面试题:Commonjs 和 Es Module区别
一 前言
今天我们来深度分析一下 Commonjs 和 Es Module,希望通过本文的学习,能够让大家彻底明白 Commonjs 和 Es Module 原理,能够一次性搞定面试中遇到的大部分有关 Commonjs 和 Es Module 的问题。
老规矩我们带上疑问开始今天的分析????????????:
1 Commonjs 和 Es Module 有什么区别 ?
2 Commonjs 如何解决的循环引用问题 ?
3 既然有了
exports,为何又出了module.exports? 既生瑜,何生亮 ?4
require模块查找机制 ?5 Es Module 如何解决循环引用问题 ?
6
exports = {}这种写法为何无效 ?7 关于
import()的动态引入 ?8 Es Module 如何改变模块下的私有变量 ?
9 ...
ps:由于作者前一段时间在写《React进阶实践指南》小册,没有时间持续输出高质量文章,接下来我会回归创作高质量技术文章,送人玫瑰,手有余香,希望阅读的朋友能给作者点个赞????,鼓励我持续创作。
二 模块化
早期 JavaScript 开发很容易存在全局污染和依赖管理混乱问题。这些问题在多人开发前端应用的情况下变得更加棘手。我这里例举一个很常见的场景:
如上在没有模块化的前提下,如果在 html 中这么写,那么就会暴露一系列问题。
全局污染
没有模块化,那么 script 内部的变量是可以相互污染的。比如有一种场景,如上 ./index.js 文件和 ./list.js 文件为小 A 开发的,./home.js 为小 B 开发的。
小 A 在 index.js中声明 name 属性是一个字符串。
var name = '我不是外星人'
然后小 A 在 list.js 中,引用 name 属性,
console.log(name)
打印却发现 name 竟然变成了一个函数。刚开始小 A 不知所措,后来发现在小 B 开发的 home.js 文件中这么写道:
function name(){
//...
}
而且这个 name 方法被引用了多次,导致一系列的连锁反应。
上述例子就是没有使用模块化开发,造成的全局污染的问题,每个加载的 js 文件都共享变量。当然在实际的项目开发中,可以使用匿名函数自执行的方式,形成独立的块级作用域解决这个问题。
只需要在 home.js 中这么写道:
(function (){
function name(){
//...
}
})()
这样小 A 就能正常在 list.js 中获取 name 属性。但是这只是一个 demo ,我们不能保证在实际开发中情况会更加复杂。所以不使用模块开发会暴露出很多风险。
依赖管理
依赖管理也是一个难以处理的问题。还是如上的例子,正常情况下,执行 js 的先后顺序就是 script 标签排列的前后顺序。那么如何三个 js 之间有依赖关系,那么应该如何处理呢?
假设三个 js 中,都有一个公共方法 fun1 , fun2 , fun3。三者之间的依赖关系如下图所示。
下层 js 能调用上层 js 的方法,但是上层 js 无法调用下层 js 的方法。
 3.jpg
3.jpg
所以就需要模块化来解决上述的问题,今天我们就重点讲解一下前端模块化的两个重要方案:Commonjs 和 Es Module
三 Commonjs
Commonjs 的提出,弥补 Javascript 对于模块化,没有统一标准的缺陷。nodejs 借鉴了 Commonjs 的 Module ,实现了良好的模块化管理。
目前 commonjs 广泛应用于以下几个场景:
Node是 CommonJS 在服务器端一个具有代表性的实现;Browserify是 CommonJS 在浏览器中的一种实现;webpack打包工具对 CommonJS 的支持和转换;也就是前端应用也可以在编译之前,尽情使用 CommonJS 进行开发。
1 commonjs 使用与原理
在使用 规范下,有几个显著的特点。
在
commonjs中每一个 js 文件都是一个单独的模块,我们可以称之为 module;该模块中,包含 CommonJS 规范的核心变量: exports、module.exports、require;
exports 和 module.exports 可以负责对模块中的内容进行导出;
require 函数可以帮助我们导入其他模块(自定义模块、系统模块、第三方库模块)中的内容;
commonjs 使用初体验
导出:我们先尝试这导出一个模块:
hello.js中
let name = '《React进阶实践指南》'
module.exports = function sayName (){
return name
}
导入:接下来简单的导入:
home.js
const sayName = require('./hello.js')
module.exports = function say(){
return {
name:sayName(),
author:'我不是外星人'
}
}
如上就是 Commonjs 最简单的实现,那么暴露出两个问题:
如何解决变量污染的问题。
module.exports,exports,require 三者是如何工作的?又有什么关系?
