Redis学习
Redis
不仅仅是为了面试与工作去学习,要出于兴趣----
如果在使用Typora的时候,出现全屏的情况,按一下F11即可
0先知
- nosql讲解
- 阿里巴巴架构演进
- nosql数据模型
- Nosql四大分类
- cap
- base
- Redis入门
- Redis安装(Windou&Linux服务器)
- 五大基本数据类型
- String
- List
- Set
- Hash
- Zset
- 三种特殊数据类型
- geo
- hyperloglog
- bitmap
- Redis配置文件的详解
- Redis持久化
- RDB
- AOP
- Redis实务操作
- Redis实现订阅发布
- Redis主从复制
- Redis哨兵模式(当下公司中所有的集群都是用这个)
- 缓存穿透及解决方案
- 缓存雪崩及解决方案,(一环头一环,一个崩了,全部完蛋)
- 基础API 值Jedis详解(实现基本的操作)
- springboot 继承Redis操作
- Redis的实践分析
1Nosql概述
我们现在是大数据时代,一般的数据库无法进行分析处理,现在至少需要springboot、springcloud, 压力会越来越大,一定要逼着自己学习,这是在社会上的生存法则。
为什么用Nosql?
单机MySQL年代
用户通过访问APP,app到达DAL(数据库访问层),然后再去访问MySQL;原来90年代的时候,单个数据库足够了;更多的是静态网页Html。
瓶颈:
- 数据量太大,一个机器放不下
- 数据的索引,300万就一定要建立索引,(B+ tree),一个机器内存放不下
- 访问量太大,一个服务器承受不了
Memcached(缓存)+MySQL+垂直拆分(读写分离)
我们可能有多个数据库,让一台数据库承担写的角色,其他的承担读的角色。然而网站80%是在读,所以每次去查询,就会麻烦,所以我们希望减轻数据库的压力,因此使用缓存(Cache)来保证效率!
发展过程:优化数据结构和索引–>文件缓存(IO操作)–>Memcached(以前最为热门的技术)
大厂不缺人,缺少人才。
分库分表+水平拆分+MySQL集群

如今最近的年代
如今信息量井喷式增长,各种各样的数据出现(用户定位数据,图片数据等),大数据的背景下关系型数据库(RDBMS)无法满足大量数据要求。Nosql数据库就能轻松解决这些问题。
目前一个基本的互联网项目

Nosql
Nosql,不仅仅是数据库(SQL)
关系型数据库:表格,行,列
Nosql泛指费关系型数据库,在超大规模的高并发下,诞生了当今Nosql的快速发展趋势,Redis是发展最快的技术
”Boss招聘“,
很多数据类型(用户的个人信息,社交网络,地理位置,这些数据类型的存储,不需要一个固定的格式),不需要多月的操作就能横向拓展! 例如:Map
Nosql特点
- 方便扩展(数据之间没有关系,很好拓展)
- 大数据量,高性能(Redis一秒可以写8万次,读取11万,NoSql的缓存记录级,是一种喜力度的缓存,性能会比较高)
- 数据类形式多样性的(不需要事先设计数据库,随取随用,很多人无法设计了)
- 传统的RDBMX和NoSql
- 传统的RDBMS:结构化组织;基本花SQL;数据和关系都存在单独的表中;操作数据库定义语言;
- Nosql:不仅仅是数据,没有固定的查询语言;简直对查询,列存储,文档存储,图形数据库;最终以党性;CAP定力和BASE初级架构师;高性能,高可用,高可扩展;
了解:3V 和 3高
大数据时代的3V:主要是描述问题
- 海量Volume
- 多样Variety
- 实时Velocity
大数据时代的3高:主要是对程序的要求
- 高并发(用户流量)
- 高可拓(随时水平拆分,机器不够了)
- 高性能(保证用户体验)
在公司中实践:Nosql+RDBMS 一起使用才是最强的,阿里巴巴的架构演进!
真正在公司中的实践:NoSQL + RDBMS 一起使用才是最强的。
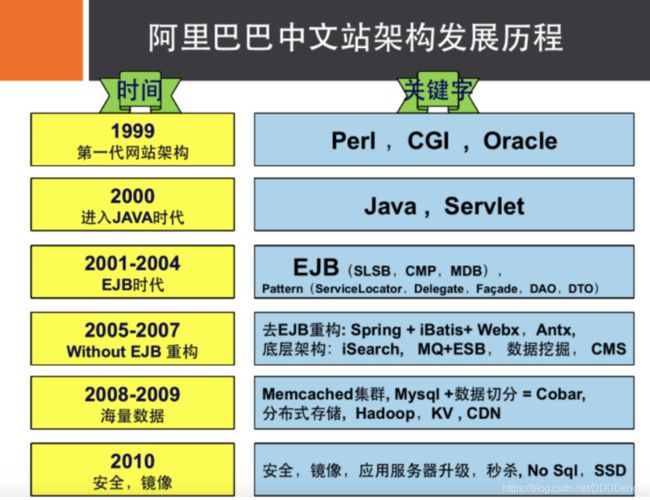
2阿里巴巴演进分析
推荐阅读:阿里云的这群疯子https://yq.aliyun.com/articles/653511
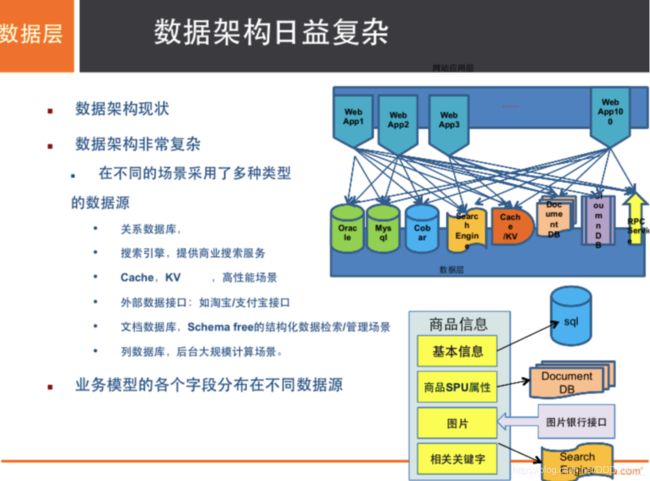
# 商品信息
- 一般存放在关系型数据库:Mysql,阿里巴巴使用的Mysql都是经过内部改动的。
# 商品描述、评论(文字居多)
- 文档型数据库:MongoDB
# 图片
- 分布式文件系统 FastDFS
- 淘宝:TFS
- Google: GFS
- Hadoop: HDFS
- 阿里云: oss
# 商品关键字 用于搜索
- 搜索引擎:solr,elasticsearch
- 阿里:Isearch 多隆
# 商品热门的波段信息
- 内存数据库:Redis,Memcache
# 商品交易,外部支付接口
- 第三方应用
3Nosql的四大分类
KV键值对:
- 新浪:Redis
- 美团:Redis+Tair
- 阿里、百度:Redis+memecache
文档型数据库(bson格式和json一样)
- MongoDB
- MongoDB是一个基于分布式文件存储的数据库,C++编写,主要用来处理大量的文档
- MongoDB是一个介于关系型数据库和非关系型数据库中见得产品!MongoDB是一个费关系型数据库种功能最丰富的,最想关系型数据库的
- ConthDB
列存储数据库
- HBase
- 分布式文件系统
图关系数据库(存储关系的,不是图形,如朋友圈的社交网络)
- Neo4j,InfoGrid
4 Redis入门
概述
Redis是什么?
