C++ 多线程编程导论(下)
文章目录
- 参考资料
- 线程安全(续)
-
- 门闩与屏障——`latch` 对象与 `barrier` 对象
-
- 门闩(latch)
- 屏障(barrier)
- 一次性调用——`once_flag` 对象与 `call_once` 函数
- 异步任务
-
- 未来与承诺——`future` 对象与 `promise` 对象
-
- future 的方法
- promise 的方法
- 共享 future——`shared_future`
- 包装的承诺
-
- 低级包装——`packaged_task` 对象
- 高级包装——`async` 函数
上:https://blog.csdn.net/lycheng1215/article/details/113282527
中:https://blog.csdn.net/lycheng1215/article/details/126179195
参考资料
- cppreference.com(该项引用的内容较多。由于这是一个手册性质的文档,因此请读者自行在其中查阅相应内容,本文不再额外指明引用自其中的哪几篇,也不显式地标明哪句话引自该文档)
- 见角注1。
- 见角注2。
以上参考资料中,除了第一项,其余有引用的,会通过角标注明。没有用角标注明的,说明是我看过,但并没有引用其中作者的观点,读者可以将他们作为扩展资料阅读。
线程安全(续)
就差屏障了。
门闩与屏障——latch 对象与 barrier 对象
顾名思义,门闩和屏障是拿来“挡”线程的。当一定数量的线程“到达”门闩或者屏障时,它们就会打开,“放行”这些线程。
相比之下,门闩比较简陋,就是一根杆子:指定数量的线程“到达”后把门闩撞断,门开了,线程就继续运行,门闩却不复存在了。而屏障比较高级,把它看作一个能量罩吧:指定数量的线程“无阻地进入能量罩”后,最后一个到达的线程可以“按一个按钮”,然后能量罩自动关闭,线程继续运行,再然后能量罩又自动打开,等待下一批线程的到来。
以上场景中总是可以将条件变量作为替代品,因为可以把“已到达的线程达到指定数量”作为条件谓词。但门闩和屏障在以上场景中语意更贴切,代码会更易写易读。屏障还是 pthread 本身就支持的线程同步原语之一,在特定场景下使用它们,性能可能会高于更加通用的条件变量。
需要注意的是,门闩和屏障不尽相同1,主要在于:
- 门闩的重点在门闩(一系列任务)上,一个线程“撞一下门闩”(完成一项任务)后可以直接继续工作,不一定非要在门口等着。也就是说门闩的“耐久度”应该与任务数量相关。
- 屏障的重点在限制线程上,一个线程“进入能量罩”后无法再离开,直到“能量罩被关闭”。也就是说屏障的“耐久度”应该与线程数量相关。
门闩(latch)
要使用门闩需要先包含头文件:
#include 线程可以对门闩有如下作用:
- 撞一下门闩,然后在门口等。对应
arrive_and_wait方法。 - 撞一下门闩,然后跑去干其他事情。对应
count_down方法。 - 直接在门口等。对应
wait(try_wait)方法。
因此,可以有如下常见的应用方法:
- 完成工作的线程调用
count_down方法。 - 等待工作完成的线程调用
wait方法。 - 完成工作后,还需要等待其他工作也完成的线程,调用
arrive_and_wait方法。
import std;
int main() {
constexpr auto n_work = 114;
auto work_done = std::latch(n_work);
auto exit_together = std::latch(2);
int a_number = 514;
auto worker = std::jthread([&]() {
for ([[maybe_unused]] auto _ : std::views::iota(0, n_work)) {
a_number += 114514;
// 子线程完成一部分工作,撞一下门闩。(1)
work_done.count_down(1);
}
// 撞一下门闩,并且等待。默认就撞一下。(3)
exit_together.arrive_and_wait();
});
// 主线程等待工作全部完成。(2)
work_done.wait();
// 撞一下门闩,并且等待。(3)
exit_together.arrive_and_wait();
}
屏障(barrier)
要使用屏障需要先包含头文件:
#include 线程可以对屏障有如下作用:
- 进入屏障,等待屏障放行。对应
arrive_and_wait方法。 - 进入屏障,然后立即被放行,但屏障重新启动后不再等待该线程。对应
arrive_and_drop方法。
尽管屏障还提供单独的 arrive 和 wait 方法,但不应该调用它们,因为 arrive 方法的返回值必须提供给 wait 方法,以保证屏障的正常运行。
前面提到,屏障还支持让最后一个线程“按一个按钮”,意思是在最后一个线程调用这两个方法的时候顺便执行一个绝不抛出异常的回调函数,称为完成时函数(completion function)。
由于屏障可以重用,所以完成时函数的主要功能是处理各个线程的同步任务。
import std;
int main() {
constexpr size_t n_worker = 8;
std::array<float, n_worker> numbers{};
