C++ - stack 和 queue 模拟实现 -认识 deque 容器 容器适配器
stack模拟实现
用模版实现 链式栈 和 顺序栈
对于stack 的实现,有两种方式,一种是连续空间存储的顺序栈,一种是不连续空间存储的链式栈,在C当中如果要使用两种不同的栈的话,实现方式是不一样的,他们的底层逻辑是不一样的 。所以要用不同的方式去实现。
而在C++当中有模版,而且C++当中的 stack 和 queue 不是单独实现的,是复用了 deque 这个类,也就意味着,在同一类当中 ,可以用模版参数来实现不同的栈。如下所示:
namespace My_stack
{
template
class stack
{
public:
private:
Container _con;
};
} 由上述代码,我们就可以在外面自定义这个栈是 链式结构 还是 顺序结构,如下代码所示:
My_stack::stack> st1;
My_stack::stack> st2; 
我们这里的顺序栈 使用的不是 deque 容器,而是vector,其实deque更好,这样只是简单实现,所以用vector 就足够。
上述就是使用上述 stack 模版的方式,这样,我们就可以自定义 stack 的 存储类型,和存储结构了。
直接复用有一个好处,我们可以不用实现构造函数 和 析构函数,因为我们使用的空间不是我们是实现的 stack 类监管,而是由 vector 和 list 监管。
在官方文档中,我们发现这里的 Container 模版参数给了缺省值,其实模版参数也是有缺省值的,这里的缺省值给的是类型。如下所示:

所以我, 还可以进行优化:
template> 增删查改
因为stack 是 vector 和 list 容器来实现,所以下面的函数也都可以复用 两个容器当中函数。
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_back ();
}
T top()
{
return _con.back();
}
size_t size()
{
return _con.size();
}
bool empty()
{
return _con.empty();
}总代码
#pragma once
namespace My_stack
{
template>
class stack
{
public:
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_back ();
}
T top()
{
return _con.back();
}
size_t size()
{
return _con.size();
}
bool empty()
{
return _con.empty();
}
private:
Container _con;
};
} queue 模拟实现
队列的实现 和 栈是一样的,都可以是使用其他类的 复用,达到容器适配器的效果:
#pragma once
#include
#include
#include
namespace bit
{
//
template>
class queue
{
public:
void push(const T& x)
{
_con.push_back(x);
}
void pop()
{
_con.pop_front();
//_con.erase(_con.begin());
}
T& front()
{
return _con.front();
}
T& back()
{
return _con.back();
}
size_t size()
{
return _con.size();
}
bool empty()
{
return _con.empty();
}
private:
Container _con;
};
void test_queue()
{
queue> q;
//queue> q;
q.push(1);
q.push(2);
q.push(3);
q.push(4);
while (!q.empty())
{
cout << q.front() << " ";
q.pop();
}
cout << endl;
}
}
注意:虽然我们上述实现的了 queue的 vector底层结构实现,但是queue用 vector 不太好,因为缺如是 先进先出的结构,这里vector 找尾需要遍历,存在效率问题,而且头删存储移位问题,效率不好。
在库当中的 queue 就没有支持 vector 为底层结构的 queue,因为在库当中,queue的Pop函数是直接调用的 pop_front() 这个函数,而这个函数是 vector没有的:
![]()
deque
deque的优劣
我们前面多次提到了 deque 这个容器,deque 也叫做 双端队列,虽然叫做队列,但是实际上这个容器已经不是队列了,队列要求是要先进先出,但是deque当中实现了其他功能,如下所示:

 我们发现,deque实现了 vector 有 list 没有的 operator[] 函数,还实现了 vector 没有 list 有的 头插头删等等。可以说,deque的功能 是 vector 和 list 的结合体。
我们发现,deque实现了 vector 有 list 没有的 operator[] 函数,还实现了 vector 没有 list 有的 头插头删等等。可以说,deque的功能 是 vector 和 list 的结合体。
虽然功能上很齐全,但是单个功能的效率不如 vector 和 list。
下述测试 deque 直接 sort()快排,和 deque 拷贝数据到 vector 之后排序,在拷贝回去,这两种方式的时间消耗(10000000个数据):
void test_op()
{
srand(time(0));
const int N = 1000000;
vector v1;
vector v2;
v1.reserve(N);
v2.reserve(N);
deque dq1;
deque dq2;
for (int i = 0; i < N; ++i)
{
auto e = rand();
//v1.push_back(e);
//v2.push_back(e);
dq1.push_back(e);
dq2.push_back(e);
}
// 拷贝到vector排序,排完以后再拷贝回来
int begin1 = clock();
// 先拷贝到vector
for (auto e : dq1)
{
v1.push_back(e);
}
// 排序
sort(v1.begin(), v1.end());
// 拷贝回去
size_t i = 0;
for (auto& e : dq1)
{
e = v1[i++];
}
int end1 = clock();
int begin2 = clock();
//sort(v2.begin(), v2.end());
sort(dq2.begin(), dq2.end());
int end2 = clock();
printf("deque copy vector sort:%d\n", end1 - begin1);
printf("deque sort:%d\n", end2 - begin2);
} 输出:

发现 deque 效率更低,但是deque的 拷贝消耗不大,几乎可以省略。
deque的底层实现
之前的vector 容器,扩容的时候都是有代价的,比如 vector 容器,它的扩容就是 新开辟一个空间,然后把原空间当中的数据拷贝到新的空间当中。这样做的代价不小,所以deque就在list 和 vector 之间做了新的结构设计:

deque底层设计:
- 如上图所示,是deque的结构设计,它有一个中控(指针数组)来维护多个 顺序表(连续存储结构)。而且存储各个 顺序表的头指针的 中控(指针数组)并不是从开始来存储指针,而是从中间开始存储,这样方便头插和尾差的时候,往前或后新开辟空间,用新指针来维护新开皮带空间。
- 每一个顺序表的size(),元素个数是一样的。
- 如果像头插和尾插数据,这种操作,可以新开辟一块空间,用新的指针来维护,在中控(指针数组当中指针是有顺序的)。
- 如果中控(指针数组)存储的指针满了,可以对 中控(指针数组)单独扩容。
- 上述提到了 中控(指针数组)可以单独扩容,这样的好处是:扩容时候,不需要拷贝其他顺序表当中的数据,主需要拷贝自己的指针数据,或者是存储在这单个的顺序表当中数据即可,大大减少了靠北的消耗。
这么一说,上述 deque 的结构,跟 vector
deque当中的 头插和尾插顺序:

问题:那么 中间插入是不是,不需要后面挪动数据,直接在想插入的位置的顺序表空间当中直接插入,需要挪动的只是这个小的顺序表中后面的数据,如果满了,只用扩容这个一个小的顺序表空间。
其实不是,可以看下面 vector 当中的对比和 operator[] 的实现方式。
迭代器

deque的底层实现是非常复杂的,处了上述的基本结构和功能,deque的迭代器的实现也是很复杂,deque的迭代器的封装了 四个指针:
- first 和 last 分别指向 每一段 数组的 开始和结束位置。
- cur 指向 在这个数组中,当前数据的位置。
- node 是一个二级指针,反向过来指向中控器,这样利于寻找下一个数组。
迭代器遍历过程如下图:
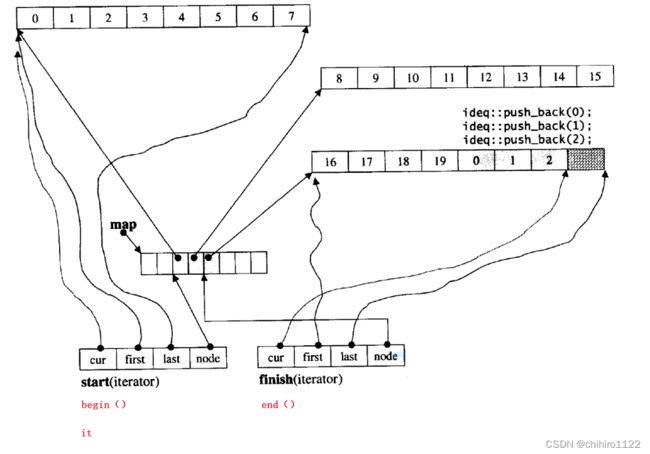
- *it :解引用 it, 解引用的是 cur,由cur 来遍历数组。
- ++it:有两种情况,一种是没有走到 last ,此时说明当前数组还没有走完,那么就直接 ++cut;如果当前数组走完了,就 ++node ,这样 node 就指向了下一个数组。更新其他是哪个指针的指向下一个位置的指定位置。
库当中是这样实现的:


deque 和 vector 相比
相比于 vector, deque 很大程度上的解决了扩容的问题(头插头删,中间插/删)。但是 在 operator[] 这个函数的实现比较复杂,这个函数需要计算,这个下标在哪一个 顺序表当中,计算方式如下:
- 首先看是否在第一个 顺序表当中,在就找位置访问;
- 不在第一个数组,用 i - 第一个数组的 size(),再去取 / 计算在第几个数组当中,在取 % 计算在这个数组的那一个位置。
虽然看上去计算并不多,但是在大量访问的时候还是有很大的效率问题,这里就印证了为什么上述deque 的sort() 跑不过 vector 的sort(),因为 在sort()当中用了很多的 operator[] 函数。
deque 和 list 相比
好处:
- 首先是支持 operator[] 函数。
- cpu高速缓存当中效率不错。
缺点:
头尾插删,都差不多,但是在中间插入和删除不好。这里没有使用上述在 deque 的底层实现小结当中最后提出的问题一样,没有使用那样的方式来实现,因为如果每一个顺序表的大小都是相等的,那么 operator[] 函数在计算下标位置的时候更加方便快捷。如果每一个顺序表的大小不一样,只能使用遍历的方式来计算个数,这样很麻烦。
所以,deque采用但是 挪动数据来实现的 中间插入和删除。那么挪动数据所带来的代价就很大了。
deque 的 使用场景
由上述分析,我们发现deque适合 高频的头尾插删,不是和 中间插删。
对于 高频的头尾插删,比如:上述的 stack 和 queue 容器就非常适合。