CNN成长路:从AlexNet到EfficientNet(02)
一、说明
在~10年的深度学习中,进步是多么迅速!早在 2012 年,Alexnet 在 ImageNet 上的准确率就达到了 63.3% 的 Top-1。现在,我们超过90%的EfficientNet架构和师生训练(teacher-student)。
二、第一阶段
见文:CNN成长路:从AlexNet到EfficientNet(01)
三、第二阶段:近代CNN
3.1 DenseNet: Densely Connected Convolutional Networks (2017)
跳过连接是一个非常酷的主意。我们为什么不跳过连接所有内容?
Densenet是将这种想法推向极端的一个例子。当然,与 ResNets 的主要区别在于我们将连接而不是添加特征图。
因此,其背后的核心思想是功能重用,这导致了非常紧凑的模型。因此,它比其他CNN需要更少的参数,因为没有重复的特征图。
好吧,为什么不呢?嗯......这里有两个问题:
-
特征映射的大小必须相同。
-
与所有先前特征映射的串联可能会导致内存爆炸。
为了解决第一个问题,我们有两个解决方案:
a) 使用具有适当填充的 conv 图层来保持空间暗淡或
b) 仅在称为密集块的块内使用密集跳过连接。
示例图像如下所示:
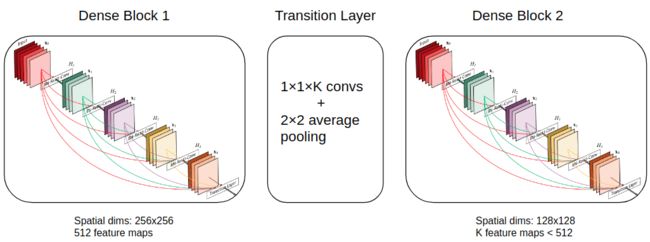
过渡层可以使用平均池化对图像尺寸进行下采样。
为了解决第二个问题,即内存爆炸,特征图通过 1x1 convs 减少(一种压缩)。请注意,我在图中使用了 K,但 densenet 使用�=��一个��一个��/2K=Fe a tmaps/2
此外,当不使用数据增强时,它们在每个卷积层后添加一个 p=0.2 的 dropout 层。
3.2 增长率
更重要的是,还有一个参数控制整个架构的特征图数量。这是增长率。它指定每个超密集卷积层的输出特征。鉴于k0初始特征图和k增长率,可以计算出每层输入特征图的数量l如![]()
.在框架中,数字 k 是 4 的倍数,称为瓶颈大小 (bn_size)。
最后,我在这里引用DenseNet在火炬视觉中最重要的论点作为总结:
import torchvision
model = torchvision.models.DenseNet(
growth_rate = 16, # how many filters to add each layer (`k` in paper)
block_config = (6, 12, 24, 16), # how many layers in each pooling block
num_init_features = 16, # the number of filters to learn in the first convolution layer (k0)
bn_size= 4, # multiplicative factor for number of bottleneck (1x1 cons) layers
drop_rate = 0, # dropout rate after each dense conv layer
num_classes = 30 # number of classification classes
)
print(model) # see snapshot below在“密集”层(快照中的密集层5和6)内部,有一个瓶颈(1x1)层,将通道减少到bn_size∗growth_rate=64bn_size∗growth_rate=64在我们的例子中。否则,输入通道的数量将激增。如下图所示,每层加起来16=growth_rate16=growth_rate渠道。

在实践中,我发现基于 DenseNet 的模型训练速度很慢,但由于功能重用,与具有竞争力的模型相比,参数很少。
尽管DenseNet被提议用于图像分类,但它已被用于特征可重用性更为关键的领域的各种应用(即分割和医学成像应用)。从 Papers with Code 借来的饼图说明了这一点:
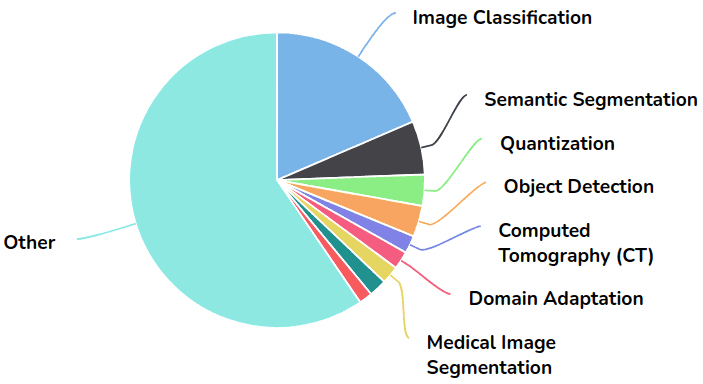
图片来自带有代码的论文
在 2017 年的 DenseNet 之后,我只发现 HRNet 架构很有趣,直到 2019 年 EfficientNet 问世!