commonjs 实现原理
首先从上述得知每个模块文件上存在 module,exports,require三个变量,然而这三个变量是没有被定义的,但是我们可以在 Commonjs 规范下每一个 js 模块上直接使用它们。在 nodejs 中还存在 __filename 和 __dirname 变量。
如上每一个变量代表什么意思呢:
module记录当前模块信息。require引入模块的方法。exports当前模块导出的属性
在编译的过程中,实际 Commonjs 对 js 的代码块进行了首尾包装, 我们以上述的 home.js 为例子????,它被包装之后的样子如下:
(function(exports,require,module,__filename,__dirname){
const sayName = require('./hello.js')
module.exports = function say(){
return {
name:sayName(),
author:'我不是外星人'
}
}
})
在 Commonjs 规范下模块中,会形成一个包装函数,我们写的代码将作为包装函数的执行上下文,使用的
require,exports,module本质上是通过形参的方式传递到包装函数中的。
那么包装函数本质上是什么样子的呢?
function wrapper (script) {
return '(function (exports, require, module, __filename, __dirname) {' +
script +
'\n})'
}
包装函数执行。
const modulefunction = wrapper(`
const sayName = require('./hello.js')
module.exports = function say(){
return {
name:sayName(),
author:'我不是外星人'
}
}
`)
如上模拟了一个包装函数功能, script 为我们在 js 模块中写的内容,最后返回的就是如上包装之后的函数。当然这个函数暂且是一个字符串。
runInThisContext(modulefunction)(module.exports, require, module, __filename, __dirname)
在模块加载的时候,会通过 runInThisContext (可以理解成 eval ) 执行
modulefunction,传入require,exports,module等参数。最终我们写的 nodejs 文件就这么执行了。
到此为止,完成了整个模块执行的原理。接下来我们来分析以下 require 文件加载的流程。
2 require 文件加载流程
上述说了 commonjs 规范大致的实现原理,接下来我们分析一下, require 如何进行文件的加载的。
我们还是以 nodejs 为参考,比如如下代码片段中:
const fs = require('fs') // ①核心模块
const sayName = require('./hello.js') //② 文件模块
const crypto = require('crypto-js') // ③第三方自定义模块
如上代码片段中:
① 为 nodejs 底层的核心模块。
② 为我们编写的文件模块,比如上述
sayName③ 为我们通过 npm 下载的第三方自定义模块,比如
crypto-js。
当 require 方法执行的时候,接收的唯一参数作为一个标识符 ,Commonjs 下对不同的标识符,处理流程不同,但是目的相同,都是找到对应的模块。
require 加载标识符原则
首先我们看一下 nodejs 中对标识符的处理原则。
首先像 fs ,http ,path 等标识符,会被作为 nodejs 的核心模块。
./和../作为相对路径的文件模块,/作为绝对路径的文件模块。非路径形式也非核心模块的模块,将作为自定义模块。
核心模块的处理:
核心模块的优先级仅次于缓存加载,在 Node 源码编译中,已被编译成二进制代码,所以加载核心模块,加载过程中速度最快。
路径形式的文件模块处理:
已 ./ ,../ 和 / 开始的标识符,会被当作文件模块处理。require() 方法会将路径转换成真实路径,并以真实路径作为索引,将编译后的结果缓存起来,第二次加载的时候会更快。至于怎么缓存的?我们稍后会讲到。
自定义模块处理:自定义模块,一般指的是非核心的模块,它可能是一个文件或者一个包,它的查找会遵循以下原则:
在当前目录下的
node_modules目录查找。如果没有,在父级目录的
node_modules查找,如果没有在父级目录的父级目录的node_modules中查找。沿着路径向上递归,直到根目录下的
node_modules目录。在查找过程中,会找
package.json下 main 属性指向的文件,如果没有package.json,在 node 环境下会以此查找index.js,index.json,index.node。
查找流程图如下所示:
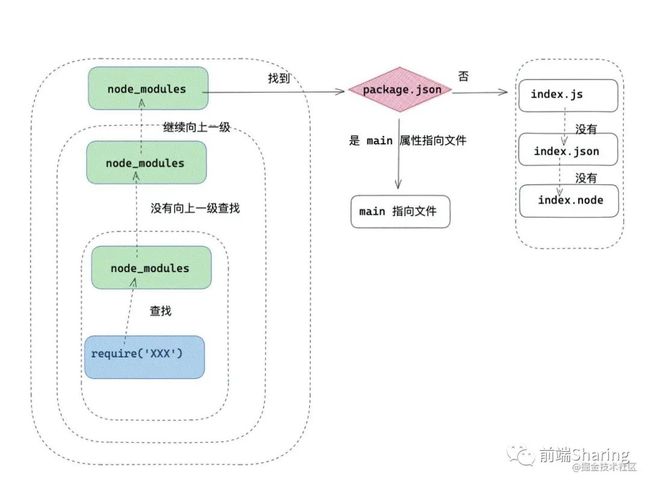 4.jpg
4.jpg
3 require 模块引入与处理
CommonJS 模块同步加载并执行模块文件,CommonJS 模块在执行阶段分析模块依赖,采用深度优先遍历(depth-first traversal),执行顺序是父 -> 子 -> 父;
为了搞清除 require 文件引入流程。我们接下来再举一个例子,这里注意一下细节:
