.println(date.compareTo(date3));//-1
43.@FeignClient注解理解
————————————————
版权声明:本文为CSDN博主「Heart_B」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/hearth_b/article/details/107573332
Feign基本介绍
首先来个基本的普及,怕有些同学还没接触过Spring Cloud。Feign是Netflix开源的一个REST客户端,通过定义接口,使用注解的方式描述接口的信息,就可以发起接口调用。
GitHub地址:https://github.com/OpenFeign/feign
下面是GitHub主页上给的一个最基本的使用示列,示列中采用Feign调用GitHub的接口。
interface GitHub {
@RequestLine("GET /repos/{owner}/{repo}/contributors")
List<Contributor> contributors(@Param("owner") String owner, @Param("repo") String repo);
@RequestLine("POST /repos/{owner}/{repo}/issues")
void createIssue(Issue issue, @Param("owner") String owner, @Param("repo") String repo);
}
public static class Contributor {
String login;
int contributions;
}
public static class Issue {
String title;
String body;
List<String> assignees;
int milestone;
List<String> labels;
}
public class MyApp {
public static void main(String... args) {
GitHub github = Feign.builder()
.decoder(new GsonDecoder())
.target(GitHub.class, "https://api.github.com");
// Fetch and print a list of the contributors to this library.
List<Contributor> contributors = github.contributors("OpenFeign", "feign");
for (Contributor contributor : contributors) {
System.out.println(contributor.login + " (" + contributor.contributions + ")");
}
}
}
Spring Cloud OpenFeign介绍
Spring Cloud OpenFeign是Spring Cloud团队将原生的Feign结合到Spring Cloud中的产物。从上面原生Feign的使用示列来看,用的注解都是Feign中自带的,但我们在开发中基本上都是基于Spring MVC的注解,不是很方便调用。所以Spring Cloud OpenFeign扩展了对Spring MVC注解的支持,同时还整合了Ribbon和Eureka来提供均衡负载的HTTP客户端实现。
GitHub地址:https://github.com/spring-cloud/spring-cloud-openfeign
官方提供的使用示列:
@FeignClient("stores")
public interface StoreClient {
@RequestMapping(method = RequestMethod.GET, value = "/stores")
List<Store> getStores();
@RequestMapping(method = RequestMethod.POST, value = "/stores/{storeId}", consumes = "application/json")
Store update(@PathVariable("storeId") Long storeId, Store store);
}
FeignClient注解的使用介绍
value, name
value和name的作用一样,如果没有配置url那么配置的值将作为服务名称,用于服务发现。反之只是一个名称。
serviceId
serviceId已经废弃了,直接使用name即可。
contextId
比如我们有个user服务,但user服务中有很多个接口,我们不想将所有的调用接口都定义在一个类中,比如:
Client 1
@FeignClient(name = "optimization-user")
public interface UserRemoteClient {
@GetMapping("/user/get")
public User getUser(@RequestParam("id") int id);
}
Client 2
@FeignClient(name = "optimization-user")
public interface UserRemoteClient2 {
@GetMapping("/user2/get")
public User getUser(@RequestParam("id") int id);
}
这种情况下启动就会报错了,因为Bean的名称冲突了,具体错误如下:
Description:
The bean 'optimization-user.FeignClientSpecification', defined in null, could not be registered. A bean with that name has already been defined in null and overriding is disabled.
Action:
Consider renaming one of the beans or enabling overriding by setting spring.main.allow-bean-definition-overriding=true
解决方案可以增加下面的配置,作用是允许出现beanName一样的BeanDefinition。
spring.main.allow-bean-definition-overriding=true
另一种解决方案就是为每个Client手动指定不同的contextId,这样就不会冲突了。
上面给出了Bean名称冲突后的解决方案,下面来分析下contextId在Feign Client的作用,在注册Feign Client Configuration的时候需要一个名称,名称是通过getClientName方法获取的:
String name = getClientName(attributes);
registerClientConfiguration(registry, name, attributes.get("configuration"));
private String getClientName(Map<String, Object> client) {
if (client == null) {
return null;
}
String value = (String) client.get("contextId");
if (!StringUtils.hasText(value)) {
value = (String) client.get("value");
}
if (!StringUtils.hasText(value)) {
value = (String) client.get("name");
}
if (!StringUtils.hasText(value)) {
value = (String) client.get("serviceId");
}
if (StringUtils.hasText(value)) {
return value;
}
throw new IllegalStateException("Either 'name' or 'value' must be provided in @"
+ FeignClient.class.getSimpleName());
}
可以看到如果配置了contextId就会用contextId,如果没有配置就会去value然后是name最后是serviceId。默认都没有配置,当出现一个服务有多个Feign Client的时候就会报错了。
其次的作用是在注册FeignClient中,contextId会作为Client 别名的一部分,如果配置了qualifier优先用qualifier作为别名。
private void registerFeignClient(BeanDefinitionRegistry registry,
AnnotationMetadata annotationMetadata, Map<String, Object> attributes) {
String className = annotationMetadata.getClassName();
BeanDefinitionBuilder definition = BeanDefinitionBuilder
.genericBeanDefinition(FeignClientFactoryBean.class);
validate(attributes);
definition.addPropertyValue("url", getUrl(attributes));
definition.addPropertyValue("path", getPath(attributes));
String name = getName(attributes);
definition.addPropertyValue("name", name);
String contextId = getContextId(attributes);
definition.addPropertyValue("contextId", contextId);
definition.addPropertyValue("type", className);
definition.addPropertyValue("decode404", attributes.get("decode404"));
definition.addPropertyValue("fallback", attributes.get("fallback"));
definition.addPropertyValue("fallbackFactory", attributes.get("fallbackFactory"));
definition.setAutowireMode(AbstractBeanDefinition.AUTOWIRE_BY_TYPE);
// 拼接别名
String alias = contextId + "FeignClient";
AbstractBeanDefinition beanDefinition = definition.getBeanDefinition();
boolean primary = (Boolean) attributes.get("primary"); // has a default, won't be null
beanDefinition.setPrimary(primary);
// 配置了qualifier优先用qualifier
String qualifier = getQualifier(attributes);
if (StringUtils.hasText(qualifier)) {
alias = qualifier;
}
BeanDefinitionHolder holder = new BeanDefinitionHolder(beanDefinition, className,
new String[] { alias });
BeanDefinitionReaderUtils.registerBeanDefinition(holder, registry);
}
url
url用于配置指定服务的地址,相当于直接请求这个服务,不经过Ribbon的服务选择。像调试等场景可以使用。
使用示列
@FeignClient(name = "optimization-user", url = "http://localhost:8085")
public interface UserRemoteClient {
@GetMapping("/user/get")
public User getUser(@RequestParam("id") int id);
}
decode404
当调用请求发生404错误时,decode404的值为true,那么会执行decoder解码,否则抛出异常。
解码也就是会返回固定的数据格式给你:
{"timestamp":"2020-01-05T09:18:13.154+0000","status":404,"error":"Not Found","message":"No message available","path":"/user/get11"}
configuration
configuration是配置Feign配置类,在配置类中可以自定义Feign的Encoder、Decoder、LogLevel、Contract等。
configuration定义
List item
public class FeignConfiguration {
@Bean
public Logger.Level getLoggerLevel() {
return Logger.Level.FULL;
}
@Bean
public BasicAuthRequestInterceptor basicAuthRequestInterceptor() {
return new BasicAuthRequestInterceptor("user", "password");
}
@Bean
public CustomRequestInterceptor customRequestInterceptor() {
