Pandas
系列文章目录
第一章 python数据挖掘基础环境安装和使用
第二章 Matplotlib
第三章 Numpy
文章目录
- 系列文章目录
- 一、介绍
-
- 1.1 为什么用Pandas?
- 1.2 核心数据结构
- 1.3 DataFrame
-
- 1.3.1 结构
- 1.3.2 常用属性
- 1.3.3 常用方法
- 1.3.4 DataFrame索引的设置
-
- 修改行列索引值
- 重设索引 (了解)
- 设置新索引
- 1.3.5 设置新索引案例
-
- 设置多个索引
- 1.4 MultiIndex 与 Panel
-
- MultiIndex
- Panel (Pandas 版本0.20.0 开始弃用)
- 1.5 Series
-
- 属性
- 创建Series
- 二、基本数据操作
-
- 2.1 准备数据
- 2.2 索引操作
-
- 1. 直接索引:直接使用行列索引 (先列后行)
- 2. 按名字索引 loc
- 3. 按数字索引 iloc
- 4. 使用 ix 组合索引 (过时了)
- 2.3 赋值操作
- 2.4 排序操作
-
- 内容排序
- 索引排序
- 三、DataFrame 运算
-
- 算术运算
- 逻辑运算
-
- 1. 逻辑运算符号<、>、| 、&
- 2. 逻辑运算函数
- 统计运算
-
- 累计统计函数
- 自定义运算
- 四、Pandas 画图
-
- pandas.DataFrame.plot
- pandas.Series.plot
- 五、文件读取与存储
-
- CSV
- HDF5
-
- read_hdf() 与 to_hdf()
- JSON
- 六、高级处理-缺失值处理
-
- 如何处理 NaN?
- 不是缺失值 NaN, 有默认标记的
- 七、高级处理-数据离散化
-
- 什么是数据的离散化
- 为什么要离散化 ?
- 如何实现数据的离散化
-
- 案例:股票的涨跌幅离散化
- 八、高级处理-合并
-
- 按方向拼接
- 按索引拼接
- 九、高级处理-交叉表与透视表
-
- 交叉表
- 透视表
- 十、分组与聚合
-
- 案例:星巴克零售店铺数据案例
- 综合案例
一、介绍
Pandas是数据处理工具
-
panel + data + analysis
- panel + data 面板数据 ==> 词来源于计量经济学,金融经济领域经常用到这样的经济结构,这样的数据结构通常用于存储三维的数据。
- analysis 分析

- 2008 年 WesMcKinney 开发出的库
- 专门用于数据挖掘的开源 Python 库
- 以 Numpy 为基础,借力 Numpy 模块在计算方面性能高的优势
- 基于 matplotlib,能够简便的画图
- 独特的数据结构
1.1 为什么用Pandas?
- 便捷的数据处理能力
- 读取文件方便
- 封装了 Matplotlib、Numpy 的画图和计算
1.2 核心数据结构
- DataFrame(Series的容器)
- 带索引的二维数组
- Pannel(DataFrame的容器)
- 带索引的三维数组
- 不提倡使用,了解即可
- Series
- 带索引的一维数组
1.3 DataFrame
1.3.1 结构
- 既有行索引,又有列索引的二维数组
- 行索引,表明不同行,横向索引,叫 index
- 列索引,表明不同列,纵向索引,叫 columns
回忆我们在numpy当中创建的股票涨跌幅数据形式
import numpy as np
stock_change = np.random.normal(loc=0, scale=1, size=(10,5))# 创建一个符合正态分布的10只股票,5天的涨幅数据
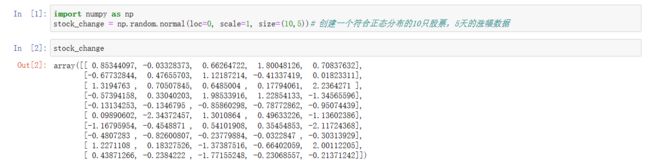
但是这样的数据形式很难看到存储的是什么样的数据,并且也很难获取相应的数据,比如需要获取某个指定股票的数据,就很难去获取!
如何让数据更有意义的显示?
pandas.DataFrame( data, index, columns, dtype, copy)
# 使用Pandas中的数据结构
import pandas as pd
pd.DataFrame(stock_change)
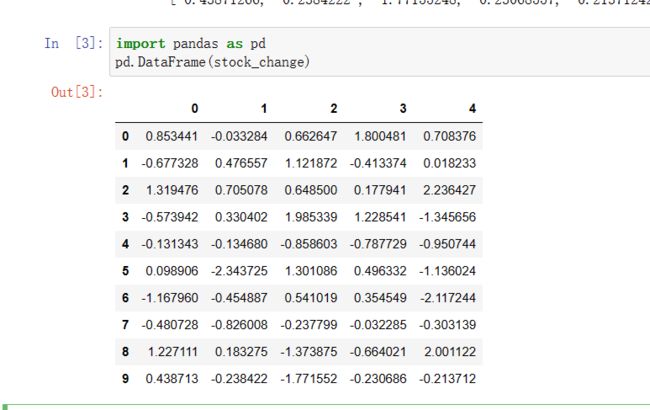
我们可以发现原始的二维数组行和列都是有明显的索引了,但是因为我们没有指定行列索引,它默认生成0到n的索引,现在我们还是不知道这些数据代表什么意思,所以我们需要手动添加行列索引。
给股票涨跌幅数据增加行列索引,显示效果更佳
pandas.DataFrame( data, index, columns, dtype, copy)
- data:一组数据(ndarray、series, map, lists, dict 等类型)。
- index:行索引值,或者可以称为行标签。
- columns:列索引,列标签,默认为 RangeIndex (0, 1, 2, …, n) 。
- dtype:数据类型。
- copy:拷贝数据,默认为 False。
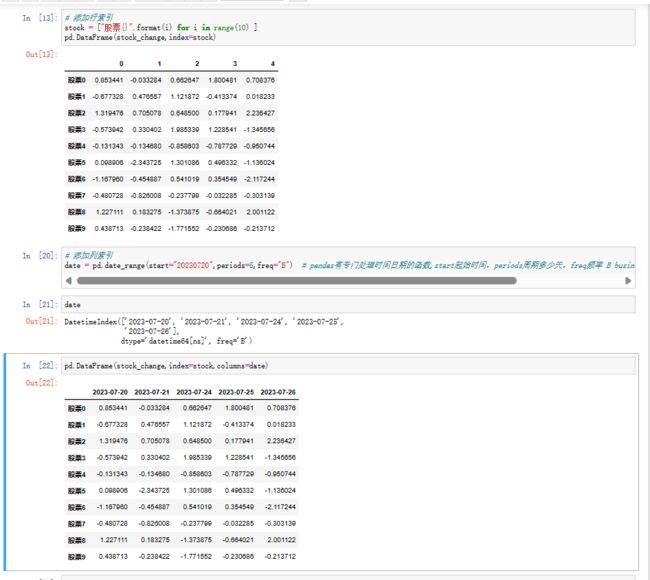
# 添加行索引
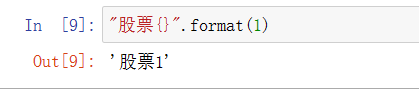
stock = ["股票{}".format(i) for i in range(10) ]
pd.DataFrame(stock_change,index=stock)
# 添加列索引
date = pd.date_range(start="20230720",periods=5,freq="B")
pd.DataFrame(stock_change,index=stock,columns=date)
待格式化字符串.format()函数进行字符串格式化
- pandas有专门处理时间日期的函数
pd.date_range(start="20230720",periods=5,freq="B")
- start起始时间
- periods周期多少天
- freq频率
- B business day frequency 工作日频率
1.3.2 常用属性
跟Numpy学的时候是类似的,我们把DataFrame就可以看成是ndarray外面包了一层行索引和列索引,所以ndarray有的属性它一般也是有的。
-
shape
-
index 行索引列表
-
columns 列索引列表
-
values 直接获取其中 array 的值,把行索引、列索引刨除之后的东西,其实就是刚开始的ndarray
-
T 行列转置
data = pd.DataFrame(stock_change,index=stock,columns=date)
data.shape
data.index
data.columns
data.values
data.T



1.3.3 常用方法
一般用在当我们想看这个数据构成有哪些字段、哪些索引,又不想把整个大表全都显示出来,因为有时候数据量非常大,这时候我们就经常用到DataFrame.head()
-
head()开头几行
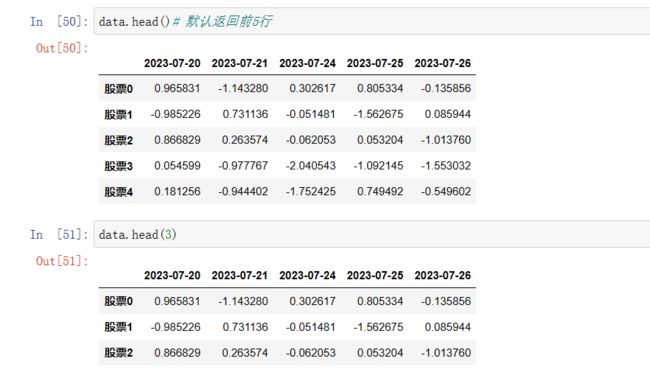
-
tail()最后几行
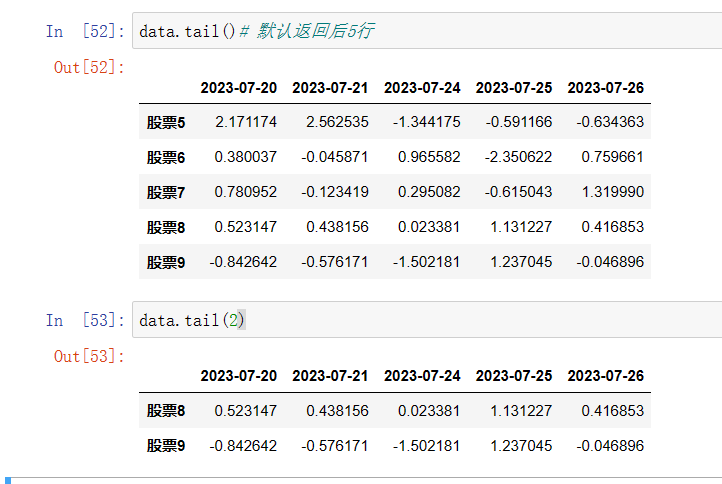
1.3.4 DataFrame索引的设置
修改行列索引值
注意: 以下修改方式是错误的,在DataFrame中你要想改DataFrame.index你只能整体的修改,单独的修改索引是不行的。
# 错误修改方式
data.index[3] = '股票_3'
正确的方式:
stock_code = ["股票_{}".format(i) for i in range(10) ]
data.index = stock_code # 必须整体全部修改
date= pd.date_range(start="2023-07-25",periods=5,freq="B")
data.columns = date
data
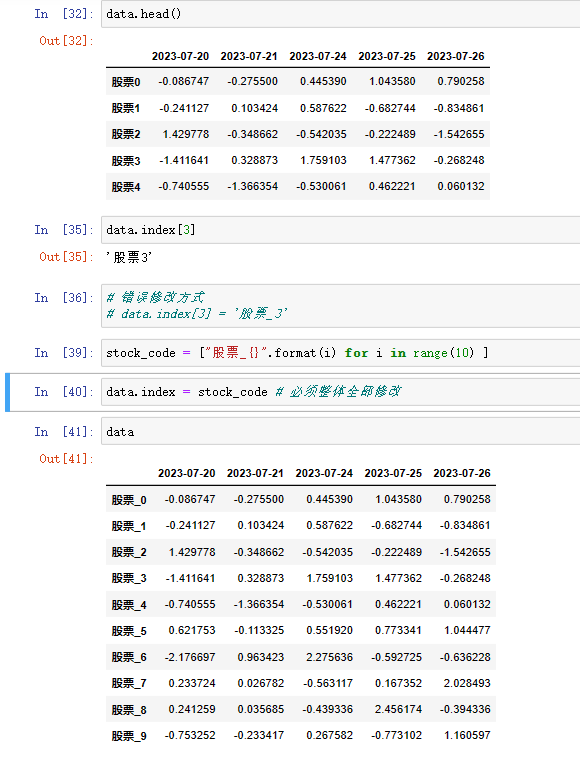

