mongodb 使用总结
mongodb 前台直接运行建立索引命令的话,将造成整个数据库阻塞,因此索引建议使用 background 的方式建立,尤其是数据量很大的表应该注意,会造成数据库阻塞,影响非常严重
mongo 分页查询排序报错误,数据量小时没有错误,当数据量大时报错误,排序最大32MB的限制
解决方案:对排序字段创建索引即可
You're running into the 32MB limit on an in-memory sort:
http://docs.mongodb.org/manual/reference/limits/#Sorted-Documents
Indexing the sort field allows MongoDB to stream documents to you in sorted order, rather than attempting to load them all into memory on the server and sort them in memory before sending them to the client.
./mongo localhost:27017/admin
db.auth("site","123456")
use test1
更新
db.User.update({},{$rename:{"account.id":"account._id"}},{multi:true})
删除字段
db.Role.update({},{$unset:{"creator":1}},{multi:true})
Mongodb修改字段名称
db.User.update({mvno:{$exists:true,$nin:[null]}},{$rename:{"mvno.id":"mvno._id"}},{multi:true})
db.User.update({"account.accType.id":{$exists:true,$nin:[null]}},{$rename:{"account.accType.id":"account.accType._id"}},{multi:true})
db.User.update({_id:ObjectId("561b88eedc199e231802267c")},{$set:{username:"test"}})
导出数据指定数据表
./mongoexport -h localhost:27017 -u site -p=123456 --authenticationDatabase admin -d test1 -c Terminal -o /tmp/terminal.dat
mongoexport -h ip:port -uxxx -pyyy-d bss -c table_name --type csv -q '{}' --fields _id,name,age,type --out /home/xx/xx.dat
导出数据库
./mongod -h localhost:27017 -u site -p=123456 --authenticationDatabase admin -d test1 -o /tmp/datacopy
./mongodump -h localhost:40000 -u site -p=123456 --authenticationDatabase admin -d bssmongodb -o /tmp/datacopy
字段重命名
db.SESSION_2016_9.update({}, {$rename : {"flowsize" : "flowSize"}}, false, true)
导入数据库
./mongorestore -h localhost:27017 -u site -p=123456 --authenticationDatabase admin -d test1 /tmp/datacopy/test2/
{$where: '(this.createTime-1452152974903 > 1000)'} where做运算
db.test.find({"$and":[{"$where" :"this.createDate- this.endTime > 86400000"},{"$where" :"this.tradeType in ['0','1','5','8']"}]})
db.test.find({'$where': "this.endTime < this.createDate-3600000",trade:"1"}).sort({create:-1});
./mongostat --host localhost --port 27017 -u site -p 123456 --authenticationDatabase admin --监控mongodb状态
--discover切片信息查看
./mongostat --host localhost --port 27017 -u site -p 123456 --authenticationDatabase admin --discover
./mongostat -h 123.1.20.126:4200 -u site -p 123456 --authenticationDatabase admin
--聚合通道使用
db.DetailRecord.aggregate(
[
{ $match : { "businessId" : "5630851131196b149429ae88"}},
{
$group:
{
_id: {day:"$sessionId"},
totalAmount: { $sum: "$amount"},
count: { $sum: 1 }
}
}
]
)
创建组合索引
db.DetailedRecord.ensureIndex({"createDate":1,"processState":1})
./mongod --port=27017 --dbpath=/usr/local/mongodb/data/mongodb_data/ --logpath=/usr/local/mongodb/data/mongodb_log/mongodb.log --auth --fork