Redis(Remote Dictionary Server),即远程字典服务!
是一个开源的使用ANSI C语言编写、支持网络、科技与内UC那一刻持久化的日志型、KV数据库,并提供多种语言的API。
免费开源,当下最热门的NoSQL 技术之一,也被人们称之为结构化数据库!
Redis能够干啥?
- 内存存储,持久化,内存是断电即失,所以说持久化很重要(rdb, aof)
- 效率高,可以用于高速缓存
- 发布订阅系统
- 地图信息分析
- 计时器、计数器(浏览量)
Redis 特性
- 多样的数据类型
- 持久化
- 集群
- 事务
需要用到的东西
- Redis官网 Redis
- 中文网redis中文官方网站
- 下载:通过官网,需要在Github上下载
- Redis推荐都是在LINUX服务器上搭建的,我们是基于Linux学习
Windows中下载
-
下载安装包Releases · microsoftarchive/redis (github.com)
-
解压到我们自己的环境下
-
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fnI3DeaL-1626518757387)(C:\Users\AW\Desktop\Redis学习.assets\image-20210707162553436.png)]
-
双击运行服务
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-buKNwv6Y-1626518757389)(C:\Users\AW\Desktop\Redis学习.assets\image-20210707162652797.png)]
- 使用Redis客户单来连接Redis
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wz9nXyGp-1626518757390)(C:\Users\AW\Desktop\Redis学习.assets\image-20210707162915789.png)]
Linux安装
- 下载安装包
Redis-benchmar:是一个压力测试工具
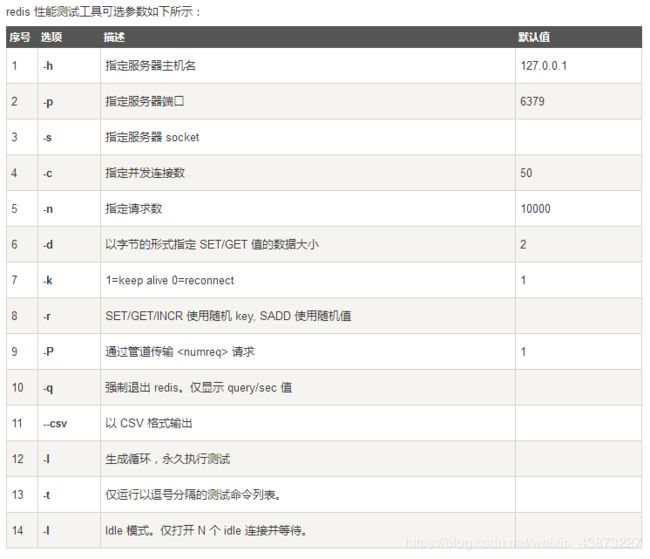
redis-benchmark命令参数,可以来简单地测试一下;
#测试:100个并发连接 10000请求
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
具体的在服务器上演示的代码:
#启动redis的链接
redis-server /wkconfig/redis.conf
#启动我们的链接
redis-cli-p 6379
#进入到我们固有的目录下面,然后看看是否存在
cd /usr/local/bin
ls
#执行我们的测试
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
通过测试,可以帮助我们理解redis能够有多快
5 Redis基础知识
测试一下基本的性能
redis默认有16个数据库(databases=16)
默认使用的是第0个,
可以使用select +数字,来切换到所要前往的数据库!
#查看数据库
select 3
#查看DB大小
DBSIZE
#给当前的数据库设置值
set name wk
select 7
DBSIZE
get name #可见,在其他数据库中是没有的
select 3
get name #这里就能够得到我们的值:wk
#查看当前数据库中的key
keys * #结果会出现我们设置的wk所属于的key(“name”)
#清空全部数据库的内容
FLUSHALL
#清空当前库
flushdb
keys * #如此操作之后,就会发现没有了
selcet 0
keys * #会发现,在默认的数据库之中,会存在一些默认的key
为什么redis选择6379,是开发者的时候,作为一个明星的名字的缩写(粉丝效应)
Redis是单线程的
明白我们的Redis是很快的,官方表示,Redis是基于内存操作,CPU不是redis的性能瓶颈,是依据机器的带宽,既然可以使用单线程来实现,所以就使用了单线程了
为啥呢么单线程这么快?
(前言:Redis是C语言写的,官方提供的数据为100000+的QPS,所以这个不比Memecache差)
误区:
1.高性能的服务器不一定是多线程的
2.多线程不一定比单线程效率高,其中多线程食欲CPU的调度有关的(CPU>内存>硬盘的速度)
3.redis是将所有的数据全部放在内存中的,所以说使用单线程操作的效率就是最高的,而多线程需要的是(cpu的上下文切换的操作),而对于内存系统来说,如果没有上下文切换,那么效率就是最高的!!
多次的读写都是在一个CPU上的,所以单线程的就是最佳的方案
6 五大数据类型,
Redis—key
步骤,先打开redis,然后测试连接;
FLUSHALL,将数据库全部清空,尽量要用英文
EXISTS +key的名字 ,我们现在讲解的所有命令,一定要全部记住
现在我们看一下服务器上原生态使用这些命令
#将位于0,1,2...中的1号移除掉
move name 1
#设置我们名字的过期时间
ketys *
get name
EXPIRE name 10 #意思:命令将会在10后停止
ttl name # 说哦名当前执行,还剩余的时间,可以应用在我们的缓存方面上做用户的Cokkie,
#查看当前key的类型
type +key的名字
后面如果遇到不知道的命令,就去官网查看即可
String
基本的命令
#设置了一个key,是key1;它的值是v1
set key1 v1
get key1
keys *
#判断是否存在key1
EXISTS key1
#在字符串后面去追加东西(返回值是字符串的长度)
APPEND key1 "hello" #如果当前的key不存在,将相当于set key
get key1
#截取字符串,获取其长度(返回值也是长度)
STRLEN key1
#设置浏览量的问题
set views 0
#每一个用户来就加一
incr views
#阅读量减一
decr views
#步长(一次性增加或减少很多个)
INCRBY views 10
DECRBY views 10
#字符串的范围range
set key1 "hello,wk"
GETRANGE key1 0 3 #这个表示截取了0,1,2,3位置的字符串
GETRANGE key1 0 -1 #表示查看所有的字符串
set key2 abcdey
SETRANGE key2 1 xx #表示将原字符串中的b改成了xx
#效率很高,甚至可以远远大过当前的数据库
#setex (set with expire) #设置过期时间
#setnx (set if not exist)#不存在设置 # 在分布式锁中会常常使用
setex key3 30 "hello" #设置了新的key,然后这个key将在30s之后过期
ttl key3 #用来查看这个key还有多长时间过期
setnx mykey "redis" #设置值,如果没有值,就覆盖
#mset 同时设置多个值
#mget 同时获得多个值
mset k1 v1 k2 v2 #这样可以一次性设置多个值
mget k1 k2 #将对应的值批量拿去出来了
msetnx k1 v1 k4 v4 #msetnx是一个验字型的操作,要么一起成功,要么一起失败
#对象
set user:1 {name:zhangsan,age:3} #设置一个user:1对象 职位 json字符串来保存一个对象
mset user:1:name zhangsan user:1:age 2
mget user:1:name user:1:age
#先get再set
getset db redis #输出结果表示,没有redis的db;
get db #显示,我们有了,因为前面的语句在get完了之后会set
getset db mongodb #这个时候,会先get原来的redis,然后在把redis更新成mongodb
数据结构是想通的,未来会学习 Jedis,我们现在的key,会会变成方法
String类似的使用场景:value除了是我们的字符串还可以是我们的后数字
- 计数器
- 统计多单位的数量uid:123:follow 1
- 粉丝数
- 对象缓存存储
List
是一种基本的数据类型,是一种列表,可以变成一个栈
在Redis里,可以把List变成 栈,队列,阻塞队列
注意:Redis不区分大小写
#所有的List命令都是用L开头的
#LPUSH 是将一个值或者是多个值,插入到列表的头部(就是左边)
LPUSH list one
LPUSH list two
LPUSH list three
#lrange是查询获取其中的值
LRANGE list 0 -1 #这种表示是获取全部的值,结果会出现three two one
LRANGE list 0 1 #结果是three two
#Rpush是将一个值或者多个值放在最后面(右边)
Rpush list right
#POP移除一个元素
LPOP #左移除(移除列表的第一个元素,即标号是1的元素)
RPOP #右移除(移除最后一个元素)
#lindex通过下表获得List中的值
lindex list 0
#Llen获取其长度
Llen list #返回列表中的长度
#Lrem移除指定的值
lrem list 1 one #移除列表中的一个one
lrem list 1 three#移除列表中的两个three
#ltrim修剪操作
ltrim mylist 1 2 #结果是:如果有四个元素,0 1 2 3,那么结果就变成了保留原来中间的两个下标为1 2 的元素
