[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)
hello,大家好,这里是bang___bang_,今天来谈谈的文件系统知识,包含有缓冲区、inode、软硬链接、动静态库。本篇旨在分享记录知识,如有需要,希望能有所帮助。
![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第1张图片](http://img.e-com-net.com/image/info8/562416631dad43b7acf0ce178f8463a4.jpg)

目录
1️⃣缓冲区
缓冲区的意义
常见缓冲区刷新策略
缓冲区位置猜想
现象猜测
现象解释
用户级缓冲区位置
2️⃣理解文件系统
磁盘的存储结构
磁盘物理结构
磁盘抽象结构
文件系统
inode vs 文件名
3️⃣软硬链接
软链接
硬链接
4️⃣动态库和静态库
静态库
生成静态库
使用静态库
动态库
生成动态库
使用动态库
同时存在使用静态库还是动态库?
特点总结
静态库特点
动态库特点
1️⃣缓冲区
问题:什么是缓冲区?
答:就是一段内存空间!!
缓冲区的意义
我们知道了一段内存空间就是缓冲区,那么为什么要有缓冲区呢?
生活例子映射:
你在西安,你有个好朋友在上海,下个月好朋友要过生日了,你想送他一本你自己手绘的图画,你可以选择自己骑车亲手送给你的朋友;也可以选择下楼到顺丰选择寄送包裹然后回家。
毫无疑问:你自己骑车亲手送需要花费大量的时间,而你选择去顺丰寄包裹却很快,但是寄包裹也不是立马就会发送包裹,可能要等仓库堆满一批货物再一起发送。(图画是数据,顺丰是缓冲区)
自己骑车亲手送就相当于写透模式(WT)
而去顺丰寄包裹再可以直接回家就相当于写回模式(WB)
写透模式:直接将数据写到外部设备。
写回模式:先将数据写到缓冲区,当缓冲区的数据达到一定量时,再集中写到外部设备。
通过这个例子很显然能感受到缓冲区存在的意义了!
缓冲区存的意义:提高整机效率。主要是为了提高用户的响应速度!
常见缓冲区刷新策略
缓冲策略=一般+特殊
一般情况:
✦立即刷新
✦行刷新(行缓冲)
✦满刷新(全缓冲)
特殊情况:
✦用户强制刷新(fflush)
✦进程退出
一般而言:行缓冲的设备文件——显示器 全缓冲的设备文件——磁盘文件
所有的设备,永远都倾向于全缓冲!
——缓冲区满了,才刷新—>更少次的IO操作—>更少次的外设的访问(提高效率)
和外部设备IO的时候,数据量的大小不是主要矛盾,和外设预备IO的过程是最耗费时间的!!
缓冲区位置猜想
现象猜测
下面有一段代码,我们分别输出到显示屏,输出重定向到文件。
int main() {
//C语言提供的
printf("hello printf\n");
fprintf(stdout, "hello fprintf\n");
const char* s = "hello fputs\n";
fputs(s, stdout);
//OS提供的
const char* ss = "hello write\n";
write(1, ss, strlen(ss));
fork();
return 0;
}![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第2张图片](http://img.e-com-net.com/image/info8/83db51f614e94c5aab9ee41747346ceb.png) 现象图
现象图
我们可以看到同一份代码,输出的结果却不一样,C的IO接口打印了2次,系统接口只打印1次和向显示器打印一样!也就是说子进程中有父进程C的IO接口对应的打印数据,但没有系统接口的。也就是说如果有缓冲区,那么绝对是C标准库来提供的。
![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第3张图片](http://img.e-com-net.com/image/info8/0aa1d021a69942a283e110b68017a2af.jpg)
现象解释
★如果向显示器打印,刷新策略是行刷新,那么进程执行到fork()函数时会将C标准库里缓冲区的数据全部进行刷新出去(fork无意义!)
对于进程来说,当我们调用C文件接口fputs时,实际是将进程数据写入到C标准库中的缓冲区里,然后再统一调用系统接口write函数写入到对应的目标文件中。
![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第4张图片](http://img.e-com-net.com/image/info8/adbc9ec0130c4ea897ee429a2e749c9f.jpg)
★如果我们进行输出重定向时,将原本写入到stdout文件中的数据写入到了磁盘文件中,缓冲模式就由行刷新变成了全缓冲。(\n便没有意义了!)当进程执行到代码fork()时,此时进程写入C标准库中的缓冲区数据还未刷新。当进程执行fork函数,便又生成了子进程。
fork后父子进程退出:刷新数据到磁盘文件中,但是刷新实际上也是一次写入,因为进程的独立性,发生写时拷贝,打印2份!!
★缓冲区里的数据也是父进程的数据!提前强制刷新后,没有数据了,子进程也就没拷贝了!
