linux搭建pyspark环境,本地pycharm使用远程连接
环境准备:
python3.6
jdk1.8
spark-2.3.4-bin-hadoop2.7 Downloads | Apache Spark
# java 安装
mkdir /apps/jdk
tar xvzf jdk-8u251-linux-x64.tar.gz -C /apps/jdk
#spark 安装
mkdir /apps/spark
tar -zxvf spark-2.3.4-bin-hadoop2.7.tgz -C /apps/spark/
#python 安装
mkdir /apps/python3
tar -zxvf Python-3.6.8.tgz -C /apps/python3/
#安装依赖包
yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc
cd /apps/python3/Python-3.6.8
./configure --prefix=/usr/local/python3
#编译
make && make install
#软连接
ln -s /usr/local/python3/bin/python3 /usr/bin/python3
ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3
#设置环境变量
vim /etc/profile
export JAVA_HOME=/apps/jdk/jdk1.8.0_251/jre
export PYSPARK_PYTHON=python3
export SPARK_HOME=/apps/spark/spark-2.3.4-bin-hadoop2.7
export PATH=$PATH:$JAVA_HOME/bin:$SPARK_HOME/bin
source /etc/profile测试:
1)输入:java -version,出现下面则成功

2)输入:python3,出现下面则成功

3)输入:spark-shell ,出现下面则成功

4)输入:pyspark ,出现下面则成功

如果上面都没问题就行了,那就表示sapark和pyspark环境搭建完成。
下面开始配置pycharm 远程连接
#将pysark和py4j包拷贝到site-packages下
#切记 不要pip3 install pyspark ,因为这样会造成版本不一致
cd /apps/spark/spark-2.3.4-bin-hadoop2.7/python/lib
unzip py4j-0.10.7-src.zip -d /usr/local/lib/python3.6/site-packages
unzip pyspark.zip -d /usr/local/lib/python3.6/site-packages
打开pycharm,一定要正式版的,不要社区版,社区版不能建立ssh连接,点击tool-deployment-configuration

打开后,点击+号创建一个SFTP

输入相关信息,点击测试连接,出来连接成功 则表示服务可以连接

点击 mapping,在deployment path 输入服务器的代码地址,设置该路径则可以把本地代码提交到服务器上,一般都放在tmp文件夹中,比如:/tmp/pycharm_project_90
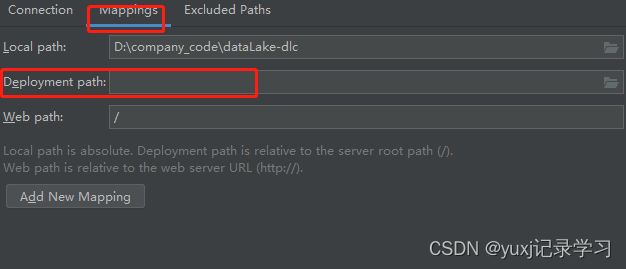
点击OK,即可完成操作
点击,选择刚刚配置好的远程服务


等待加载完成后,就可以把本地运行的pyspark代码
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("test").getOrCreate()
df = spark.read.options(header=True, inferSchema=True, delimiter=',', encoding="utf-8") \
.csv('a.csv')
df.printSchema()
df.show()现在的代码运行在服务器上的local,不是yarn 也不能指定master是yarn,因为没有Hadoop环境,如果想运行在yarn上则需要配置hadoop的环境