return new CustomRequestInterceptor();
}
// Contract,feignDecoder,feignEncoder.....
}
使用示列
@FeignClient(value = "optimization-user", configuration = FeignConfiguration.class)
public interface UserRemoteClient {
@GetMapping("/user/get")
public User getUser(@RequestParam("id")int id);
}
fallback
定义容错的处理类,也就是回退逻辑,fallback的类必须实现Feign Client的接口,无法知道熔断的异常信息。
fallback定义
@Component
public class UserRemoteClientFallback implements UserRemoteClient {
@Override
public User getUser(int id) {
return new User(0, "默认fallback");
}
}
fallbackFactory
也是容错的处理,可以知道熔断的异常信息。
fallbackFactory定义
@Component
public class UserRemoteClientFallbackFactory implements FallbackFactory<UserRemoteClient> {
private Logger logger = LoggerFactory.getLogger(UserRemoteClientFallbackFactory.class);
@Override
public UserRemoteClient create(Throwable cause) {
return new UserRemoteClient() {
@Override
public User getUser(int id) {
logger.error("UserRemoteClient.getUser异常", cause);
return new User(0, "默认");
}
};
}
}
使用示列
@FeignClient(value = "optimization-user", fallbackFactory = UserRemoteClientFallbackFactory.class)
public interface UserRemoteClient {
@GetMapping("/user/get")
public User getUser(@RequestParam("id")int id);
}
path
path定义当前FeignClient访问接口时的统一前缀,比如接口地址是/user/get, 如果你定义了前缀是user, 那么具体方法上的路径就只需要写/get 即可。
使用示列
primary
primary对应的是@Primary注解,默认为true,官方这样设置也是有原因的。当我们的Feign实现了fallback后,也就意味着Feign Client有多个相同的Bean在Spring容器中,当我们在使用@Autowired进行注入的时候,不知道注入哪个,所以我们需要设置一个优先级高的,@Primary注解就是干这件事情的。
qualifier
qualifier对应的是@Qualifier注解,使用场景跟上面的primary关系很淡,一般场景直接@Autowired直接注入就可以了。
如果我们的Feign Client有fallback实现,默认@FeignClient注解的primary=true, 意味着我们使用@Autowired注入是没有问题的,会优先注入你的Feign Client。
如果你鬼斧神差的把primary设置成false了,直接用@Autowired注入的地方就会报错,不知道要注入哪个对象。
解决方案很明显,你可以将primary设置成true即可,如果由于某些特殊原因,你必须得去掉primary=true的设置,这种情况下我们怎么进行注入,我们可以配置一个qualifier,然后使用@Qualifier注解进行注入,示列如下:
Feign Client定义
@FeignClient(name = "optimization-user", path="user", qualifier="userRemoteClient")
public interface UserRemoteClient {
@GetMapping("/get")
public User getUser(@RequestParam("id") int id);
}
Feign Client注入
@Autowired
@Qualifier("userRemoteClient")
private UserRemoteClient userRemoteClient;
44.Springboot使用@ConditionalOnProperty控制配置类是否生效
————————————————
版权声明:本文为CSDN博主「Buckletime」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_45698637/article/details/118883733
Springboot项目中集成Shiro框架做登录验证,要求在配置文件中增加一个关于登录的开关控制,控制是否启用登录验证。可以使用 @ConditionalOnProperty 解决。
开关配置
在application.yml文件中增加如下配置:
#登录
cas:
#控制开关 true:启用登录验证 false:不启用
enable: false
@ConditionalOnProperty注解使用
在配置类上加@ConditionalOnProperty注解
@ConditionalOnProperty(prefix = "cas", value = "enable", matchIfMissing = true)
@Configuration
public class ShiroConfig {
// 省略其他配置信息...
}
作用
@ConditionalOnProperty注解用来控制@Configuration是否生效。
ConditionalOnProperty属性说明
@ConditionalOnProperty注解类源码如下:
@Retention(RetentionPolicy.RUNTIME)
@Target({ ElementType.TYPE, ElementType.METHOD })
@Documented
@Conditional(OnPropertyCondition.class)
public @interface ConditionalOnProperty {
// 数组,获取对应property名称的值,与name不可同时使用
String[] value() default {};
// 配置属性名称的前缀,比如spring.http.encoding
String prefix() default "";
// 数组,配置属性完整名称或部分名称
// 可与prefix组合使用,组成完整的配置属性名称,与value不可同时使用
String[] name() default {};
// 可与name组合使用,比较获取到的属性值与havingValue给定的值是否相同,相同才加载配置
String havingValue() default "";
// 缺少该配置属性时是否可以加载。如果为true,没有该配置属性时也会正常加载;反之则不会生效
boolean matchIfMissing() default false;
}
@ConditionalOnProperty注解使用
根据@ConditionalOnProperty注解的属性信息,有两种使用方式,使用name 或者value。
属性matchIfMissing = true表示若未找到该配置属性时也会正常加载。
方式一、根据属性value,若value值为true,则加载此配置类
@ConditionalOnProperty(prefix = "cas", value = "enable", matchIfMissing = true)
// 或者可以省略prefix前缀
@ConditionalOnProperty(value = "cas.enable", matchIfMissing = true)
方式二、根据属性name和havingValue指定值是否一致,一致则加载此配置类
@ConditionalOnProperty(name = "cas.enable", havingValue = "true", matchIfMissing = true)
使用
AliyunOssProperties:
@Data
@NoArgsConstructor
@AllArgsConstructor
@ConfigurationProperties(prefix = "udian.aliyun.oss")
public class AliyunOssProperties {
private String bucket;
private String accessId;
private String accessKey;
private String endpoint;
private String root;
}
EcloudOssProperties:
@Data
@NoArgsConstructor
@AllArgsConstructor
@ConfigurationProperties(prefix = "udian.ecloud.oss")
public class EcloudOssProperties {
private String accessId;
private String accessKey;
private String endpoint;
private String bucket;
private String root;
}
LocalFileProperties:
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.boot.context.properties.ConfigurationProperties;
@Data
@NoArgsConstructor
@AllArgsConstructor
@ConfigurationProperties(prefix = "udian.local.file")
public class LocalFileProperties {
private String rootPath;
private String root;
}
ThirdConfiguration:
import com.udian.third.file.service.FileService;
import com.udian.third.file.service.impl.AliyunOssFileServiceImpl;
import com.udian.third.file.service.impl.EcloudOssFileServiceImpl;
import com.udian.third.file.service.impl.LocalFileServiceImpl;
import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.io.File;
@Configuration
@EnableConfigurationProperties(value = {AliyunOssProperties.class,EcloudOssProperties.class,LocalFileProperties.class})
public class ThirdConfiguration {
@Bean
@ConditionalOnProperty(prefix = "udian.file",name = "server-type",havingValue = "aliyun")
public FileService aliyunOssFileService(){
return new AliyunOssFileServiceImpl();
}
@Bean
@ConditionalOnProperty(prefix = "udian.file",name = "server-type",havingValue = "ecloud")
public FileService ecloudOssFileService(){
return new EcloudOssFileServiceImpl();
}
@Bean
@ConditionalOnProperty(prefix = "udian.file",name = "server-type",havingValue = "local")
public FileService localFileService(){
return new LocalFileServiceImpl();
}
}
当配置为udian.file.server-type=local即local生效
udian.file.server-type=local
udian.file.domain=http://ip:8000/files
udian.file.root-path=/data/uploadfile
udian.file.base-url=http://ip:8888/file/fileDown/downloadFileById
45.maven-compiler-plugin和spring-boot-maven-plugin的选择
参考链接:https://blog.csdn.net/nanosss/article/details/121826306?spm=1001.2014.3001.5506
在搭建springboot项目时候,会遇到maven打包插件报错的情况,笔者做了一个测试,对这2种方式进行一个验证
1.maven-compiler-plugin方式
此种方式打出的包是一个普通jar,并不能执行,但是可以被引用其中的bean。可以点开其jar包一探究竟,发现并没有把依赖打进包里。
不含有root-inf,没有依赖被打进来。