#rpoplpush #移除列表中的最后一个元素,并将其添加到另一个列表中
rpoplpush mylist myotherlist#结果是在mylist中没有了最后一个元素,然后被添加到了myotherlist中了
#lset设置值,相当于update
lset list 0 item #如果没有list这个集合,就会报错;下标不存在也不存在,如果存在,就会替换当前值
#linsert 从一个key的前面或后面插入一个指定的值
linsert mylist before "world" "other" #就会在world的前面,插入了
linsert mylist after "world" "hello"
小结
- 实际上是一个链表,before Node after ,right,left 都可以插入值
- 如果key不存在,创建新的链表
- 如果key存在,新增内容
- 如果移除了所有制,空链表,也不存在
- 在两头插入或该冬至,效率最高!中间元素,相对来说效率会低一点
消息排队!消息队列 (从左边进,从右边拿Lpush, Rpop )栈(从左边进去,从左边拿Lpush lpop)
Set
也是一个集合,而且在Set中值不能够重复
都是以S开头的
#sadd向集合中添加元素
sadd myset "hello"
sadd myset "wk的回忆"
sadd myset "lovelike"
#Smembers 查看所有的元素
SMEMBERS myset
#Sismember 判断是否是其中的成员
SISMEMBER myset hello
#Scard 获取set集合中的内容元素个数
scard myset
#Srem 移除集合中的某个值
Srem myset hello
#set 是无序不重复集合,抽随机
#Srandmemert
SRANDMEMBER myset
#spop 随机删除指定的key
spop myset
#Smove 将某个元素从哪里移动到那里
Smove myset myset2 "wkwk"
#共同关注!(并集)
#数字集合类,差集、交集、并集)
sadd key1 a
sadd key1 b
sadd key2 a
sadd key2 c
#差集
Sdiff key1 key2
#交集 (共同好友,微博)
Sinter key1 key2
#并集
Sunion key1 key2
Hash
Map集合,key-Value!这时候这个值就是一个map集合,本质和string类型没有区别
#以H开头
Hset myhash field1 wk
Hget myhash field1
#hmset同时设置多个值
hmset myhash field1 hello field2 world
#hmget同时获取多个值
hmget myhash field1 fild2
#hgetall获取全部的数据
hgetall myhash
#hdel 删除hash制定的key字段,对应的value值也就会消失了
hdel myhash field1
#获取所有的值
hgetall myhash
#Hlen 查看都烧纸
hlen myhash
#Hexists 判断hash中指定字段是否存在
HExists myhash field1
Hexists myhash field3
#只获得所有的field
hkeys myhash
#只获得所有的value
hvals myhash
#HIncr Hdecr
Hincrby myhash field3 1
hincrby myhahs field3 -1
#Hsetnx 如果不存在,就创建;如果存在的话就报错
Hsetnx myhash field4 hello
Hsetnx myhash field4 world
hash 变更的数据 user name age ,尤其是用户信息之类的,经常变动的信息!hash更适合于对象的存储,String 更加适合字符串存储
Zset
有序集合,可以排序,在set的基础上,正加了一个值,set k1 v1
zadd myset 1 one #添加一个或多个值
zadd myset 2 two 3 three
#排序
zadd salary 2500 xiaohong
zadd salary 50000 zhangsan
zadd salary 500 wjwj
ZRANGEBYCORE salary -inf +inf #会按照字母由小到大的顺序排序 inf表示无穷的意思
Zrevrange salary 0 -1 # 从大到小排序
ZRANGEBYCORE salary -inf 2500 withscores# 会将小于2500的值,输出来
ZRANGEBYCORE salary -inf +inf withscores #将从小到大输出来
#zrem移除元素
zrange salary 0 -1
zrem salary xiaohong
zrange salary 0 -1
#查询元素的个数
zcard salary
#zcount 获取指定区间的元素数量
zadd myset 1 hello
zadd myset 2 world 3 wkwk
zcount myset 1 3 # 获取指定区间的元素数量
按理思路:set 排序 存储班级成绩表,工资表排序
普通消息,1重要信息 2 带权重进行判断
排行榜应用实现,取Top N设置
7三种特殊数据类型
geospatial 地理位置
朋友的定位,附近的人,打车距离计算,城市地理经纬度查询
Redis的Geo可以查询一些测试数据 在Redis3.2版本就推出了
相关命令
# geoadd添加地理位置
# 规则:地理上的两级无法直接泰诺健啊,我们一般会下载城市数据,直接通过java程序一次性导入
# 参数:key
geoadd china:city 116.40 39.90 beijing
geoadd china:city 121.47 31.23 shanghai
geoadd china:city 105.20 89.23 chongqing 114.05 22.52 shenzhen
geoadd china:city 120.16 30.34 hangzhou 108.67 23.14 xi`an
#geopos 获取指定城市的经纬度,获得当前定位
GEOPOS china:city beijing
#GEOdist 查看两个城市之间的距离
GEODIST China:city beijing shanghai km
#GEORADIUS以给定的经纬度为中心,找出某一半径内的元素
GEORADIUS china:city 110 30 1000 km #以110 30点为中心的,半径为1000km的城市
GEORADIUS china:city 110 30 500 km withdist #查看半径为500km内的城市及其之间的距离
GEORADIUS china:city 110 30 500 km withcoord #查询半径500km内的城市之间点的坐标
GEORADUIS china:city 110 30 500 km withdist withcoord count 2 #筛选出指定的结果
#找出位于指定元素周围的其他元素
GEORADIUSBYMEMBER china:city beijing 1000 km
#GEOHASH 命令,返回一个或多个位置元素的Geohash表示(该命令返回11个自负的Geohash字符串)
#将而为的经纬度转换为一味地字符串,如果两个字符串越是相像,那么则距离越近
GEOhash china:city beijing chongqing
#Zrange 查询
zrange china:city 0 -1
#Zrem 移除
Zrem china:city beijing
GEO底层的实现原理其实就是Zset,
Hyperloglog
基数:不重复的元素,可以接受误差
简介
更新了Hyperloglog数据结构
Redis hyperloglog 技术统计的算法
优点:占用的内存是固定的,2^64的不同元素的基数,只需要占用12KB内存,如果要从内存角度来比较,Hyperloglog是首选的
网页的UV(一个人放那个问一个网站多次,但是还是算作一个人)
传统的方式:set保存用户的id,然后就可以统计set中的元素数量作为标准判断。这个昂视如果保存大量的用户id,就会编辑哦麻烦,我们的目的是为了技术,而不是保存用户id
0.81% 的错误率,来统计UV任务,可以忽略不计的
#
PFadd mykey a b c d e f g j
PFcount mykey #结果是8个
PFadd mykey2 i j z x c v b n m
PFcount mykey2
#下面的操作是将mykey 和 mykey2 合并成了mykey3
PFmerge mykey3 mykey mykey2
PFcount mykey3 #只会输出不同的元素的个数
如果允许容错,呢么一定可以使用Hyperloglog
如果不允许容错,就是用set或者自己的数据类型即可
Bitmaps
位存储
统计用户信息(活跃,不活跃,登录,未登录),统计疫情情况
Bitmaps位图,数据结构,都是操作二进制位来进行记录,就只有0和1两个状态
365 天 = 365 bit 一字节=八比特
测试
#设置七天之内是否登陆
setbit sign 0 1
setbit sign 1 1
setbit sign 2 0
setbit sign 3 1
setbit sign 4 0
setbit sign 5 1
setbit sign 6 0
#查看某一天是否登录
getbit sign 3
#统计登录的天数
bitcount sign
8事务
Redis单条命令是保存原子性的,但是事务不保证原子性(要么同时成功,要么同时失败,原子性!)