重设索引 (了解)
- reset_index(drop=False)
- 设置新的下标索引
- drop: 默认为False,不删除原来索引,如果为True,删除原来的索引值
data.reset_index()
data.reset_index(drop=True) # drop=True把之前的索引删除
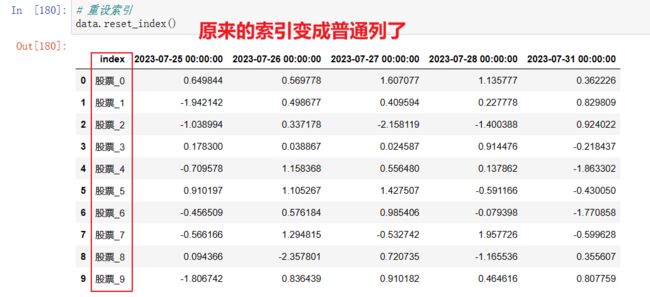
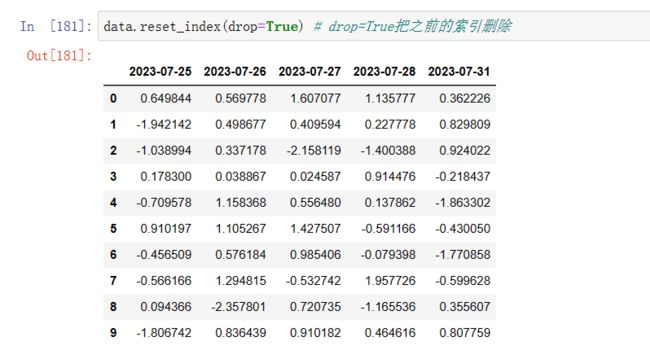
索引 默认都是 0-10 的
设置新索引
- 以某列值设置为新的索引
- set_index( keys, drop=True )
- keys: 列索引名称或者列索引名称的列表
- drop: boolean,default True. 当做新的索引,删除原来的列
- set_index( keys, drop=True )
1.3.5 设置新索引案例
- 创建
其实我们还可以用字典去生成DataFramedf = pd.DataFrame({"month":[1,4,7,10], "year":[2012,2014,2016,2015], "sale":[55,40,84,31]})

- 将月份设置成新的索引
df.set_index("month")
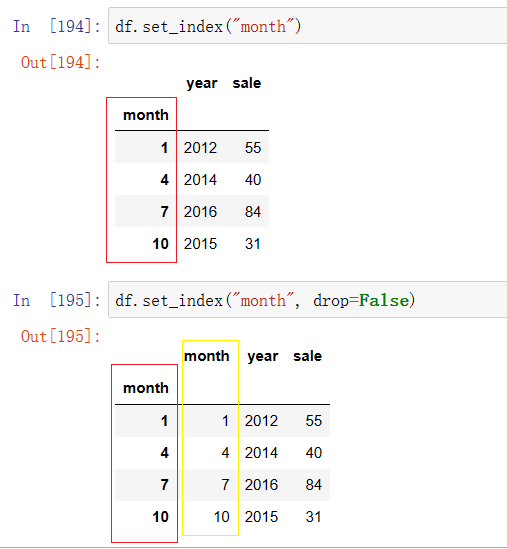
3.设置多个索引,以年和月份
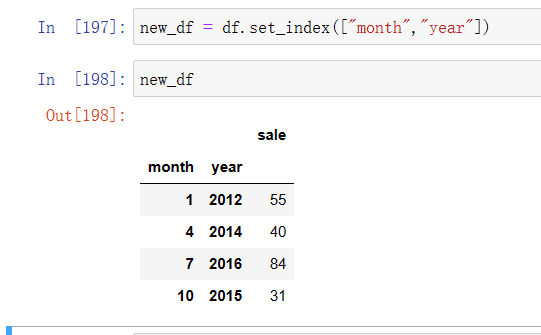
设置多个索引
new_df = df.set_index(["month","year"])
new_df.index

可以看到它的索引结果变成 MultiIndex,带MultiIndex的DataFrame。
1.4 MultiIndex 与 Panel
MultiIndex
多级或分层索引对象。
- index 属性
- names: levels 的名称
- levels: 每个 level 的元组值
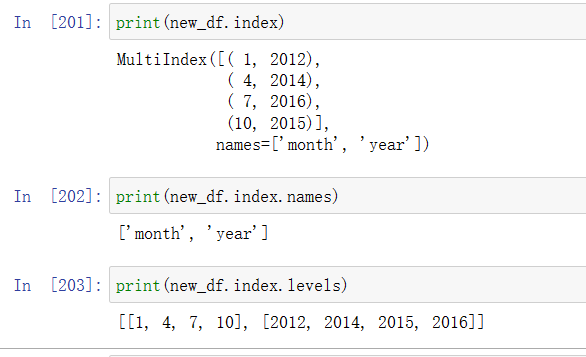
print(new_df.index)
print(new_df.index.names)
print(new_df.index.levels)
Panel (Pandas 版本0.20.0 开始弃用)
- pandas.Panel(data=None,items=None,major_axis=None,minor_axis=None,copy=False,dtype=None)
- 存储 3 维数组的 Panel 结构
- items - axis 0,每个项目对应于内部包含的数据帧(DataFrame)。
- major_axis - axis 1,它是每个数据帧(DataFrame)的索引(行)。
- minor_axis - axis 2,它是每个数据帧(DataFrame)的列。
p = pd.Panel(np.arange(24).reshape(4,3,2),
items=list('ABCD'),
major_axis=pd.date_range('20130101', periods=3),
minor_axis=['first', 'second'])
p["A"]
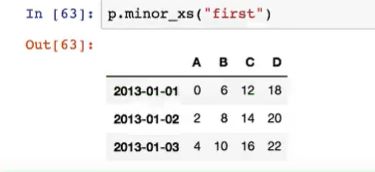
p.major_xs("2013-01-01")
p.minor_xs("first")


注:Pandas 从版本 0.20.0 开始弃用,推荐的用于表示 3D 数据的方法是 DataFrame 上的 MultiIndex 方法
思考:如果获取DataFrame中某个股票的不同时间数据? 这样的结构是什么?
import numpy as np
stock_change = np.random.normal(loc=0, scale=1, size=(10,5))# 创建一个符合正态分布的10只股票,5天的涨幅数据
import pandas as pd
# 添加行索引
stock = ["股票{}".format(i) for i in range(10) ]
pd.DataFrame(stock_change,index=stock)
# 添加列索引
date = pd.date_range(start="20230720",periods=5,freq="B")
data = pd.DataFrame(stock_change,index=stock,columns=date)
data

data.iloc[1,:]
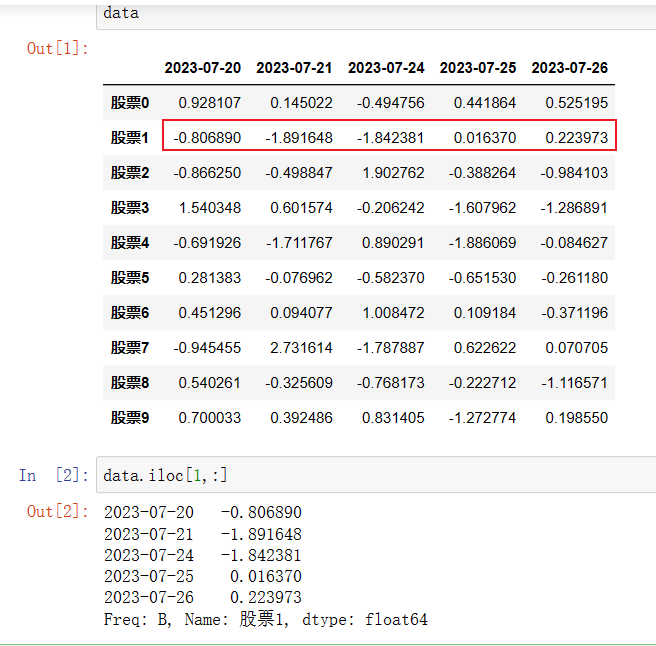
这样获取到的数据,相当于在这样的二维表(data)中,我去抽取了它一行,这样的一个数据,如果我们不要行索引(股票1),它其实就是一个一维数组,这个行索引我们统一的这行就是股票1,它列索引是不还在呀?还有2023-07-20到2023-07-26,所以我们这样的一个结构,我们可以理解成带索引的一维数组,也就是我们Pandas中的第三大数据结构,叫做Series。
1.5 Series
带索引的一维数组
什么是Series结构呢,我们直接看下面的图:

因为它现在是一维的,所以不分行列了,只说带索引的一维数组。
- Series结构只有行索引(你可以把他理解成行索引,因为他是一维的就不分行列了,这里为什么这么说行索引,因为它用index进行表示了)
属性
- index 索引
- values 值
- 一维数组,ndarray类型
sr = data.iloc[1,:]
sr.index
sr.values
type(sr.values)

