一步步读懂Pytorch Chatbot Tutorial代码(五) - 定义模型
文章目录
- 自述
- 有用的工具
- 代码出处
- 目录
- 头更大了
- 代码及说明 Define Models
-
- Encoder
-
- Encoder
- forward
- Decoder
-
- dot_socre
- forward
自述
我是编程小白,别看注册时间长,但从事的不是coding工作,为了学AI才开始自学Python。
平时就是照着书上敲敲代码,并没有深刻理解。现在想要研究chatbot了,才发现自己的coding水平急需加强,所以开这个系列记录自己一行行扣代码的过程。当然这不是从0开始的,只是把自己不理解的写出来,将来也可以作为资料备查。
最后还要重申一下,我没有系统学过编程,写这个系列就是想突破自己,各位大神请不吝赐教!
有用的工具
可以视觉化代码的网站https://pythontutor.com/visualize.html
代码出处
Pytorch的CHATBOT TUTORIAL
https://pytorch.org/tutorials/beginner/chatbot_tutorial.html?highlight=gpu%20training
目录
一步步读懂Pytorch Chatbot Tutorial代码(一) - 加载和预处理数据
一步步读懂Pytorch Chatbot Tutorial代码(二) - 数据处理
一步步读懂Pytorch Chatbot Tutorial代码(三) - 创建字典
一步步读懂Pytorch Chatbot Tutorial代码(四) - 为模型准备数据
一步步读懂Pytorch Chatbot Tutorial代码(五) - 定义模型
头更大了
和小朋友打羽毛球竟然把脚给崴了,头一次体验了做轮椅的感觉,发现那玩意并不好控制啊,和电影里面的不太一样。还好没有骨折,但是床上躺了5天,提前感觉到了老年生活的“乐趣”。瞬间觉得还是要好好锻炼身体,另外合适的鞋子和准备活动也是必须的。
还有代码复杂程度加倍了啊,这个系列要完…
代码及说明 Define Models
看下李沐的视频有助于理解下面的内容
https://www.bilibili.com/video/BV1mf4y157N2?from=search&seid=12221000276700031173&spm_id_from=333.337.0.0
Seq2Seq 模型
我们这个chatbot的核心是一个sequence-to-sequence(seq2seq)模型。 seq2seq模型的输入是一个变长的序列,而输出也是一个变长的序列。而且这两个序列的长度并不相同。一般我们使用RNN来处理变长的序列,Sutskever等人的论文发现通过使用两个RNN可以解决这类问题。这类问题的输入和输出都是变长的而且长度不一样,包括问答系统、机器翻译、自动摘要等等都可以使用seq2seq模型来解决。
其中一个RNN叫做Encoder,它把变长的输入序列编码成一个固定长度的context向量,我们一般可以认为这个向量包含了输入句子的语义。而第二个RNN叫做Decoder,初始隐状态是Encoder的输出context向量,输入是(表示句子开始的特殊Token),然后用RNN计算第一个时刻的输出,接着用第一个时刻的输出和隐状态计算第二个时刻的输出和新的隐状态,…,直到某个时刻输出特殊的(表示句子结束的特殊Token)或者长度超过一个阈值。Seq2Seq模型如下图所示。

Encoder
Encoder是个RNN,它会遍历输入的每一个Token(词),每个时刻的输入是上一个时刻的隐状态和输入,然后会有一个输出和新的隐状态。这个新的隐状态会作为下一个时刻的输入隐状态。每个时刻都有一个输出,对于seq2seq模型来说,通常只保留最后一个时刻的隐状态,认为它编码了整个句子的语义,但是后面会用到Attention机制,它还会用到Encoder每个时刻的输出。Encoder处理结束后会把最后一个时刻的隐状态作为Decoder的初始隐状态。
通常使用多层的Gated Recurrent Unit(GRU)或者LSTM来作为Encoder,这里使用GRU,可以参考Cho等人2014年的[论文]。
这里使用双向的RNN,如下图所示。
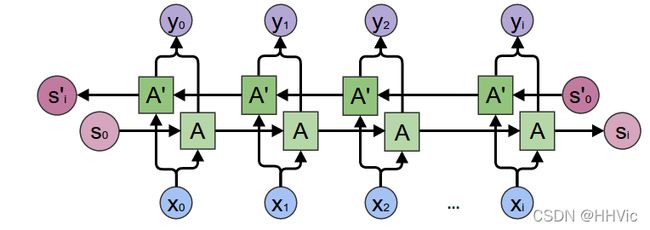