![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第5张图片](http://img.e-com-net.com/image/info8/eb0bdc442b234cbcbc17462ed626977c.jpg)
用户级缓冲区位置
问题:为什么fflush只传了stdout,却能找到缓冲区?
答:C语言中,打开文件,FILE* fopen(),struct FILE 结构体 内部封装了fd,还包含了该文件fd对应的语言层的缓冲区结构!
![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第6张图片](http://img.e-com-net.com/image/info8/a642ec247f864c39a4e3e68ad5729238.jpg)
2️⃣理解文件系统
我们使用ls -l指令读取文件信息,实际上是对磁盘中的文件进行读取。
![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第7张图片](http://img.e-com-net.com/image/info8/8a02a387814e48bab1574aebbac4c85e.png)
磁盘——永久性存储介质(还有SSD,U盘,flash卡,光盘,磁带)
磁盘是一个外设+还是我们计算机中唯一的一个机械设备!也就是说速度很慢!(相对于CPU)
磁盘的存储结构
磁盘物理结构
磁盘盘片,磁头,伺服系统,音圈马达等等
![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第8张图片](http://img.e-com-net.com/image/info8/19a1b446a09e4d51a8476977a4805098.jpg)
向磁盘写入,本质就是改变磁盘上的正负性。
![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第9张图片](http://img.e-com-net.com/image/info8/7a68de65f7ad4ff69e997a412891afb8.jpg)
磁盘的盘面被划分为一个个磁道,而磁道又被划分为一个个扇区。
扇区(磁道划分区域)是磁盘存储数据的基本单位(512byte)
如何将数据写入指定的一个扇区?有以下步骤:CHS寻址
——1.在哪一个面上(对应的就是哪一个磁头)
——2.在哪一个磁道(柱面)上
——3.在哪一个扇区上
如果我们有了CHS寻址方式,就可以找到任意一个扇区。
磁盘抽象结构
小时候我们都有过磁带这种东西,他是缠在一起成圈的,但是我们也可以将他全拉出来成线状。磁盘我们也可以抽象成拉长后变为线状结构。
结构:圆形结构(CHS)->线性结构(LBA)
LBA是非常单纯的一种寻址模式﹔从0开始编号来定位扇区,第一扇区LBA=0,第二扇区LBA=1,依此类推。所以将来我们想要访问磁盘的某个扇区,只需要将通过LBA寻址后转换为CHS物理寻址。
![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第10张图片](http://img.e-com-net.com/image/info8/3f72472330c3480192ba7340935e4ec2.jpg)
最终:对磁盘的管理就变成了对一个个小分区的管理。
文件系统
![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第11张图片](http://img.e-com-net.com/image/info8/5f6513ffbf994d3385d5d323c2bde341.jpg) 磁盘文件系统图
磁盘文件系统图
虽然磁盘的基本单位是扇区(512字节),但是OS(文件系统)和磁盘进行IO的基本单位是:4KB(8*512byte)4KB->block大小。
★Super Block->文件系统的属性信息
★Data bolcks->多个4KB大小的集合,保存的都是特定文件的内容
★inode Table:inode是一个大小为128字节的空间,保存的是对应文件的属性该块组内,所有文件的inode空间的集合,需要标识唯一性,每一个inode块,都要有一个inode编号!
★Block Bitmap:假设有10000+blocks,10000+比特位;比特位合特定的block是一一对应的,其中比特位为1,代表该block被占用,否则表示可用!
★inode Bitmap:假设有10000+个inode节点,就有10000+个比特位,比特位和特定的inode是一一对应的。其中bitmap中比特位为1,代表该inode被占用,否则表示可用!
★GDT:块组描述符,这个块组多大,已经使用了多少了,有多少个inode,已经占用了多少个,还剩多少,一共有多少个block,使用了多少....
我们将块组分割成上面的内容,并且写入相关的管理数据->每一个块组都这么干->整个分区就被写入了文件系统信息!!!(格式化)
inode vs 文件名
- 一个目录下,可以保存很多文件,但是这些文件都不会重名。
- 目录是文件,目录有自己的inode和Data block
文件名在目录的Data block 中,它保存着与inode编号的映射关系,文件名与inode互为key值,都是唯一的。
为什么目录需要w权限?
因为在目录下创建文件时,这个目录有自己的数据块,我们创建文件的文件名就在目录的Data block 中,所以我们要将文件名和inode编号写入保存,此时必须需要w权限。
为什么目录中具有r权限?
当我们需要显示文件名时,我们只能从目录的内容中获取文件名及相关属性,就必须访问目录的文件内容,就必须需要r权限从目录的Data block中获取文件名。
创建文件,系统做了什么?