创建Series
通过已有数据创建
-
指定内容,默认索引
pd.Series(np.arange(10))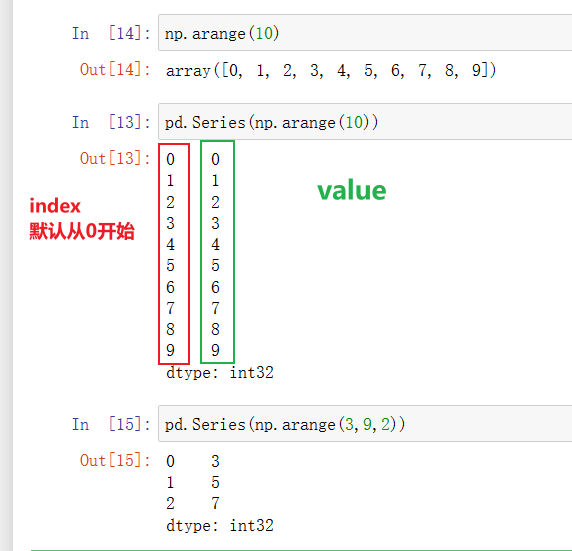
Series默认索引就是从0开始排的
注意:只能传一维的
-
指定索引
pd.Series(np.arange(3,9,2),index=["a1","a2","a3"])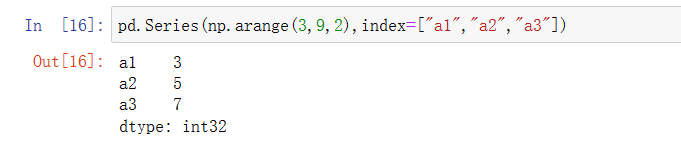
通过字典数据创建
pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000})

自动的将键作为索引,相对应的值作为具体的值。
总结:DataFrame 是 Series 的容器,Panel 是 DataFrame 的容器
二、基本数据操作
2.1 准备数据
为了更好的理解这些基本操作,我们将读取一个真实的股票数据。关于文件操作,后面再介绍,这里只先用一下API
链接:https://pan.baidu.com/s/1JfZdA-gLHvFzoPqcWIhLAA?pwd=6666
提取码:6666

import pandas as pd
# 读取文件
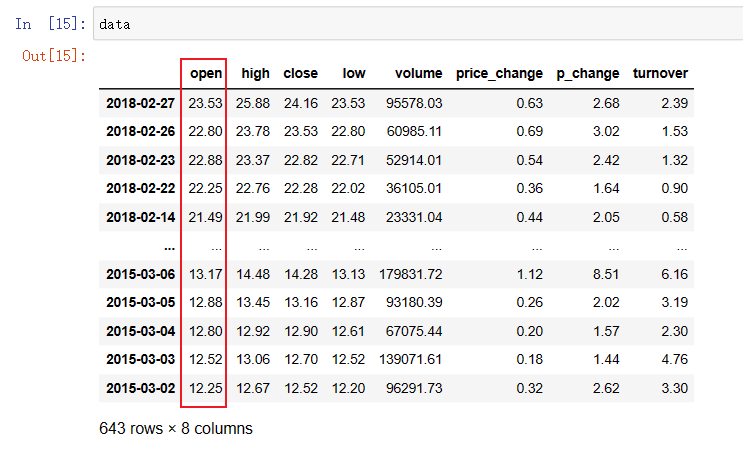
data = pd.read_csv("./stock_day/stock_day.csv")
# 删除一些列,让数据更简单些、再去做后面的操作
data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1)
data

p_change 是每天涨跌幅的情况
2.2 索引操作
Numpy当中我们已经讲过使用索引选取序列和切片选择,pandas也支持类似的操作,也可以直接使用列名、行名称,甚至组合使用。
1. 直接索引:直接使用行列索引 (先列后行)
# data[0,1] # 报错:不能直接进行数字索引
data["open"]["2018-02-26"]# 必须先列后行
# data["2018-02-26"]["open"]# 报错:要先列后行

结合loc或者iloc使用索引
2. 按名字索引 loc
data.loc["2018-02-26"]["open"] # 按名字索引
data.loc["2018-02-26", "open"]

3. 按数字索引 iloc
data.iloc[1, 0] # 数字索引
# 结果:22.8
如果我既想用到名字索引又想用到数字索引,怎么办呢?
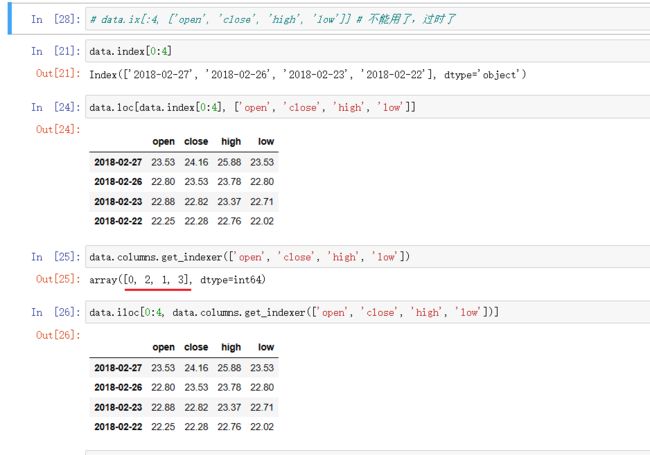
4. 使用 ix 组合索引 (过时了)
# 组合索引
# 获取行第1天到第4天,['open', 'close', 'high', 'low']这个四个指标的结果
# data.ix[:4, ['open', 'close', 'high', 'low']] # 不能用了,过时了
data.loc[data.index[0:4], ['open', 'close', 'high', 'low']]
data.iloc[0:4, data.columns.get_indexer(['open', 'close', 'high', 'low'])]
2.3 赋值操作
可以用四种索引操作方法进行赋值操作
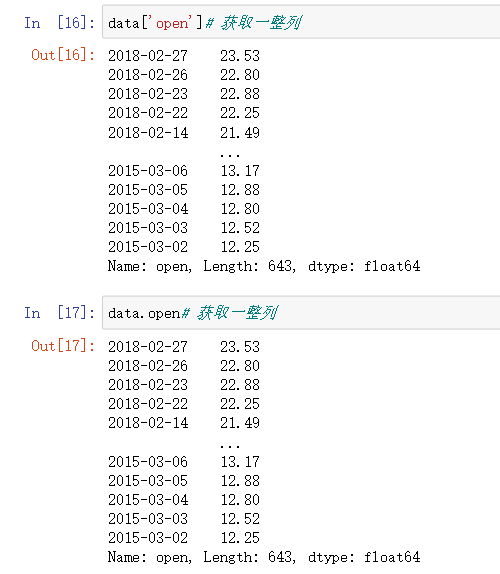
data['open']# 获取一整列
data.open# 获取一整列
data.open = 100 # 整个open列给他赋值100
data
data.iloc[1, 0] = 222 # 第2行第1列给他赋值222
data


2.4 排序操作
排序有两种形式,一种对内容进行排序,一种对索引进行排序。
既可以对DataFrame又可以对Series进行排序。
内容排序
- 使用
df.sort_values(by=,ascending=)对内容进行排序- 单个键或者多个键进行排序,默认升序
- ascending=False:降序 True:升序
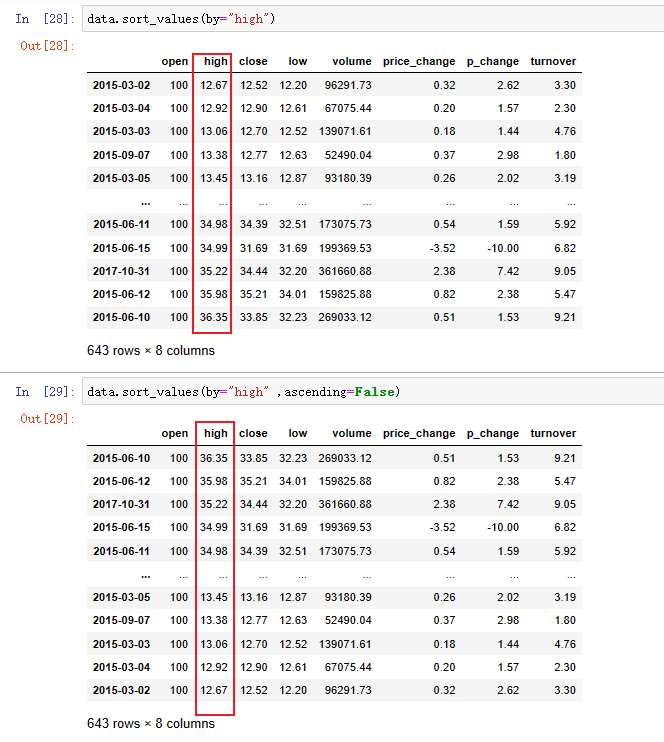
data.sort_values(by="high")
data.sort_values(by="high" ,ascending=False)
data.sort_values(by=["high", "p_change"], ascending=False)
data.sort_values(by=["high", "p_change"], ascending=False).head() # 多个列内容排序

索引排序
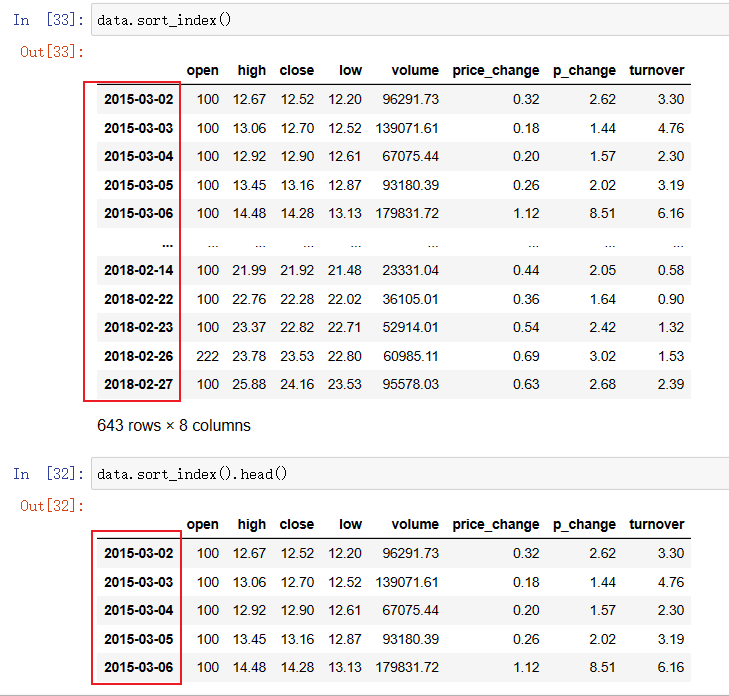
使用 df.sort_index 对索引进行排序
这个股票的日期索引原来是从大到小,现在重新排序,从小到大
data.sort_index()
data.sort_index().head()
Series 排序 跟 DataFrame一样
- series.sort_values(ascending=True)
- series本来只有一维,可以不用指定字段就进行排序了
- series.sort_index()
sr = data["price_change"] sr.sort_values(ascending=False).head() sr.sort_index().head()