Redis事物本质:一组命令的集合!一个数物种的所有命令都会被序列化,在事务执行过程中,会按照顺序执行!
一次性、顺序性、排他性!执行一些列的命令
Redis的事务:
- 开启事务(multi)
- 命令入队()
- 执行事务(exec)
正常执行事务!
#开启事务
multi
#列出(Queued)相关的命令,让命令入对
set k1 v1
set k2 v2
get k2
set k3 v3
#一次性执行上面的所有命令
exec
multi
set k1 v1
set k2 v2
set k4 v4
discard #取消事务,上面的队列就不会执行了
编译型异常(代码有问题!命令有错),事务中所有的命令都不会被执行
运行时异常(例如:1除以0),如果事务队列中存在语法性,那么执行命令的时候,其他命令是可以正常执行的
监控 Watch
悲观锁:
- 认为什么时候都会出问题,无论做什么都会加锁
乐观锁:
- 乐观,什么时候都不会出现问题,不需要加锁,更新数据的时候判断一下,在此期间是否有人修改过这个数据,
- 获取version
- reids中的watch本身就是一个乐观锁
#银行支出记录
Multi
set money 100
set out 0
watch money
Decrby money 20
INcrby out 20
exec
测试多线程修改值的时候,使用watch可以当做乐观锁操作
watch money#检视money
multi
DECRBY money 10
INCRBY out 10
exec#在另一个线程中修改了值,发现结果失败
如果修改失败,就修改最新的解锁,解 锁
Unwatch#如果发现事务执行失败,就先解锁
Watch money#获取最新的值,再次检视,select version
multi
Decrby money 1
Incrby money 1
exec#比对监视的值是否发生了变化,如果咩有变化,那么可以执行成功,如果便了就执行失败
9Jedis
什么系Jedis?
- 是Redis官方推荐的java连接开发工具!使用java操作redis的中间件
- 所以要对jedis需要十分熟悉
知其然并知其所以然,慢慢来就很快
测试
-
建立一个空项目,wk-redis
-
在里面建立一个新的maven的module
-
导入相应的依赖
<dependencies>
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>3.6.1version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>fastjsonartifactId>
<version>1.2.76version>
dependency>
dependencies>
- 编码测试
- 连接数据库
- 操作命令
- 断开连接
- 建立com.wk.TestPing,进行连接测试
- new一个jedis对象
- jedis的所有命令就是我们之前学习的所有指令
- 指令就变成了现在的方法
- 输入ping,然后得到pong,那么连接成功
常用的API
见上面的五大数据类型 String Set Zset Hash List
10Springboot整合
Springboot操作数据:spring-data jpa jdbc mongodb redis
springData也是和Springboot起名的项目
说明:在springboot之后,我们原来是用的jedis被替换为了lettuce
jedis:底层采用的是智联的操作,多个线程操作的话,数不安全的,如果想要避免不安全,使用jedis pool连接池!更像BIO模式
lettuce:底层采用netty,实例可以再多个线程中进行共享,不存在线程不安全的情况!可以减少线程数据了,更像NIO模式
默认的RedisTemplate没有过多的设置,redis对象都是需要序列化,两个泛型都是object类型,我们需要强制转换
由于String是redis中最常使用的类型,所以说单独提出来一个Bean
整合测试一下
-
导入依赖
<dependency> <groupId>org.springframework.bootgroupId> <artifactId>spring-boot-starter-data-redisartifactId> dependency> -
配置连接
#配置redis spring.redis.host=127.0.0.1 spring.redis.port=6379 -
测试
@Autowired private RedisTemplate redisTemplate; @Test void contextLoads() { //redisTemplate. 操作不用的数据类型,点出来的api跟我们是一样的 //opsForValue 类似String //opsForList 操作List 类似String //opsForHash //opsForGeo //opsForSet //opsForZSet //opsForHyperLogLog //除了基本的操作,我们常用的方法都可以直接通过redisTemplate操作,比如食物,和基本的CRUD // 获取redis的链接对象 // RedisConnection connection = redisTemplate.getConnectionFactory().getConnection(); // connection.flushDb(); // connection.flushAll(); redisTemplate.opsForValue().set("mykey","哇卡哇卡java"); System.out.println(redisTemplate.opsForValue().get("mykey")); } -
编写我们自己写的API
//编写我们自己的配置类RedisTemplate @Bean public RedisTemplate<String,Object> redisTemplate(RedisConnectionFactory redisConnectionFactory)throws UnknownHostException{ RedisTemplate<String, Object> template = new RedisTemplate<>(); template.setConnectionFactory(redisConnectionFactory); return template; } -
RedisTemplate模板,可以直接使用
@Configuration public class RedisConfig { //编写我们自己的配置类RedisTemplate //下方是固定的一个模板,在企业中可以直接使用 @Bean @SuppressWarnings("all") public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) { //为了开发方便,使用注意:1.如果出现重名的情况,就用修饰语 @Qualifier(“redisTemplate”)
2.如果出现在Idea中,可以执行出来,指定的字符串,但是在客户端redis-cli却不可以,那么解决这个问题,就要用到我们的redis-cli了 -
多使用cmd+p查看方法需要的parameter,给进去就好
-
RedisUtils开发
package com.wk.utils; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.stereotype.Component; import org.springframework.util.CollectionUtils; import java.util.Collection; import java.util.List; import java.util.Map; import java.util.Set; import java.util.concurrent.TimeUnit; @Component public class RedisUtils { @Autowired //注入我们自己编写的redisTemplate private RedisTemplate<String, Object> redisTemplate; /** * 制定缓存失效时间 * @param key 键 * @param time 时间(秒) */ public boolean expire(String key, long time) { try { if (time > 0) { redisTemplate.expire(key, time, TimeUnit.SECONDS); } return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 根据key 获取过期时间 * @param key 键 不能为null * @return 时间(秒) 返回0代表为永久有效 */ public long getExpire(String key) { return redisTemplate.getExpire(key, TimeUnit.SECONDS); } /** * 判断key是否存在 * @param key 键 * @return