std::barrier sync_point(n_worker, [&]() noexcept { // 完成时函数必须是 noexcept 的。
// 对所有数取平均。
numbers.fill(std::accumulate(numbers.cbegin(), numbers.cend(), 0.0f) / n_worker);
// 此函数由最后一个线程执行。由于只有一个线程了,所以不用同步。
for (size_t i = 0; i < numbers.size(); i++) {
std::cout << ("after sync: " + std::to_string(i) + " is " + std::to_string(numbers[i]) + "\n");
}
});
std::array<std::jthread, n_worker> workers;
for (size_t i = 0; i < workers.size(); i++) {
workers[i] = std::jthread([&, i] {
for ([[maybe_unused]] auto _ : std::views::iota(0, 10)) {
numbers[i] += i;
std::cout << ("before sync: " + std::to_string(i) + " is " + std::to_string(numbers[i]) + "\n");
// 等待所有增加结束后再取平均。(1)
sync_point.arrive_and_wait();
}
// 线程不再工作。(2)
sync_point.arrive_and_drop();
// 以下输出内容一定至少有一句在最后一次同步输出的后面,因为完成时函数由最后一个线程调用。
// 由于 arrive_and_drop 立即返回,所以其他线程的以下内容很有可能在同步输出的前面。
std::cout << ("exit: " + std::to_string(i) + "\n");
});
}
}
一次性调用——once_flag 对象与 call_once 函数
如果希望某个函数仅被调用一次,可以使用 call_once 函数来调用它。需要辅以一个 once_flag 对象来记录调用情况。特别地,如果调用抛出异常,则之后允许重新调用;异常由 call_once 的调用方处理。
import std;
int main() {
auto flag = std::once_flag();
constexpr size_t n_worker = 8;
std::array<std::jthread, n_worker> workers;
for (auto& t : workers) {
t = std::jthread([&flag]() { // 按引用捕获 once_flag。
call_once(flag, [] {
std::cout << "Hello!" << std::endl; // 仅输出了一次。
});
});
}
}
异步任务
当我们创建一个线程以执行运算任务时,如何获取执行结果便成了问题。对于需要获取结果的异步任务,C++ 标准库提供了一系列线程相关的对象来保证整个过程的安全与优雅。
未来与承诺——future 对象与 promise 对象
C++ 规定,异步任务的运算结果用 future 对象获取,而用 promise 对象设置,两者密不可分。
future 的方法
目前为止,只需要知道 future 对象存储的是异步任务的运算结果。但据此我们就可以猜出它可能存在的状态:
- 异步任务执行未完成,还没有存储值。
- 异步任务执行已完成,已经存储值。
针对以上两个状态,future 存在以下方法:
wait系列方法:等待异步任务提供值。get方法:等待异步任务提供值,然后返回它。
事实上,future 对象不仅可以存储一个成功的结果。如果异步任务失败,还可以通过异常的形式传递失败的信息:get 方法会抛出异步任务提供的异常。
import std;
using namespace std::literals;
int main() {
// 本程序仅展示调用方法,无法实际投入使用。
std::future<int> demo; // 结果的类型是 int。
demo.wait(); // 等待存在值。
if (demo.wait_for(100ms) == std::future_status::ready) { // 等待存在值且没有超时。
// 除了 ready 和 timeout,还有 deferred,表示结果需要惰性求值,wait_for 是无效的。稍后讲解。
try {
int value = demo.get();
std::cout << "The result is " << value << std::endl;
}
catch (const std::exception& my_exception) {
std::cerr << my_exception.what() << std::endl;
}
}
}
future 并不会一直存储结果。一旦调用了 get 方法,future 也就无效了,不允许再次 get,否则抛出 std::future_error 异常。可以用 valid 方法进行检查是否可以调用 get 方法。
对于默认构造的 future,valid 总是 false,因为没有为 future 指定数据源。下面的代码验证了默认的 future 的窘况。
import std;