2.spring-boot-maven-plugin方式
这种方式打出的包可执行,但是我并没有去验证其中的bean是否可以被引用。网上说不可被引用,有待进一步验证。
打好的包到服务器上运行,可运行 ,且含有完整的依赖包

46.fastjson
————————————————
版权声明:本文为CSDN博主「beidaol」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/beidaol/article/details/103767189
说明
com.alibaba.fastjson.JSONObject是经常会用到的JSON工具包,同样它的转换方法也会经常被我们使用,包括对象转成JSON串,JSON串转成java对象等,如果过一段时间不用的话很容易就会忘记,所以将使用方法总结如下,以便以后忘记了方便查询。
//Java对象转换成String类型的JSON字符串
JSONObject.toJSONString(Java对象)
//String类型的JSON字符串转换成Java对象
JSONObject.toJavaObject(JSON字符串,Java对象.class)
//Json字符串转换成JSONObject对象
JSONObject.parseObject(JSON字符串)
//JSON字符串转换成Java对象
JSONObject.parseObject(JSON字符串,Java对象.class)
JSON
JSON 即 JavaScript Object Natation,它是一种轻量级的数据交换格式,非常适合于服务器与 JavaScript 的交互。
创建json对象
用put(key,value)拼接json:
JSONObject object = new JSONObject();
object.put("YWH", "projId");
object.put("YWX", "2010");
object.put("JGXYH", object.getString("YWX"));
System.out.println(object); // {"YWH":"projId","YWX":"2010","JGXYH":"2010"}
创建json数组
用add添加json对象(json对象转json数组):
JSONObject object = new JSONObject();
object.put("YWH", "projId");
object.put("YWX", "2010");
object.put("JGXYH", object.getString("YWX"));
System.out.println(object);
JSONArray jsonArrayRow = new JSONArray();
jsonArrayRow.add(object);
jsonArrayRow.add(object.getString("YWX"));
System.out.println(jsonArrayRow);// [{"YWH":"projId","YWX":"2010","JGXYH":"2010"},"2010"]
JSON.parseObject(String text)与JSONObject.parseObject(String text)
JSONObject是JSON的子类。JSON是一个抽象类,JSON中有一个静态方法parseObject(String text),
将text解析为一个JSONObject对象并返回;JSONObject是一个继承自JSON的类,
当调用JSONObject.parseObject(result)时,会直接调用父类的parseObject(String text)。
所以两者没什么区别,一个是用父类去调用父类自己的静态的parseObject(String text),
一个是用子类去调用父类的静态parseObject(String text),两者调的是同一个方法。
parseObject(String str) 的作用
json.parseObbject(String str)是将str转换成相应的jsonObject对象,
其中str是“键值对”形式的json字符串,转化为jsonObject对象之后就可以使用其内置的方法,进行处理
JSON.parseArray()
这个方法的作用就是将json格式的数据转换成数组格式。
假设有Person这个类,有json类型数据
jsonStr = [{"name":"张三","age":"1"},{"name":"李四","age":"4"}],
那么List lists = json.parseArray(jsonStr, Person.class);
lists就可以接收jsonStr了
JSON与JAVA数据的转换
来自net.sf.json.*下的类(jar包是json-lib-x.x.jar)
JSONObject jo = JSONObject.fromObject(map);将参数解析成JSONObject对象
它在对Object转换的时候是按照domain类中的所有getXXX()方法进行转换的。
如果你在类中写了非属性的getXXX()方法,那么返回给你的就会有XXX属性了。
1. List集合转换成json代码
List list = new ArrayList();
list.add( "first" );
list.add( "second" );
JSONArray jsonArray2 = JSONArray.fromObject( list );
2. Map集合转换成json代码
Map map = new HashMap();
map.put("name", "json");
map.put("bool", Boolean.TRUE);
map.put("int", new Integer(1));
map.put("arr", new String[] { "a", "b" });
map.put("func", "function(i){ return this.arr[i]; }");
JSONObject json = JSONObject.fromObject(map);
3. Bean转换成json代码
JSONObject jsonObject = JSONObject.fromObject(new JsonBean());
4. 数组转换成json代码
boolean[] boolArray = new boolean[] { true, false, true };
JSONArray jsonArray1 = JSONArray.fromObject(boolArray);
5. 一般数据转换成json代码
JSONArray jsonArray3 = JSONArray.fromObject("['json','is','easy']" );
6、首先将json字符串转换为json对象,然后再解析json对象,过程如下。
JSONObject jsonObject = JSONObject.fromObject(jsonStr);
根据json中的键得到它的值
String name = jsonObject.getString("name");
int num = jsonObject.getInt("num");
String sex = jsonObject.getString("sex");
int age = jsonObject.getInt("age");
7.将json字符串转换为java对象
先将json字符串转换为json对象,再将json对象转换为java对象,如下所示。
JSONObject obj = new JSONObject().fromObject(jsonStr);//将json字符串转换为json对象
将json对象转换为java对象
Person jb = (Person)JSONObject.toBean(obj,Person.class);//将建json对象转换为Person对象
8.将java对象转换为json字符串
先将java对象转换为json对象,在将json对象转换为json字符串
JSONObject json = JSONObject.fromObject(obj);//将java对象转换为json对象
String str = json.toString();//将json对象转换为字符串
47.Runtime.getRuntime().availableProcessors()
————————————————
版权声明:本文为CSDN博主「马丁半只瞄」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/fenglongmiao/article/details/79401449
java.lang.Runtime.availableProcessors() 方法: 返回可用处理器的Java虚拟机的数量。
这个值可以在虚拟机中的某个调用过程中改变。应用程序是可用的处理器数量敏感,因此应该偶尔查询该属性,并适当调整自己的资源使用情况。
方法声明:public native int availableProcessors();
例子:
package com.vrv.linkdood_util;
/**
* 说 明:
*
* @author 作者名:冯龙淼
* E-mail:[email protected]
*
* @version 版 本 号:1.0.
* 创建时间:2018年2月28日 下午3:53:47
*/
public class RuntimeMain{
public static void main(String arg[]){
// check the number of processors available
// 16,电脑为8核心16线程
System.out.println("" + Runtime.getRuntime().availableProcessors());
}
}
然而,更大的问题在于Runtime.getRuntime().availableProcessors()也并非都能返回你所期望的数值。比如说,在我的四核1-4-1机器上,它返回的是4,这是对的。不过在我的1-4-2机器 上,也就是一个CPU插槽,4核,每个核2个超线程,这样的话会返回8。不过我其实只有4个核,如果代码的瓶颈是在CPU这块的话,我会有7个线程在同时 竞争CPU周期,而不是更合理的4个线程。如果我的瓶颈是在内存这的话,那这个测试我可以获得7倍的性能提升。
不过这还没完!Java Champions上的一个哥们发现了一种情况,他有一台16-4-2的机器 (也就是16个CPU插槽,每个CPU4个核,每核两个超线程,返回的值居然是16!从我的i7 Macbook pro上的结果来看,我觉得应该返回的是1642=128。在这台机器上运行Java 8的话,它只会将通用的FJ池的并发数设置成15。正如 Brian Goetz所指出的,“虚拟机其实不清楚什么是处理器,它只是去请求操作系统返回一个值。同样的,操作系统也不知道怎么回事,它是去问的硬件设备。硬件会告诉它一个值,通常来说是硬件线程数。操作系统相信硬件说的,而虚拟机又相信操作系统说的。”
48.生产环境 InputStream.available() = 0 导致的问题
————————————————
版权声明:本文为CSDN博主「我傲故我狂」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_36918149/article/details/103022221
1、问题现象
InputStream is = connection.getInputStream();
String reqData = "";
if (is != null && is.available() != 0) {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
byte[] receiveBuffer = new byte[2048];//缓冲区长度
//读取数据长度,InputStream要读取的数据长度一定要小于等于缓冲区中的字节数
int readBytesSize = is.read(receiveBuffer);
while (readBytesSize != -1) {//判断流是否位于文件末尾而没有可用的字节
//从receiveBuffer内存处的0偏移开始写,写与readBytesSize长度相等的字节
bos.write(receiveBuffer, 0, readBytesSize);
readBytesSize = is.read(receiveBuffer);
}
reqData = new String(bos.toByteArray(), "UTF-8");//编码后的tr2报文