true 存在 false不存在 */ public boolean hasKey(String key) { try { return redisTemplate.hasKey(key); } catch (Exception e) { e.printStackTrace(); return false; } } /** * 删除缓存 * @param key 可以传一个值 或多个 */ @SuppressWarnings("unchecked") public void del(String... key) { if (key != null && key.length > 0) { if (key.length == 1) { redisTemplate.delete(key[0]); } else { redisTemplate.delete((Collection<String>) CollectionUtils.arrayToList(key)); } } } // ============================String============================= /** * 普通缓存获取 * @param key 键 * @return 值 */ public Object get(String key) { return key == null ? null : redisTemplate.opsForValue().get(key); } /** * 普通缓存放入 * @param key 键 * @param value 值 * @return true成功 false失败 */ public boolean set(String key, Object value) { try { redisTemplate.opsForValue().set(key, value); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 普通缓存放入并设置时间 * @param key 键 * @param value 值 * @param time 时间(秒) time要大于0 如果time小于等于0 将设置无限期 * @return true成功 false 失败 */ public boolean set(String key, Object value, long time) { try { if (time > 0) { redisTemplate.opsForValue().set(key, value, time, TimeUnit.SECONDS); } else { set(key, value); } return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 递增 * @param key 键 * @param delta 要增加几(大于0) * @return */ public long incr(String key, long delta) { if (delta < 0) { throw new RuntimeException("递增因子必须大于0"); } return redisTemplate.opsForValue().increment(key, delta); } /** * 递减 * @param key 键 * @param delta 要减少几(小于0) * @return */ public long decr(String key, long delta) { if (delta < 0) { throw new RuntimeException("递减因子必须大于0"); } return redisTemplate.opsForValue().increment(key, -delta); } // ================================Map================================= /** * HashGet * @param key 键 不能为null * @param item 项 不能为null * @return 值 */ public Object hget(String key, String item) { return redisTemplate.opsForHash().get(key, item); } /** * 获取hashKey对应的所有键值 * @param key 键 * @return 对应的多个键值 */ public Map<Object, Object> hmget(String key) { return redisTemplate.opsForHash().entries(key); } /** * HashSet * @param key 键 * @param map 对应多个键值 * @return true 成功 false 失败 */ public boolean hmset(String key, Map<String, Object> map) { try { redisTemplate.opsForHash().putAll(key, map); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * HashSet 并设置时间 * @param key 键 * @param map 对应多个键值 * @param time 时间(秒) * @return true成功 false失败 */ public boolean hmset(String key, Map<String, Object> map, long time) { try { redisTemplate.opsForHash().putAll(key, map); if (time > 0) { expire(key, time); } return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 向一张hash表中放入数据,如果不存在将创建 * @param key 键 * @param item 项 * @param value 值 * @return true 成功 false失败 */ public boolean hset(String key, String item, Object value) { try { redisTemplate.opsForHash().put(key, item, value); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 向一张hash表中放入数据,如果不存在将创建 * @param key 键 * @param item 项 * @param value 值 * @param time 时间(秒) 注意:如果已存在的hash表有时间,这里将会替换原有的时间 * @return true 成功 false失败 */ public boolean hset(String key, String item, Object value, long time) { try { redisTemplate.opsForHash().put(key, item, value); if (time > 0) { expire(key, time); } return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 删除hash表中的值 * @param key 键 不能为null * @param item 项 可以使多个 不能为null */ public void hdel(String key, Object... item) { redisTemplate.opsForHash().delete(key, item); } /** * 判断hash表中是否有该项的值 * @param key 键 不能为null * @param item 项 不能为null * @return true 存在 false不存在 */ public boolean hHasKey(String key, String item) { return redisTemplate.opsForHash().hasKey(key, item); } /** * hash递增 如果不存在,就会创建一个 并把新增后的值返回 * @param key 键 * @param item 项 * @param by 要增加几(大于0) * @return */ public double hincr(String key, String item, double by) { return redisTemplate.opsForHash().increment(key, item, by); } /** * hash递减 * @param key 键 * @param item 项 * @param by 要减少记(小于0) * @return */ public double hdecr(String key, String item, double by) { return