int main() {
std::future<int> empty;
std::cout << empty.valid() << std::endl; // 0
try {
empty.get();
}
catch (const std::future_error& e) { // 被捕捉。注意这不是由结果提供方(promise)提供的异常。
std::cerr << e.what() << std::endl;
}
}
因此,如果 future 对象的来源比较复杂,就需要在调用它的 get 方法前用 valid 方法检查一下这个 future 是否能够用于获取结果。此外,标准还规定 valid 为 false 时 get 方法的行为是不确定的,所以也不建议像程序 35 那样捕捉 std::future_error 来处理无效的 future。
promise 的方法
future 只用于获取结果,如何提供结果呢?这便是 promise 对象的工作。我们可以猜出它应该有的功能:
- 提供运算结果。对应
set_value方法。 - 提供异常。对应
set_exception方法。
但 promise 如何与 future 相连呢?这个问题牵扯到 promise 和 future 的内部状态,是最复杂的、亟待解决的问题。
不过我们可以先看看基本的。promise 对象可以调用 get_future 方法获得一个对应类型的 future 对象,这个 future 对象的 valid 是有效的,从而可以完成信息传递。下面的程序展示了 promise 的基本使用方法。
import std;
int main() {
// 由数据接收方创建 promise 对象,提供给数据提供方。
std::promise<int> calc_promise;
// 当然,数据接收方保管 future 对象。类型自动为 future。
auto calc_future = calc_promise.get_future();
std::jthread t([](auto promise) {
using namespace std::literals;
std::this_thread::sleep_for(1s);
// 数据提供方使用 set_value 提供数据。
promise.set_value(114514);
// 此后不允许再次提供数据。
}, std::move(calc_promise)); // 把 promise 对象交给数据提供方时,需转移所有权。
// 已经明知 calc_future 是 valid 的,且 promise 不会 set_exception,可以不捕获异常。
int value = calc_future.get();
std::cout << value << std::endl;
}
在网上2找到了张很好的图来描述程序 36 的过程。
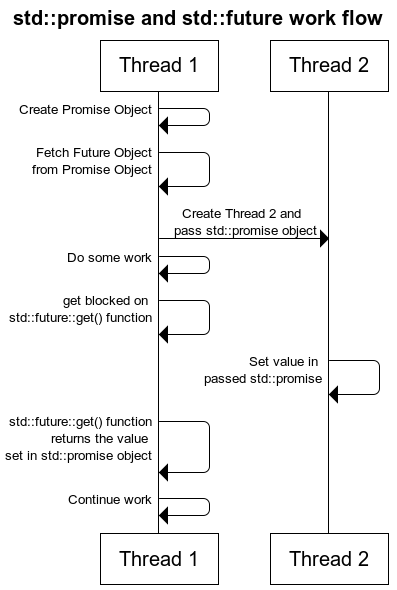
程序 36 很好理解,但是它太过标准了。我不禁想问:
get_future返回的future从哪儿来?凭什么get_future只能调用一次?promise经过移动构造后,地址改变,future凭什么找到对应的promise?- 如果
promise被提前析构,future会怎样?会变得不再valid吗?万一future正在等待呢? - ……
要回答这些问题,就必须回到一开始所提出的:promise 和 future 的内部状态究竟如何?
标准规定,promise 需要与一个共享态(shared state)相关联,而共享态包含:
- 一些状态信息。
- 一个结果值,或者一个异常对象,或者一个惰性求值函数。
另外,共享态也可以与一个 future 相关联,从而形成 promise-future 对。据此可以回答前两个问题:
- 这三种对象只有一对一的关系,不能形成一对多的关系,所以
get_future只能调用一次。 future和promise内部保存了共享态对象的引用,所以它们本身的地址并不重要。它们的通信通过共享态完成。
如果 promise 被提起析构,共享态的引用计数会减小,但对 future 来说意味着什么?下面的程序展示了这样的情况。
import std;
using namespace std::literals;
int main() {
// void 表示不需要返回值,只需要传递异常。
auto drop_promise = std::make_unique<std::promise<void>>();
auto drop_future = drop_promise->get_future();
auto t = std::jthread([](auto drop_promise) {
std::this_thread::sleep_for(500ms);
drop_promise.reset();
}, std::move(drop_promise));
std::cout << drop_future.valid() << std::endl;
if constexpr (true) {
// 演示 get 时 promise 被销毁。
try {
drop_future.get();
}
catch (const std::future_error& e) {
std::cerr << e.what() << std::endl; // broken promise.