三、DataFrame 运算
Series也是类似的
算术运算
- 算数运算符
- DataFrame + - * / 数
- 算数运算函数
- add(other) 加
- sub(other) 减
(data["open"] + 3).head() # 算数运算符
data["open"].add(3).head() # open统一加3 data["open"] + 3
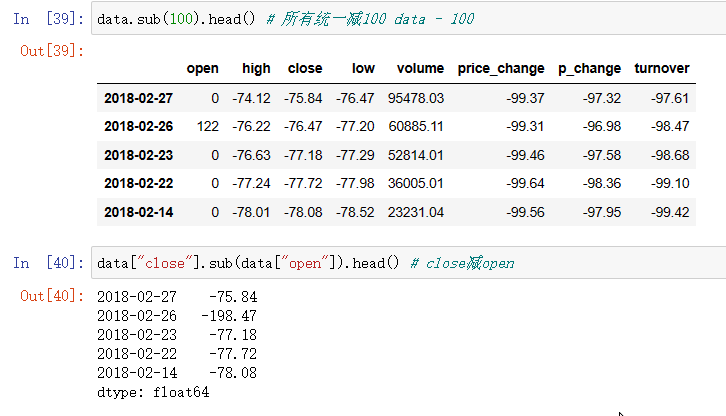
data.sub(100).head() # 所有统一减100 data - 100
data["close"].sub(data["open"]).head() # close减open
逻辑运算
1. 逻辑运算符号<、>、| 、&
例如筛选p_change > 2 的日期数据
data['p_change'] > 2
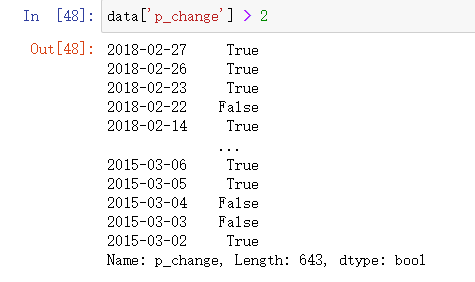
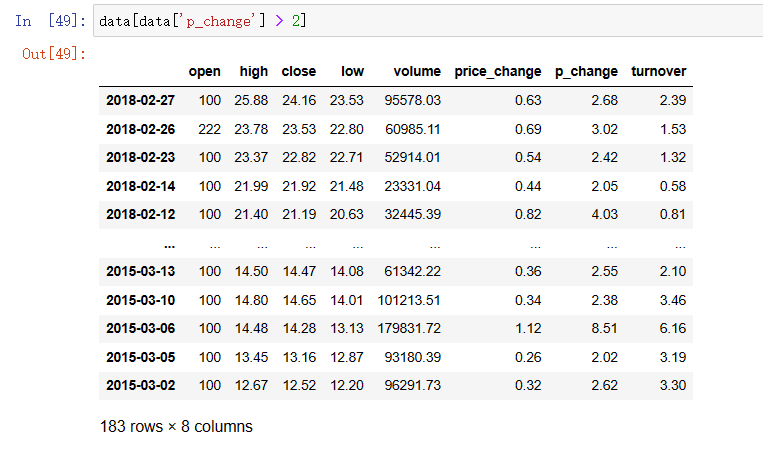
跟Numpy一样也是返回一组布尔值,只不过不一样的是他是返回的是Series,他是带索引的布尔值。也能像Numpy一样可以做布尔索引。
data[data['p_change'] > 2]
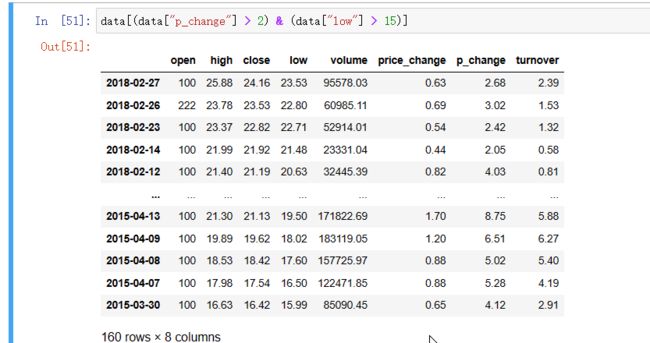
完成一个多个逻辑判断,筛选p_change >2并且low >15
data[(data["p_change"] > 2) & (data["low"] > 15)]
2. 逻辑运算函数
query(expr)- expr:查询字符串
- 返回DataFrame
isin(values)- 判断是否为 values
- 返回一组布尔值
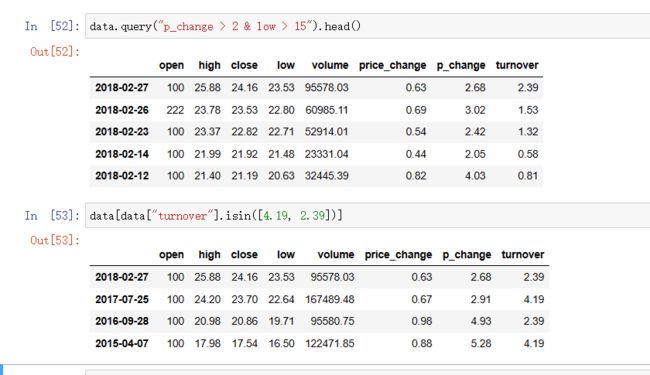
data.query("p_change > 2 & low > 15").head()
data[data["turnover"].isin([4.19, 2.39])] # 判断'turnover'是否为 4.19, 2.39
统计运算
describe()
综合分析:能够直接得出很多统计结果,count 计数, mean平均值, std标准差, min最小值, max最大值, var方差, std 标准差, median 中位数, sum 求和,idxmax 求出最大值位置, idxmin 求出最小值位置 等
data.describe()
data.max()
data.max(axis=0)# 默认axis=0按列求最大值,=1就是按行求
data.idxmax(axis=0) #最大值位置
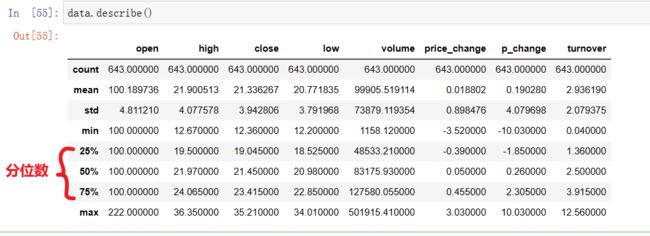
分位数:就是你把一组数据从小到大排列,分成四份,在第25%的位置的数就是25%分位数。50%就是中位数。


累计统计函数
| 函数 | 作用 |
|---|---|
| cumsum | 计算前 1/2/3/…/n 个数的和 |
| cummax | 计算前 1/2/3/…/n 个数的最大值 |
| cummin | 计算前 1/2/3/…/n 个数的最小值 |
| cumprod | 计算前 1/2/3/…/n 个数的积 |
| 举个例子:假设a= [1, 2, 3, 4, 5, 6, 7], cumsum 之后得到的结果是[ 1, 3, 6, 10, 15, 21, 28] |
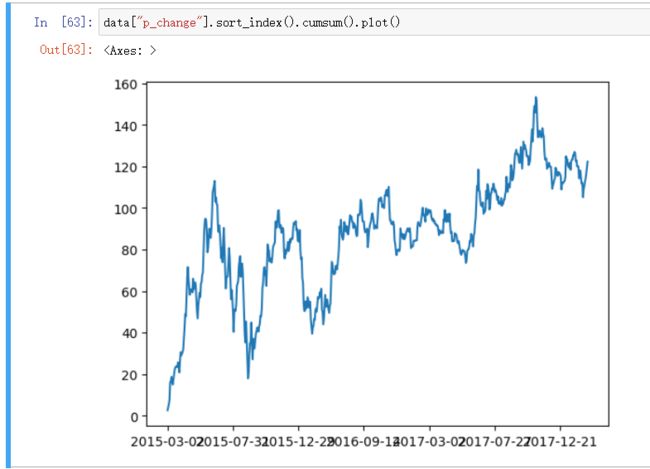
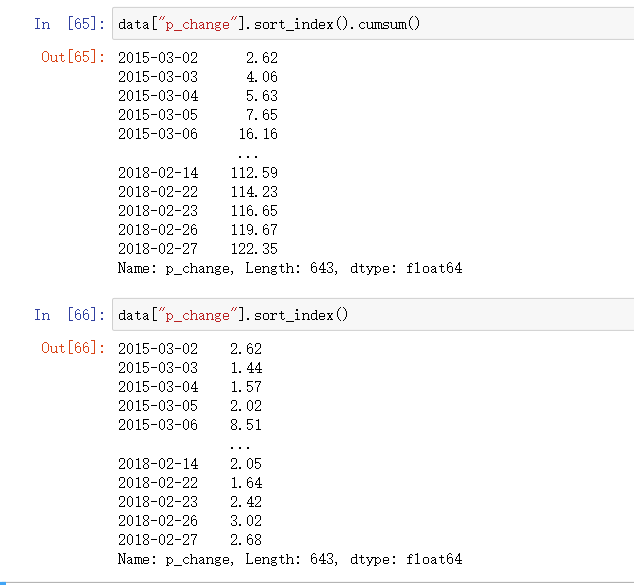
data["p_change"].sort_index().cumsum()
data["p_change"].sort_index().cumsum().plot()
自定义运算
- df.apply(func, axis=0)
- func: 自定义函数
- axis=0: 默认按列运算,axis=1 按行运算
定义一个队列,最大值-最小值的函数
data.apply(lambda x: x.max() - x.min())