String reqDataEncrypt=Base64Utils.base64Encode(reqData,"UTF-8");
logger.info("请求返回报文:{}", reqDataEncrypt);
}
在生产环境数据请求量的时候经常无法进入读取数据流的逻辑, 导致业务逻辑报空指针异常,联系了接口提供方,排查数据是有正常通过数据流回写,联系运维排查了网络,网络没有异常。既然数据回写与网络都没有问题, 我们就着研究上面的业务代码。
2、问题原因
进过对上面代码进行添加日志,发现“is.available()” 是等于0,导致无法进入读取数据流的逻辑。
为什么接口服务方已经返回了数据 但 is.available()=0呢 ? 为什么测试环境压测也没能复现?
带着这两个疑问,在google上需求答案。 终于在一些博客上发现 is.available() 判断数据流是否为0,是非阻塞操作,此操作不会等待数据流全部返回以后才执行,在业务数量大的时候,服务方数据同步返回时间比较长,还未等到数据流返回,程序已经开始执行 is.available(),从而导致服务方有返回数据,而is.available()=0 ;
3、问题解决方案
InputStream的available()方法的作用是返回此输入流在不受阻塞情况下能读取的字节数。网络流与文件流不同的关键就在于是否“受阻”二字,网络socket流在读取时如果没有内容read()方法是会受阻的,所以从socket初始化的输入流的available也是为零的,所以要read一字节后再使用,这样可用的字节数就等于 available + 1。但文件读取时read()一般是不会受阻的,因为文件流的可用字节数 available = file.length(),而文件的内容长度在创建File对象时就已知了。
所以调用网络流(socket)的available()方法前,一定记得要先调用read()方法,这样才能避免获取为0的不正确情况。
InputStream is = connection.getInputStream();
String reqData = "";
is.read(); //read()为阻塞操作,会等待数据全部返回后执行
if (is != null && is.available()!=0) {
ByteArrayOutputStream bos = new ByteArrayOutputStream();
byte[] receiveBuffer = new byte[2048];//缓冲区长度
//读取数据长度,InputStream要读取的数据长度一定要小于等于缓冲区中的字节数
int readBytesSize = is.read(receiveBuffer);
while (readBytesSize != -1) {//判断流是否位于文件末尾而没有可用的字节
//从receiveBuffer内存处的0偏移开始写,写与readBytesSize长度相等的字节
bos.write(receiveBuffer, 0, readBytesSize);
readBytesSize = is.read(receiveBuffer);
}
reqData = new String(bos.toByteArray(), "UTF-8");//编码后的tr2报文
String reqDataEncrypt=Base64Utils.base64Encode(reqData,"UTF-8");
logger.info("请求返回报文:{}", reqDataEncrypt);
}
49.java一个接口拥有多个实现类,调用指定实现类
参考链接:https://blog.csdn.net/weixin_46146718/article/details/114109613?spm=1001.2014.3001.5506
1、接口如下
/**
* @author lichangyuan
* @create 2021-02-26 0:37
*/
public interface OrdinaryService {
JsonData queryByKeywordPagination(Integer page, Integer counts,Object parameter[]);
}
2、有如下两个实现
实现类一
@Service("maintenanceService")
public class MaintenanceServiceImpl implements MaintenanceService, OrdinaryService {
@Override
public JsonData queryByKeywordPagination(Integer page, Integer counts, Object[] parameter) {
return null;
}
}
实现类二
@Service("inspectionService")
public class InspectionServiceImpl implements InspectionService,OrdinaryService {
@Override
public JsonData queryByKeywordPagination(Integer page, Integer counts, Object[] parameter) {
return null;
}
}
3、根据不同的条件调用不同的实现
方法一
@Resource(name="maintenanceService")
OrdinaryService maintenanceService;
@Resource(name="inspectionService")
OrdinaryService inspectionService;
方法二
@Autowired
@Qualifier("maintenanceService")
ShopPay weixinPay;
@Autowired
@Qualifier("inspectionService")
ShopPay aliPay;
50.Spring Boot之全局异常处理:404异常为何捕获不到
————————————————
版权声明:本文为CSDN博主「斗者_2013」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/w1014074794/article/details/106038996
Spring Boot有很多非常好的特性,可以帮助我们更快速的完成开发工作。今天和大家聊聊Spring boot的全局异常处理。
问题
1、spring boot中怎么进行全局异常处理?
2、为什么我的404异常捕获不到?
3、常见的http请求异常,能统一封装成json返回吗?
实战说明
项目依赖包:
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<optional>trueoptional>
dependency>
接口声明:
@SpringBootApplication
@RestController
public class ErrorApplication {
public static void main(String[] args) {
SpringApplication.run(ErrorApplication.class, args);
}
@GetMapping("/hello")
public String hello(){
return "hello laowan!";
}
@GetMapping("/testGet")
public String testGet(String name) throws Exception {
if (name==null) {
throw new BusinessException(ResultCode.PAPAM_IS_BLANK);
}
return "laowan!";
}
@PostMapping("/testPost")
public String testPost(){
return "post laowan!";
}
}
自定义返回码枚举类:
/**
* @program: error
* @description:返回状态码
* @author: wanli
* @create: 2020-05-09 22:03
**/
@Getter
public enum ResultCode {
/*成功状态吗*/
SUCCESS(1,"成功"),
/*系统异常:4001-1999*/
SYS_ERROR(4000,"系统异常,请稍后重试"),
/*参数错误:1001-1999*/
PAPAM_IS_INVALID(1001,"参数无效"),
PAPAM_IS_BLANK(1002,"参数为空"),
PAPAM_TYPE_BIND_ERROR(1003,"参数类型错误"),
PAPAM_NOT_COMPLETE(1003,"参数缺失"),
/*用户错误:2001-2999*/
USER_NOT_LOGGED_IN(2001,"用户未登录,请登录后重试"),
USER_LOGIN_ERROR(2002,"账号不存在或密码错误"),
USER_ACCOUNT_FORBIDDERN(2003,"账号已被禁用"),
USER_NOT_EXIST(2004,"用户不存在"),
USER_HAS_EXISTED(2005,"账号已存在")
;
//状态码
private Integer code;
//提示信息
private String message;
ResultCode(Integer code,String message){
this.code = code;
this.message = message;
}
}
通用返回类:
/**
* 通用返回响应
*/
@JsonInclude(JsonInclude.Include.NON_NULL)
@Data
public class CommonResp<T> {
private Integer code;
private String message;
private T data;
public CommonResp(ResultCode resultCode) {
this.code=resultCode.getCode();
this.message=resultCode.getMessage();
}
public CommonResp(ResultCode resultCode, T data) {
this.code=resultCode.getCode();
this.message=resultCode.getMessage();
this.data = data;
}
public CommonResp(Integer code,String message) {
this.code=code;
this.message=message;
}
public static <T> CommonResp create(ResultCode resultCode) {
return new CommonResp( resultCode);
}
public static <T> CommonResp getErrorResult(String message) {
return new CommonResp(-1,message);
}
public static <T> CommonResp create(ResultCode resultCode, T data) {
return new CommonResp( resultCode,data);
}
}
自定义业务异常:
/**
* 自定义业务异常
* @program: error
* @description:
* @author: wanli
* @create: 2020-05-09 21:49
**/
@Getter
public class BusinessException extends Exception{
private ResultCode resultCode;
public BusinessException(){}
public BusinessException(ResultCode resultCode){
super(resultCode.getMessage());
this.resultCode = resultCode;
}
public BusinessException(String message){
super(message);
}
}
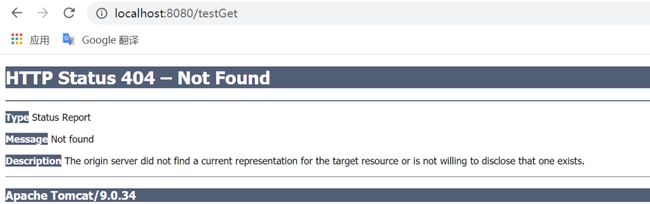
如果我们不进行异常处理,直接抛出BusinessException异常的话,请求接口如下:
请求链接:http://localhost:8080/testGet
返回结果如下,是一个异常提示页面,显然和我们现在主流的前后端分离,统一采用json格式返回结果不符。