a.js文件
const getMes = require('./b')
console.log('我是 a 文件')
exports.say = function(){
const message = getMes()
console.log(message)
}
b.js文件
const say = require('./a')
const object = {
name:'《React进阶实践指南》',
author:'我不是外星人'
}
console.log('我是 b 文件')
module.exports = function(){
return object
}
主文件
main.js
const a = require('./a')
const b = require('./b')
console.log('node 入口文件')
接下来终端输入 node main.js 运行 main.js,效果如下:
 5.jpg
5.jpg
从上面的运行结果可以得出以下结论:
main.js和a.js模块都引用了b.js模块,但是b.js模块只执行了一次。a.js模块 和b.js模块互相引用,但是没有造成循环引用的情况。执行顺序是父 -> 子 -> 父;
那么 Common.js 规范是如何实现上述效果的呢?
require 加载原理
首先为了弄清楚上述两个问题。我们要明白两个感念,那就是 module 和 Module。
module :在 Node 中每一个 js 文件都是一个 module ,module 上保存了 exports 等信息之外,还有一个 loaded 表示该模块是否被加载。
为
false表示还没有加载;为
true表示已经加载
Module :以 nodejs 为例,整个系统运行之后,会用 Module 缓存每一个模块加载的信息。
require 的源码大致长如下的样子:
// id 为路径标识符
function require(id) {
/* 查找 Module 上有没有已经加载的 js 对象*/
const cachedModule = Module._cache[id]
/* 如果已经加载了那么直接取走缓存的 exports 对象 */
if(cachedModule){
return cachedModule.exports
}
/* 创建当前模块的 module */
const module = { exports: {} ,loaded: false , ...}
/* 将 module 缓存到 Module 的缓存属性中,路径标识符作为 id */
Module._cache[id] = module
/* 加载文件 */
runInThisContext(wrapper('module.exports = "123"'))(module.exports, require, module, __filename, __dirname)
/* 加载完成 *//
module.loaded = true
/* 返回值 */
return module.exports
}
从上面我们总结出一次 require 大致流程是这样的;
require 会接收一个参数——文件标识符,然后分析定位文件,分析过程我们上述已经讲到了,加下来会从 Module 上查找有没有缓存,如果有缓存,那么直接返回缓存的内容。
如果没有缓存,会创建一个 module 对象,缓存到 Module 上,然后执行文件,加载完文件,将 loaded 属性设置为 true ,然后返回 module.exports 对象。借此完成模块加载流程。
模块导出就是 return 这个变量的其实跟 a = b 赋值一样, 基本类型导出的是值, 引用类型导出的是引用地址。
exports 和 module.exports 持有相同引用,因为最后导出的是 module.exports, 所以对 exports 进行赋值会导致 exports 操作的不再是 module.exports 的引用。
require 避免重复加载
从上面我们可以直接得出,require 如何避免重复加载的,首先加载之后的文件的 module 会被缓存到 Module 上,比如一个模块已经 require 引入了 a 模块,如果另外一个模块再次引用 a ,那么会直接读取缓存值 module ,所以无需再次执行模块。
对应 demo 片段中,首先 main.js 引用了 a.js ,a.js 中 require 了 b.js 此时 b.js 的 module 放入缓存 Module 中,接下来 main.js 再次引用 b.js ,那么直接走的缓存逻辑。所以 b.js 只会执行一次,也就是在 a.js 引入的时候。
require 避免循环引用
那么接下来这个循环引用问题,也就很容易解决了。为了让大家更清晰明白,那么我们接下来一起分析整个流程。
① 首先执行
node main.js,那么开始执行第一行require(a.js);② 那么首先判断
a.js有没有缓存,因为没有缓存,先加入缓存,然后执行文件 a.js (需要注意 是先加入缓存, 后执行模块内容);③ a.js 中执行第一行,引用 b.js。
④ 那么判断
b.js有没有缓存,因为没有缓存,所以加入缓存,然后执行 b.js 文件。⑤ b.js 执行第一行,再一次循环引用
require(a.js)此时的 a.js 已经加入缓存,直接读取值。接下来打印console.log('我是 b 文件'),导出方法。⑥ b.js 执行完毕,回到 a.js 文件,打印