四、Pandas 画图
pandas.DataFrame.plot
- DataFrame.plot(x=None, y=None, kind=‘line’)
- x: label or position, default None
- y: label, position or list of label, positions, default None
- Allows plotting of one column versus another
- kind: str 图的类型
- ‘line’: line plot(default) 折线图
- ''bar": vertical bar plot 柱状图
- “barh”: horizontal bar plot 二维水平直方图;水平条图;水平柱图
- “hist”: histogram 直方图
- “pie”: pie plot 饼图
- “scatter”: scatter plot 散点图
data.plot(x="volume", y="turnover", kind="scatter")
data.plot(x="high", y="low", kind="scatter")
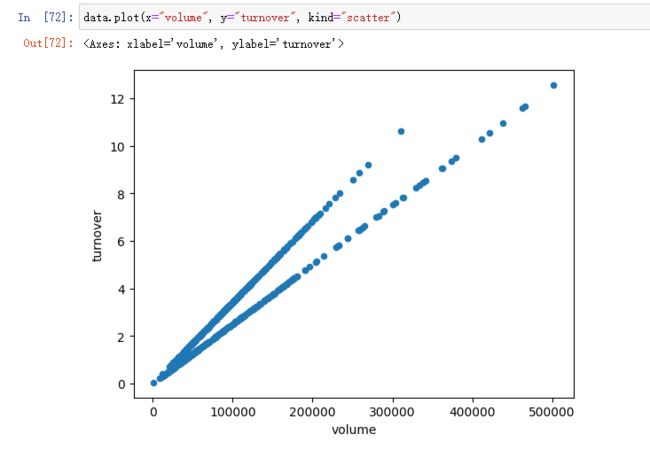
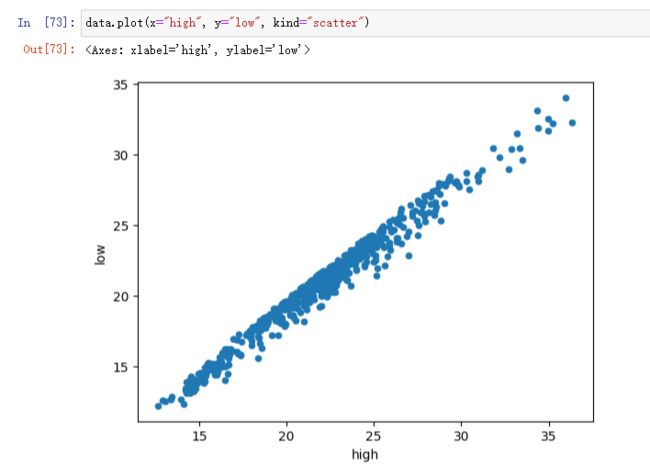
更多参数细节:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.plot.html
pandas.Series.plot
sr.plot(kind="line")
五、文件读取与存储
准备数据:
链接:https://pan.baidu.com/s/1JfZdA-gLHvFzoPqcWIhLAA?pwd=6666
提取码:6666
CSV
读取csv文件
- pandas.read_csv(filepath_or_buffer, sep=‘,’, delimiter = None)
- filepath_or_buffer: 文件路径
- usecols:指定读取的列名,列表形式
- names: 设置列名
import pandas as pd
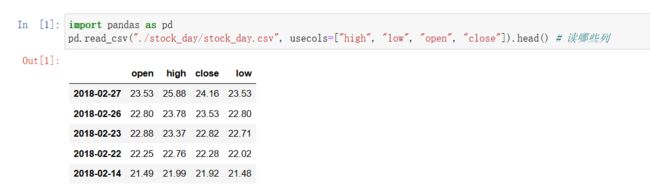
pd.read_csv("./stock_day/stock_day.csv", usecols=["high", "low", "open", "close"]).head() # 读哪些列
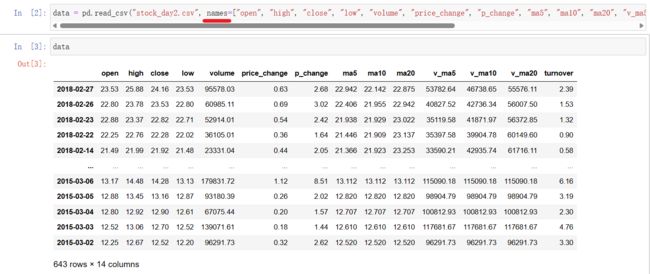
data = pd.read_csv("stock_day2.csv", names=["open", "high", "close", "low", "volume", "price_change", "p_change", "ma5", "ma10", "ma20", "v_ma5", "v_ma10", "v_ma20", "turnover"]) # 如果列没有列名,用names传入
data

写入csv文件

案例
- 保存’open’列的数据 columns=[“open”]
# 选取10行数据保存,便于观察数据
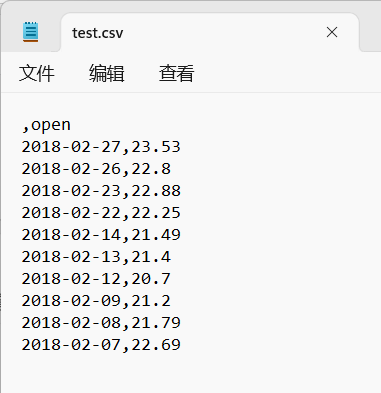
data[:10].to_csv("test.csv", columns=["open"]) # 保存open列数据
-
读取,查看结果
pd.read_csv("test.csv")
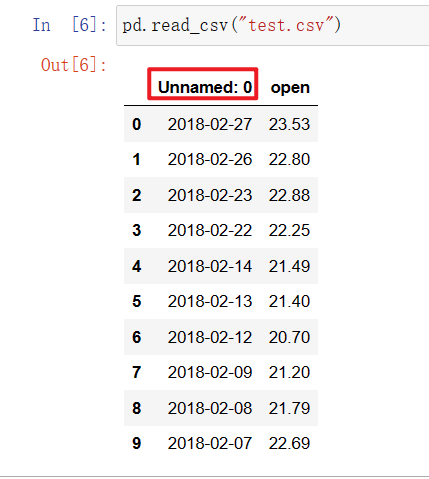
我们发现第一列字段名Unnamed: 0 ,因为它在读取的时候,我们也没有给它names参数,而数据里前面的字段也是空的,所以就直接给了个Unnamed: 0 。
如果我们不想要这个索引列的话,怎么办?我们在保存的时候, 其实就可以设置一个参数,就是index可以设置成False,不要行索引。
data[:10].to_csv("test.csv", columns=["open"], index=False)

mode="a"追加模式|mode="w"重写
header=False不要列索引,防止追加的时候把列索引加进去
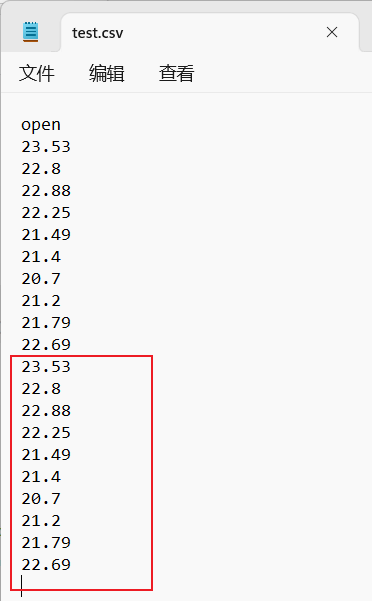
data[:10].to_csv("test.csv", columns=["open"], index=False, mode="a", header=False) # 保存opend列数据,index=False不要行索引,
# mode="a"追加模式|mode="w"重写,
# header=False不要列索引,防止追加的时候把列索引加进去
HDF5
hdf5文件不像csv可以直接去看,hdf5是一个二进制文件。
优先选择使用HDF5文件存储
- HDF5在存储的是支持压缩,使用的方式是blosc,这个是速度最快的也是pandas默认支持的
- 使用压缩可以提高磁盘利用率,节省空间
- HDF5还是跨平台的,可以轻松迁移到hadoop 上面
read_hdf() 与 to_hdf()
HDF5 文件的读取和存储需要指定一个键,值为要存储的 DataFrame
可以这么理解: hdf5 存储 三维数据的文件
key1 dataframe1二维数据
key2 dataframe2二维数据
pandas.read_hdf(path_or_buf, key=None, **kwargs)
从 h5 文件当中读取数据- path_or_buffer: 文件路径
- key: 读取的键
- mode: 打开文件的模式
- reurn: The Selected object
DataFrame.to_hdf(path_or_buf, key, **kwargs)
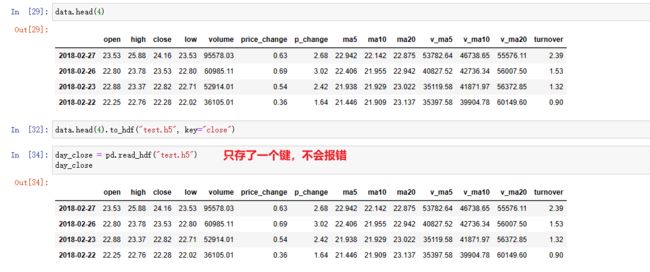
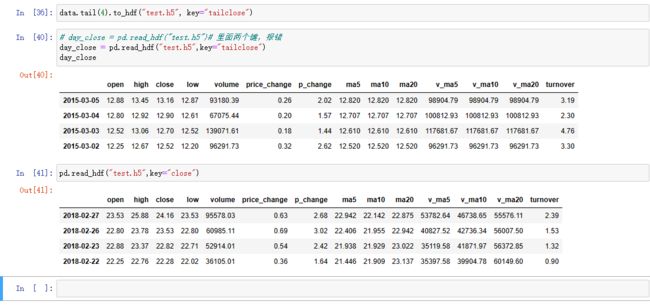
data.head(4).to_hdf("test.h5", key="close")
day_close = pd.read_hdf("test.h5") # 当只有一个键的时候,可以查出来,不会报错
data.tail(4).to_hdf("test.h5", key="tailclose")
# day_close = pd.read_hdf("test.h5")# 里面两个键,报错
day_close = pd.read_hdf("test.h5",key="tailclose")
JSON
Json是我们常用的一种数据交换格式,前面在前后端的交互经常用到,也会在存储的时候选择这种格式。所以我们需要知道Pandas如何进行读取和存储JSON格式。
read_json()
pandas.read_json(path_or_buf=None,orient=None,typ="frame",lines=False)- 将 JSON 格式转换成默认的 Pandas DataFrame 格式
orient: string,Indication of expected JSON string format. 告诉API读取进来的JSON以怎样的格式进行展示- ‘split’: dict like {index -> [index], columns -> [columns], data -> [values]}
- ‘records’: list like [{column -> value}, …, {column -> value}]
- ‘index’: dict like {index -> {column -> value}}
- ‘columns’: dict like {column -> {index -> value}}, 默认该格式
- ‘values’: just the values array
lines: boolean, default False- 是否按照每行读取 json 对象
- 一般写True
- typ: default ‘frame’,指定转换成的对象类型 series 或者 dataframe
DataFrame.to_json(path_or_buf=None,orient=None,lines=False)- 将DataFrame对象存储为 json 格式
- 参数是跟read_json一样的
- path_or_buf 文件地址
- orient 存储的 json 形式
- lines一个对象存储为一行
sa = pd.read_json("Sarcasm_Headlines_Dataset.json", orient="records", lines=True)
sa.to_json("test.json", orient="records")
sa.to_json("test.json", orient="records", lines=True)
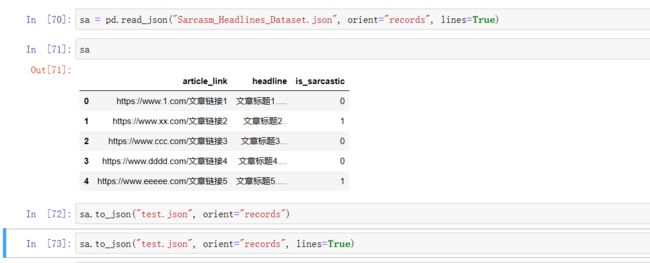
没有指定lines=True,那么他就没有以这个行为一个样本,换行下来,他是形成了中括号包着一层一层的样本还用逗号分割。看起来比较乱