}
}
else {
// 演示 promise 被销毁后的 valid 情况。
drop_future.wait(); // 成功在 500 ms 后返回。
std::cout << drop_future.valid() << std::endl; // 还是 1。
}
}
可见,future 与 promise 通过共享态强绑定。一旦 promise 被销毁,future 的所有等待函数都会立即返回。特别地,get 函数还会抛出 future_error 异常,所以正常情况下 promise 不应该在 set_value 前被销毁。
程序 37 中,即使 promise 被销毁了,future 仍然是 valid 的。因为 future 的有效与否只取决于它是否绑定了共享态,与 promise 无关。这也解释了 future 只能调用一次 get 函数的原理:调用 get 函数会导致 future 解绑当前的共享态。
共享 future——shared_future
前面强调了,future、promise、共享态是一对一的关系,这也就意味着一个 promise-future 对只能有一个生产者和一个消费者。如果我们希望有多个消费者该怎么办?
future 对象提供了一个名为 shared 的方法,返回一个类型为 shared_future 的对象,它将引用同一个共享态。与 future 不同的是,shared_future 允许复制,并且通过不同的 shared_future 访问同一个共享态是线程安全的。
import std;
using namespace std::literals;
int main() {
auto single_promise = std::promise<int>();
auto my_shared_future = single_promise.get_future().share();
auto consumers = std::array<std::jthread, 2>{};
for (auto& t : consumers) {
t = std::jthread([my_shared_future] { // 注意:此处的捕捉是复制构造。
std::cout << my_shared_future.get() << std::endl;
std::cout << my_shared_future.get() << std::endl;
});
}
single_promise.set_value(114514);
}
需要注意的是,调用 future 对象的 share 方法后,future 对象本身会抛弃其共享态,之后不再允许使用 future 对象,所以程序 38 直接声明了 my_shared_future 对象,然后通过复制构造传递给多个消费者。
从程序 38 还可以看出,shared_future 也没有限制调用 get 函数的次数。
包装的承诺
因为函数调用的返回值也可以看作是数据的提供方,所以我们往往不直接使用 promise 对象,而是再包装一下,直接让函数调用的结果称为 promise 的结果。
低级包装——packaged_task 对象
packaged_task 把一个可调用对象转变为另一个可调用对象,使得调用的过程不变,但是原可调用对象的返回值不再直接可用,而必须通过一个 future 对象获取。
import std;
int main() {
auto task1 = std::packaged_task([]() -> int {
return 114;
});
auto task2 = std::packaged_task([]() -> int {
return 514;
});
task1(); // packaged_task 只能被调用一次。
// 获取结果。
std::cout << task1.get_future().get() << std::endl;
auto future2 = task2.get_future();
auto t = std::jthread(std::move(task2)); // 必须 move!
// 获取结果。
std::cout << future2.get() << std::endl;
}
高级包装——async 函数
很多时候,我们只是想执行一个函数然后获得结果,不再需要额外引入 packaged_task 这样一个中间对象。async 函数可以帮助我们做到这一点:它直接运行我们提供的可调用对象,并且返回值就是一个 future。
如果我们不希望立即求值,又不希望引入 future 之外的对象,应该怎么办?async 函数提供了一系列标志位,允许我们让 future 在调用 get 函数或 wait 函数时再开始求值。标志位包括:
std::launch::async:立即新建一个线程求值。线程可能来自内部维护的线程池。返回的future被析构时会等待任务执行完成。std::launch::deferred:在当前线程求值,惰性求值。调用get函数或wait函数时才开始求值。调用wait_for或wait_until函数会导致立即返回,且返回值为std::future_status::deferred。
如果多个标志位被选中,则采用哪个标志位是由编译器决定的。如果不指定标志位,则等同于两个标志位都指定,相当于一切都是编译器说了算,所以调用 async 函数通常都需要指定标志位。
import std;
int main() {
auto a1 = std::async(std::launch::async, [] {
return 114514;
});
std::cout << a1.get() << std::endl;
auto a2 = std::async(std::launch::async, [] {
for ([[maybe_unused]] auto _ : std::views::iota(0, static_cast<int>(1e8)));
});
// 析构 a2 时,会等待任务执行结束。
}
c++ - Where can we use std::barrier over std::latch? - Stack Overflow ↩︎ ↩︎
C++之future和promise - PKICA - 博客园 (cnblogs.com) ↩︎ ↩︎