3.3 大迁移(Big Transfer-BiT):一般视觉表示学习(2020)
尽管已经提出了许多ResNet的变体,但最新和最著名的是BiT。大转移(BiT)是一种可扩展的基于ResNet的模型,用于有效的图像预训练[5]。
他们基于 ResNet3 开发了 152 个 BiT 模型(小型、中型和大型)。对于BiT的大变化,他们使用ResNet152x4,这意味着每层都有4倍的通道。他们在比imagenet更大的数据集中对模型进行了一次预训练。最大的模型是在疯狂庞大的JFT数据集上训练的,该数据集由300M标记的图像组成。
该架构的主要贡献是规范化层的选择。为此,作者用组归一化(GN)和权重标准化(WS)取代了批次归一化(BN)。

图片来源:Lucas Beyer和Alexander Kolesnikov。源
为什么?因为第一个BN的参数(均值和方差)需要在预训练和转移之间进行调整。另一方面,GN 不依赖于任何参数状态。另一个原因是 BN 使用批处理级统计信息,这对于像 TPU 这样的小型设备的分布式训练变得不可靠。分布在 4 个 TPU 上的 500K 批次意味着每个工人有 8 个批次,这并不能很好地估计统计数据。通过将规范化技术更改为 GN+WS,它们避免了工作线程之间的同步。
显然,扩展到更大的数据集与模型大小密切相关。
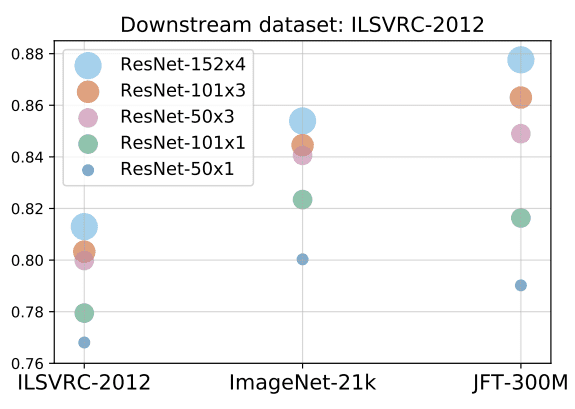 性能与更多和多种模型。
性能与更多和多种模型。
资料来源:亚历山大·科列斯尼科夫等人,2020
在此图中,说明了与数据并行扩展体系结构的重要性。ILSVER是具有1M图像的Imagenet数据集,ImageNet-21K具有大约14M图像,JFT 300M!
最后,这种大型预训练模型可以微调到非常小的数据集,并获得非常好的性能。
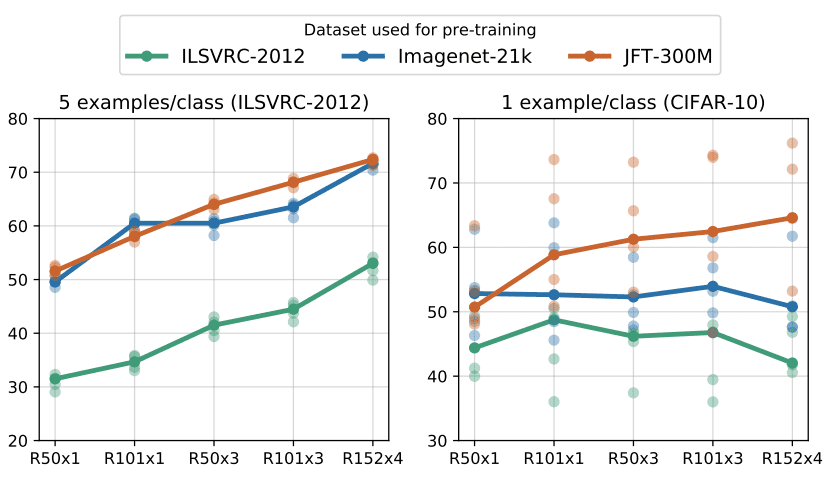 性能与更多和多种模型。
性能与更多和多种模型。
资料来源:亚历山大·科列斯尼科夫等人,2020
在 ImageNet 上每个类有 5 个示例,将 3 倍扩大,在 JFT 上预训练的 ResNet-50 (x3) 实现了与 AlexNet 相似的性能!