redisTemplate.opsForHash().increment(key, item, -by); } // ============================set============================= /** * 根据key获取Set中的所有值 * @param key 键 * @return */ public Set<Object> sGet(String key) { try { return redisTemplate.opsForSet().members(key); } catch (Exception e) { e.printStackTrace(); return null; } } /** * 根据value从一个set中查询,是否存在 * @param key 键 * @param value 值 * @return true 存在 false不存在 */ public boolean sHasKey(String key, Object value) { try { return redisTemplate.opsForSet().isMember(key, value); } catch (Exception e) { e.printStackTrace(); return false; } } /** * 将数据放入set缓存 * @param key 键 * @param values 值 可以是多个 * @return 成功个数 */ public long sSet(String key, Object... values) { try { return redisTemplate.opsForSet().add(key, values); } catch (Exception e) { e.printStackTrace(); return 0; } } /** * 将set数据放入缓存 * @param key 键 * @param time 时间(秒) * @param values 值 可以是多个 * @return 成功个数 */ public long sSetAndTime(String key, long time, Object... values) { try { Long count = redisTemplate.opsForSet().add(key, values); if (time > 0) expire(key, time); return count; } catch (Exception e) { e.printStackTrace(); return 0; } } /** * 获取set缓存的长度 * @param key 键 * @return */ public long sGetSetSize(String key) { try { return redisTemplate.opsForSet().size(key); } catch (Exception e) { e.printStackTrace(); return 0; } } /** * 移除值为value的 * @param key 键 * @param values 值 可以是多个 * @return 移除的个数 */ public long setRemove(String key, Object... values) { try { Long count = redisTemplate.opsForSet().remove(key, values); return count; } catch (Exception e) { e.printStackTrace(); return 0; } } // ===============================list================================= /** * 获取list缓存的内容 * @param key 键 * @param start 开始 * @param end 结束 0 到 -1代表所有值 * @return */ public List<Object> lGet(String key, long start, long end) { try { return redisTemplate.opsForList().range(key, start, end); } catch (Exception e) { e.printStackTrace(); return null; } } /** * 获取list缓存的长度 * @param key 键 * @return */ public long lGetListSize(String key) { try { return redisTemplate.opsForList().size(key); } catch (Exception e) { e.printStackTrace(); return 0; } } /** * 通过索引 获取list中的值 * @param key 键 * @param index 索引 index>=0时, 0 表头,1 第二个元素,依次类推;index<0时,-1,表尾,-2倒数第二个元素,依次类推 * @return */ public Object lGetIndex(String key, long index) { try { return redisTemplate.opsForList().index(key, index); } catch (Exception e) { e.printStackTrace(); return null; } } /** * 将list放入缓存 * @param key 键 * @param value 值 * @param `time 时间(秒) * @return */ public boolean lSet(String key, Object value) { try { redisTemplate.opsForList().rightPush(key, value); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 将list放入缓存 * @param key 键 * @param value 值 * @param time 时间(秒) * @return */ public boolean lSet(String key, Object value, long time) { try { redisTemplate.opsForList().rightPush(key, value); if (time > 0) expire(key, time); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 将list放入缓存 * @param key 键 * @param value 值 * @param `time 时间(秒) * @return */ public boolean lSet(String key, List<Object> value) { try { redisTemplate.opsForList().rightPushAll(key, value); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 将list放入缓存 * * @param key 键 * @param value 值 * @param time 时间(秒) * @return */ public boolean lSet(String key, List<Object> value, long time) { try { redisTemplate.opsForList().rightPushAll(key, value); if (time > 0) expire(key, time); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 根据索引修改list中的某条数据 * @param key 键 * @param index 索引 * @param value 值 * @return */ public boolean lUpdateIndex(String key, long index, Object value) { try { redisTemplate.opsForList().set(key, index, value); return true; } catch (Exception e) { e.printStackTrace(); return false; } } /** * 移除N个值为value * @param key 键 * @param count 移除多少个 * @param value 值 * @return 移除的个数 */ public long lRemove(String key, long count, Object value) { try { Long remove = redisTemplate.opsForList().remove(key, count, value); return remove; } catch (Exception e) { e.printStackTrace(); return 0; } } }
11RedisConfig详解
启动的时候,就通过配置文件来启动
行家有没有,出手就知道
