深度学习基础知识扫盲
深度学习
- 监督学习(Supervised learning)
-
- 监督学习分类
- 无监督学习(Non-supervised learning)
-
- 无监督学习的算法
- 无监督学习使用场景
- 术语
-
- 特征值
- 特征向量
- 特征工程(Feature engineering)
- 特征缩放
- Sigmod function
- 决策边界
- 激活函数
- 过拟合/欠拟合
- 逻辑回归算法
- 多类(mutil-classes)分类与多标签(multi-lable)分类
- 卷积层(Convolutional Layer)
- 前向传播算法(forward propagation)
- 反向传播算法(back propagation)
- 计算图(computation graph)
- Training Set/ Validation Set/ Test Set
- 高偏差/和高方差
- 正则化项(Lambda)
- 基准性能水平
- 学习曲线(learning curves)
- 数据增强(data augmentation)
- 迁移学习(Transfer learning)
- 准确率/召回率(Precision/recall)
- 调和平均数(harmonic mean)
- 熵(Entrop)
- 信息增益(Information Gain)
监督学习(Supervised learning)
计算机通过示例进行学习,它从过去的数据进行学习,并将学习结果应用到当前数据中,以预测未来事件,在这种情况下,输入和期望的输出数据都有助于预测未来事件。
监督学习分类
- 回归(regressing)模型
通过一系列的训练集,训练出回归算法,来预测新的数据。常见的回归算法有线性回归、逻辑回归、多项式回归和脊回归。 - 分类(classification)模型
分类模型可以对输出的变量进行分类,例如:“是“”否“,用于预测数据的类别。比如垃圾邮件检测、情绪分析。
在现实生活中的一些应用有:
文本分类
- 垃圾邮件检测
- 天气预报
- 根据当前市场价格预测房价
- 股票价格预测等
- 人脸识别
- 签名识别
- 客户发现
无监督学习(Non-supervised learning)
它的本质上是一种统计手段,在没有标签的数据里可以发现潜在的一些结构的一种训练方式。主要具备三个特点:1.没有明确的目的。2.不需要给数据打标签。3.无法量化效果。
无监督学习的算法
- 聚类
简单说就是一种自动分类的方法,在监督学习中,你很清楚每一个分类是什么,但是聚类则不是,你并不清楚聚类后的几个分类每个代表什么意思 - 降维
降维看上去很像压缩。这是为了在尽可能保存相关的结构的同时降低数据的复杂度。
无监督学习使用场景
- 发现异常
有很多违法的行为都需要”洗钱“,这些洗钱行为跟普通用户的行为是不一样的,到底哪里不一样?
如果通过人为去分析是一件成本很高很复杂的事情,我们可以通过这些行为特征对用户进行分类,这样容易能找到行为异常的用户,然后再深入分析他们的行为到底哪里不一样,是否属于违法洗钱的范畴。
通过无监督学习,我们可以快速把行为进行分类,虽然我们不知道这些分类意味着什么,但是通过这种分类,可以快速排出正常的用户,更有针对性的对异常行为进行深入分析。
- 用户细分
这对于广告平台很有意义,我们不仅按照用户的性别、年龄、地理位置等维度对用户进行细分,还可以通过用户的行为对用户进行分类。以便为用户推荐个性化内容。
- 推荐系统
淘宝天猫推荐系统,根据用户的购买行为和浏览行为推荐一些相关产品,有些商品是通过无监督学习的聚类推荐出来的。
术语
特征值
每个数据都有自己的属性,这个独特的属性就是特征值。
特征向量
多个特征值所组成的向量。
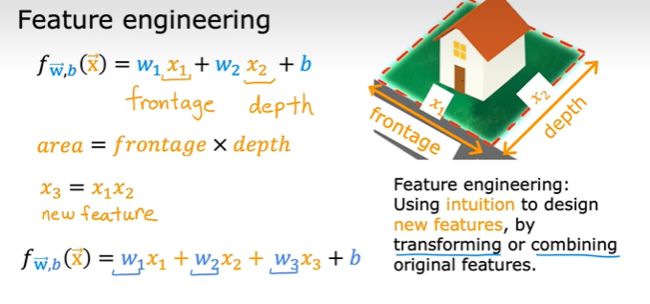
特征工程(Feature engineering)
通过变换或者组合原特征值,使用直觉去设计新的特征值的工程。
根据长和宽,来设计area面积。
特征缩放
因为某些属性的数值过大或过小,影响梯度计算,因此要通过放大或所想来修改特征值到合适的位置。
Sigmod function
通过该函数,可以控制输出值在0~1之间。