注意在接入RNN之前会有一个Embedding层,用来把每一个词(ID或者one-hot向量)映射成一个连续的稠密的向量,我们可以认为这个向量编码了一个词的语义。在我们的模型里,我们把它的大小定义成和RNN的隐状态大小一样(但是并不是一定要一样)。有了Embedding之后,模型会把相似的词编码成相似的向量(距离比较近)。
最后,为了把padding的batch数据传给RNN,我们需要使用下面的两个函数来进行pack和unpack,这两个函数是:torch.nn.utils.rnn.pack_padded_sequence 和 torch.nn.utils.rnn.pad_packed_sequence
计算图:
-
把词的ID通过Embedding层变成向量。
-
把padding后的数据进行pack。
-
传入GRU进行Forward计算。
-
Unpack计算结果
-
把双向GRU的结果向量加起来。
-
返回(所有时刻的)输出和最后时刻的隐状态。
输入:
input_seq: 一个batch的输入句子,shape是(max_length, batch_size)
input_lengths: 一个长度为batch的list,表示句子的实际长度。
hidden: 初始化隐状态(通常是零),shape是(n_layers x num_directions, batch_size, hidden_size)
输出:
outputs: 最后一层GRU的输出向量(双向的向量加在了一起),shape(max_length, batch_size, hidden_size)
hidden: 最后一个时刻的隐状态,shape是(n_layers x num_directions, batch_size, hidden_size)
EncoderRNN代码如下:
class EncoderRNN(nn.Module):
def __init__(self, hidden_size, embedding, n_layers=1, dropout=0):
super(EncoderRNN, self).__init__()
self.n_layers = n_layers
self.hidden_size = hidden_size
self.embedding = embedding
# Initialize GRU; the input_size and hidden_size params are both set to 'hidden_size'
# because our input size is a word embedding with number of features == hidden_size
self.gru = nn.GRU(hidden_size, hidden_size, n_layers,
dropout=(0 if n_layers == 1 else dropout), bidirectional=True)
def forward(self, input_seq, input_lengths, hidden=None):
# Convert word indexes to embeddings
embedded = self.embedding(input_seq)
# Pack padded batch of sequences for RNN module
packed = nn.utils.rnn.pack_padded_sequence(embedded, input_lengths)
# Forward pass through GRU
outputs, hidden = self.gru(packed, hidden)
# Unpack padding
outputs, _ = nn.utils.rnn.pad_packed_sequence(outputs)
# Sum bidirectional GRU outputs
outputs = outputs[:, :, :self.hidden_size] + outputs[:, : ,self.hidden_size:]
# Return output and final hidden state
return outputs, hidden