单位
- 配置文件unit单位,对大小写不敏感
包含
可以将多个配置文件都配置到一个
网络
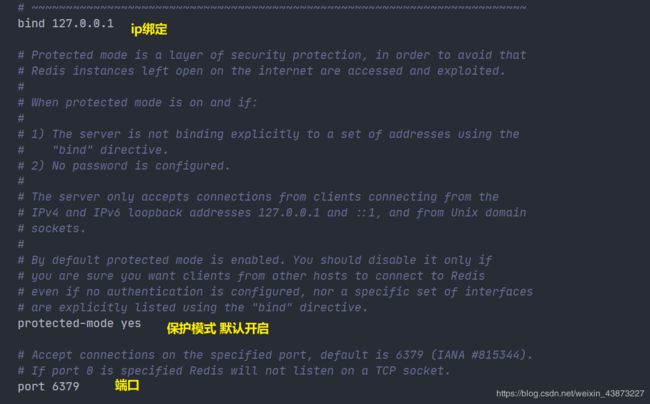
bind 127.0.0.1 #绑定的ip
protected-mode yes #保护模式
port 6379
通用配置 GENERAL
daemonize yes #以守护进程的方式运行,默认是no,我们需要自己开启为yes
pidfile
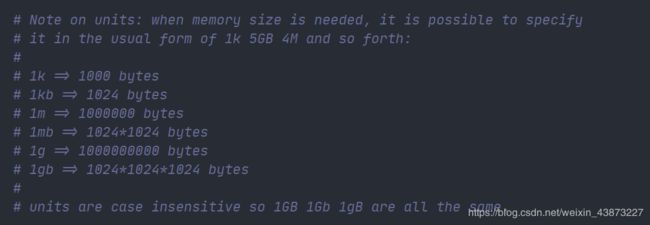
可以使用 include 组合多个配置问题

网络配置
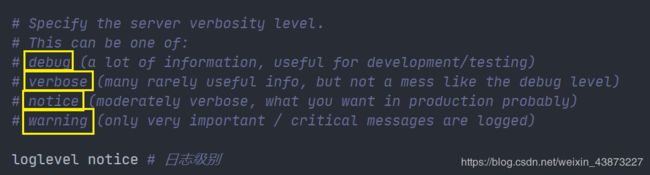
日志输出级别
日志输出文件

持久化规则
由于Redis是基于内存的数据库,需要将数据由内存持久化到文件中
持久化方式:
- RDB
- AOF

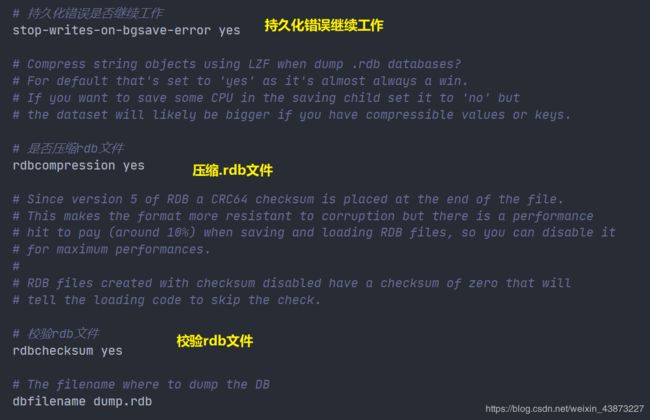
RDB文件相关

主从复制

Security模块中进行密码设置

客户端连接相关
maxclients 10000 最大客户端数量
maxmemory <bytes> 最大内存限制
maxmemory-policy noeviction # 内存达到限制值的处理策略
123
redis 中的默认的过期策略是 volatile-lru 。
设置方式
config set maxmemory-policy volatile-lru
1
maxmemory-policy 六种方式
**1、volatile-lru:**只对设置了过期时间的key进行LRU(默认值)
2、allkeys-lru : 删除lru算法的key
**3、volatile-random:**随机删除即将过期key
**4、allkeys-random:**随机删除
5、volatile-ttl : 删除即将过期的
6、noeviction : 永不过期,返回错误
————————————————
版权声明:本文为CSDN博主「每天进步一點點」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/DDDDeng_/article/details/108118544
AOF相关部分


12Redis持久化(较好)
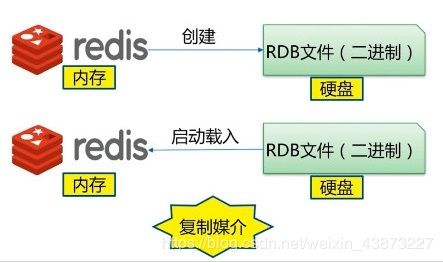
redis是内存数据库,如果不讲内存中的数据库状态保存到磁盘中,那么一旦服务器进程退出,服务器中的状态也会消失,所以redis提供了持久化功能
在指定的时间间隔内,将内存中的数据用快照(snapshot)的方式写入到磁盘中,恢复时是将快照文件直接读到内存中。
Redis单独创建(fork)一个子进程进行持久化,会先将数据写入到一个临时文件中,带持久化过程都结束了,在用这个临时文件替换上次持久化好的文件。整个过程中,住进城市不进行任何IO操作的,这就确保了极高的性能。如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加高效。RDB的却带那是最后一次持久化后的数据可能丢失。我们默认的就是RDB,一般情况下不需要修改这个配置。
触发机制
- save的规则满足的情况下,会自动触发rdb规则
- 执行flushall命令,也会触发我们的人多不规则
- 退出redis也会产生rdb文件
备份集自动生成一个dump.rdb
如何恢复rdb文件
-
只需要将rdb文件放在我们redis启动目录就可以,redis启动的时候会自动检查dump.rdb恢复期中的数据
-
查看需要存在的位置
config get dir -
其自己默认的配置基本够用,但还不够
优点:
- 适合大规模的数据恢复!dump.rdb
- 对数据的完整性不高
缺点:
- 需要一定的时间间隔进行操作,如果redis意外宕机了,最后一次修改的数据就没有了
- fork进程的时候,会占用一定的内存空间
13 AOF(Append Only File)
将我们的所有命令都记录下来,history恢复的时候就把这个文件全部执行一遍
append
默认是不开启的 ,需要手动开启,appendonly 改为yes就开启了aof了
重启我们的redis,就可以生效了
但是如果aof文件有错误,这时候redis是不能启动的,因此我们需要修改这个aof文件
redis给我们通了一个工具redis-check-aof --fix
如果aof文件大于64m,太大,fork一个新的进程来将我们的文件进行重写
aof默认就是文件的无限追加,文件会越来越大
优缺点
优点:
- 每一次修改都同步,文件的完整性会更加好
- 美妙同步一次,可能会丢失一秒的数据
- 从不同步,效率是最高的
缺点:
- 相对于数据文件来说,aof远远大于rdb,修复的素的也比rdb
- aof运行效率也要比rdb慢
| RDB | AOF | |
|---|---|---|
| 启动优先级 | 低 | 高 |
| 体积 | 小 | 大 |
| 恢复速度 | 快 | 慢 |
| 数据安全性 | 丢数据 | 根据策略决定 |
14主从复制
概念
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(Master/Leader),后者称为从节点(Slave/Follower), 数据的复制是单向的!只能由主节点复制到从节点(主节点以写为主、从节点以读为主)。
默认情况下,每台Redis服务器都是主节点,一个主节点可以有0个或者多个从节点,但每个从节点只能由一个主节点。
作用
- 数据冗余:主从复制实现了数决定热备份,是持久化之外的一中数据冗余的方式
- 故障恢复:当主节点故障时,从节点可以暂时替代主节点提供服务,是一种服务冗余的方式
- 负载均衡:当主从复制的基础上,配合读写分离,有主节点进行写操作,从节点进行读操作,分担服务器的附在;尤其是在多度烧写的场景下,通过镀铬从节点分担负载,提高并发量
- 高可用基石:主从复制还是哨兵和集群能够实施的基础
为什么使用集群
- 单台服务器难以负载大量的请求
- 单台服务器故障率高,系统崩坏的概率大
- 单台服务器内存容量有限
环境配置
只配置从库,不用配置主库!
info replication # 查看当前库的信息
# Replication
role:master #角色 master
connnected_slaves:0 # 没有从机
master_replid:b63c90e6c501143759cb0e7f450bd1eb0c70882a
master_replid2:00000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
复制三个配置文件,然后修改对应的信息
- 端口号
- pid名字
- log+文件名字
- dump.rdb名字
修改完毕之后,启动我们的3个redis服务器,可以通过进程信息查看
SLAVEOF host 6379 #让6379当老大
info replication #在主机中查看
真实的主从配置应该是在配置文件里面的,我们在命令行里面进行的,只是暂时的
主机可以进行写,但从机不能写只能读
如果主机断掉了,从机依旧可以查询到,info replication;如果主机又重启了,从机依旧可以直接获取到主机写的信息!
如果是用命令行,来配置的主从,如果重启了,就会变回主机。然后把这个主机变成从机,立马就会从主机中获取值
复制原理
Slave启动成功连接到master后会发送一个sync同步命令
Master接到命令,启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令, 在后台进程执行完毕之后,master将传送整个数据文件到slave,并完成一次完全同步。
全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
增量复制:Master继续将新的所有收集到的修改命令一次传给slave,完成同步
但是只要是重新连接到master,一次完全同步(全量复制)将会被自动执行!我们的数据一定可以在从机中看到
主节点M,创造一个从节点S1,然后让另外一个从节点S2作为S1的从节点,然后,S1便即使M从节点,也是S2的主节点。这时候就实现了主从复制
如果老大再见了,那额我们可以改朝换代,只要再从集中输入:SLAVEOF no one; 便成为了主机,这是手动的然后再info replication ; 如果这个时候原来的老大回来了,那么只是一个光杆司令了
15哨兵模式
自动选择老大的模式
概述
主机从机切换技术的方法是:当主服务器当即后,需要手动吧一台从机服务器切换为主服务器,这就需要人工干预,还会造成一段时间内服务不可用的现象。当我们使用哨兵架构(Sentinel)来解决这一问题
自动谋朝篡位,能后台监控主机是否故障,如果故障了根据投票数自欧东能够将从库转换为主库
哨兵模式是一种特殊的模式,首先Redis提供了烧饼的命令,哨兵是一个独立的进程,作为进程,会独立运行。原理是:哨兵通过发送命令,等待redis服务器相应,从而监控运行的多个Redis实例
哨兵一般有至少三个,=
- 通过发送命令,让Redis服务器返回监控其运行转改,包括主服务器和从服务器
- 当哨兵检测到master宕机,会自动能够将slave切换成为master,然后通过发布订阅模式通知掐的从服务器,修改配置文件,让他们切换主机