3.4 EfficientNet:重新思考卷积神经网络的模型缩放(2019)
EfficientNet是关于工程和规模的。它证明,如果您仔细设计架构,则可以使用合理的参数获得最佳结果。
 图片来源:Mingxing Tan和Quoc V. Le 2020。
图片来源:Mingxing Tan和Quoc V. Le 2020。
来源:EfficientNet:重新思考卷积神经网络的模型缩放
该图演示了 ImageNet 精度与模型参数。
令人难以置信的是,EfficientNet-B1比ResNet-7小6.5倍,快7.152倍。
3.5 个性化升级
让我们了解这是如何实现的。
-
有了更多的层(深度),人们可以捕获更丰富和更复杂的特征,但这样的模型很难训练(由于梯度消失)
-
更广泛的网络更容易训练。它们往往能够捕获更细粒度的特征,但很快就会饱和。
-
通过训练更高分辨率的图像,卷积神经网络理论上能够捕获更细粒度的细节。同样,对于相当高的分辨率,精度增益会降低
作者没有找到最好的架构,而是建议从一个相对较小的基线模型开始。F并逐渐扩展它。
这缩小了设计空间。为了进一步限制设计空间,作者将所有层限制为具有恒定比率的均匀缩放。这样,我们就有了一个更易于处理的优化问题。最后,必须尊重我们基础设施的最大内存和 FLOP 数量。
下图很好地演示了这一点:
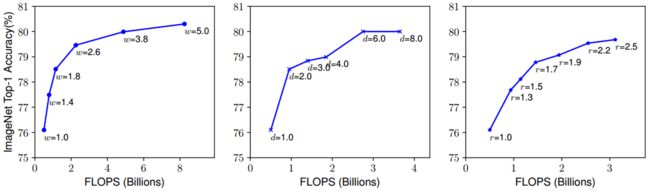
图片来源:Mingxing Tan和Quoc V. Le 2020。来源:EfficientNet:重新思考卷积神经网络的模型缩放
w是宽度,d深度,以及r分辨率缩放因子。通过缩放一个,它们中只有一个会在一个点上饱和。我们能做得更好吗?
3.5 复合缩放
因此,让我们同时放大网络深度(更多层)、宽度(每层更多通道)、分辨率(输入图像)。这称为复合缩放。
为此,我们必须在缩放过程中平衡上述所有维度。在这里,它变得令人兴奋。
这样:α⋅β2⋅γ2≈2,给定所有α,β,γ>1
现在φ控制所有所需的尺寸并将它们缩放在一起,但不能相等。α,β,γ告诉我们如何将额外的资源分配到网络。
注意到什么奇怪的东西了吗?β和γ在约束中平方。
原因很简单:网络深度加倍将使 FLOPS 翻倍,但宽度或输入分辨率加倍将使 FLOPS 增加四倍。通过这种方式,我们类似于卷积,这是基本的构建块。
基线架构是使用神经架构搜索找到的,因此它可以优化准确性和FLOPS,称为EfficientNet-B0。
还行,很酷。剩下的就是定义α,β,γ和φ.