| --quiet | # 安静输出 |
| --port arg | # 指定服务端口号,默认端口27017 |
| --bind_ip arg | # 绑定服务IP,若绑定127.0.0.1,则只能本机访问,不指定默认本地所有IP |
| --logpath arg | # 指定MongoDB日志文件,注意是指定文件不是目录 |
| --logappend | # 使用追加的方式写日志 |
| --pidfilepath arg | # PID File 的完整路径,如果没有设置,则没有PID文件 |
| --keyFile arg | # 集群的私钥的完整路径,只对于Replica Set 架构有效 |
| --unixSocketPrefix arg | # UNIX域套接字替代目录,(默认为 /tmp) |
| --fork | # 以守护进程的方式运行MongoDB,创建服务器进程 |
| --auth | # 启用验证 |
| --cpu | # 定期显示CPU的CPU利用率和iowait |
| --dbpath arg | # 指定数据库路径 |
| --diaglog arg | # diaglog选项 0=off 1=W 2=R 3=both 7=W+some reads |
| --directoryperdb | # 设置每个数据库将被保存在一个单独的目录 |
| --journal | # 启用日志选项,MongoDB的数据操作将会写入到journal文件夹的文件里 |
| --journalOptions arg | # 启用日志诊断选项 |
| --ipv6 | # 启用IPv6选项 |
| --jsonp | # 允许JSONP形式通过HTTP访问(有安全影响) |
| --maxConns arg | # 最大同时连接数 默认2000 |
| --noauth | # 不启用验证 |
| --nohttpinterface | # 关闭http接口,默认关闭27018端口访问 |
| --noprealloc | # 禁用数据文件预分配(往往影响性能) |
| --noscripting | # 禁用脚本引擎 |
| --notablescan | # 不允许表扫描 |
| --nounixsocket | # 禁用Unix套接字监听 |
| --nssize arg (=16) | # 设置信数据库.ns文件大小(MB) |
| --objcheck | # 在收到客户数据,检查的有效性, |
| --profile arg | # 档案参数 0=off 1=slow, 2=all |
| --quota | # 限制每个数据库的文件数,设置默认为8 |
| --quotaFiles arg | # number of files allower per db, requires --quota |
| --rest | # 开启简单的rest API |
| --repair | # 修复所有数据库run repair on all dbs |
| --repairpath arg | # 修复库生成的文件的目录,默认为目录名称dbpath |
| --slowms arg (=100) | # value of slow for profile and console log |
| --smallfiles | # 使用较小的默认文件 |
| --syncdelay arg (=60) | # 数据写入磁盘的时间秒数(0=never,不推荐) |
| --sysinfo | # 打印一些诊断系统信息 |
| --upgrade | # 如果需要升级数据库 |
复制集读选项模式
详细说明
primary
默认模式,所有的读操作都在复制集的 主节点 进行的。
primaryPreferred
在大多数情况时,读操作在 主节点 上进行,但是如果主节点不可用了,读操作就会转移到 从节点 上执行。
secondary
所有的读操作都在复制集的 从节点 上执行。
secondaryPreferred
在大多数情况下,读操作都是在 从节点 上进行的,但是当 从节点 不可用了,读操作会转移到 主节点 上进行。
nearest
读操作会在 复制集 中网络延时最小的节点上进行,与节点类型无关。
注意:在从节点上进行读操作时返回的数据可能不是 主节点 上最新的数据。如果需要数据强一致性,也需要在写入的时候设置写策略。
代码参考:
DBCollection collection=mongoPersist.getMongoTemplate().getCollection("test");
//Gets a read preference that forces reads to a secondary if one is available, otherwise to the primary 读数据设置。根据实际情况设置不同的读策略。
collection.setReadPreference(ReadPreference.secondaryPreferred());
//at least 2 servers for the write operation 写数据时设置。根据实际情况设置不同的写策略。
collection.setWriteConcern(WriteConcern.REPLICAS_SAFE);
collection.find();
collection.save(document);
集群搭建资料
http://blog.csdn.net/luonanqin/article/details/8497860
Spring 集成配置方式
用户验证:注意事项
为什么我们启用了登录验证模块,但我们登录时没有指定用户,为什么还可以登录
呢?在最初始的时候 MongoDB 都默认有一个 admin 数据库(默认是空的),
而 admin.system.users 中将会保存比在其它数据库中设置的用户权限更大的用户信息。
注意:当 admin.system.users 中没有添加任何用户时,即使 MongoDB 启动时添加了 --auth
参数,如果在除 admin 数据库中添加了用户,此时不进行任何认证依然可以使用任何操作,
直到知道你在 admin.system.users 中添加了一个用户.