console.log('我是 a 文件'),导出方法。⑦ 最后回到
main.js,打印console.log('node 入口文件')完成这个流程。
不过这里我们要注意问题:
如上第 ⑤ 的时候,当执行 b.js 模块的时候,因为 a.js 还没有导出
say方法,所以 b.js 同步上下文中,获取不到 say。
我用一幅流程图描述上述过程:
 15.jpg
15.jpg
为了进一步验证上面所说的,我们改造一下 b.js 如下:
const say = require('./a')
const object = {
name:'《React进阶实践指南》',
author:'我不是外星人'
}
console.log('我是 b 文件')
console.log('打印 a 模块' , say)
setTimeout(()=>{
console.log('异步打印 a 模块' , say)
},0)
module.exports = function(){
return object
}
打印结果:
 6.jpg
6.jpg
第一次打印 say 为空对象。
第二次打印 say 才看到 b.js 导出的方法。
那么如何获取到 say 呢,有两种办法:
一是用动态加载 a.js 的方法,马上就会讲到。
二个就是如上放在异步中加载。
我们注意到 a.js 是用 exports.say 方式导出的,如果 a.js 用 module.exports 结果会有所不同。至于有什么不同,为什么?我接下来会讲到。
4 require 动态加载
上述我们讲了 require 查找文件和加载流程。接下来介绍 commonjs 规范下的 require 的另外一个特性——动态加载。
require 可以在任意的上下文,动态加载模块。我对上述 a.js 修改。
a.js:
console.log('我是 a 文件')
exports.say = function(){
const getMes = require('./b')
const message = getMes()
console.log(message)
}
main.js:
const a = require('./a')
a.say()
如上在 a.js 模块的 say 函数中,用 require 动态加载 b.js 模块。然后执行在 main.js 中执行 a.js 模块的 say 方法。
打印结果如下:
 7.jpg
7.jpg
require 本质上就是一个函数,那么函数可以在任意上下文中执行,来自由地加载其他模块的属性方法。
5 exports 和 module.exports
系统分析完 require ,接下来我们分析一下,exports 和 module.exports,首先看一下两个的用法。
exports 使用
第一种方式:exportsa.js
exports.name = `《React进阶实践指南》`
exports.author = `我不是外星人`
exports.say = function (){
console.log(666)
}
引用
const a = require('./a')
console.log(a)
打印结果:
 8.jpg
8.jpg
exports 就是传入到当前模块内的一个对象,本质上就是
module.exports。
问题:为什么 exports={} 直接赋值一个对象就不可以呢? 比如我们将如上 a.js 修改一下:
exports={
name:'《React进阶实践指南》',
author:'我不是外星人',
say(){
console.log(666)
}
}
打印结果:
 9.jpg
9.jpg
理想情况下是通过 exports = {} 直接赋值,不需要在 exports.a = xxx 每一个属性,但是如上我们看到了这种方式是无效的。为什么会这样?实际这个是 js 本身的特性决定的。
通过上述讲解都知道 exports , module 和 require 作为形参的方式传入到 js 模块中。我们直接 exports = {} 修改 exports ,等于重新赋值了形参,那么会重新赋值一份,但是不会在引用原来的形参。举一个简单的例子
function wrap (myExports){
myExports={
name:'我不是外星人'
}
}
let myExports = {
name:'alien'
}
wrap(myExports)
console.log(myExports)
打印:
 10.jpg
10.jpg
我们期望修改 myExports ,但是没有任何作用。
假设 wrap 就是 Commonjs 规范下的包装函数,我们的 js 代码就是包装函数内部的内容。当我们把 myExports 对象传进去,但是直接赋值 myExports = { name:'我不是外星人' } 没有任何作用,相等于内部重新声明一份 myExports 而和外界的 myExports 断绝了关系。所以解释了为什么不能 exports={...} 直接赋值。
那么解决上述也容易,只需要函数中像 exports.name 这么写就可以了。
function wrap (myExports){
myExports.name='我不是外星人'
}
打印:
 11.jpg
11.jpg
module.exports 使用
module.exports 本质上就是 exports ,我们用 module.exports 来实现如上的导出。
