论文《Deep Interest Evolution Network for Click-Through Rate Prediction》
阿里DIEN
摘要里面表示很多CTR模型都将用户历史行为的向量表示直接作为用户兴趣,没有对用户这些行为背后的隐兴趣进行建模;此外很少有工作考虑用户的兴趣的变化趋势。DIEN设计了兴趣抽取层从历史行为序列中捕获用户隐式兴趣,设计了兴趣进化层建模用户兴趣变化。
简介中,介绍前人工作多是关注不同特征域的特征交叉,很少关注用户兴趣表示,DIN使用attention机制来捕获用户不同兴趣和目标item的相关性,但是这些模型都是将历史行为序列直接当做用户兴趣,没有去挖掘这些行为序列背后的用户真正的兴趣,而且用户兴趣是变化的,捕获用户动态变化的兴趣也十分重要。
DIEN中有2个关键模块,一个是从用户显式行为序列中抽取用户隐式的兴趣,另一个是建模用户兴趣进化过程。在兴趣抽取层,DIEN使用GRU建模用户行为之间的依赖,提出了使用下一个行为来监督当前hidden state的学习的辅助loss,有额外监督的hidden state称为兴趣state,即用户的隐式兴趣。用户兴趣是多样化的,会导致兴趣飘逸现象:用户在相邻的行为这意图可能差异巨大,用户产生一个行为可能依赖于很久之前产生的一个历史行为,每个兴趣都有自己的进化过程。基于兴趣提取层抽取的兴趣序列,使用带attention update gate的GRU来建模用户的兴趣进化轨迹,计算兴趣state和目标item的相关性来加强相关兴趣的影响,降低不相关兴趣的影响。
在相关工作中,很多工作关注特征的交互,Wide&Deep和DeepFM结合低阶特征和高阶特征提升表达效果,PNN有个点积层捕获不同类别特征的交叉,这些模型没有明确的反映用户的兴趣。DIN使用attention来激活历史序列,但是没法捕获这些序列之间的依赖关系。TDSSM结合长期和短期的历史序列来提升推荐质量,DRAEM使用RNN来研究每个用户的动态表示,ATRank使用基于attention的序列框架建模不同的用户行为。
基线模型
四类特征,用户画像、用户行为、item(ad)特征、上下文特征,分别表示为 x p , x b , x a , x c \mathbf x_p,\mathbf x_b,\mathbf x_a,\mathbf x_c xp,xb,xa,xc,每个行为都是一个one-hot的向量表示,用户行为特征 x b = [ b 1 ; b 2 ; . . . ; b T ] ∈ R K × T \mathbf x_b = [\mathbf b_1;\mathbf b_2;...;\mathbf b_T] \in R^{K \times T} xb=[b1;b2;...;bT]∈RK×T, b t ∈ { 0 , 1 } K \mathbf b_t \in \{0,1\}^{K} bt∈{0,1}K其中 K K K表示有行为的商品总量, T T T表示用户行为序列长度。
Embedding
每个特征域对应一个Embedding矩阵,例如用户行为序列Embedding矩阵 E g o o d s = [ m 1 ; m 2 ; . . . ; m K ] ∈ R n E × K \mathbf E_{goods} = [\mathbf m_1;\mathbf m_2;...;\mathbf m_K] \in R^{n_E \times K} Egoods=[m1;m2;...;mK]∈RnE×K,总共有 K K K个行为(商品), n E n_E nE表示每个行为embedding的维度。对于指定用户,用户行为的Embedding矩阵 e b = [ m j 1 ; m j 2 ; . . . ; m j T ] ∈ R n E × T \mathbf e_b = [\mathbf m_{j_1};\mathbf m_{j_2};...;\mathbf m_{j_T}] \in R^{n_E \times T} eb=[mj1;mj2;...;mjT]∈RnE×T,其他各个域类似。
MLP
先对行为序列做pooling操作,然后拼接到一起,作为MLP的输入
Loss
L t a r g e t = − 1 N ∑ ( x , y ) ∈ D N ( y log ( p ( x ) ) + ( 1 − y ) log ( 1 − p ( x ) ) ) L_{target} = - \frac {1} {N} \sum_{(\mathbf x, y) \in D}^N ( y \log (p(\mathbf x)) + (1-y) \log (1 - p(\mathbf x)) ) Ltarget=−N1(x,y)∈D∑N(ylog(p(x))+(1−y)log(1−p(x)))
x = [ x p ; x b ; x a ; x c ] \mathbf x = [\mathbf x_p;\mathbf x_b;\mathbf x_a;\mathbf x_c] x=[xp;xb;xa;xc], y ∈ { 0 , 1 } y \in \{0,1\} y∈{0,1}
DIEN
Interest Extractor Layer
使用GRU来提取兴趣
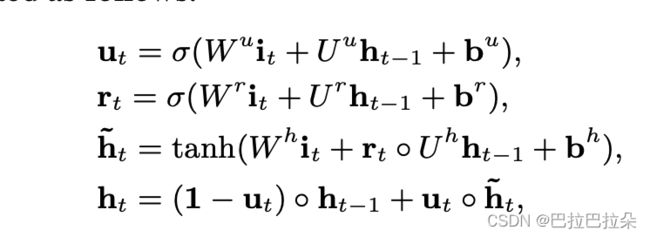