副本集加切片部署方案详见:http://blog.csdn.net/angellove156/article/details/20638107
Mongodb权威指南中文版
仲裁节点不需要也可以切换主从,副本集使用奇数个成员
奇数 官方推荐副本集的成员数量为奇数,最多12个副本集节点,最多7个节点参与选举。最多12个副本集节点是因为没必要一份数据复制那么多份,备份太多反而增加了网络负载和拖慢了集群性能;而最多7个节点参与选举是因为内部选举机制节点数量太多就会导致1分钟内还选不出主节点,凡事只要适当就好。这个“12”、“7”数字还好,通过他们官方经过性能测试定义出来可以理解。具体还有哪些限制参考官方文档《 MongoDB Limits and Thresholds 》。 但是这里一直没搞懂整个集群为什么要奇数,通过测试集群的数量为偶数也是可以运行的,参考这个文章http://www.itpub.net/thread-1740982-1-1.html。后来突然看了一篇stackoverflow的文章终于顿悟了,mongodb本身设计的就是一个可以跨IDC的分布式数据库,所以我们应该把它放到大的环境来看。
假设四个节点被分成两个IDC,每个IDC各两台机器,如下图。但这样就出现了个问题,如果两个IDC网络断掉,这在广域网上很容易出现的问题,在上面选举中提到只要主节点和集群中大部分节点断开链接就会开始一轮新的选举操作,不过mongodb副本集两边都只有两个节点,但是选举要求参与的节点数量必须大于一半,这样所有集群节点都没办法参与选举,只会处于只读状态。但是如果是奇数节点就不会出现这个问题,假设3个节点,只要有2个节点活着就可以选举,5个中的3个,7个中的4个。。。
/usr/local/mongodb/bin/mongod --replSet rs2 --keyFile /data/key/r0 --fork --port 28010 --dbpath /data/data/r0 --logpath=/data/log/r0.log --logappend
/usr/local/mongodb/bin/mongod --replSet rs2 --keyFile /data/key/r1 --fork --port 28011 --dbpath /data/data/r1 --logpath=/data/log/r1.log --logappend
/usr/local/mongodb/bin/mongod --replSet rs2 --keyFile /data/key/r2 --fork --port 28012 --dbpath /data/data/r2 --logpath=/data/log/r2.log --logappend
/usr/local/mongodb/bin/mongod --configsvr --keyFile /data/key/config --port 30000 --dbpath /data/configdb --fork --logpath /data/log/config.log --directoryperdb
/usr/local/mongodb/bin/mongos --port 40000 --configdb SZ-MongoDB02:30000 --fork --logpath /data/log/route.log --keyFile /data/key/mongos
/usr/local/mongodb/bin/mongod --replSet rs1 --keyFile /data/key/r0 --fork --port 28010 --dbpath /data/data/r0 --logpath=/data/log/r0.log --logappend
/usr/local/mongodb/bin/mongod --replSet rs1 --keyFile /data/key/r1 --fork --port 28011 --dbpath /data/data/r1 --logpath=/data/log/r1.log --logappend
/usr/local/mongodb/bin/mongod --replSet rs1 --keyFile /data/key/r2 --fork --port 28012 --dbpath /data/data/r2 --logpath=/data/log/r2.log --logappend
/usr/local/mongodb/bin/mongos --port 40000 --configdb SZ-MongoDB02:30000 --fork --logpath /data/log/route.log --keyFile /data/key/mongos
创建用户
db.createUser({
"user" : "test1",
"pwd" : "123456",
"roles" : [
{
"role" : "dbAdmin",
"db" : "test"
},
{
"role" : "readWrite",
"db" : "test"
}
]
}
)
where查询
db.test.find({'$where':'this.createDate-this.endDate>10'});
db.cyl.find({'imei':{$type:18}}).forEach(function(x) {x.imei = String(x.imei);db.cyl.save(x); });
18为long型
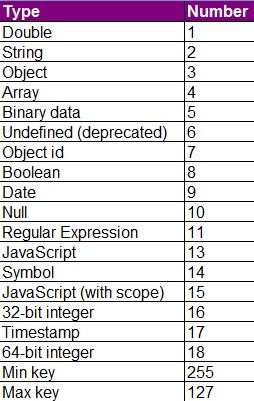
db.test.distinct("imei",{}).length mongodb查询重复数据
oplog相关
oplog ——> producer(blockQueue)->replBatcher->oplogApplication->16个replwriter线程
1、合理配置oplog,按默认『5% 的可用磁盘空间』来配置oplog在绝大部分场景下都能满足需求
2、新加入节点时,可以通过物理复制来避免initial sync,将Primary上的dbpath拷贝到新的节点,直接启动,效率更高
3、db.printSlaveReplicationInfo()监控主从同步时延
复制集
1、网络分区时会存在多个primary,driver写入时设置writer Concern
索引
1、创建索引需指定后台执行,否则会阻塞数据库
2、TTL 集合,指定文档的过期时间
常见问题
1、读写分离应用,刚刚存入立马读取的场景,可能读不到数据,主从同步时延
2、CPU杀手:全表扫描、不合理索引、排序聚合、创建索引
从节点
Arbiter 仲裁节点
Hidden 隐藏节点 数据备份、离线计算
Delayed 延时节点
同步工具
mongoshake
mongsync