module.exports ={
name:'《React进阶实践指南》',
author:'我不是外星人',
say(){
console.log(666)
}
}
module.exports 也可以单独导出一个函数或者一个类。比如如下:
module.exports = function (){
// ...
}
从上述 require 原理实现中,我们知道了 exports 和 module.exports 持有相同引用,因为最后导出的是 module.exports 。那么这就说明在一个文件中,我们最好选择 exports 和 module.exports 两者之一,如果两者同时存在,很可能会造成覆盖的情况发生。比如如下情况:
exports.name = 'alien' // 此时 exports.name 是无效的
module.exports ={
name:'《React进阶实践指南》',
author:'我不是外星人',
say(){
console.log(666)
}
}
上述情况下 exports.name 无效,会被
module.exports覆盖。
Q & A
1 那么问题来了?既然有了 exports,为何又出了 module.exports?
答:如果我们不想在 commonjs 中导出对象,而是只导出一个类或者一个函数再或者其他属性的情况,那么 module.exports 就更方便了,如上我们知道 exports 会被初始化成一个对象,也就是我们只能在对象上绑定属性,但是我们可以通过 module.exports 自定义导出出对象外的其他类型元素。
let a = 1
module.exports = a // 导出函数
module.exports = [1,2,3] // 导出数组
module.exports = function(){} //导出方法
2 与 exports 相比,module.exports 有什么缺陷 ?
答:module.exports 当导出一些函数等非对象属性的时候,也有一些风险,就比如循环引用的情况下。对象会保留相同的内存地址,就算一些属性是后绑定的,也能间接通过异步形式访问到。但是如果 module.exports 为一个非对象其他属性类型,在循环引用的时候,就容易造成属性丢失的情况发生了。
四 Es Module
Nodejs 借鉴了 Commonjs 实现了模块化 ,从 ES6 开始, JavaScript 才真正意义上有自己的模块化规范,
Es Module 的产生有很多优势,比如:
借助
Es Module的静态导入导出的优势,实现了tree shaking。Es Module还可以import()懒加载方式实现代码分割。
在 Es Module 中用 export 用来导出模块,import 用来导入模块。但是 export 配合 import 会有很多种组合情况,接下来我们逐一分析一下。
导出 export 和导入 import
所有通过 export 导出的属性,在 import 中可以通过结构的方式,解构出来。
export 正常导出,import 导入
导出模块:a.js
const name = '《React进阶实践指南》'
const author = '我不是外星人'
export { name, author }
export const say = function (){
console.log('hello , world')
}
导入模块:main.js
// name , author , say 对应 a.js 中的 name , author , say
import { name , author , say } from './a.js'
export { }, 与变量名绑定,命名导出。
import { } from 'module', 导入
module的命名导出 ,module 为如上的./a.js这种情况下 import { } 内部的变量名称,要与 export { } 完全匹配。
默认导出 export default
导出模块:a.js
const name = '《React进阶实践指南》'
const author = '我不是外星人'
const say = function (){
console.log('hello , world')
}
export default {
name,
author,
say
}
导入模块:main.js
import mes from './a.js'
console.log(mes) //{ name: '《React进阶实践指南》',author:'我不是外星人', say:Function }
export default anything导入 module 的默认导出。anything可以是函数,属性方法,或者对象。对于引入默认导出的模块,
import anyName from 'module', anyName 可以是自定义名称。
混合导入|导出
ES6 module 可以使用 export default 和 export 导入多个属性。
导出模块:a.js
export const name = '《React进阶实践指南》'
export const author = '我不是外星人'
export default function say (){
console.log('hello , world')
}