Encoder
初始化GRUself.gru = nn.GRU(hidden_size, hidden_size, n_layers,dropout=(0 if n_layers == 1 else dropout), bidirectional=True)
这里input_size和hidden_size 参数都设置成hidden_size,因为我们这里假设embedding层的输出大小是hidden_size
如果只有一层,那么不进行Dropout,否则使用传入的参数dropout进行GRU的Dropout。
forward
输入是(max_length, batch),Embedding之后变成(max_length, batch, hidden_size)
packed因为RNN(GRU)需要知道实际的长度,所以PyTorch提供了一个函数pack_padded_sequence把输入向量和长度pack到一个对象PackedSequence里,这样便于使用。
通过GRU进行forward计算,需要传入输入和隐变量
如果传入的输入是一个Tensor (max_length, batch, hidden_size)
那么输出outputs是(max_length, batch, hidden_size*num_directions)。
第三维是hidden_size和num_directions的混合,它们实际排列顺序是num_directions在前面,因此我们可以:
-
使用
outputs.view(seq_len, batch, num_directions, hidden_size)得到4维的向量。 -
其中第三维是方向,第四位是隐状态。
而如果输入是PackedSequence对象,那么输出outputs也是一个PackedSequence对象,我们需要用函数pad_packed_sequence把它变成一个shape为(max_length, batch, hidden*num_directions)的向量以及一个list,表示输出的长度,当然这个list和输入的input_lengths完全一样,因此通常我们不需要它。
outputs, hidden = self.gru(packed, hidden)得到outputs为(max_length, batch, hidden*num_directions)
outputs, _ = torch.nn.utils.rnn.pad_packed_sequence(outputs):
我们需要把输出的num_directions双向的向量加起来
因为outputs的第三维是先放前向的hidden_size个结果,然后再放后向的hidden_size个结果
所以outputs[:, :, :self.hidden_size]得到前向的结果 outputs[:, :, self.hidden_size:]是后向的结果
注意,如果bidirectional是False,则outputs第三维的大小就是hidden_size,
这时outputs[:, : ,self.hidden_size:]是不存在的,因此也不会加上去。
return outputs, hidden 返回最终的输出和最后时刻的隐状态。
Decoder
Decoder也是一个RNN,它每个时刻输出一个词。每个时刻的输入是上一个时刻的隐状态和上一个时刻的输出。一开始的隐状态是Encoder最后时刻的隐状态,输入是特殊的。然后使用RNN计算新的隐状态和输出第一个词,接着用新的隐状态和第一个词计算第二个词,…,直到遇到,结束输出。普通的RNN Decoder的问题是它只依赖与Encoder最后一个时刻的隐状态,虽然理论上这个隐状态(context向量)可以编码输入句子的语义,但是实际会比较困难。因此当输入句子很长的时候,效果会很长。
为了解决这个问题,Bahdanau等人在论文里提出了注意力机制(attention mechanism),在Decoder进行t时刻计算的时候,除了t-1时刻的隐状态,当前时刻的输入,注意力机制还可以参考Encoder所有时刻的输入。拿机器翻译来说,我们在翻译以句子的第t个词的时候会把注意力机制在某个词上。