六、高级处理-缺失值处理
如何处理缺失值
两种思路:
- 直接删除含有缺失值的样本(那一行或者那一列)
- 替换/插补 (补入平均值或中位数)
如何处理 NaN?
NaN是float类型
- 判断是否有 NaN
pd.isnull(df)pd.notnull(df)
- 删除含有缺失值的样本
df.dropna(inplace=True)默认按行删除 inplace:True 修改原数据,False 返回新数据,默认 False
- 替换/插补数据
df.fillna(value,inplace=True)value 替换的值 inplace:True 修改原数据,False 返回新数据,默认 False
import pandas as pd
import numpy as np
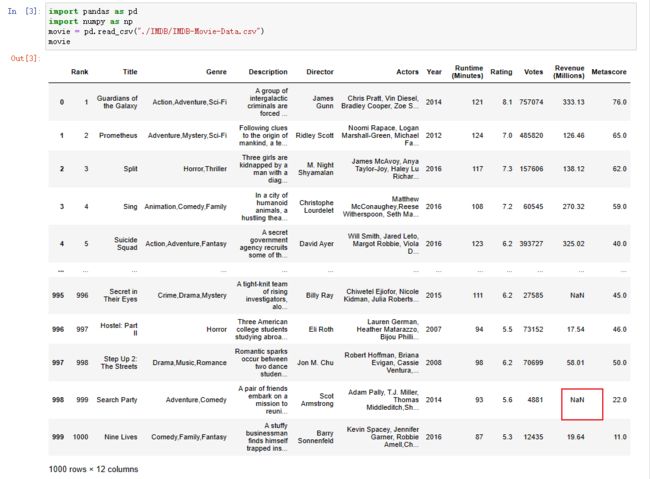
movie = pd.read_csv("./IMDB/IMDB-Movie-Data.csv")
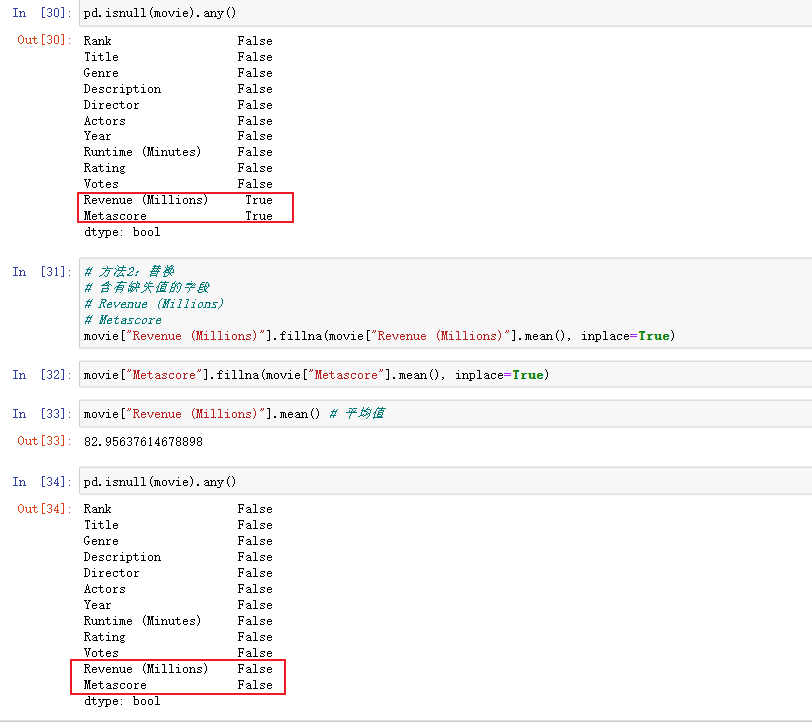
# 1)判断是否存在NaN类型的缺失值
np.any(pd.isnull(movie)) # 返回True,说明数据中存在缺失值
np.all(pd.notnull(movie)) # 返回False,说明数据中存在缺失值
pd.isnull(movie).any()
pd.notnull(movie).all()
# 2)缺失值处理
# 方法1:删除含有缺失值的样本
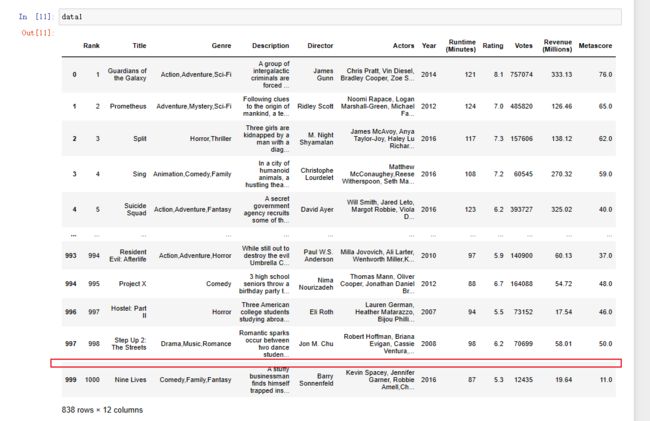
data1 = movie.dropna()
pd.notnull(data1).all()
# 方法2:替换
# 含有缺失值的字段
# Revenue (Millions)
# Metascore
movie["Revenue (Millions)"].fillna(movie["Revenue (Millions)"].mean(), inplace=True)
movie["Metascore"].fillna(movie["Metascore"].mean(), inplace=True)
movie["Revenue (Millions)"].mean() # 平均值


numpy.nan 就是 NaN
不是缺失值 NaN, 有默认标记的
遇到数据这样的:
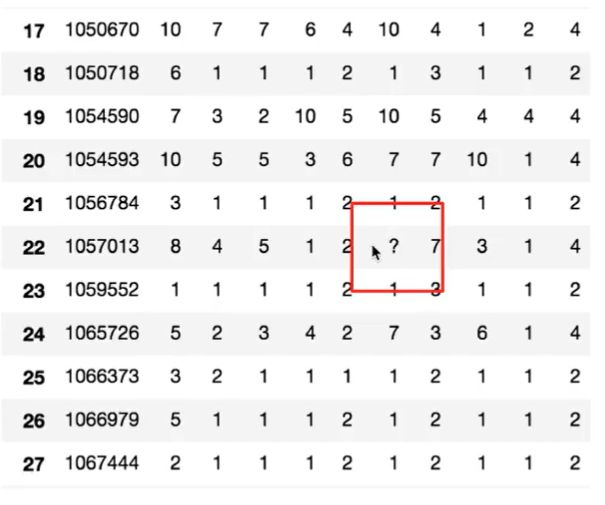
df.replace(to_replace=, value=)- to_replace: 替换前的值
- value:替换后的值
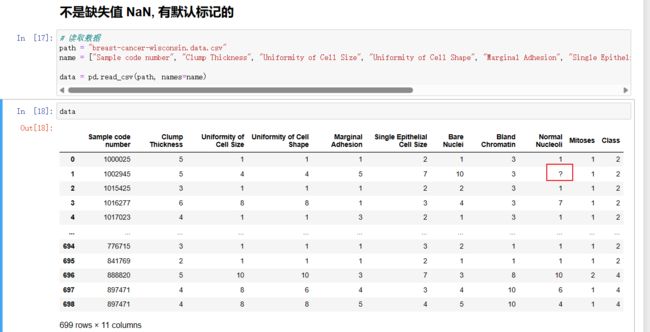
# 读取数据
path = "breast-cancer-wisconsin.data.csv"
name = ["Sample code number", "Clump Thickness", "Uniformity of Cell Size", "Uniformity of Cell Shape", "Marginal Adhesion", "Single Epithelial Cell Size", "Bare Nuclei", "Bland Chromatin", "Normal Nucleoli", "Mitoses", "Class"]
data = pd.read_csv(path, names=name)
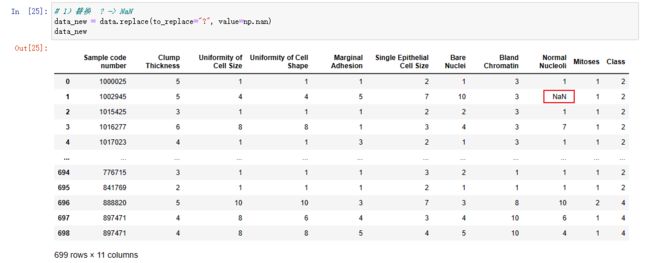
# 1)替换 ? -> NaN
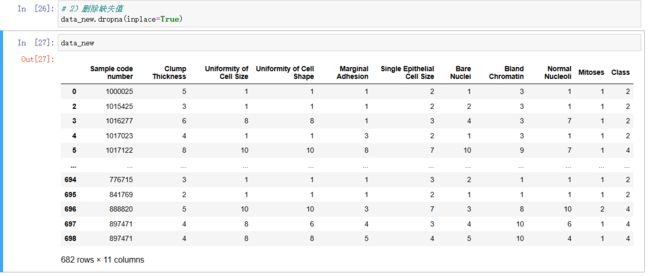
data_new = data.replace(to_replace="?", value=np.nan)
# 2)删除缺失值
data_new.dropna(inplace=True)
处理问号
七、高级处理-数据离散化
什么是数据的离散化
连续属性的离散化就是将连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间的属性值。