声明全局异常处理:
/**
* @ClassName: GlobalExceptionHandler
* @Description: 异常处理
* @date: 2017年6月6日 下午2:12:08
*/
@Slf4j
@ControllerAdvice
public class GlobalExceptionHandler{
/**
* 业务异常处理
* @param e
* @return
* @throws Exception
*/
@ResponseBody
@ExceptionHandler( BusinessException.class )
public CommonResp handleBusinessException (BusinessException e ) throws Exception {
log.error("BusinessException error", e);
return CommonResp.create(e.getResultCode());
}
}
1、使用@ControllerAdvice注解声明全局异常处理类
2、使用@ExceptionHandler指定要捕捉什么异常,这里会优先捕捉子级异常,当没有匹配到子级异常时,才会去匹配父级异常。比如同时声明了@ExceptionHandler( BusinessException.class )和@ExceptionHandler(Exception.class )方法进行异常处理,当抛出BusinessException异常时,只会被@ExceptionHandler( BusinessException.class )注解的方法捕获到。
3、通过@ResponseBody注解控制返回json格式数据。
重启项目,再次请求,结果如下。
说明我们配置的BusinessException异常的全局捕获成功,也是按照我们定义的异常码返回的JSON格式数据。

404异常捕捉
假设我们去请求一个不存在的项目下一个不存在的url,会出现什么样的返回结果呢?
请求链路:http://localhost:8080/test
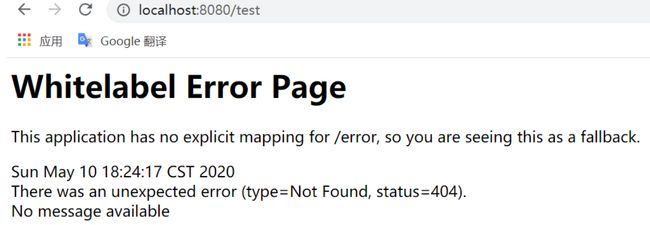
我们会发现,返回的是一个404的异常页面,关键是后台竟然没有打印任何异常日志。
那么针对这类不是经由请求接口里面抛出的异常,我们怎么去捕捉,并封装成json格式进行返回呢?
首先,添加参数,控制异常抛出:
#出现错误时, 直接抛出异常
spring.mvc.throw-exception-if-no-handler-found=true
#不要为我们工程中的资源文件建立映射
spring.resources.add-mappings=false
然后继承ResponseEntityExceptionHandler,封装异常处理
@ControllerAdvice
@Slf4j
public class RestResponseEntityExceptionHandler extends ResponseEntityExceptionHandler {
public RestResponseEntityExceptionHandler() {
super();
}
@Override
protected ResponseEntity<Object> handleExceptionInternal(Exception ex, @Nullable Object body, HttpHeaders headers, HttpStatus status, WebRequest request) {
log.error(ex.getMessage(),ex);
if (HttpStatus.INTERNAL_SERVER_ERROR.equals(status)) {
request.setAttribute("javax.servlet.error.exception", ex, 0);
}
return new ResponseEntity( new CommonResp(status.value(),ex.getMessage()), headers, status);
}
}
再次请求,发现404异常捕获成功,并返回json异常提示。

这里提一点注意事项,在全局异常处理类GlobalExceptionHandler中,尽量不要为了方便,直接对Exception异常进行捕获处理,会影响返回结果的HttpStatus。
我们演示一下:
/**
* 统一异常处理
* @param e
* @return
* @throws Exception
*/
@ResponseBody
@ExceptionHandler( Exception.class )
public CommonResp handleException (Exception e){
log.error( "Exception error", e );
return CommonResp.getErrorResult(e.getMessage());
}
然后再次请求http://localhost:8080/test
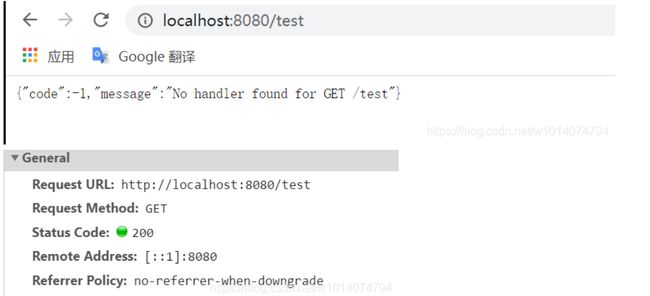
分析:
这是由于RestResponseEntityExceptionHandler类先对异常处理,返回ResponseEntity,由于ResponseEntity中的HttpStatus是一个异常码,异常会紧接着被我们自定义的GlobalExceptionHandler类中的@ExceptionHandler( Exception.class )捕获,这里由于返回的是一个封装的CommonResp对象,而不是一个ResponseEntity对象,默认就相当于把异常捕捉封装处理了,虽然返回的结果数据是json数据,异常提示也正确,但是原本HttpStatu为404的请求竟然变成了200成功请求,显然不是我们想要的。
有人可能会说,我在@ExceptionHandler( Exception.class )方法里面,也封装返回一个ResponseEntity对象不就好了,但是这里比较难获取原本的HttpStatu,不推荐。
所以,建议大家尽量谨慎使用@ExceptionHandler( Exception.class)去进行异常处理,而是针对具体的异常进行特定处理。
最后,推荐大家看看ResponseEntityExceptionHandler类的源码,会对Spring Boot中对ResponseEntity的异常处理,有更深的了解。
里面默认对如下异常进行了捕捉处理。

核心处理流程:
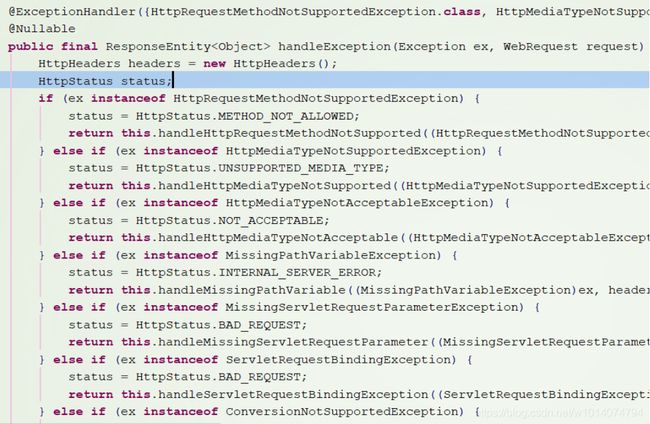
可以发现,默认的实现中,返回结构都是为空。

这就是我们在继承ResponseEntityExceptionHandler类后,重写handleExceptionInternal类的原因:
@ControllerAdvice
@Slf4j
public class RestResponseEntityExceptionHandler extends ResponseEntityExceptionHandler {
public RestResponseEntityExceptionHandler() {
super();
}
@Override
protected ResponseEntity<Object> handleExceptionInternal(Exception ex, @Nullable Object body, HttpHeaders headers, HttpStatus status, WebRequest request) {
log.error(ex.getMessage(),ex);
if (HttpStatus.INTERNAL_SERVER_ERROR.equals(status)) {
request.setAttribute("javax.servlet.error.exception", ex, 0);
}
//通过HttpStatus返回码和异常名称封装返回结果
return new ResponseEntity( new CommonResp(status.value(),ex.getMessage()), headers, status);
}
}
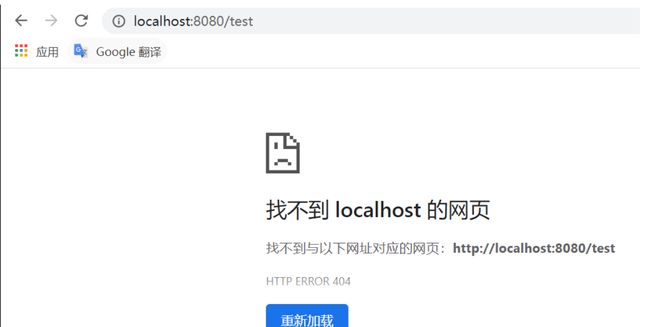
如果只是简单继承,不封装返回值的话,请求结果如下:
定义server.servlet.context-path后,异常捕获失败
新增server.servlet.context-path属性,让servlet拦截所有与/tax匹配的请求
server.servlet.context-path=/tax
请求如下链接:http://localhost:8080/testGet