当然常见的注意力是一种soft的注意力,假设输入有5个词,注意力可能是一个概率,比如(0.6,0.1,0.1,0.1,0.1),表示当前最关注的是输入的第一个词。同时我们之前也计算出每个时刻的输出向量,假设5个时刻分别是 y 1 , … , y 5 y_1,…,y_5 y1,…,y5,那么我们可以用attention概率加权得到当前时刻的context向量 0.6 y 1 + 0.1 y 2 + … + 0.1 y 5 0.6y_1+0.1y_2+…+0.1y_5 0.6y1+0.1y2+…+0.1y5。
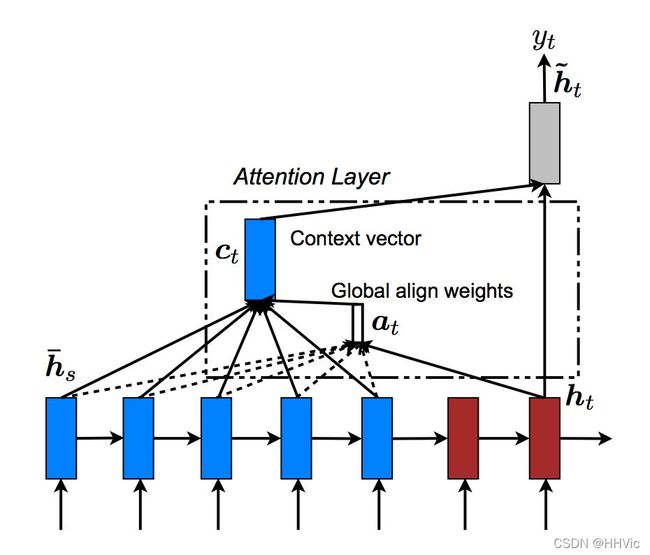
注意力有很多方法计算,我们这里介绍Luong等人在论文提出的方法。它是用当前时刻的GRU计算出的新的隐状态来计算注意力得分,首先它用一个score函数计算这个隐状态和Encoder的输出的相似度得分,得分越大,说明越应该注意这个词。然后再用softmax函数把score变成概率。拿机器翻译为例,在t时刻, h t h_t ht表示t时刻的GRU输出的新的隐状态,我们可以认为 h t h_t ht表示当前需要翻译的语义。通过计算 h t h_t ht与 y 1 , … , y n y_1,…,y_n y1,…,yn的得分,如果 h t h_t ht与 y 1 y_1 y1的得分很高,那么我们可以认为当前主要翻译词 x 1 x_1 x1的语义。有很多中score函数的计算方法,如下图所示:

式中 h t h_t ht表示t时刻的隐状态,比如第一种计算score的方法,直接计算 h t h_t ht与 h s h_s hs的内积,内积越大,说明这两个向量越相似,因此注意力也更多的放到这个词上。第二种方法也类似,只是引入了一个可以学习的矩阵,我们可以认为它先对 h t h_t ht做一个线性变换,然后在与 h s h_s hs计算内积。而第三种方法把它们拼接起来然后用一个全连接网络来计算score。
注意,我们前面介绍的是分别计算 h t h_t ht和 y 1 y_1 y1的内积、 h t h_t ht和 y 2 y_2 y2的内积,…。但是为了效率,可以一次计算 h t h_t ht与 h s = [ y 1 , y 2 , … , y n ] h_s=[y_1,y_2,…,y_n] hs=[y1,y2,…,yn]的乘积。 计算过程如下图所示。
dot_socre
输入hidden的shape是(1, batch=64, hidden_size=500)
encoder_outputs的shape是(input_lengths=10, batch=64, hidden_size=500)
hidden * encoder_output得到的shape是(10, 64, 500),然后对第3维求和就可以计算出score。
forward
输入是上一个时刻的隐状态hidden和所有时刻的Encoder的输出encoder_outputs
输出是注意力的概率,也就是长度为input_lengths的向量,它的和加起来是1。
计算注意力的score,输入hidden的shape是(1, batch=64, hidden_size=500),表示t时刻batch数据的隐状态
encoder_outputs的shape是(input_lengths=10, batch=64, hidden_size=500)
attn_energies = attn_energies.t() 把attn_energies从(max_length=10, batch=64)转置成(64, 10)
F.softmax(attn_energies, dim=1).unsqueeze(1)使用softmax函数把score变成概率,shape仍然是(64, 10),然后用unsqueeze(1)变成 (64, 1, 10)
# Luong attention layer
class Attn(nn.Module):
def __init__(self, method, hidden_size):
super(Attn, self).__init__()
self.method = method
if self.method not in ['dot', 'general', 'concat']:
raise ValueError(self.method, "is not an appropriate attention method.")