这种表示方法就叫做数据的离散化,这种表示形式叫做one-hot编码,也叫哑变量。
为什么要离散化 ?
连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数。离散化方法经常作为数据挖掘的工具。
如何实现数据的离散化
- 分组
- 自动分组 sr =
pd.qcut(data, bins)- bins 分几组
- 自定义分组 sr =
pd.cut(data, [])- sr 是 Series
- [] 自定义区间,例如[150, 165, 180, 195]
都是左开右闭区间
- 将分组好的结果转换成 one-hot 编码(哑变量)
pd.get_dummies(sr, prefix=)- prefix前缀
如果想看 Series每个区间段都有几个样本
sr.value_counts()看每一组分组情况
# 1)准备数据
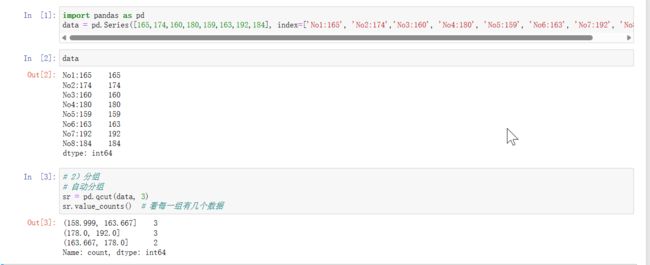
data = pd.Series([165,174,160,180,159,163,192,184], index=['No1:165', 'No2:174','No3:160', 'No4:180', 'No5:159', 'No6:163', 'No7:192', 'No8:184'])
# 2)分组
# 自动分组
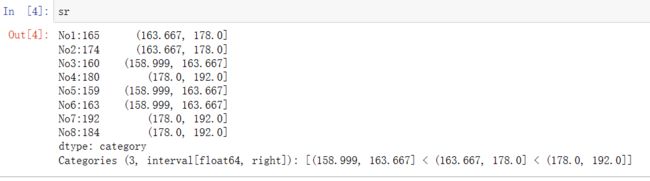
sr = pd.qcut(data, 3)
sr.value_counts() # 看每一组有几个数据
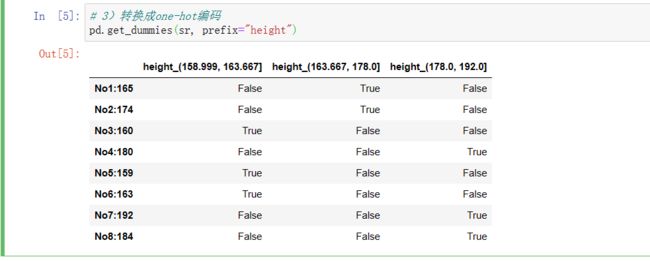
# 3)转换成one-hot编码
pd.get_dummies(sr, prefix="height")
# 自定义分组
bins = [150, 165, 180, 195]
sr = pd.cut(data, bins)
# get_dummies
pd.get_dummies(sr, prefix="身高")


案例:股票的涨跌幅离散化
需求:我们对股票每日的"p_change"进行离散化
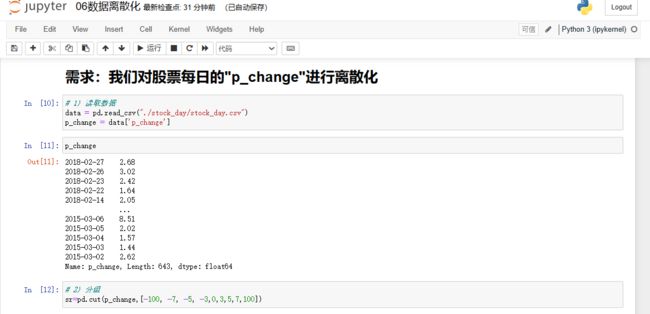
# 1) 读取数据
data = pd.read_csv("./stock_day/stock_day.csv")
p_change = data['p_change']
# 2) 分组
sr=pd.cut(p_change,[-100, -7, -5, -3,0,3,5,7,100])
# 3) 离散化
pd.get_dummies(sr,prefix="涨跌幅")

八、高级处理-合并
按方向拼接
pd.concat([data1, data2], axis=1)- axis:0 为列索引;1 为行索引
准备数据:
import pandas as pd
data = pd.read_csv("./stock_day/stock_day.csv")
p_change = data['p_change']
sr=pd.cut(p_change,[-100, -7, -5, -3,0,3,5,7,100])
data_change = pd.get_dummies(sr,prefix="涨跌幅")
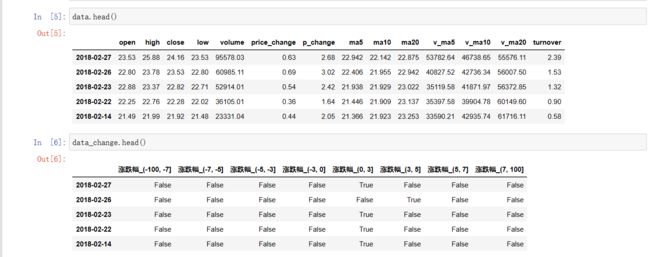
拼接:
pd.concat([data,data_change],axis=1)# 水平拼接
pd.concat([data,data_change],axis=0)# 竖直拼接会怎么样

注意这两个表都是有行列索引的,如果把他们进行竖直拼接,他们这个列索引是不一致的,遇到这种情况竖直拼接,会保留所有字段,但是没有数据的字段会标记成NaN。

按索引拼接
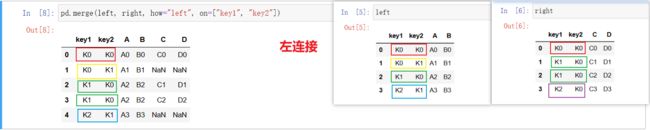
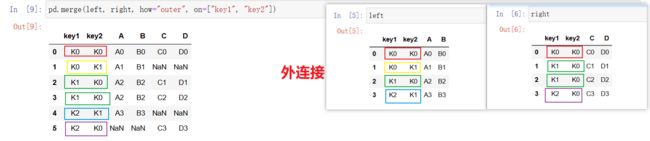
pd.merge(left, right, how="inner", on=[索引] )- left:左表
- right:右表
- how:如何合并
- 默认 “inner” 内连接,用的最多
- left
- right
- outer
- on:按哪一个索引进行拼接
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
pd.merge(left, right, how="inner", on=["key1", "key2"])
pd.merge(left, right, how="left", on=["key1", "key2"])
pd.merge(left, right, how="right", on=["key1", "key2"])
pd.merge(left, right, how="outer", on=["key1", "key2"])
内连接:保留共有的键,不共有的键就不合并到一起。

左连接:左表的key1、key2都是要保留下来的,右表不需要都保留,只以左表为主
右连接:右表的key1、key2都是要保留下来的,左表不需要都保留,只以右表为主

外连接:两个表的key1、key2都要保留下来,如果遇到没有数据,用缺失值NaN
参数还有很多

九、高级处理-交叉表与透视表
作用:找到、探索两个变量之间的关系
交叉表
交叉表用于计算一列数据对于另外一列数据的分组个数(寻找两个列之间的关系)
pd.crosstab(value1, value2)
import pandas as pd
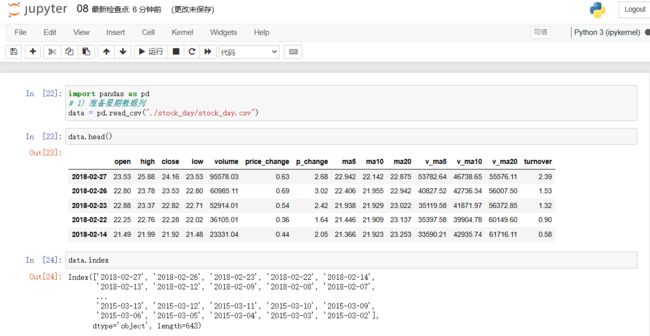
# 1) 准备星期数据列
data = pd.read_csv("./stock_day/stock_day.csv")
date = pd.to_datetime(data.index)
data["week"]=date.weekday
# 2) 准备涨跌幅数据列
import numpy as np
data["pona"] = np.where(data["p_change"] > 0,1,0)
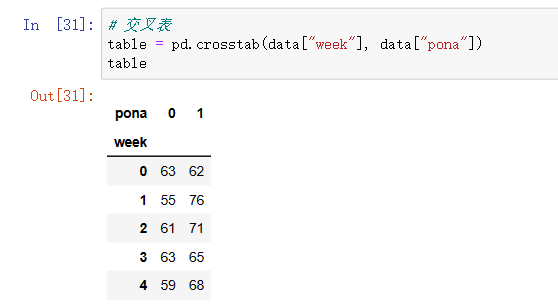
# 交叉表
table = pd.crosstab(data["week"], data["pona"])
table
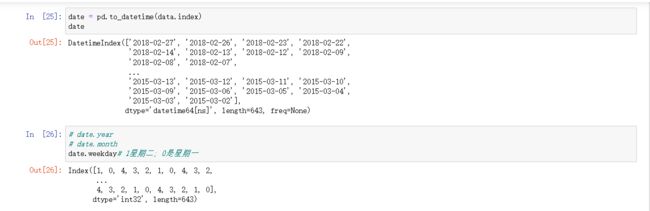
pandas 专门用于处理日期的API,
date = pd.to_datetime(value)
date.year
date.month
date.weekday 1星期二; 0是星期一

这里显示的是频数,如果我想弄成百分比怎么办?
DataFrame.sum(axis=)函数返回所有数值的总和
- axis: {竖直(0),水平(1)}

DataFrame1.div(value,axis=)
- DataFrame1/value 相除
- axis: {竖直(0),水平(1)}
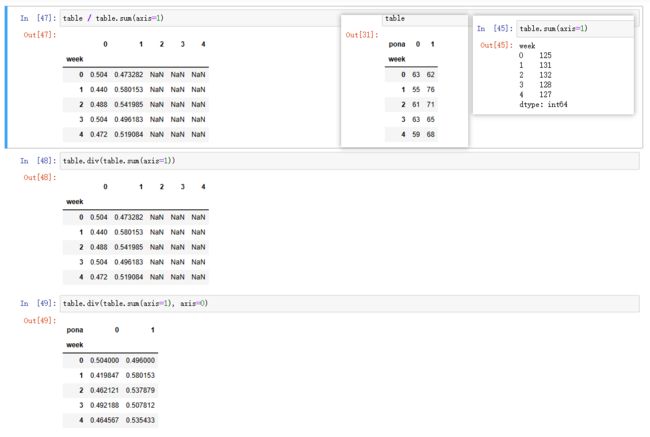
table.div(table.sum(axis=1), axis=0)
table.div(table.sum(axis=1), axis=0).plot(kind="bar", stacked=True)