W u , W r , W h ∈ R n H × n I \mathbf W^u,\mathbf W^r,\mathbf W^h \in R^{n_H \times n_I} Wu,Wr,Wh∈RnH×nI, U u , U r , U h ∈ R n H × n H \mathbf U^u,\mathbf U^r,\mathbf U^h \in R^{n_H \times n_H} Uu,Ur,Uh∈RnH×nH, n H n_H nH表示隐层维度, n I n_I nI表示输入维度, i t = e b [ i ] \mathbf i_t=\mathbf e_b[i] it=eb[i]是GRU的输入, h t \mathbf h_t ht表示第 t t t个hidden state。
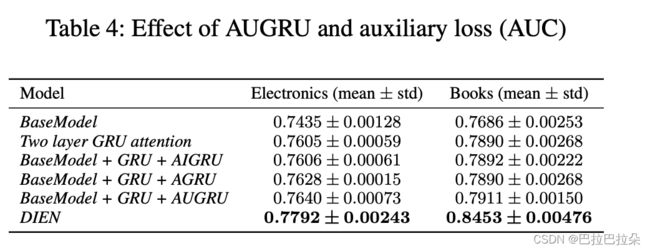
因为用户行为target item时通过最后一个兴趣触发的,因此能对最后一个兴趣state进行label监督,但是中间的兴趣状态 h t ( t < T ) \mathbf h_t(t
Loss
L a u x = − 1 N ( ∑ i = 1 N ∑ t log ( σ ( h t e b i [ t + 1 ] ) ) + log ( 1 − σ ( h t e b i [ t + 1 ] ) ) ) L_{aux} = - \frac {1} {N}( \sum_{i=1}^N \sum_t \log ( \sigma (\mathbf h_t \mathbf e_b^i[t+1]) ) + \log ( 1- \sigma (\mathbf h_t \mathbf e_b^i[t+1]) ) ) Laux=−N1(i=1∑Nt∑log(σ(htebi[t+1]))+log(1−σ(htebi[t+1])))
σ ( x 1 , x 2 ) = 1 1 + e x p ( − [ x 1 , x 2 ] ) \sigma (\mathbf x_1, \mathbf x_2) = \frac {1} { 1 + exp(- [\mathbf x_1, \mathbf x_2])} σ(x1,x2)=1+exp(−[x1,x2])1
L = L t a r g e t + α ∗ L a u x L = L_{target} + \alpha * L_{aux} L=Ltarget+α∗Laux
辅助loss使得每一个hidden state h t \mathbf h_t ht都能表示兴趣state
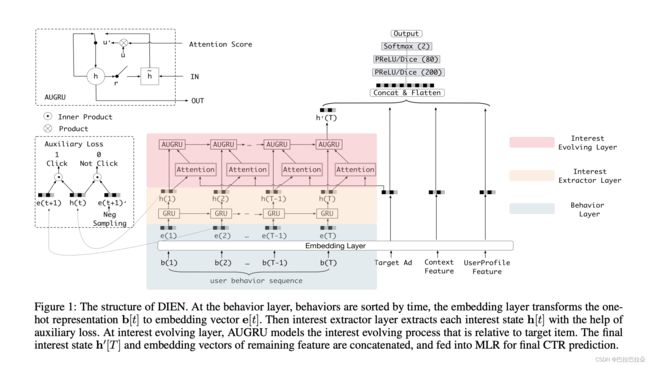
Interest Evolving Layer
用户的兴趣在随时间逐渐变化,兴趣在进化过程中有2个特点:
- 因为兴趣的多样性,兴趣可能会发生漂移,用户可能在一段时间内喜欢书籍,另外一段时间喜欢衣服。
- 兴趣互相影响,但是每个兴趣有自己的进化过程,例如对书籍的兴趣和对衣服的兴趣,DIEN仅关注进化过程中兴趣和target item的相关性。
使用 i t ′ \mathbf i_t^{'} it′和 h t ′ \mathbf h_t^{'} ht′表示兴趣进化层的输入状态和隐层状态,兴趣进化层的输入 i t ′ \mathbf i_t^{'} it′对应兴趣提取层的隐层状态 h t \mathbf h_t ht, i t ′ = h t \mathbf i_t^{'} = \mathbf h_t it′=ht,attention分数可以表示为
a t = h t W e a ∑ j = 1 T h j W e a a_t = \frac { \mathbf h_t \mathbf W \mathbf e_a } { \sum_{j = 1}^T \mathbf h_j \mathbf W \mathbf e_a } at=∑j=1ThjWeahtWea
其中 e a \mathbf e_a ea表示广告(target item)Embedding向量, W ∈ R n H × n A \mathbf W \in R^{n_H \times n_A} W∈RnH×nA, n H n_H nH表示hidden的维度, n A n_A nA表示广告Embedding的维度。
三种结合attention机制和GRU的方式
- GRU with attentional input (AIGRU) 直接用户attention分数(标量)乘以兴趣提取层的hidden state向量,这样不相关的兴趣因为attention分数小会减弱其相应的影响。但是效果不会好,因为即输入是零,也会改变GRU的hidden state,这样不相关的兴趣还是会影响兴趣进化过程。
i t ′ = a t ∗ h t \mathbf i_t^{'} = a_t * \mathbf h_t it′=at∗ht - Attention based GRU(AGRU),使用attention分数替换GRU的更新门
KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at position 64: …-a_t) * \tilde \̲m̲a̲t̲h̲b̲f̲ ̲h_{t-1}^{'} - GRU with attentional update gate (AUGRU)不替换更新gate,但是用attention分数改变更新gate
KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at position 8: \tilde \̲m̲a̲t̲h̲b̲f̲ ̲u_{t}^{'} = a_…
KaTeX parse error: Unexpected end of input in a macro argument, expected '}' at position 31: … = (1 - \tilde \̲m̲a̲t̲h̲b̲f̲ ̲u_{t}^{'} ) \c…