self.hidden_size = hidden_size
if self.method == 'general':
self.attn = nn.Linear(self.hidden_size, hidden_size)
elif self.method == 'concat':
self.attn = nn.Linear(self.hidden_size * 2, hidden_size)
self.v = nn.Parameter(torch.FloatTensor(hidden_size))
def dot_score(self, hidden, encoder_output):
return torch.sum(hidden * encoder_output, dim=2)
def general_score(self, hidden, encoder_output):
energy = self.attn(encoder_output)
return torch.sum(hidden * energy, dim=2)
def concat_score(self, hidden, encoder_output):
energy = self.attn(torch.cat((hidden.expand(encoder_output.size(0), -1, -1), encoder_output), 2)).tanh()
return torch.sum(self.v * energy, dim=2)
def forward(self, hidden, encoder_outputs):
# Calculate the attention weights (energies) based on the given method
if self.method == 'general':
attn_energies = self.general_score(hidden, encoder_outputs)
elif self.method == 'concat':
attn_energies = self.concat_score(hidden, encoder_outputs)
elif self.method == 'dot':
attn_energies = self.dot_score(hidden, encoder_outputs)
# Transpose max_length and batch_size dimensions
attn_energies = attn_energies.t()
# Return the softmax normalized probability scores (with added dimension)
return F.softmax(attn_energies, dim=1).unsqueeze(1)
上面的代码实现了dot、general和concat三种score计算方法,分别和前面的三个公式对应,我们这里介绍最简单的dot方法。代码里也有一些注释,只有dot_score函数比较难以理解,我们来分析一下。首先这个函数的输入输入hidden的shape是(1, batch=64, hidden_size=500),encoder_outputs的shape是(input_lengths=10, batch=64, hidden_size=500)。
怎么计算hidden和10个encoder输出向量的内积呢?为了简便,我们先假设batch是1,这样可以把第二维(batch维)去掉,因此hidden是(1, 500),而encoder_outputs是(10, 500)。内积的定义是两个向量对应位相乘然后相加,但是encoder_outputs是10个500维的向量。当然我们可以写一个for循环来计算,但是效率很低。这里用到一个小的技巧,利用broadcasting,hidden * encoder_outputs可以理解为把hidden从(1,500)复制成(10, 500)(当然实际实现并不会这么做),然后两个(10, 500)的矩阵进行乘法。注意,这里的乘法不是矩阵乘法,而是所谓的Hadamard乘法,其实就是把对应位置的乘起来,比如下面的例子:
因此hidden * encoder_outputs就可以把hidden向量(500个数)与encoder_outputs的10个向量(500个数)对应的位置相乘。而内积还需要把这500个乘积加起来,因此后面使用torch.sum(hidden * encoder_output, dim=2),把第2维500个乘积加起来,最终得到10个score值。当然我们实际还有一个batch维度,因此最终得到的attn_energies是(10, 64)。接着在forward函数里把attn_energies转置成(64, 10),然后使用softmax函数把10个score变成概率,shape仍然是(64, 10),为了后面使用方便,我们用unsqueeze(1)把它变成(64, 1, 10)。
有了注意力的子模块之后,我们就可以实现Decoder了。Encoder可以一次把一个序列输入GRU,得到整个序列的输出。但是Decoder t时刻的输入是t-1时刻的输出,在t-1时刻计算完成之前是未知的,因此只能一次处理一个时刻的数据。因此Encoder的GRU的输入是(max_length, batch, hidden_size),而Decoder的输入是(1, batch, hidden_size)。此外Decoder只能利用前面的信息,所以只能使用单向(而不是双向)的GRU,而Encoder的GRU是双向的,如果两种的hidden_size是一样的,则Decoder的隐单元个数少了一半,那怎么把Encoder的最后时刻的隐状态作为Decoder的初始隐状态呢?这里是把每个时刻双向结果加起来的,因此它们的大小就能匹配了(请读者参考前面Encoder双向相加的部分代码)。
计算图:
-
把词ID输入Embedding层
-
使用单向的GRU继续Forward进行一个时刻的计算。
-
使用新的隐状态计算注意力权重
-
用注意力权重得到context向量
-
context向量和GRU的输出拼接起来,然后再进过一个全连接网络,使得输出大小仍然是hidden_size
-
使用一个投影矩阵把输出从hidden_size变成词典大小,然后用softmax变成概率 7) 返回输出和新的隐状态
输入:
input_step: shape是(1, batch_size)