决策边界
决策边界有线性的也有非线性的,可有sigmod function函数得来。


激活函数
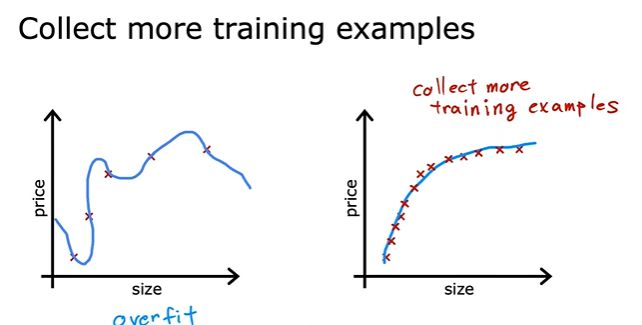
过拟合/欠拟合
过拟合是训练集训练出来的模型,过于贴合实际数据,导致估计值不准确。

如何解决过拟合的问题呢?
-
有更多训练集
-
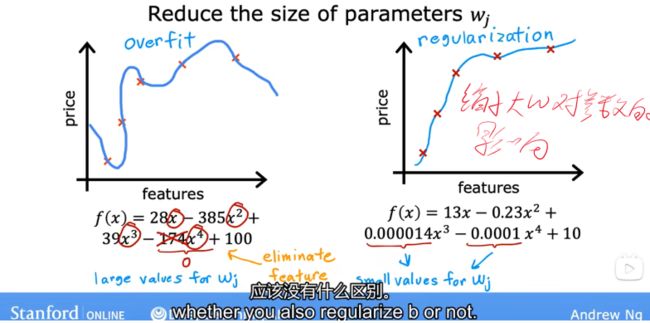
过多特征但训练集少(删除相应特征,缩小大特征的影响)

-
正则化(惩罚所有w值,保证值没有太大偏差)

逻辑回归算法
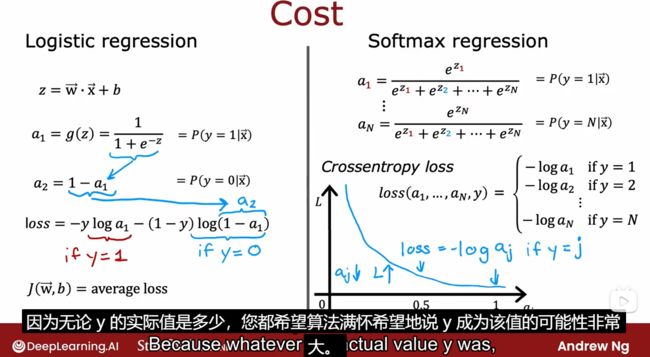
- 逻辑回归函数

- 逻辑回归的成本函数(使用交叉熵来写),aj越接近1,说明估计成本越小。
- 左边是简单的二元分类函数;右边是Siftmax函数,解决多分类的回归问题。
多类(mutil-classes)分类与多标签(multi-lable)分类
mutil-classes classifition 类似于识别一个数字是几,只能是0~9中的一个数字,输出结果是一个数字。
而multi-lable classifition 是一个识别多种标签的问题,输出是一个向量。

卷积层(Convolutional Layer)
每个神经元只查看输入图像区域的层级,称为卷积层。
卷积神经网络:

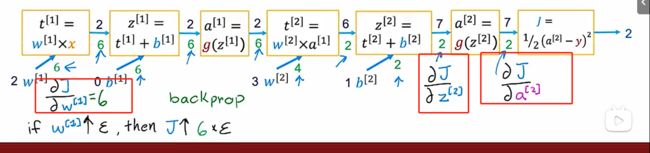
前向传播算法(forward propagation)
通过输入值,假设w和b,一步一步往后计算。
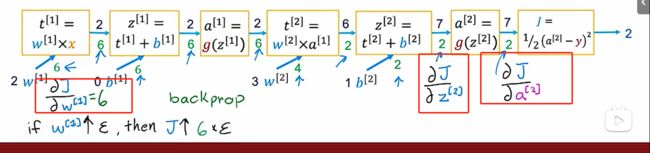
反向传播算法(back propagation)
根据前向传播算法的值,从后往前求偏导
计算图(computation graph)
描述计算过程的图像


Training Set/ Validation Set/ Test Set
训练集:用来训练w,b的参数。生成w,b。
交叉验证集、开发集、验证集:用来选择具体的模型。生成d。
测试集:要有泛化评估能力,不能参与参数生成。

高偏差/和高方差

左图是高偏差,右图是高方差。
- 高偏差不能只增大训练集数据量,没用!!