-
修复φ=1,假设还有两次可用的资源,并执行网格搜索α,β,γ.EfficientNet-B0的最佳获取值是α=1.2,β=1.2,γ=1.15
-
修复α,β,γ并扩大规模φ关于硬件(FLOP + 内存)
在我看来,理解复合缩放有效性的最直观方法与 ImageNet 上相同基线模型 (EfficientNet-B0) 的单个缩放相当:
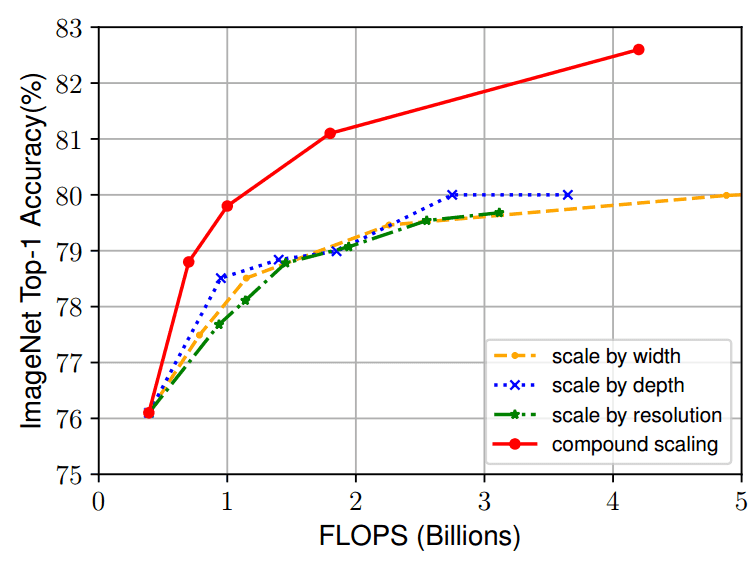
图片来源:Mingxing Tan和Quoc V. Le 2020。来源:EfficientNet:重新思考卷积神经网络的模型缩放
3.6 与吵闹的学生进行自我训练改进了图像网络分类(2020 年)
不久之后,使用了迭代半监督方法。它通过300亿张未标记的图像显着提高了Efficient-Net的性能。作者称培训计划为“嘈杂的学生培训” [8]。它由两个神经网络组成,称为教师和学生。迭代训练方案可以用 4 个步骤来描述:
-
在标记的图像上训练教师模型,
-
使用老师在300M未标记的图像上生成标签(伪标签))
-
在标记图像和伪标记图像的组合上训练学生模型。
-
从步骤 1 开始迭代,将学生视为教师。重新推断未标记的数据并从头开始培训新学生。
新学生模型通常大于教师模型,因此可以从更大的数据集中受益。此外,在训练学生模型时添加了明显的噪声,因此它被迫从伪标签中学习。
伪标签通常是软标签(连续分布)而不是硬标签(独热编码)。
此外,辍学和随机深度等不同的技术被用来训练新生[8]。

图片来源:Xizhe Xie et al. 来源:Noisy Student 的自我训练改进了 ImageNet 分类
在步骤 3 中,我们使用标记和未标记的数据联合训练模型。未标记的批大小在第一次迭代中设置为标记批大小的 14 倍,在第二次迭代中设置为 28 倍。
3.7 元伪标签 (2021)
动机:如果伪标签不准确,学生不会超过老师。这在伪标记方法中称为确认偏差。
高层次的思想:设计一个反馈机制来纠正教师的偏见。
观察结果来自伪标签如何影响学生在标记数据集上的表现。反馈信号是训练教师的奖励,类似于强化学习技术。
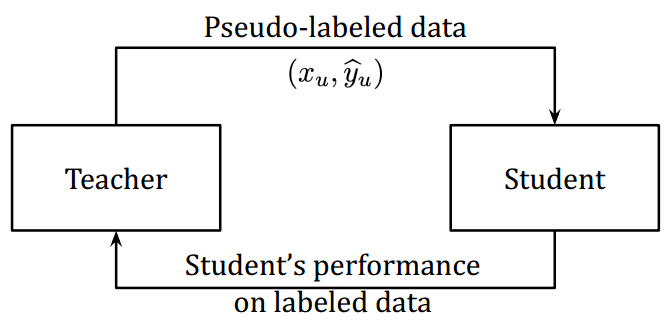
Hieu Pham等人,2020年。来源:元伪标签
这样,教师和学生就得到了共同的训练。教师从奖励信号中了解学生在来自标记数据集的一批图像上的表现。
3 总结和概括
那里有很多凸网!我们可以通过查看下表来总结它们:
| 型号名称 | 参数数量 [百万] | 图像网前 1 名精度 | 年 |
| 亚历克斯网 | 60 米 | 63.3 % | 2012 |
| 盗梦空间 V1 | 5 米 | 69.8 % | 2014 |
| VGG 16 | 138 米 | 74.4 % | 2014 |
| VGG 19 | 144 米 | 74.5 % | 2014 |
| 盗梦空间 V2 | 11,2 米 | 74.8 % | 2015 |
| 瑞思网-50 | 26 米 | 77.15 % | 2015 |
| 瑞思网-152 | 60 米 | 78.57 % | 2015 |
| 盗梦空间 V3 | 27 米 | 78.8 % | 2015 |
| 密集网-121 | 8 米 | 74.98 % | 2016 |
| 密集网-264 | 22. | 77.85 % | 2016 |
| BiT-L (ResNet) | 928 米 | 87.54 % | 2019 |