特定分组找到没有使用的inode,分配inode编号,如果文件有内容,向文件内容当中申请Data Block,设置Block Bitmap,建立inode和Bitmap的映射,inode和Bitmap、Data Block的对应关系并写到inode结点中,inode文件名对应的映射关系写到特定的目录的DataBlock中。
删除文件,系统做了什么?
删除文件肯定是在这个目录下删除,找到这个目录的Data Block, 删文件用户提供文件名,在Data Block中索引查询由文件名进行映射的inode编号,找到将inodeBitmap对应的比特位由1置为0,将Block Bitmap中的比特位由1置为0,在目录的Data Blocks中将文件名与inode编号解除映射关系。
查看文件,系统做了什么?
根据文件名找到inode,然后查内容查属性。
3️⃣软硬链接
本质区别:有没有独立的inode
软链接
软链接有独立的inode,软链接是一个独立的文件
应用:相当于windows下的快捷方式
特性:可以理解成为:软链接的文件内容,是指向的文件对应的路径!
ln -s 文件 软链接文件名建立一个软链接
![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第12张图片](http://img.e-com-net.com/image/info8/f6031608fe0947c2be0d2108552ce28f.jpg)
软链接如同Windows下的快捷方式
![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第13张图片](http://img.e-com-net.com/image/info8/87d34b2cc787423d9e79d7a67403622b.jpg)
硬链接
硬链接没有独立的inode,硬链接不是一个独立的文件(有被链接文件的inode)
创建硬链接就是在指定的目录下,建立了 文件名 和 指定inode的映射关系。
ln 文件 硬链接文件名建立一个硬链接
![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第14张图片](http://img.e-com-net.com/image/info8/04ca0fcce325443b998d99d64cec0b3d.jpg)
硬链接没有独立的inode!也就是说硬链接不是一个独立的文件!
硬链接数(引用计数)
![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第15张图片](http://img.e-com-net.com/image/info8/ffddcd245eb645dc9d7dfbcf7fc9ee3a.jpg)
硬链接后inode与文件名映射关系增加1组,所以为2,从这里可以看出一个思想:
当我们删除一个文件的时候,并不是把这个文件inode删除,而是将这个文件的inode引用计数--。当引用计数为0的时候,这个文件,才正在删除!!(RAII思想)
默认创建文件引用计数是1,创建目录引用计数是2
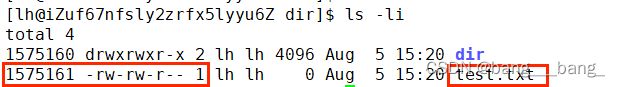
inode与文件名对应一组映射关系。
但目录为什么是2呢?
![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第16张图片](http://img.e-com-net.com/image/info8/b7d2b5f7c3804313a86b794123731de4.png)
因为目录里面还有隐藏文件.文件,也就是说inode对应2个文件名(自己目录名,自己目录内部的文件名),所以引用计数为2。
4️⃣动态库和静态库
静态库
✦静态库(.a):程序在编译链接的时候把库的代码链接到可执行文件中。程序运行的时候将不再需要静态库。
生成静态库
打包.o文件:ar -rc xxx.a xxx.o xxx.o
解析 ar是gnu归档工具 ar——archieve r——replace c ——create ,把.o文件打包到.a(静态库)将myprint.o、mymath.o打包到libtest.a
myprint.h代码:
#pragma once
#include
#include
extern void Print(const char* str);
myprint.c代码:
#include"myprint.h"
void Print(const char* str)
{
printf("%s[%d]\n",str,(int)time(NULL));
}mymath.h代码:
#pragma once
#include
extern int addToTarget(int form,int to); mymath.c代码:
#include"mymath.h"
int addToTarget(int form,int to)
{
int sum=0;
for(int i=form;i<=to;i++)
{
sum+=i;
}
return sum;
}
Makefile:
libtest.a:mymath.o myprint.o
ar -rc libtest.a mymath.o myprint.o
mymath.o:
gcc -c mymath.c -o mymath.o -std=c99
myprint.o:
gcc -c myprint.c -o myprint.o -std=c99
.PHONY:clean
clean:
rm -rf *.o *.a
![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第17张图片](http://img.e-com-net.com/image/info8/05cd71894490470a9f8ce9a52d51156d.png) 静态库生成图
静态库生成图
使用静态库
gcc main.c -I 指定头文件搜索路径 -L 指定库文件搜索路径 -l使用哪个库使用上面生成的libtest.a静态库
修改Makefile文件,将头文件放到include目录中,静态库放到lib目录中。
libtest.a:mymath.o myprint.o