导入模块:main.js 中有几种导入方式:
第一种:
import theSay , { name, author as bookAuthor } from './a.js'
console.log(
theSay, // ƒ say() {console.log('hello , world') }
name, // "《React进阶实践指南》"
bookAuthor // "我不是外星人"
)
第二种:
import theSay, * as mes from './a'
console.log(
theSay, // ƒ say() { console.log('hello , world') }
mes // { name:'《React进阶实践指南》' , author: "我不是外星人" ,default: ƒ say() { console.log('hello , world') } }
)
导出的属性被合并到
mes属性上,export被导入到对应的属性上,export default导出内容被绑定到default属性上。theSay也可以作为被export default导出属性。
重属名导入
import { bookName as name, say, bookAuthor as author } from 'module'
console.log( bookName , bookAuthor , say ) //《React进阶实践指南》 我不是外星人
从 module 模块中引入 name ,并重命名为 bookName ,从 module 模块中引入 author ,并重命名为 bookAuthor。然后在当前模块下,使用被重命名的名字。
重定向导出
可以把当前模块作为一个中转站,一方面引入 module 内的属性,然后把属性再给导出去。
export * from 'module' // 第一种方式
export { name, author, ..., say } from 'module' // 第二种方式
export { bookName as name, bookAuthor as author, ..., say } from 'module' //第三种方式
第一种方式:重定向导出 module 中的所有导出属性, 但是不包括
module内的default属性。第二种方式:从 module 中导入 name ,author ,say 再以相同的属性名,导出。
第三种方式:从 module 中导入 name ,重属名为 bookName 导出,从 module 中导入 author ,重属名为 bookAuthor 导出,正常导出 say 。
无需导入模块,只运行模块
import 'module'
执行 module 不导出值 多次调用
module只运行一次。
动态导入
const promise = import('module')
import('module'),动态导入返回一个Promise。为了支持这种方式,需要在 webpack 中做相应的配置处理。
ES6 module 特性
接下来我们重点分析一下 ES6 module 一些重要特性。
1 静态语法
ES6 module 的引入和导出是静态的,import 会自动提升到代码的顶层 ,import , export 不能放在块级作用域或条件语句中。
????错误写法一:
function say(){
import name from './a.js'
export const author = '我不是外星人'
}
????错误写法二:
isexport && export const name = '《React进阶实践指南》'
这种静态语法,在编译过程中确定了导入和导出的关系,所以更方便去查找依赖,更方便去 tree shaking (摇树) , 可以使用 lint 工具对模块依赖进行检查,可以对导入导出加上类型信息进行静态的类型检查。
import 的导入名不能为字符串或在判断语句,下面代码是错误的
????错误写法三:
import 'defaultExport' from 'module'
let name = 'Export'
import 'default' + name from 'module'
2 执行特性
ES6 module 和 Common.js 一样,对于相同的 js 文件,会保存静态属性。
但是与 Common.js 不同的是 ,CommonJS 模块同步加载并执行模块文件,ES6 模块提前加载并执行模块文件,ES6 模块在预处理阶段分析模块依赖,在执行阶段执行模块,两个阶段都采用深度优先遍历,执行顺序是子 -> 父。
为了验证这一点,看一下如下 demo。
main.js
console.log('main.js开始执行')
import say from './a'
import say1 from './b'
console.log('main.js执行完毕')
a.js
import b from './b'
console.log('a模块加载')
export default function say (){
console.log('hello , world')
}
b.js
console.log('b模块加载')
export default function sayhello(){
console.log('hello,world')
}
main.js和a.js都引用了b.js模块,但是 b 模块也只加载了一次。执行顺序是子 -> 父