| 嘈杂学生高效网-L2 | 480 米 | 88.4 % | 2020 |
| 元伪标签 | 480 米 | 90.2 % | 2021 |
您可以注意到DenseNet模型的紧凑性。或者最先进的EfficientNet有多大。更多的参数并不总是能保证更高的精度,正如您在BiT和VGG中看到的那样。
在本文中,我们提供了最著名的深度学习架构背后的一些直觉。话虽如此,继续前进的唯一方法就是练习!从火炬视导入模型并根据您的数据对其进行微调。它是否比从头开始训练提供更好的准确性?
下一步是什么?使用深度学习为计算机视觉系统提供可靠而全面的方法。试一试!使用折扣代码 aisummer35 从您最喜欢的 AI 博客中获得独家 35% 的折扣。使用折扣代码 aisummer35 从您最喜欢的 AI 博客中获得独家 35% 的折扣。如果您更喜欢视觉课程,Andrew Ng的卷积神经网络是迄今为止最好的课程。
4 引用
[1] Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2017).使用深度卷积神经网络进行图像网络分类。ACM的通讯,60(6),84-90。
[2] Simonyan, K., & Zisserman, A. (2014).用于大规模图像识别的非常深的卷积网络。arXiv预印本arXiv:1409.1556。
[3] 塞格迪, C., 刘, W., 贾, Y., Sermanet, P., Reed, S., Anguelov, D., ...&Rabinovich, A. (2015).更深入地进行卷积。在IEEE计算机视觉和模式识别会议记录中(第1-9页)。
[4] He, K., Zhang, X., Ren, S., & Sun, J. (2016).用于图像识别的深度残差学习。IEEE计算机视觉和模式识别会议论文集(第770-778页)。
[5] Kolesnikov, A., Beyer, L., Zhai, X., Puigcerver, J., Yung, J., Gelly, S., & Houlsby, N. (2019).大迁移(位):一般视觉表示学习。arXiv预印本arXiv:1912.11370,6(2)
[6] Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K. Q. (2017).密集连接的卷积网络。IEEE计算机视觉和模式识别会议论文集(第4700-4708页)。
[7] Tan, M., & Le, Q. V. (2019).高效网络:重新思考卷积神经网络的模型缩放。arXiv预印本arXiv:1905.11946。
[8] Xie, Q., Luong, M. T., Hovy, E., & Le, Q. V. (2020).与嘈杂的学生进行自我训练可改进图像网分类。在IEEE/CVF计算机视觉和模式识别会议记录中(第10687-10698页)。
[9] Pham, H., Xie, Q., Dai, Z., & Le, Q. V. (2020).元伪标签。arXiv预印本arXiv:2003.10580。
[10] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., & Wojna, Z. (2016).重新思考计算机视觉的初始架构。IEEE计算机视觉和模式识别会议论文集(第2818-2826页)。