ar -rc libtest.a mymath.o myprint.o
mymath.o:
gcc -c mymath.c -o mymath.o -std=c99
myprint.o:
gcc -c myprint.c -o myprint.o -std=c99
.PHONY:output
output:
mkdir -p lib
mkdir -p include
cp -rf *.h include
cp -rf *.a lib
.PHONY:clean
clean:
rm -rf *.o *.a lib include
![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第18张图片](http://img.e-com-net.com/image/info8/6e871ba0822f4b82832c4a7398f4c166.jpg)
使用静态库生成可执行文件:
![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第19张图片](http://img.e-com-net.com/image/info8/e16604d6a28c4c538ac26874fe338de4.jpg)
动态库
✦动态库(.so):程序在运行的时候才去链接动态库的代码,多个程序共享使用库的代码。
生成动态库
生成动态库的必须加 -fPIC 生成二进制文件
-shared告诉gcc生成动态库
gcc -fPIC -c xxxx.c -o xxxx.o //生成动态库必须加-fPIC
gcc -shared xxxx.o -o libxxxx.so //-shared告诉gcc生成动态库生成libtest.so动态库
编写Makefile文件:
libtest.so:mymath_d.o myprint_d.o
gcc -shared mymath_d.o myprint_d.o -o libtest.so
mymath_d.o:mymath.c
gcc -fPIC -c mymath.c -o mymath_d.o -std=c99
myprint_d.o:myprint.c
gcc -fPIC -c myprint.c -o myprint_d.o -std=c99
.PHONY:output
output:
mkdir -p lib
mkdir -p include
cp -rf *.h include
cp -rf *.so lib
.PHONY:clean
clean:
rm -rf *.o *.so lib include
![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第20张图片](http://img.e-com-net.com/image/info8/47b20d2e02844a48a92d5704d66b9a48.png) 生成动态库
生成动态库
使用动态库
动态库的使用和静态库是一样的。
gcc main.c -I 指定头文件搜索路径 -L 指定库文件搜索路径 -l使用哪个库main.c使用动态库libtest.so
查看程序链接的库(动态库):ldd
ldd 可执行程序 //查看程序链接的库![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第21张图片](http://img.e-com-net.com/image/info8/ba5b3f5ebbc541378a66200748dc544a.jpg)
同时存在使用静态库还是动态库?
问题:假设现在既有静态库又有动态库,那么程序默认链接的是哪种库?
修改Makefile文件:
.PHONY:all
all:libtest.so libtest.a
libtest.so:mymath_d.o myprint_d.o
gcc -shared mymath_d.o myprint_d.o -o libtest.so
mymath_d.o:mymath.c
gcc -fPIC -c mymath.c -o mymath_d.o -std=c99
myprint_d.o:myprint.c
gcc -fPIC -c myprint.c -o myprint_d.o -std=c99
libtest.a:mymath.o myprint.o
ar -rc libtest.a mymath.o myprint.o
mymath.o:
gcc -c mymath.c -o mymath.o -std=c99
myprint.o:
gcc -c myprint.c -o myprint.o -std=c99
.PHONY:clean
clean:
rm -rf *.o *.a *.so
现象:
![[Linux]理解文件系统!动静态库详细制作使用!(缓冲区、inode、软硬链接、动静态库)_第22张图片](http://img.e-com-net.com/image/info8/fdd682798ece42e0a3647274d5bdf06a.jpg)
验证发现同时存在静态库和动态库默认使用的是动态库。
那么如何在这种情况使用静态库呢? -static 指定静态链接
-static的意义:摒弃默认优先使用动态库的原则,而是直接使用静态库。

使用ldd查看链接的动态库,报错显示:不是动态可执行文件,也就是说使用的是静态库!!
特点总结
静态库特点
优点:
①静态库被打包到应用程序中加载速度快
②发布程序无需提供静态库,移植方便
缺点:
①相同的库文件数据可能在内存中被加载多份,消耗系统资源,浪费内存
②库文件更新需要重新编译项目文件,生成新的可执行程序,浪费时间
动态库特点
优点:
①可实现不同进程间的资源共享
②动态库升级简单,只需要替换库文件,无需重新编译应用程序
③可以控制何时加载动态库,不调用库函数动态库不会被加载
缺点:
①加载速度比静态库慢
②发布程序需要提供依赖的动态库
文末结语,开篇解释缓冲区以及意义,并验证了用户级缓冲区的刷新策略,接下来谈文件系统,首先介绍磁盘的存储结构(包括物理结构和抽象结构),介绍inode和文件名之间的关系,软硬链接的使用,最后讲解动静态库,详细说明如何制作并使用动静态库,并探究了动静态库同时存在时默认使用动态库,以及想使用静态库的解决方案,最终总结动静态的特点。本篇旨在分享记录知识,如有需要,希望能有所帮助!!感谢观看!