- 高方差可以增加训练集的数据量,来减小Jcv!!!

针对高方差和高偏差的解决方法:

如何

正则化项(Lambda)
正则化可以调整参数的权重,从而影响fit的效果。
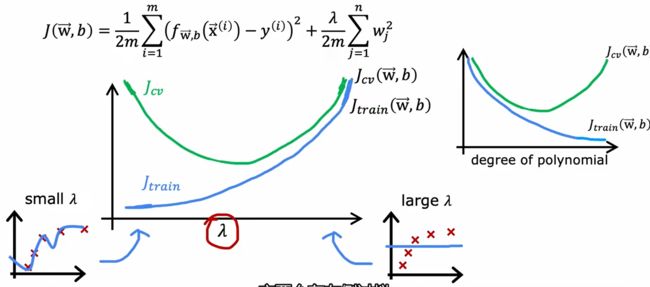
Lambda越大,算法越试图保持平方项越小,正则化项的权重越大,对训练集实际的表现关注越少。(欠拟合);Lambda越小,越过拟合。
基准性能水平
可以合理的希望学习算法最终达到的误差水平;建立基准性能水平常见的是:衡量人在这项任务上的表现;或者是对比其他相似的算法。

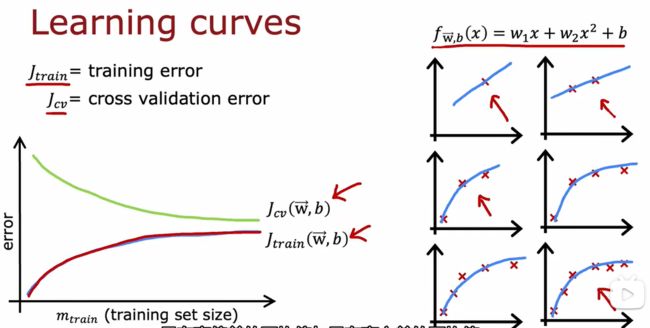
学习曲线(learning curves)
为什么训练集越大,训练集的损失函数越大?
以右面的图为例:数据越多,二次函数越难拟合数据,只有一个数据时,能完美拟合,但当数据越来越越多,损失函数就越大。
为什么验证集的损失函数越来越小呢?
因为训练集越大,越可能准确,因此验证集的损失函数会变小。
数据增强(data augmentation)
通过修改已有的数据,(图片放缩,反转,透视变换、扭曲失真)或者音频变换(添加背景噪音)来变成新的样例。通过这些方法,可以获得更多数据。

迁移学习(Transfer learning)
将别人训练好的模型和网络(包括参数,但不包括output layer的参数,因为结果不一样),完全复制过来,由于output lunits 不同,所以w5,b5不能用,因此用前4组w,b训练第五组‘或者仅仅复制网络,参数自己训练。

方法一:适用训练集较少的情况,数据不够。
方法二:使用训练集较多的情况,数据量充足,自己训练更好。
迁移学习的步骤:

准确率/召回率(Precision/recall)
(稀有病的预测)
Precision:预测的稀有病的准确率,如下表:(越高越好)
recall():在所有得病的人群中,被检测出有病的概率。越高越好。

如何权衡精度与召回率之间的关系:
高精度:更偏向于信任True
高召回:更偏向信任False

调和平均数(harmonic mean)
这种mean更加倾向于较小的平均数:
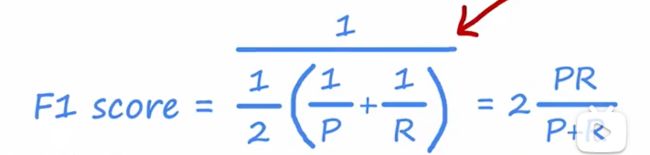

熵(Entrop)
表示一个样本的混乱程度,熵越大,样本越混乱,越不纯。

信息增益(Information Gain)
熵的减少/减少杂质/增大纯度称为信息增益。