last_hidden: 上一个时刻的隐状态, shape是(n_layers x num_directions, batch_size, hidden_size)
encoder_outputs: encoder的输出, shape是(max_length, batch_size, hidden_size)
输出:
output: 当前时刻输出每个词的概率,shape是(batch_size, voc.num_words)
hidden: 新的隐状态,shape是(n_layers x num_directions, batch_size, hidden_size)
class LuongAttnDecoderRNN(nn.Module):
def __init__(self, attn_model, embedding, hidden_size, output_size, n_layers=1, dropout=0.1):
super(LuongAttnDecoderRNN, self).__init__()
# 保存到self里,attn_model就是前面定义的Attn类的对象。
# Keep for reference
self.attn_model = attn_model
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.dropout = dropout
# Define layers
# 定义Decoder的layers
self.embedding = embedding
self.embedding_dropout = nn.Dropout(dropout)
self.gru = nn.GRU(hidden_size, hidden_size, n_layers, dropout=(0 if n_layers == 1 else dropout))
self.concat = nn.Linear(hidden_size * 2, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.attn = Attn(attn_model, hidden_size)
def forward(self, input_step, last_hidden, encoder_outputs):
# 注意:decoder每一步只能处理一个时刻的数据,因为t时刻计算完了才能计算t+1时刻。
# input_step的shape是(1, 64),64是batch,1是当前输入的词ID(来自上一个时刻的输出)
# 通过embedding层变成(1, 64, 500),然后进行dropout,shape不变。
# Note: we run this one step (word) at a time
# Get embedding of current input word
embedded = self.embedding(input_step)
embedded = self.embedding_dropout(embedded)
# 把embedded传入GRU进行forward计算
# 得到rnn_output的shape是(1, 64, 500)
# hidden是(2, 64, 500),因为是双向的GRU,所以第一维是2。
# Forward through unidirectional GRU
rnn_output, hidden = self.gru(embedded, last_hidden)
# 计算注意力权重, 根据前面的分析,attn_weights的shape是(64, 1, 10)
# Calculate attention weights from the current GRU output
attn_weights = self.attn(rnn_output, encoder_outputs)
# encoder_outputs是(10, 64, 500)
# encoder_outputs.transpose(0, 1)后的shape是(64, 10, 500)
# attn_weights.bmm后是(64, 1, 500)
# bmm是批量的矩阵乘法,第一维是batch,我们可以把attn_weights看成64个(1,10)的矩阵
# 把encoder_outputs.transpose(0, 1)看成64个(10, 500)的矩阵
# 那么bmm就是64个(1, 10)矩阵 x (10, 500)矩阵,最终得到(64, 1, 500)
# Multiply attention weights to encoder outputs to get new "weighted sum" context vector
context = attn_weights.bmm(encoder_outputs.transpose(0, 1))
# 把context向量和GRU的输出拼接起来
# rnn_output从(1, 64, 500)变成(64, 500)
# Concatenate weighted context vector and GRU output using Luong eq. 5
rnn_output = rnn_output.squeeze(0)
# context从(64, 1, 500)变成(64, 500)
context = context.squeeze(1)
# 拼接得到(64, 1000)
concat_input = torch.cat((rnn_output, context), 1)
# self.concat是一个矩阵(1000, 500),
# self.concat(concat_input)的输出是(64, 500)
# 然后用tanh把输出返回变成(-1,1),concat_output的shape是(64, 500)
concat_output = torch.tanh(self.concat(concat_input))
# out是(500, 词典大小=7826)
# Predict next word using Luong eq. 6
output = self.out(concat_output)
# 用softmax变成概率,表示当前时刻输出每个词的概率。
output = F.softmax(output, dim=1)
# 返回 output和新的隐状态
# Return output and final hidden state
return output, hidden