效果如下:
 12.jpg
12.jpg
3 导出绑定
不能修改import导入的属性
a.js
export let num = 1
export const addNumber = ()=>{
num++
}
main.js中
import { num , addNumber } from './a'
num = 2
如果直接修改,那么会报错。如下所示:
 属性绑定
属性绑定
所以可以在 main.js 中这么修改。
import { num , addNumber } from './a'
console.log(num) // num = 1
addNumber()
console.log(num) // num = 2
如上属性 num 的导入是绑定的。
接下来对 import 属性作出总结:
使用 import 被导入的模块运行在严格模式下。
使用 import 被导入的变量是只读的,可以理解默认为 const 装饰,无法被赋值
使用 import 被导入的变量是与原变量绑定/引用的,可以理解为 import 导入的变量无论是否为基本类型都是引用传递。
import() 动态引入
import() 返回一个 Promise 对象, 返回的 Promise 的 then 成功回调中,可以获取模块的加载成功信息。我们来简单看一下 import() 是如何使用的。
main.js
setTimeout(() => {
const result = import('./b')
result.then(res=>{
console.log(res)
})
}, 0);
b.js
export const name ='alien'
export default function sayhello(){
console.log('hello,world')
}
打印如下:
 13.jpg
13.jpg
从打印结果可以看出 import()的基本特性。
import()可以动态使用,加载模块。import()返回一个Promise,成功回调 then 中可以获取模块对应的信息。name对应 name 属性,default代表export default。__esModule为 es module 的标识。
import() 可以做一些什么
动态加载
首先
import()动态加载一些内容,可以放在条件语句或者函数执行上下文中。
if(isRequire){
const result = import('./b')
}
懒加载
import()可以实现懒加载,举个例子 vue 中的路由懒加载;
[
{
path: 'home',
name: '首页',
component: ()=> import('./home') ,
},
]
React中动态加载
const LazyComponent = React.lazy(()=>import('./text'))
class index extends React.Component{
render(){
return React.lazy 和 Suspense 配合一起用,能够有动态加载组件的效果。React.lazy 接受一个函数,这个函数需要动态调用 import() 。
import() 这种加载效果,可以很轻松的实现代码分割。避免一次性加载大量 js 文件,造成首次加载白屏时间过长的情况。
tree shaking 实现
Tree Shaking 在 Webpack 中的实现,是用来尽可能的删除没有被使用过的代码,一些被 import 了但其实没有被使用的代码。比如以下场景:
a.js:
export let num = 1
export const addNumber = ()=>{
num++
}
export const delNumber = ()=>{
num--
}
main.js:
import { addNumber } from './a'
addNumber()
如上
a.js中暴露两个方法,addNumber和delNumber,但是整个应用中,只用到了addNumber,那么构建打包的时候,delNumber将作为没有引用的方法,不被打包进来。
五 Commonjs 和 Es Module 总结
接下来贯穿全文,讲一下 Commonjs 和 Es Module 的特性。
Commonjs 总结
Commonjs 的特性如下:
CommonJS 模块由 JS 运行时实现。
CommonJs 是单个值导出,本质上导出的就是 exports 属性。
CommonJS 是可以动态加载的,对每一个加载都存在缓存,可以有效的解决循环引用问题。
CommonJS 模块同步加载并执行模块文件。
es module 总结
Es module 的特性如下:
ES6 Module 静态的,不能放在块级作用域内,代码发生在编译时。
ES6 Module 的值是动态绑定的,可以通过导出方法修改,可以直接访问修改结果。
ES6 Module 可以导出多个属性和方法,可以单个导入导出,混合导入导出。
ES6 模块提前加载并执行模块文件,
ES6 Module 导入模块在严格模式下。
ES6 Module 的特性可以很容易实现 Tree Shaking 和 Code Splitting。
六 总结
本文详细讲解了 Commonjs 和 Es Module ,希望阅读的同学能对前端模块化的实现有更深入的认识。吃透本文,能够轻松应付 Commonjs 和 Es Module 的面试知识点。