然而一个烧饼进程对Redis服务器进行监控,可能会出现问题,我们可以使用多个烧饼进行监控,各个烧饼之间还会进行监控,这样就形成了多哨兵模式
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行failover过程((计算机)故障切换;失效备援(为系统备援能力的一种,当系统中其中一项设备失效而无法运作时,另一项设备即可自动接手原失效系统所执行的工作)),仅仅是哨兵1主管道认为主服务器不可用,这个现象称为主管下线。当后面的邵兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果有一个烧饼发起,进行failover故障转移操作,切换成功后,就会通过发布订阅模式,让各个哨兵把自己金控的从服务器是实现切换主机,这个过程称为客观下线
测试
我们目前的状态是:一主二从
-
配置哨兵配置文件sentinel.conf
在文件中,编辑文件,然后输入:
#sentinel monitor 被监控的名称 hostport 1
sentinel monitor myredis 127.0.0.1 6379 1
1代表主机管了,slave投票看让谁接替成为主机,票数最多的,就会成为主机
- 启动哨兵
从哨兵日志中可以看到相关的修改信息,如果原来的主机现在回来了,那么会变成从机
哨兵模式
优点:
- 哨兵集群,给予主从复制模式,所有的主从配置优点,都有
- 主从可以切换,鼓掌可以转移,系统的可用性就会更好
- 哨兵模式就是主从模式的升级,手动到自动
缺点:
- redis不好在线扩容,集群容量一旦到达上限,在线扩容就十分麻烦
- 实现哨兵模式的配置很麻烦
哨兵模式的全部配置
-
如果哨兵集群
# Example sentinel.conf # 哨兵sentinel实例运行的端口 默认26379 port 26379 # 哨兵sentinel的工作目录 dir /tmp # 哨兵sentinel监控的redis主节点的 ip port # master-name 可以自己命名的主节点名字 只能由字母A-z、数字0-9 、这三个字符".-_"组成。 # quorum 当这些quorum个数sentinel哨兵认为master主节点失联 那么这时 客观上认为主节点失联了 # sentinel monitor总是“failover”, #是“leader”或者“observer”中的一个。 # 参数 from-ip, from-port, to-ip, to-port是用来和旧的master和新的master(即旧的slave)通信的 # 这个脚本应该是通用的,能被多次调用,不是针对性的。 # sentinel client-reconfig-script
16Redis缓存穿透和雪崩
所有读的请求先到缓存中查询,如果缓存中没有,就回去数据库中查,如果还有找到,就会疯狂的去mysql 中查,可能造成恶意攻击
缓存穿透
概念
缓存穿透是:用户要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询,发现也没有,于是本次查询失败,当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库,这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透
解决方案
布隆过滤器
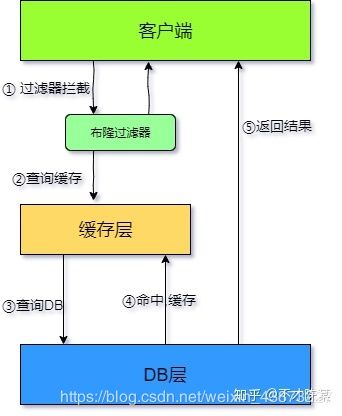
布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层呢个先进行校验,不符合则丢弃,从而避免了对底层存储系统的查询压力;
缓存空对象
一次请求若在缓存和数据库中都没找到,就在缓存中方一个空对象用于处理后续这个请求。
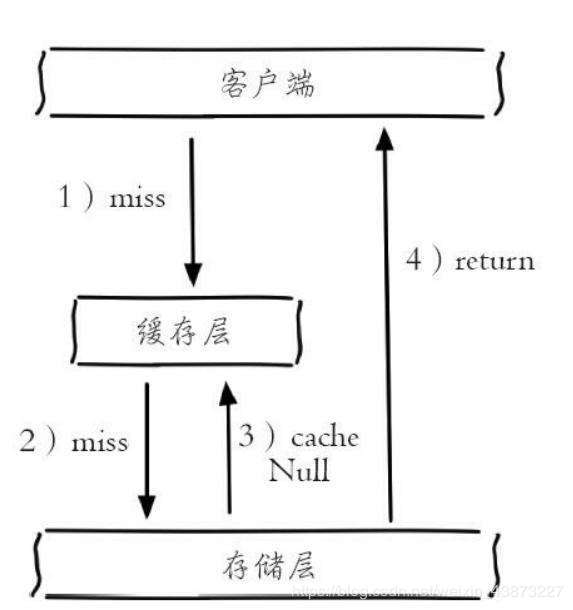
这样做有一个缺陷:存储空对象也需要空间,大量的空对象会耗费一定的空间,存储效率并不高。解决这个缺陷的方式就是设置较短过期时间
即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
缓存击穿(量太大,缓存过期)
概念
相较于缓存穿透,缓存击穿的目的性更强,一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到DB,造成瞬时DB请求量大、压力骤增。这就是缓存被击穿,只是针对其中某个key的缓存不可用而导致击穿,但是其他的key依然可以使用缓存响应。
比如热搜排行上,一个热点新闻被同时大量访问就可能导致缓存击穿。
比如热搜排行上,一个热点新闻被同时大量访问就可能导致缓存击穿。
解决方案
设置热点数据永不过期
这样就不会出现热点数据过期的情况,但是当Redis内存空间满的时候也会清理部分数据,而且此种方案会占用空间,一旦热点数据多了起来,就会占用部分空间。
加互斥锁(分布式锁)
在访问key之前,采用SETNX(set if not exists)来设置另一个短期key来锁住当前key的访问,访问结束再删除该短期key。保证同时刻只有一个线程访问。这样对锁的要求就十分高。
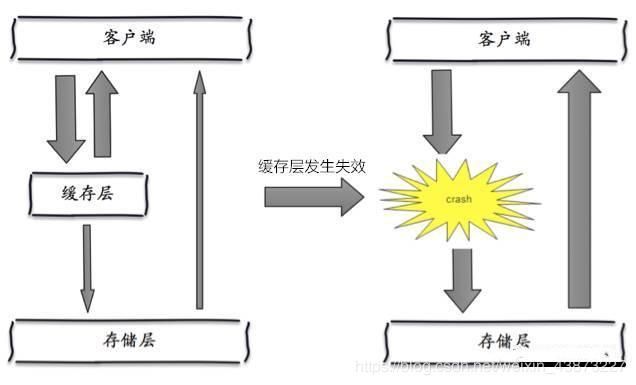
缓存雪崩
概念
大量的key设置了相同的过期时间,导致在缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。
解决方案
redis高可用
这个思想的含义是,既然redis有可能挂掉,那我多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群
限流降级
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
数据预热
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
————————————————
版权声明:本文参考CSDN博主「每天进步一點點」的原创文章,遵循CC 4.0 BY-SA版权协议
原文链接:https://blog.csdn.net/DDDDeng_/article/details/108118544
视频拦截:【狂神说Java】Redis最新超详细版教程通俗易懂_哔哩哔哩_bilibili
念
缓存穿透是:用户要查询一个数据,发现redis内存数据库没有,也就是缓存没有命中,于是向持久层数据库查询,发现也没有,于是本次查询失败,当用户很多的时候,缓存都没有命中,于是都去请求了持久层数据库,这会给持久层数据库造成很大的压力,这时候就相当于出现了缓存穿透
解决方案
布隆过滤器
布隆过滤器是一种数据结构,对所有可能查询的参数以hash形式存储,在控制层呢个先进行校验,不符合则丢弃,从而避免了对底层存储系统的查询压力;
缓存空对象
一次请求若在缓存和数据库中都没找到,就在缓存中方一个空对象用于处理后续这个请求。
这样做有一个缺陷:存储空对象也需要空间,大量的空对象会耗费一定的空间,存储效率并不高。解决这个缺陷的方式就是设置较短过期时间
即使对空值设置了过期时间,还是会存在缓存层和存储层的数据会有一段时间窗口的不一致,这对于需要保持一致性的业务会有影响。
缓存击穿(量太大,缓存过期)
概念
相较于缓存穿透,缓存击穿的目的性更强,一个存在的key,在缓存过期的一刻,同时有大量的请求,这些请求都会击穿到DB,造成瞬时DB请求量大、压力骤增。这就是缓存被击穿,只是针对其中某个key的缓存不可用而导致击穿,但是其他的key依然可以使用缓存响应。
比如热搜排行上,一个热点新闻被同时大量访问就可能导致缓存击穿。
比如热搜排行上,一个热点新闻被同时大量访问就可能导致缓存击穿。
解决方案
设置热点数据永不过期
这样就不会出现热点数据过期的情况,但是当Redis内存空间满的时候也会清理部分数据,而且此种方案会占用空间,一旦热点数据多了起来,就会占用部分空间。
加互斥锁(分布式锁)
在访问key之前,采用SETNX(set if not exists)来设置另一个短期key来锁住当前key的访问,访问结束再删除该短期key。保证同时刻只有一个线程访问。这样对锁的要求就十分高。
缓存雪崩
概念
大量的key设置了相同的过期时间,导致在缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。
解决方案
redis高可用
这个思想的含义是,既然redis有可能挂掉,那我多增设几台redis,这样一台挂掉之后其他的还可以继续工作,其实就是搭建的集群
限流降级
这个解决方案的思想是,在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
数据预热
数据加热的含义就是在正式部署之前,我先把可能的数据先预先访问一遍,这样部分可能大量访问的数据就会加载到缓存中。在即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀。
————————————————
版权声明:本文参考CSDN博主「每天进步一點點」的原创文章,遵循CC 4.0 BY-SA版权协议
原文链接:https://blog.csdn.net/DDDDeng_/article/details/108118544
视频拦截:【狂神说Java】Redis最新超详细版教程通俗易懂_哔哩哔哩_bilibili