分析:
server.servlet.context-path默认为"/",即servlet拦截tomcat下的所有请求。
如果配置为server.servlet.context-path=/tax,那么tomcat只会将请求路径匹配的请求转发到项目中。
这也是很多人疑惑,为什么已经在spring boot项目中配置了全局异常处理,
但是当前请求localhost:8080/testGet时,404异常请求没有被项目中配置的全局异常处理捕获。
**因为请求根本没有进你的项目中,而且直接被tomcat处理了,**所以明明请求报404失败,但是你的工程下没有任何异常日志提示,全局异常处理也没有生效。
可以想想下以前使用单独的web服务器部署项目,如果你的请求路径没有和server.servlet.context-path匹配的话,请求根本就没有进入你的项目中。
所以,如果希望对进入tomcat的所有请求都进行处理的话,server.servlet.context-path一定要配置为"/",
这样你才能在代码中,对相关异常做处理,不然,就是直接tomcat返回的默认异常页面了。
404异常抛出tomcat版本信息问题
有时候我们会发现,经由tomcat直接抛出的404异常,会泄露中间件的版本信息。
在很多安全级别比较高的项目中,由于需要进行安全扫描,如果发现中间件的版本信息,就容易针对性的进行攻击,是一个非常常见的中间件版本信息泄露的安全漏洞问题。
经研究发现,该问题是由于引入了spring-boot-devtools包导致的。
解决办法有2种,
方法一:简单暴力的去除spring-boot-devtools包依赖。
方法二:通过设置scope为provided,使该包只在测试时有效,编译打包时自动过滤该jar包依赖。
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-devtoolsartifactId>
<scope>providedscope>
<optional>trueoptional>
dependency>
给大家复习下Maven的scope属性的作用:
1.compile:默认值 他表示被依赖项目需要参与当前项目的编译,还有后续的测试,运行周期也参与其中,是一个比较强的依赖。打包的时候通常需要包含进去
2.test:依赖项目仅仅参与测试相关的工作,包括测试代码的编译和执行,不会被打包,例如:junit
3.runtime:表示被依赖项目无需参与项目的编译,不过后期的测试和运行周期需要其参与。与compile相比,跳过了编译而已。例如JDBC驱动,适用运行和测试阶段
4.provided:打包的时候可以不用包进去,别的设施会提供。事实上该依赖理论上可以参与编译,测试,运行等周期。相当于compile,但是打包阶段做了exclude操作
5.system:从参与度来说,和provided相同,不过被依赖项不会从maven仓库下载,而是从本地文件系统拿。需要添加systemPath的属性来定义路径。
总结
- 1、通过@ControllerAdvice、@ExceptionHandler、@ResponseBody三个注解的组合使用,实现全局异常处理。
- 2、通过配置spring.mvc.throw-exception-if-no-handler-found=true,控制404异常抛出
- 3、通过继承ResponseEntityExceptionHandler类,可以利用重写实现404异常的自定义格式返回
- 4、自定义业务异常和统一的接口返回数据格式,将CommonResp、ResultCode、BusinessException很好的结合使用。
- 5、404异常导致tomcat版本号泄露问题的解决
- 6、全局异常处理拦截不到404请求的原因分析
51.spring-boot-configuration-processor用法
spring默认使用yml中的配置,但有时候要用传统的xml或properties配置,就需要使用spring-boot-configuration-processor了
引入pom依赖
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-configuration-processorartifactId>
<optional>trueoptional>
dependency>
authorSetting.properties:
author.name=zhangsan
author.age=20
再在配置类开头加上@PropertySource(“classpath:your.properties”),其余用法与加载yml的配置一样
@Component
@PropertySource(value = {"classpath:static/config/authorSetting.properties"},
ignoreResourceNotFound = false, encoding = "UTF-8", name = "authorSetting.properties")
public class AuthorTest {
@Value("${author.name}")
private String name;
@Value("${author.age}")
private int age;
}
@PropertySource 中的属性解释
1.value:指明加载配置文件的路径。
2.ignoreResourceNotFound:指定的配置文件不存在是否报错,默认是false。当设置为 true 时,若该文件不存在,程序不会报错。实际项目开发中,最好设置 ignoreResourceNotFound 为 false。
3.encoding:指定读取属性文件所使用的编码,我们通常使用的是UTF-8。
当我们使用 @Value 需要注入的值较多时,代码就会显得冗余,于是 @ConfigurationProperties 登场了
@Component
@ConfigurationProperties(prefix = "author")
@PropertySource(value = {"classpath:static/config/authorSetting.properties"},
ignoreResourceNotFound = false, encoding = "UTF-8", name = "authorSetting.properties")
public class AuthorTest {
private String name;
private int age;
}
使用 @EnableConfigurationProperties 开启 @ConfigurationProperties 注解:
@RestController
@EnableConfigurationProperties
public class DemoController {
@Autowired
AuthorTest authorTest;
@RequestMapping("/")
public String index(){
return "author's name is " + authorTest.getName() + ",ahtuor's age is " + authorTest.getAge();
}
}
52.minio的安装及使用
————————————————
版权声明:本文为CSDN博主「惜鸟」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_39218530/article/details/107839487
一、概述
最近在学习使用minio,在这里对自己的学习过程做一个记录和总结,方便自己查阅。
Minio是GlusterFS创始人之一Anand Babu Periasamy发布新的开源项目。Minio兼容Amason的S3分布式对象存储项目,采用Golang实现,客户端支持Java、Python、Javacript、 Golang语言。
Minio可以做为云存储的解决方案用来保存海量的图片,视频,文档。由于采用Golang实现,服务端可以工作在Windows、Linux、 OS X和FreeBSD上。安装和配置非常简单,基本是复制可执行程序,单行命令就可以运行起来。minio还可以通过容器部署以及部署到k8s集群,详细部署方式可以查看官方文档。
minio中文官方文档地址: https://docs.min.io/cn/
minio的源码地址:https://github.com/minio/minio
minio白皮书:http://www.cloudbin.cn/?p=2917
二、下载二进制文件安装minio
使用如下命令快速安装一个单机minio
# 下载 minio
wget https://dl.min.io/server/minio/release/linux-amd64/minio
# 添加可执行权限
chmod +x minio
# 设置登录minio的 access key
export MINIO_ACCESS_KEY=minioadmin
# 设置登录minio的 secret key
export MINIO_SECRET_KEY=minioadmin
# 启动 minio
./minio server /data
安装后使用浏览器访问http://127.0.0.1:9000,如果可以访问,则表示minio已经安装成功。输入上面自定义的access key 和 secret key就可以登录了。