透视表
得到的是比例
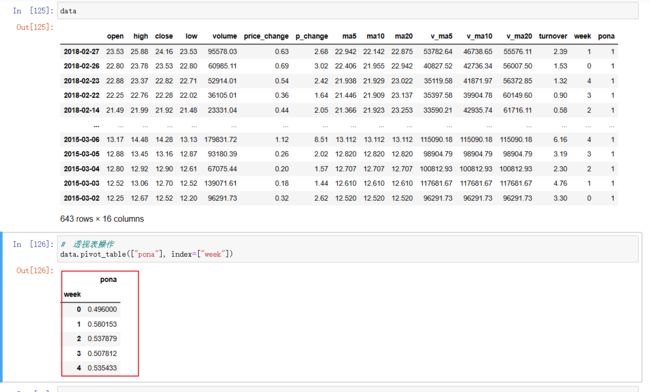
DataFrame.pivot_table([], index=[])
# 透视表操作
table.pivot_table(["pona"], index=["week"])
用透视表能直接出比例的结果
交叉表算出来的比例:

透视表得到的比例是:pona字段是1(涨)的比例
十、分组与聚合
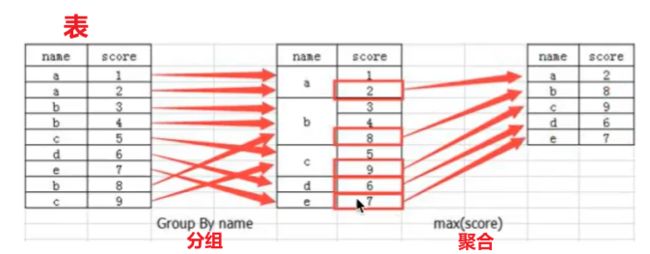
分组与聚合通常是分析数据的一种方式,通常与一些统计函数一起使用,查看数据的分组情况。
DataFrame.groupby(key, as_index=False)
- key:分组的列数据,可以多个
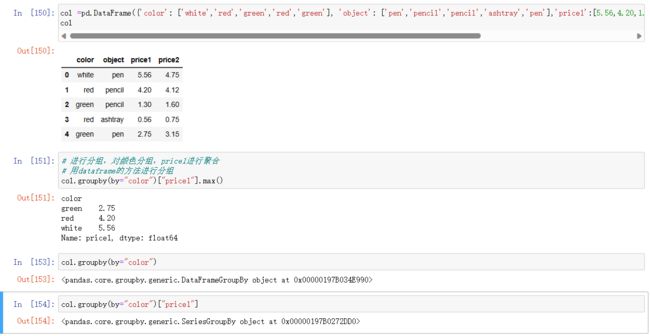
案例: 不同颜色的不同笔的价格数据
col =pd.DataFrame({'color': ['white','red','green','red','green'], 'object': ['pen','pencil','pencil','ashtray','pen'],'price1':[5.56,4.20,1.30,0.56,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]})
# 进行分组,对颜色分组,price1进行聚合
# 用dataframe的方法进行分组
col.groupby(by="color")["price1"].max()
# 或者用Series的方法进行分组聚合
col["price1"].groupby(col["color"]).max()

案例:星巴克零售店铺数据案例
现在我们有一组关于全球星巴克店铺的统计数据,如果我想知道美国的星巴克数量和中国的哪个多,或者我想知道中国每个省份星巴克的数量的情况,那么应该怎么办?
import pandas as pd
# 准备数据
starbucks = pd.read_csv("directory.csv")
# 按照国家分组,求出每个国家的星巴克零售店数量
starbucks.groupby(by="Country")
starbucks.groupby(by="Country").count()
starbucks.groupby(by="Country").count()["Brand"]# 其实哪个字段都可以,我用Brand来当每个国家的星巴克零售店数量
starbucks.groupby(by="Country").count()["Brand"].plot(kind="bar",figsize=(20,8))
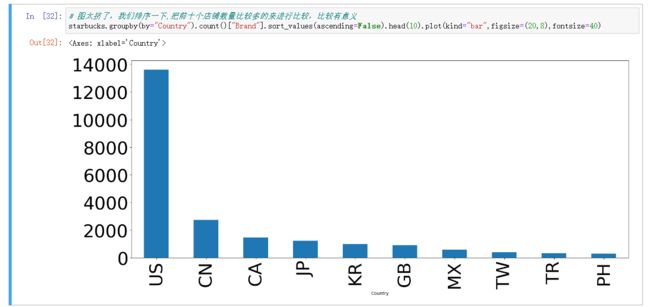
# 图太挤了,我们排序一下,把前十个店铺数量比较多的来进行比较,比较有意义
starbucks.groupby(by="Country").count()["Brand"].sort_values(ascending=False).head(10).plot(kind="bar",figsize=(20,8),fontsize=40)



假设我们加入省市一起进行分组
# 假设我们加入省市一起进行分组
starbucks.groupby(by=["Country","State/Province"]).count()

返回的这个结果是两个索引,这样的方式我们挺熟悉的,带MultiIndex的DataFrame。
综合案例
问题1: 我们想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
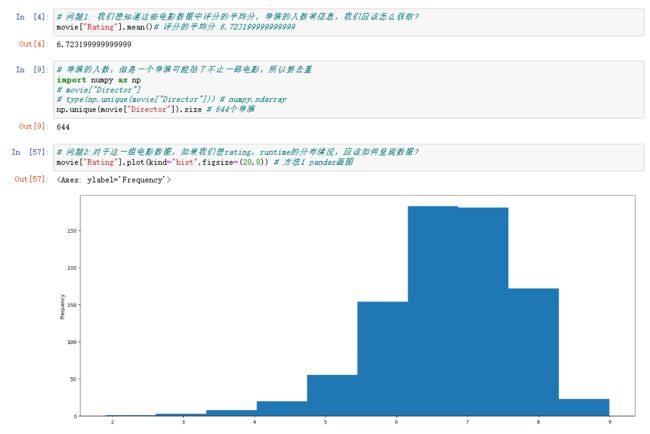
问题2:对于这一组电影数据,如果我们想rating,runtime的分布情况,应该如何呈现数据?
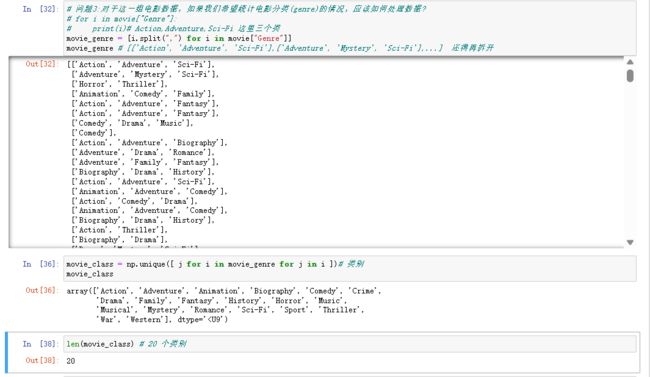
问题3:对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据?
import pandas as pd
# 1、准备数据
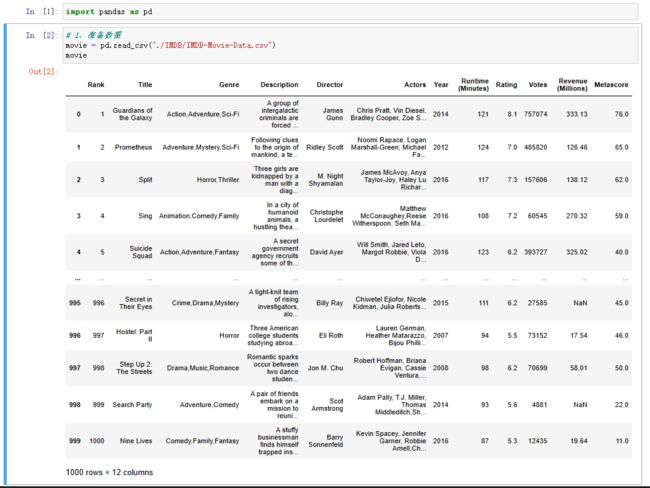
movie = pd.read_csv("./IMDB/IMDB-Movie-Data.csv")
movie
# 问题1: 我们想知道这些电影数据中评分的平均分,导演的人数等信息,我们应该怎么获取?
movie["Rating"].mean()# 评分的平均分 6.723199999999999
# 导演的人数,但是一个导演可能拍了不止一部电影,所以要去重
import numpy as np
# movie["Director"]
# type(np.unique(movie["Director"])) # numpy.ndarray
np.unique(movie["Director"]).size # 644个导演
# 问题2:对于这一组电影数据,如果我们想rating,runtime的分布情况,应该如何呈现数据?
movie["Rating"].plot(kind="hist",figsize=(20,8)) # 方法1 pandas画图
# 方法2 matplotlib 画图
import matplotlib.pyplot as plt
## 1. 创建画布
plt.figure(figsize=(20,8),dpi=80)
## 2. 绘制直方图
# plt.hist(movie["Rating"].values)也可以
plt.hist(movie["Rating"],bins=20)
plt.xticks(np.linspace(movie["Rating"].min(),movie["Rating"].max(),21))# 修改刻度
plt.grid(True, linestyle='--', alpha=0.5)# 添加网格
## 3. 显示图像
plt.show()
# 问题3:对于这一组电影数据,如果我们希望统计电影分类(genre)的情况,应该如何处理数据?
# for i in movie["Genre"]:
# print(i)# Action,Adventure,Sci-Fi 这里三个类
movie_genre = [i.split(",") for i in movie["Genre"]]
movie_genre # [['Action', 'Adventure', 'Sci-Fi'],['Adventure', 'Mystery', 'Sci-Fi'],...] 还得再拆开
movie_class = np.unique([ j for i in movie_genre for j in i ])# 类别
movie_class # array(['Action', 'Adventure',...], dtype='
len(movie_class) # 20 个类别
# 统计每个类别有几个电影
count = pd.DataFrame(np.zeros(shape=(1000,20),dtype="int32"),columns=movie_class)
count # 空表
# 计数填表
for i in range(1000):
count.loc[count.index[i],movie_genre[i]] = 1 # 组合索引
count
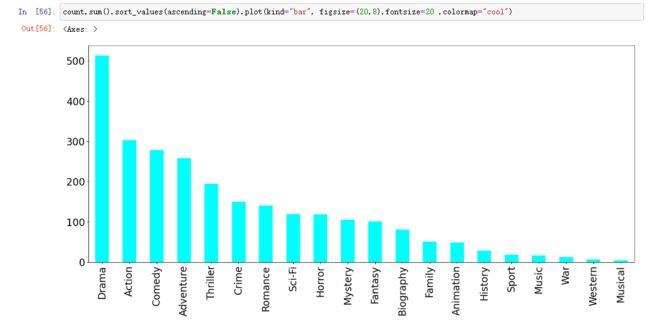
# 按列求和
count.sum()
count.sum().sort_values(ascending=False).plot(kind="bar", figsize=(20,8),fontsize=20 ,colormap="cool")