三、spring boot整合使用minio
1、使用maven引入minio依赖
在pom.xml中添加如下依赖,minio的最新依赖版本可以到maven中央仓库搜索,这里使用的最新版7.1.0
<properties>
<minio.version>7.1.0minio.version>
properties>
<dependency>
<groupId>io.miniogroupId>
<artifactId>minioartifactId>
<version>${minio.version}version>
dependency>
2、在application.yml中定义连接minio的参数
# minio 连接参数
minio:
endpoint: 127.0.0.1
port: 9000
accessKey: minioadmin
secretKey: minioadmin
bucketName: image
3、定义一个MinioUtil.java工具类
@Slf4j
@Component
public class MinioUtils {
@Value("${minio.endpoint}")
private String endpoint;
@Value("${minio.port}")
private Integer port;
@Value("${minio.accessKey}")
private String accessKey;
@Value("${minio.secretKey}")
private String secretKey;
@Value("${minio.bucketName}")
private String bucketName;
private static MinioClient minioClient;
public MinioClient getInstance() {
if (minioClient == null) {
minioClient = MinioClient.builder().endpoint(endpoint, port, false).credentials(accessKey, secretKey).build();
}
return minioClient;
}
/**
*
* @Description 获取minio所有的桶
* @return java.util.List
**/
public List<Bucket> getAllBucket() throws Exception {
// 获取minio中所以的bucket
List<Bucket> buckets = getInstance().listBuckets();
for (Bucket bucket : buckets) {
log.info("bucket 名称: {} bucket 创建时间: {}", bucket.name(), bucket.creationDate());
}
return buckets;
}
/**
*
* @Description 将图片上传到minio服务器
* @param inputStream: 输入流
* @param objectName: 对象名称
* @return void
**/
public void uploadToMinio(InputStream inputStream, String objectName) {
try {
long size = inputStream.available();
PutObjectArgs putObjectArgs = PutObjectArgs.builder()
.bucket(bucketName)
.object(objectName)
.stream(inputStream, size, -1)
.build();
// 上传到minio
getInstance().putObject(putObjectArgs);
inputStream.close();
} catch (Exception e) {
log.error(e.getMessage());
e.printStackTrace();
}
}
/**
*
* @Description 根据指定的objectName获取下载链接,需要bucket设置可下载的策略
* @param objectName: 对象的名称
* @return java.lang.String
**/
public String getUrlByObjectName(String objectName) {
String objectUrl = null;
try {
objectUrl = getInstance().getObjectUrl(bucketName, objectName);
} catch (Exception e) {
log.error(e.getMessage());
e.printStackTrace();
}
return objectUrl;
}
/**
*
* @Description 根据objectName从minio中下载文件到指定的目录
* @param objectName: objectName
* @param fileName: 文件名称
* @param dir: 文件目录
* @return void
**/
public void downloadImageFromMinioToFile(String objectName, String fileName, String dir) throws Exception {
GetObjectArgs objectArgs = GetObjectArgs.builder()
.bucket(bucketName)
.object(objectName)
.build();
File file = new File(dir);
if (!file.exists()) {
file.mkdirs();
}
InputStream inputStream = getInstance().getObject(objectArgs);
FileOutputStream outputStream = new FileOutputStream(new File(dir, fileName.substring(fileName.lastIndexOf("/")+1)));
int length;
byte[] buffer = new byte[1024];
while ((length = inputStream.read(buffer)) != -1) {
outputStream.write(buffer, 0, length);
}
outputStream.close();
inputStream.close();
}
}
四、总结
最后做一个总结,这里只是对minio做一个简单的介绍和使用,详细的使用方式需要查阅官方文档。对于一些新的api的学习,最好是直接通过IDE(推荐使用Intellij IDEA)下载源码查看java doc 进行学习,举个例子:当使用minio上传对象,我们不知道该怎么传递参数的时候,我们可以通过IDEA提供的快捷键(ctrl + Q)查看api的java doc, 如下图所示:

53.MYSQL中IN与EXISTS的区别
————————————————
版权声明:本文为CSDN博主「魏梦筱_xiao」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_39539399/article/details/80851817
在MYSQL的连表查询中,最好是遵循‘小表驱动大表的原则’
一、IN与EXISTS的区别
1、IN查询分析
SELECT * FROM A WHERE id IN (SELECT id FROM B);
等价于:1、SELECT id FROM B ----->先执行in中的查询
2、SELECT * FROM A WHERE A.id = B.id
以上in()中的查询只执行一次,它查询出B中的所有的id并缓存起来,然后检查A表中查询出的id在缓存中是否存在,如果存在则将A的查询数据加入到结果集中,直到遍历完A表中所有的结果集为止。
1、IN查询分析
以下用遍历结果集的方式来分析IN查询

通过以上程序可以看出,当B表的数据较大时不适合使用in()查询,因为它会将B表中的数据全部遍历一次
例如:
1、A表中有100条记录,B表中有1000条记录,那么最多可能遍历100*1000次,效率很差
2、A表中有1000条记录,B表中有100条记录,那么最多可遍历1000*100此,内循环次数减少,效率大大提升
结论:IN()查询适合B表数据比A表数据小的情况,IN()查询是从缓存中取数据
2、EXISTS查询分析
语法:SELECT 字段 FROM table WHERE EXISTS(subquery);
SELECT * FROM a WHERE EXISTS(SELECT 1 FROM b WHERE B.id = A.id);
以上查询等价于:
1、SELECT * FROM A;
2、SELECT I FROM B WHERE B.id = A.id;
EXISTS()查询会执行SELECT * FROM A查询,执行A.length次,并不会将EXISTS()查询结果结果进行缓存,
因为EXISTS()查询返回一个布尔值true或flase,它只在乎EXISTS()的查询中是否有记录,与具体的结果集无关。
EXISTS()查询是将主查询的结果集放到子查询中做验证,根据验证结果是true或false来决定主查询数据结果是否得以保存。
以下用遍历结果集的方式来分析EXISTS查询

从以上程序可以看出:
当B表的数据比A表的数据大时适合使用EXISTS()查询,因为它不用遍历B操作,只执行一次查询就OK了
例如:
1、A表有100条记录,B表有1000条记录,那么EXISTS()会执行100次去判断A表中的id是否与B表中的id相等.因为它只执行A.length次,可见B表数据越多,越适合EXISTS()发挥效果.
2、A表有10000条记录,B表有100条记录,那么EXISTS()还是执行10000次,此时不如使用in()遍历10000*100次,因为IN()是在内存里遍历数据进行比较,而EXISTS()需要查询数据库,我们都知道查询数据库所消耗的性能更高,而内存比较很快.
EXISTS举例:
exists (返回结果集,为真)
not exists (不返回结果集,为真)
表A
ID NAME
1 A1
2 A2
3 A3
表B
ID AID NAME
1 1 B1
2 2 B2
3 2 B3
表A和表B是1对多的关系 A.ID => B.AID
1.SELECT ID,NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE A.ID = B.AID);
执行结果:
ID NAME
1 A1
2 A2
原理如下:
(1)SELECT ID,NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID=1)
---> SELECT * FROM B WHERE B.AID=1有值,返回真,所以有数据
(2)SELECT ID,NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID=2)
---> SELECT * FROM B WHERE B.AID=2有值,返回真,所以有数据
(3)SELECT ID,NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID=3)
---> SELECT * FROM B WHERE B.AID=3无值,返回假,所以没有数据
得到的结果为,A.ID=1或2时才有数据,所以最终的条件等于
SELECT ID,NAME FROM A where id in (1,2);
3、结论
exists()适合B表比A表数据大的情况
当A表数据与B表数据一样大时,in与exists效率差不多,可任选一个使用
54.Java中transient关键字的详细总结
————————————————
版权声明:本文为CSDN博主「老鼠只爱大米」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u012723673/article/details/80699029
一、概要介绍
本文要介绍的是Java中的transient关键字,transient是短暂的意思。对于transient 修饰的成员变量,在类的实例对象的序列化处理过程中会被忽略。 因此,transient变量不会贯穿对象的序列化和反序列化,生命周期仅存于调用者的内存中而不会写到磁盘里进行持久化。
1.序列化
Java中对象的序列化指的是将对象转换成以字节序列的形式来表示,这些字节序列包含了对象的数据和信息,一个序列化后的对象可以被写到数据库或文件中,也可用于网络传输。一般地,当我们使用缓存cache(内存空间不够有可能会本地存储到硬盘)或远程调用rpc(网络传输)的时候,经常需要让实体类实现Serializable接口,目的就是为了让其可序列化。当然,序列化后的最终目的是为了反序列化,恢复成原先的Java对象实例。所以序列化后的字节序列都是可以恢复成Java对象的,这个过程就是反序列化。
2.为什么要用transient关键字?
在持久化对象时,对于一些特殊的数据成员(如用户的密码,银行卡号等),我们不想用序列化机制来保存它。为了在一个特定对象的一个成员变量上关闭序列化,可以在这个成员变量前加上关键字transient。
3.transient的作用
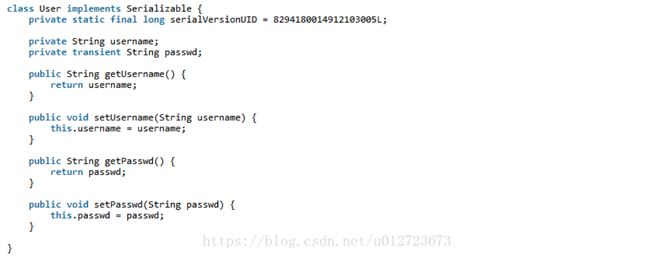
transient是Java语言的关键字,用来表示一个成员变量不是该对象序列化的一部分。当一个对象被序列化的时候,transient型变量的值不包括在序列化的结果中。而非transient型的变量是被包括进去的。 注意static修饰的静态变量天然就是不可序列化的。
User:
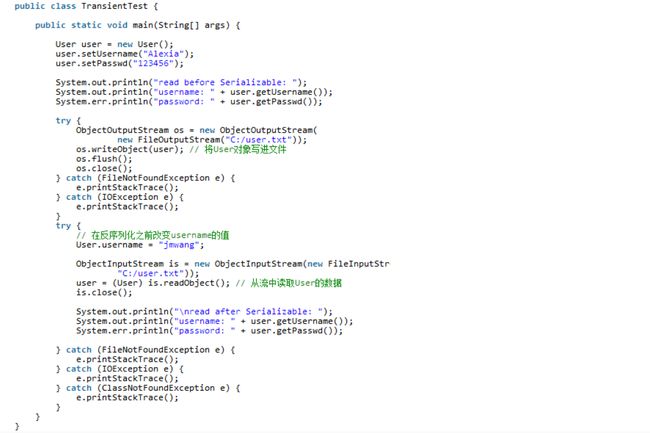
TransientTest:


二、transient使用总结
(1)一旦变量被transient修饰,变量将不再是对象持久化的一部分,该变量内容在序列化后无法被访问。
(2)transient关键字只能修饰变量,而不能修饰方法和类。注意,本地变量是不能被transient关键字修饰的。变量如果是用户自定义类变量,则该类需要实现Serializable接口。
(3)一个静态变量不管是否被transient修饰,均不能被序列化(如果反序列化后类中static变量还有值,则值为当前JVM中对应static变量的值)。序列化保存的是对象状态,静态变量保存的是类状态,因此序列化并不保存静态变量。
User:

TransientTest:

三、使用场景
(1)类中的字段值可以根据其它字段推导出来,如一个长方形类有三个属性长度、宽度、面积,面积不需要序列化。
(2) 一些安全性的信息,一般情况下是不能离开JVM的。
(3)如果类中使用了Logger实例,那么Logger实例也是不需要序列化的
55.Socket通信流程
————————————————
版权声明:本文为CSDN博主「fightsyj」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/fightsyj/article/details/86251421
Socket
在了解Socket的通信流程之前首先得弄明白Socket是啥才行,那Socket到底是啥叻?
Socket就是一组API,对TCP/IP协议进行封装的API!
可以将Socket理解为处于传输层和应用层之间的一个抽象层,它把TCP/IP层复杂的操作抽象为几个简单的接口供应用层调用以实现进程在网络中通信。
Socket通信流程
在对Socket有了大致了解之后,再来理解Socket的通信流程就容易很多了,Socket通信流程图如下:

简单描述一下Socket的通信流程:
- 服务端这边首先创建一个Socket(Socket()),然后绑定IP地址和端口号(Bind()),之后注册监听(Listen()),这样服务端就可以监听指定的Socket地址了;
- 客户端这边也创建一个Socket(Socket())并打开,然后根据服务器IP地址和端口号向服务器Socket发送连接请求(Connect());
- 服务器Socket监听到客户端Socket发来的连接请求之后,被动打开,并调用Accept()函数接收请求,这样客户端和服务器之间的连接就建立好了;
- 成功建立连接之后就可以你侬我侬了,客户端和服务器进行数据交互(Receive()、Send());
- 在腻歪完之后,各自关闭连接(Close()),交互结束;
56.java四种权限修饰符
————————————————
版权声明:本文为CSDN博主「勇敢牛牛_」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wxgxgp/article/details/55535129
1.访问权限修饰符
①public:意为公开的,访问权限最高,可以跨包访问。
②protect:意为受保护的,权限次之,可以在同包和子/父类中访问。
③default:意为默认的,一般不写,权限次之,可以在同包中访问。
④private:意为私有的,权限最低,只能在本类中访问。
所以,为了保证安全性,一般把访问权限降到最低。
四种访问权限修饰符如下图:

2.abstract(抽象)修饰符
①abstract修饰类,会使这个类成为一个抽象类,这个类将不能生成对象实例,但可以做为对象变量声明的类型,也就是编译时类型,抽象类就像当于一类的半成品,需要子类继承并覆盖其中的抽象方法。
②abstract修饰方法,会使这个方法变成抽象方法,也就是只有声明(定义)而没有实现,实现部分以”;”代替。需要子类继承实现(覆盖)。
举例:
abstract class E{
// 抽象类可以有非抽象方法
public void method1(){
/*code*/
};
public abstract void method2();//public abstract 可以省略
}
class F extends E{
//实现抽象方法method2
void method2(){
//写具体实现的代码
}
//method1不是抽象方法,不需要具体实现,但如果写了具体实现的方法会覆盖原有方法
}
最后再主方法里面定义一个父类引用指向子类对象,就会发生多态现象,比如
E e = new F();//E是抽象父类,F是E的继承类
e.show();//实际调用了子类里面的method2()方法
总结:
①抽象类和普通类差不多,只是不能用new实例化,必须要继承。
②抽象的方法所在类一定是抽象类;抽象类中的方法不一定都是抽象方法。
③抽象类中的抽象方法必须在子类中写具体实现的方法;如果抽象类中的方法是具体方法,那么重写该方法会覆盖原方法。
3.final修饰符
- final变量必须被显式初始化,并且只能被赋值一次值
- final修饰基本类型变量的时候, 该变量不能重新赋值
- final修饰引用类型变量的时候, 该变量不能重新指向其他对象
- final修饰的方法为最终的方法, 该方法不能被重写
- private类型的方法都默认为是final方法,因而也不能被子类重写
- final修饰的类为最终的类, 不能被继承
4.static修饰符
- 如果声明了静态方法或变量,值是放在方法区,因为方法区是一个数据共享区;所以不管什么变量访问它,都是同一份.
- 在静态方法中不能直接访问实例方法和实例变量.
- 在静态方法中不能使用this和super关键字.
- 静态方法不能被abstract修饰.
- 静态的成员变量可以使用类名或者是对象进行访问,非静态成员变量只能使用对象进行访问.
- 静态函数可以直接访问静态的成员,但是不能够直接访问非静态成员.,非静态函数可以访问静态和非静态成员.
- 当类被加载时,静态代码块只能被执行一次。类中不同的静态方法代码块按他们在类中出现的顺序被依次执行.
- 当多个修饰符连用时,修饰符的顺序可以颠倒,不过作为普遍遵守的编码规范,通常把访问控制修饰符放在首位,其次是static或abstact修饰符,接着就是其他的修饰符.
//这些修饰符放在一起是无效的
abstract与private
abstract与final
abstract与static
喜欢请关注我
至此,我们的编程大杂烩(三)就告一段落了。喜欢我的话可以关注我的微信公众号我爱学习呀嘻嘻,不定期分享各类资源哦。
编程大杂烩(四)
编程大杂烩(一)
编程大杂烩(二)
